
Lanskap model bahasa besar (LLMs) sedang berkembang dengan cepat. Model-model ini semakin kuat, mampu, dan, yang terpenting, lebih mudah diakses. Tim Qwen baru-baru ini meluncurkan Qwen3, generasi terbaru mereka dari LLMs, yang menawarkan kinerja mengesankan di berbagai tolok ukur, termasuk pengkodean, matematika, dan penalaran umum. Dengan model unggulan seperti Mixture-of-Experts (MoE) Qwen3-235B-A22B yang bersaing dengan raksasa yang sudah mapan dan bahkan model padat yang lebih kecil seperti Qwen3-4B yang bersaing dengan model parameter 72B generasi sebelumnya, Qwen3 merupakan lompatan signifikan ke depan.
Aspek kunci dari rilis ini adalah penetapan bobot terbuka dari beberapa model, termasuk dua varian MoE (Qwen3-235B-A22B dan Qwen3-30B-A3B) dan enam model padat yang berkisar dari 0.6B hingga 32B parameter. Keterbukaan ini mengundang pengembang, peneliti, dan penggemar untuk menjelajahi, memanfaatkan, dan membangun alat-alat yang kuat ini. Sementara API berbasis cloud menawarkan kenyamanan, keinginan untuk menjalankan model-model canggih ini secara lokal semakin meningkat, didorong oleh kebutuhan akan privasi, kontrol biaya, kustomisasi, dan aksesibilitas offline.
Untungnya, ekosistem alat untuk eksekusi LLM lokal telah matang secara signifikan. Dua platform menonjol yang menyederhanakan proses ini adalah Ollama dan vLLM. Ollama menyediakan cara yang sangat ramah pengguna untuk memulai dengan berbagai model, sementara vLLM menawarkan solusi penyajian berkinerja tinggi yang dioptimalkan untuk throughput dan efisiensi, terutama untuk model yang lebih besar. Artikel ini akan memandu Anda melalui pemahaman Qwen3 dan mengatur model-model kuat ini di mesin lokal Anda menggunakan Ollama dan vLLM.
Ingin platform terintegrasi All-in-One untuk Tim Pengembang Anda bekerja sama dengan produktivitas maksimum?
Apidog memenuhi semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!
Apa itu Qwen 3 dan Tolok Ukur
Qwen3 merupakan generasi ketiga dari model bahasa besar (LLMs) yang dikembangkan oleh tim Qwen, dirilis pada April 2025. Iterasi ini menandakan kemajuan substansial dibandingkan versi sebelumnya, dengan fokus pada kemampuan penalaran yang ditingkatkan, efisiensi melalui inovasi arsitektur seperti Mixture-of-Experts (MoE), dukungan multibahasa yang lebih luas, dan kinerja yang lebih baik di berbagai tolok ukur. Rilis ini mencakup penetapan bobot terbuka dari beberapa model di bawah lisensi Apache 2.0, mempromosikan aksesibilitas untuk penelitian dan pengembangan.
Arsitektur Model Qwen 3 dan Variants, Dijelaskan
Keluarga Qwen3 mencakup baik model padat tradisional maupun arsitektur MoE yang jarang, melayani berbagai anggaran komputasi dan kebutuhan kinerja.
Model Padat: Model-model ini memanfaatkan semua parameter mereka selama inferensi. Detail arsitektur kunci termasuk:
| Model | Lapisan | Kepala Perhatian (Query / Key-Value) | Mengikat Embedding Kata | Panjang Konteks Maksimal |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Ya | 32.768 token (32K) |
| Qwen3-1.7B | 28 | 16 / 8 | Ya | 32.768 token (32K) |
| Qwen3-4B | 36 | 32 / 8 | Ya | 32.768 token (32K) |
| Qwen3-8B | 36 | 32 / 8 | Tidak | 131.072 token (128K) |
| Qwen3-14B | 40 | 40 / 8 | Tidak | 131.072 token (128K) |
| Qwen3-32B | 64 | 64 / 8 | Tidak | 131.072 token (128K) |
Catatan: Attention Query Tergrup (GQA) diterapkan di semua model, ditunjukkan dengan jumlah kepala Query dan Key-Value yang berbeda.
Model Mixture-of-Experts (MoE): Model-model ini memanfaatkan sparsity dengan mengaktifkan hanya sebagian dari "ahli" Feed-Forward Networks (FFNs) untuk setiap token selama inferensi. Ini memungkinkan jumlah total parameter yang besar sambil menjaga biaya komputasi mendekati model padat yang lebih kecil.
| Model | Lapisan | Kepala Perhatian (Query / Key-Value) | # Ahli (Total / Diaktifkan) | Panjang Konteks Maksimal |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 131.072 token (128K) |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 131.072 token (128K) |
Catatan: Kedua model MoE menggunakan 128 total ahli tetapi hanya mengaktifkan 8 per token, secara signifikan mengurangi beban komputasi dibandingkan dengan model padat ukuran setara.
Fitur Teknologi Kunci Qwen 3
Mode Berpikir Hibrida: Fitur khas Qwen3 adalah kemampuannya untuk beroperasi dalam dua mode yang berbeda, yang dapat dikendalikan oleh pengguna:
- Mode Berpikir (Default): Model melakukan penalaran internal langkah demi langkah (gaya Chain-of-Thought) sebelum menghasilkan respons akhir. Proses pemikiran laten ini terenkapsulasi, sering ditandai dengan token khusus (misalnya, mengeluarkan
<think>...</think>konten sebelum jawaban akhir saat menggunakan konfigurasi kerangka tertentu). Mode ini meningkatkan kinerja pada tugas kompleks yang memerlukan deduksi logis, penalaran matematis, atau perencanaan. Ini memungkinkan peningkatan kinerja yang dapat diskalakan yang berkorelasi langsung dengan anggaran penalaran komputasi yang dialokasikan. - Mode Non-Berpikir: Model menghasilkan respons langsung tanpa fase penalaran internal yang eksplisit, mengoptimalkan kecepatan dan mengurangi biaya komputasi pada kueri yang lebih sederhana.
Pengguna dapat secara dinamis beralih antara mode ini, mungkin pada basis giliran demi giliran dalam percakapan multi-giliran menggunakan tag seperti/thinkdan/no_thinkdalam prompt mereka (tergantung kerangka), memungkinkan kontrol yang lebih halus atas trade-off antara latensi/biaya dan kedalaman penalaran.
Dukungan Multibahasa yang Luas: Model Qwen3 dilatih sebelumnya pada korpus yang beragam yang memungkinkan dukungan untuk 119 bahasa dan dialek di seluruh keluarga bahasa utama (Indo-Eropa, Sino-Tibet, Afro-Asiatik, Austronesia, Dravida, Turki, dll.), menjadikannya cocok untuk berbagai aplikasi global.
Metodologi Pelatihan yang Canggih:
- Pra-pelatihan: Model dilatih sebelumnya pada dataset berskala besar yang terdiri dari triliunan token. Tahap pra-pelatihan terakhir melibatkan penggunaan data konteks panjang berkualitas tinggi untuk memperpanjang jendela konteks efektif hingga 32K token pada awalnya, dengan perpanjangan lebih lanjut hingga 128K untuk model yang lebih besar.
- Pascapelatihan: Sebuah pipeline canggih yang terdiri dari empat tahap diterapkan untuk memberikan kemampuan mengikuti instruksi, keterampilan penalaran, dan mekanisme berpikir hibrida pada model:
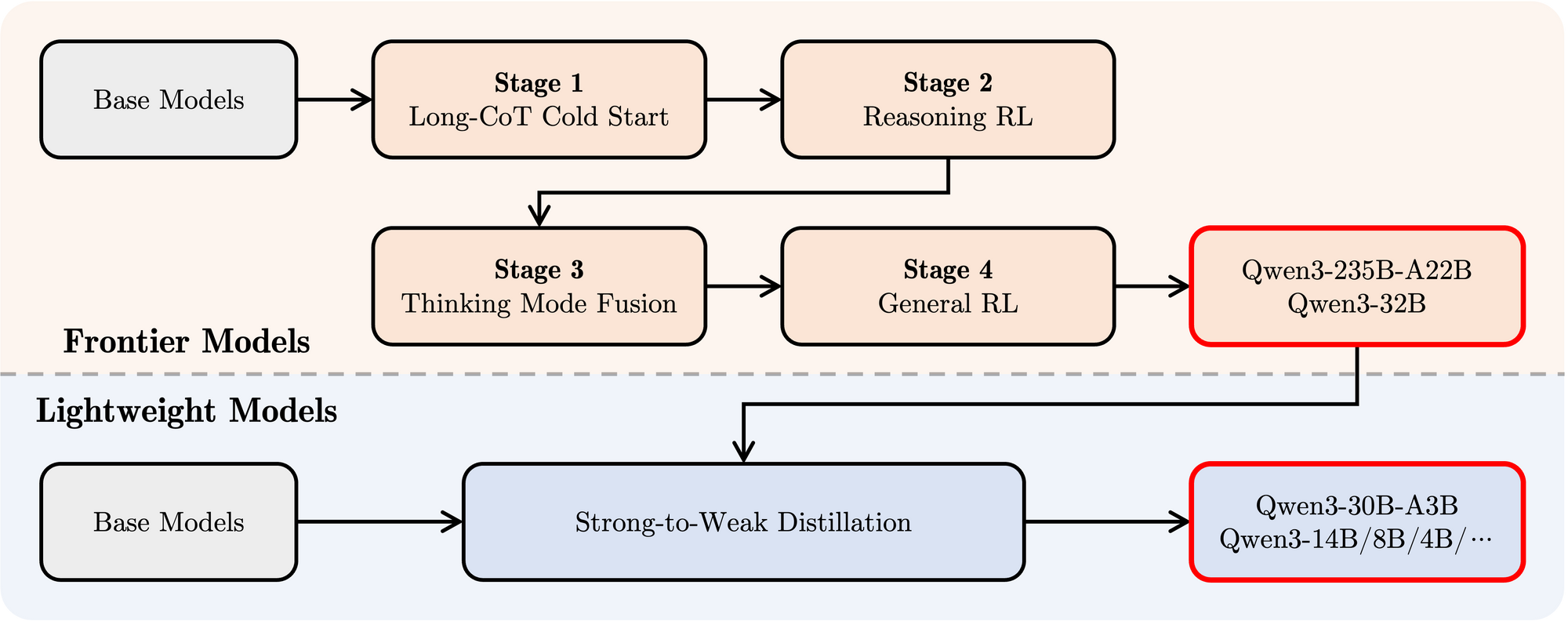
- Cold Start CoT Panjang: Penyempurnaan terawasi (SFT) pada data Chain-of-Thought (CoT) panjang yang beragam yang mencakup matematika, pengkodean, penalaran logis, dan STEM untuk membangun kemampuan penalaran dasar.
- Reinforcement Learning (RL) berbasis Penalaran: Meningkatkan sumber daya komputasi untuk RL menggunakan penghargaan berbasis aturan untuk meningkatkan eksplorasi dan eksploitasi khusus untuk tugas penalaran.
- Fusi Mode Berpikir: Mengintegrasikan kemampuan non-berpikir dengan menyempurnakan model yang ditingkatkan penalarannya pada campuran data CoT panjang dan data pelatihan instruksi standar yang dihasilkan oleh model Tahap 2. Ini memadukan penalaran mendalam dengan generasi respons yang cepat.
- RL Umum: Menerapkan RL di berbagai tugas domain umum (mengikuti instruksi, kepatuhan format, kemampuan agen) untuk menyempurnakan perilaku keseluruhan dan mengurangi keluaran yang tidak diinginkan.
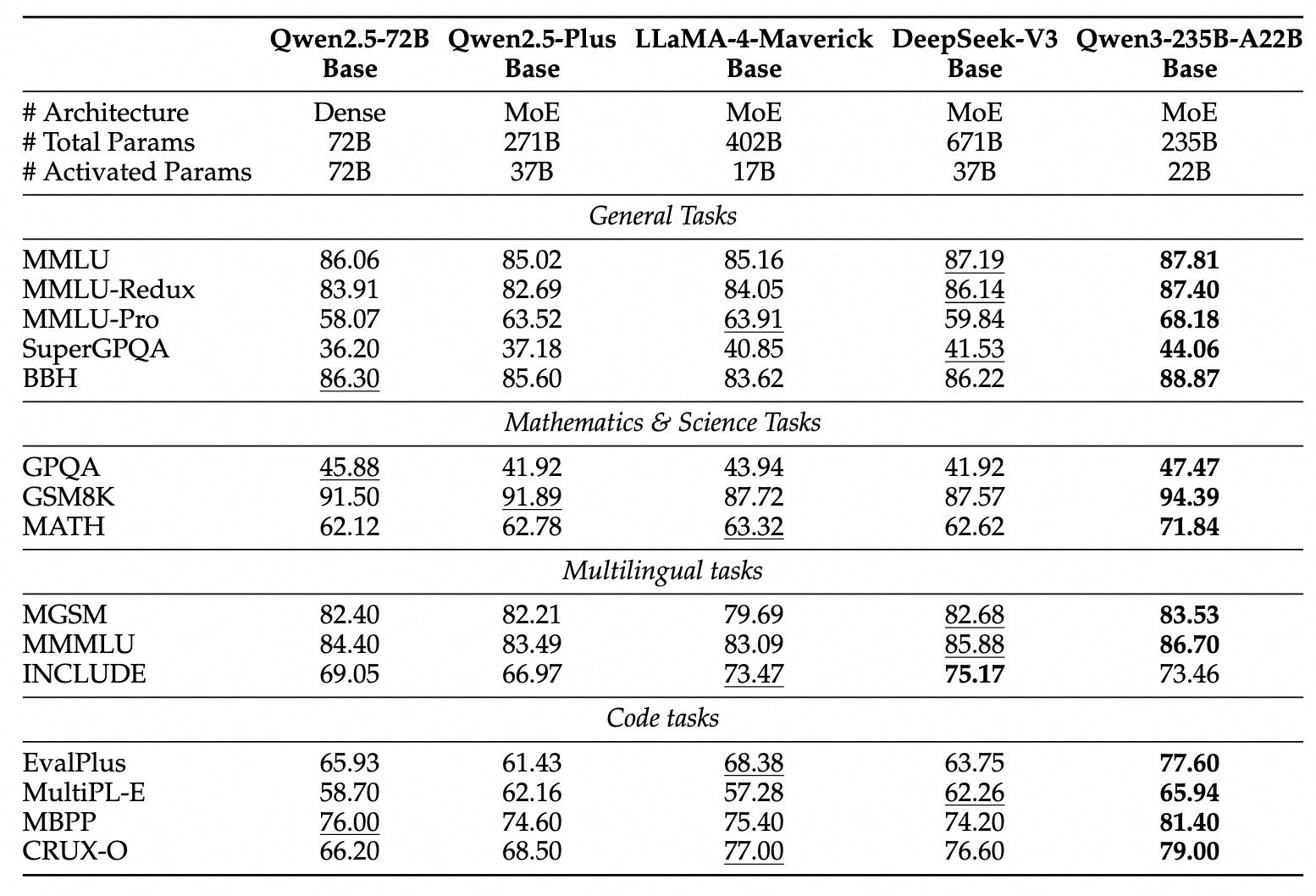
Kinerja Tolok Ukur Qwen 3
Qwen3 menunjukkan kinerja yang sangat kompetitif dibandingkan dengan model-model terkemuka kontemporer lainnya:
MoE Unggulan: Model Qwen3-235B-A22B mencapai hasil yang sebanding dengan model-model tingkat atas seperti DeepSeek-R1, o1 dan o3-mini dari Google, Grok-3, dan Gemini-2.5-Pro di berbagai tolok ukur yang mengevaluasi pengkodean, matematika, dan kemampuan umum.
MoE yang Lebih Kecil: Model Qwen3-30B-A3B secara signifikan mengungguli model-model seperti QwQ-32B, meskipun hanya mengaktifkan sebagian kecil (3B vs 32B) dari parameter selama inferensi, menyoroti efisiensi arsitektur MoE.
Model Padat: Karena kemajuan arsitektur dan pelatihan, model padat Qwen3 umumnya cocok atau melebihi kinerja model padat Qwen2.5 yang lebih besar. Misalnya:
Qwen3-1.7B≈Qwen2.5-3BQwen3-4B≈Qwen2.5-7B(dan bersaing denganQwen2.5-72B-Instructdalam beberapa aspek)Qwen3-8B≈Qwen2.5-14BQwen3-14B≈Qwen2.5-32BQwen3-32B≈Qwen2.5-72B
Penting untuk dicatat, model dasar padat Qwen3 menunjukkan peningkatan kinerja yang sangat kuat dibandingkan pendahulunya dalam tugas STEM, pengkodean, dan penalaran.
Efisiensi MoE: Model dasar MoE Qwen3 mencapai kinerja yang sebanding dengan model padat Qwen2.5 yang jauh lebih besar sambil hanya mengaktifkan sekitar 10% dari parameter, yang mengarah pada penghematan substansial dalam komputasi pelatihan dan inferensi.
Hasil tolok ukur ini menegaskan posisi Qwen3 sebagai keluarga model paling mutakhir yang menawarkan baik kinerja tinggi dan, terutama dengan varian MoE, efisiensi komputasi yang ditingkatkan. Model-model ini tersedia melalui platform standar seperti Hugging Face, ModelScope, dan Kaggle, dan didukung oleh kerangka penyebaran populer seperti Ollama, vLLM, SGLang, LMStudio, dan llama.cpp, memfasilitasi integrasi mereka ke dalam berbagai alur kerja dan aplikasi, termasuk eksekusi lokal.
Cara Menjalankan Qwen 3 Secara Lokal dengan Ollama
Ollama telah mendapatkan popularitas yang luar biasa karena kesederhanaannya dalam mengunduh, mengelola, dan menjalankan LLM secara lokal. Ini mengabstraksikan banyak kompleksitas, menyediakan antarmuka baris perintah dan server API.
1. Instalasi:
Instalasi Ollama biasanya sederhana. Kunjungi situs web resmi Ollama (ollama.com) dan ikuti instruksi unduhan untuk sistem operasi Anda (macOS, Linux, Windows).
2. Mengambil Model Qwen3:
Ollama memelihara perpustakaan model yang tersedia. Untuk menjalankan model Qwen3 tertentu, Anda menggunakan perintah ollama run. Jika model tidak ada secara lokal, Ollama secara otomatis mengunduhnya. Tim Qwen telah membuat beberapa varian Qwen3 tersedia langsung di perpustakaan Ollama.
Anda dapat menemukan tag Qwen3 yang tersedia di halaman Qwen3 situs web Ollama (misalnya, ollama.com/library/qwen3). Tag umum mungkin termasuk:
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32bqwen3:30b-a3b(Model MoE yang lebih kecil)
Untuk menjalankan model parameter 4B, misalnya, cukup buka terminal Anda dan ketik:
ollama run qwen3:4b
Perintah ini akan mengunduh model tersebut (jika diperlukan) dan memulai sesi percakapan interaktif.
3. Berinteraksi dengan Model:
Setelah perintah ollama run aktif, Anda dapat mengetik prompt langsung ke dalam terminal. Ollama juga memulai server lokal (biasanya di http://localhost:11434) yang mengekspos API yang kompatibel dengan standar OpenAI. Anda dapat berinteraksi dengan ini secara programatis menggunakan alat seperti curl atau berbagai pustaka klien dalam Python, JavaScript, dll.
4. Pertimbangan Perangkat Keras:
Menjalankan LLM secara lokal memerlukan sumber daya yang substansial.
- RAM: Bahkan model yang lebih kecil (0.6B, 1.7B) memerlukan beberapa gigabyte RAM. Model yang lebih besar (8B, 14B, 32B, 30B-A3B) memerlukan jauh lebih banyak, sering kali 16GB, 32GB, atau bahkan 64GB+, tergantung pada tingkat kuantisasi yang digunakan oleh Ollama.
- VRAM (GPU): Untuk kinerja yang dapat diterima, GPU khusus dengan VRAM yang cukup sangat dianjurkan. Ollama secara otomatis memanfaatkan GPU yang kompatibel (NVIDIA, Apple Silicon). Jumlah VRAM menentukan model terbesar yang dapat Anda jalankan sepenuhnya di GPU, yang secara signifikan mempercepat inferensi.
- CPU: Meskipun Ollama dapat menjalankan model di CPU, kinerjanya akan jauh lebih lambat dibandingkan dengan GPU.
Ollama sangat baik untuk memulai dengan cepat, pengembangan lokal, eksperimen, dan aplikasi percakapan untuk pengguna tunggal, terutama di perangkat keras kelas konsumen (dalam batasan).
Cara Menjalankan Ollama Secara Lokal dengan vLLM
vLLM adalah perpustakaan penyajian LLM throughput tinggi yang menggunakan optimasi seperti PagedAttention untuk secara signifikan meningkatkan kecepatan inferensi dan efisiensi memori, menjadikannya ideal untuk aplikasi yang menuntut dan penyajian model yang lebih besar. Tim vLLM menyediakan dukungan luar biasa untuk arsitektur baru, termasuk dukungan Hari 0 untuk Qwen3 saat dirilis.
1. Instalasi:
Instal vLLM menggunakan pip. Umumnya disarankan untuk menggunakan lingkungan virtual:
pip install -U vllm
Pastikan Anda memiliki prasyarat yang diperlukan, biasanya GPU NVIDIA yang kompatibel dengan toolkit CUDA yang sesuai terinstal. Lihat dokumentasi vLLM untuk persyaratan spesifik.
2. Menyajikan Model Qwen3:
vLLM menggunakan perintah vllm serve untuk memuat model dan meluncurkan server API yang kompatibel dengan OpenAI. Tim Qwen dan dokumentasi vLLM memberikan panduan tentang cara menjalankan Qwen3.
Berdasarkan informasi yang diberikan dan penggunaan vLLM yang umum, berikut adalah cara Anda dapat menyajikan model MoE Qwen3-235B besar menggunakan kuantisasi FP8 (untuk mengurangi penggunaan memori) dan paralel tensor di 4 GPU:
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--tensor-parallel-size 4
Mari kita uraikan perintah ini:
Qwen/Qwen3-235B-A22B-FP8: Ini adalah pengidentifikasi model, kemungkinan mengarah ke lokasi repositori Hugging Face.FP8menunjukkan penggunaan kuantisasi floating-point 8-bit, yang mengurangi jejak memori model dibandingkan FP16 atau BF16, yang sangat penting untuk model sebesar ini.--enable-reasoning: Flag ini penting untuk mengaktifkan kemampuan berpikir hibrida Qwen3 dalam vLLM.--reasoning-parser deepseek_r1: Keluaran berpikir Qwen3 memiliki format tertentu. vLLM memerlukan parser untuk menangani ini. Postingan blog menunjukkan bahwa untuk vLLM, parserdeepseek_r1harus digunakan (sementara SGLang menggunakan parserqwen3). Ini memastikan vLLM dapat dengan benar menginterpretasikan dan mungkin memisahkan langkah-langkah berpikir dari respons akhir.--tensor-parallel-size 4: Ini menginstruksikan vLLM untuk mendistribusikan bobot dan komputasi model di 4 GPU. Paralel tensor sangat penting untuk menjalankan model yang terlalu besar untuk muat di satu GPU. Anda dapat menyesuaikan angka ini berdasarkan GPU yang tersedia.
Anda dapat mengadaptasi perintah ini untuk model Qwen3 lainnya (misalnya, Qwen/Qwen3-30B-A3B atau Qwen/Qwen3-32B) dan menyesuaikan parameter seperti tensor-parallel-size berdasarkan perangkat keras Anda.
3. Berinteraksi dengan Server vLLM:
Setelah vllm serve berjalan, ia menjadi tuan rumah server API (default ke http://localhost:8000) yang mencerminkan spesifikasi API OpenAI. Anda dapat berinteraksi dengannya menggunakan alat standar:
- curl:
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-235B-A22B-FP8", # Gunakan nama model yang Anda sajikan
"prompt": "Jelaskan konsep Mixture-of-Experts dalam LLMs.",
"max_tokens": 150,
"temperature": 0.7
}'
- Klien Python OpenAI:
from openai import OpenAI
# Arahkan ke server vLLM lokal
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
completion = client.completions.create(
model="Qwen/Qwen3-235B-A22B-FP8", # Gunakan nama model yang Anda sajikan
prompt="Tulis cerita pendek tentang robot yang menemukan musik.",
max_tokens=200
)
print(completion.choices[0].text)
4. Kinerja dan Kasus Penggunaan:
vLLM bersinar dalam skenario yang memerlukan throughput tinggi (banyak permintaan per detik) dan latensi rendah. Optimasi ini membuatnya cocok untuk:
- Membangun aplikasi yang didukung oleh LLM lokal.
- Menyajikan model untuk banyak pengguna secara bersamaan.
- Menyebarkan model besar yang memerlukan pengaturan multi-GPU.
- Lingkungan produksi di mana kinerja sangat penting.
Pengujian API Lokal Ollama dengan Apidog
Apidog adalah alat pengujian API yang cocok dengan mode API Ollama. Ini memungkinkan Anda mengirim permintaan, melihat respons, dan melakukan debug pada pengaturan Qwen 3 Anda dengan efisien.
Berikut cara menggunakan Apidog dengan Ollama:
- Buat permintaan API baru:
- Endpoint:
http://localhost:11434/api/generate - Kirim permintaan dan pantau respons di timeline waktu nyata Apidog.
- Gunakan ekstraksi JSONPath Apidog untuk secara otomatis memparsing respons, fitur yang menonjol dibandingkan alat seperti Postman.


Streaming Respons:
- Untuk aplikasi waktu nyata, aktifkan streaming:
- Fitur Auto-Merge Apidog mengkonsolidasikan pesan yang di-stream, menyederhanakan debugging.
curl http://localhost:11434/api/generate -d '{"model": "gemma3:4b-it-qat", "prompt": "Tulis puisi tentang AI.", "stream": true}'

Proses ini memastikan model Anda berfungsi seperti yang diharapkan, menjadikan Apidog sebagai tambahan yang berharga.
Kesimpulan
Rilis keluarga model Qwen3 yang kuat dan beragam, dikombinasikan dengan alat eksekusi lokal yang matang seperti Ollama dan vLLM, menandai waktu yang menarik bagi praktisi AI. Apakah Anda memprioritaskan kesederhanaan plug-and-play dari Ollama untuk penggunaan pribadi dan eksperimen atau kemampuan penyajian berkinerja tinggi dari vLLM untuk membangun aplikasi yang kokoh, menjalankan LLM mutakhir secara lokal kini lebih memungkinkan daripada sebelumnya.
Dengan membawa model seperti Qwen3-30B-A3B atau bahkan varian padat yang lebih besar ke perangkat keras Anda sendiri, Anda mendapatkan kontrol, privasi, dan efisiensi biaya yang belum pernah ada sebelumnya. Anda dapat memanfaatkan fitur canggih mereka, seperti berpikir hibrida dan dukungan multibahasa yang luas, untuk proyek-proyek inovatif. Seiring ekosistem perangkat keras dan perangkat lunak terus berkembang, kekuatan model bahasa besar akan semakin terdemokratisasi, berpindah dari server cloud yang jauh ke mesin lokal kita. Eksperimen dengan Qwen3 menggunakan Ollama dan vLLM untuk merasakan ujung tombak revolusi AI lokal ini.
Ingin platform terintegrasi All-in-One untuk Tim Pengembang Anda bekerja sama dengan produktivitas maksimum?
Apidog memenuhi semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!