
Menjalankan model bahasa besar seperti Mistral 3 di mesin lokal Anda menawarkan kontrol tak tertandingi kepada pengembang atas privasi data, kecepatan inferensi, dan kustomisasi. Seiring dengan semakin menuntutnya beban kerja AI, eksekusi lokal menjadi penting untuk membuat prototipe, menguji, dan menyebarkan aplikasi secara offline. Terlebih lagi, alat seperti Ollama menyederhanakan proses ini, memungkinkan Anda memanfaatkan kemampuan Mistral 3 langsung dari desktop atau server Anda.
Panduan ini membekali Anda dengan instruksi langkah demi langkah untuk menginstal dan menjalankan varian Mistral 3 secara lokal. Kami berfokus pada seri Ministral 3 sumber terbuka, yang sangat unggul dalam penerapan di perangkat ujung (edge deployments). Pada akhirnya, Anda akan mengoptimalkan kinerja untuk tugas-tugas dunia nyata, memastikan respons latensi rendah dan efisiensi sumber daya.
Memahami Mistral 3: Kekuatan Sumber Terbuka di AI
Mistral AI terus mendorong batas dengan rilis terbarunya: Mistral 3. Pengembang dan peneliti memuji keluarga model ini karena menyeimbangkan akurasi, efisiensi, dan aksesibilitas. Tidak seperti raksasa proprietari, Mistral 3 merangkul prinsip sumber terbuka, dirilis di bawah lisensi Apache 2.0. Langkah ini memberdayakan komunitas untuk memodifikasi, mendistribusikan, dan berinovasi tanpa batasan.
Pada intinya, Mistral 3 terdiri dari dua cabang utama: seri Ministral 3 yang ringkas dan Mistral Large 3 yang luas. Model Ministral 3—tersedia dalam ukuran parameter 3B, 8B, dan 14B—menargetkan lingkungan dengan sumber daya terbatas. Para insinyur merancang ini untuk kasus penggunaan lokal dan perangkat ujung, di mana setiap watt dan inti sangat berarti. Misalnya, varian 3B cocok dengan nyaman di laptop dengan GPU sederhana, sementara 14B mendorong batas pada pengaturan multi-GPU tanpa mengorbankan kecepatan.
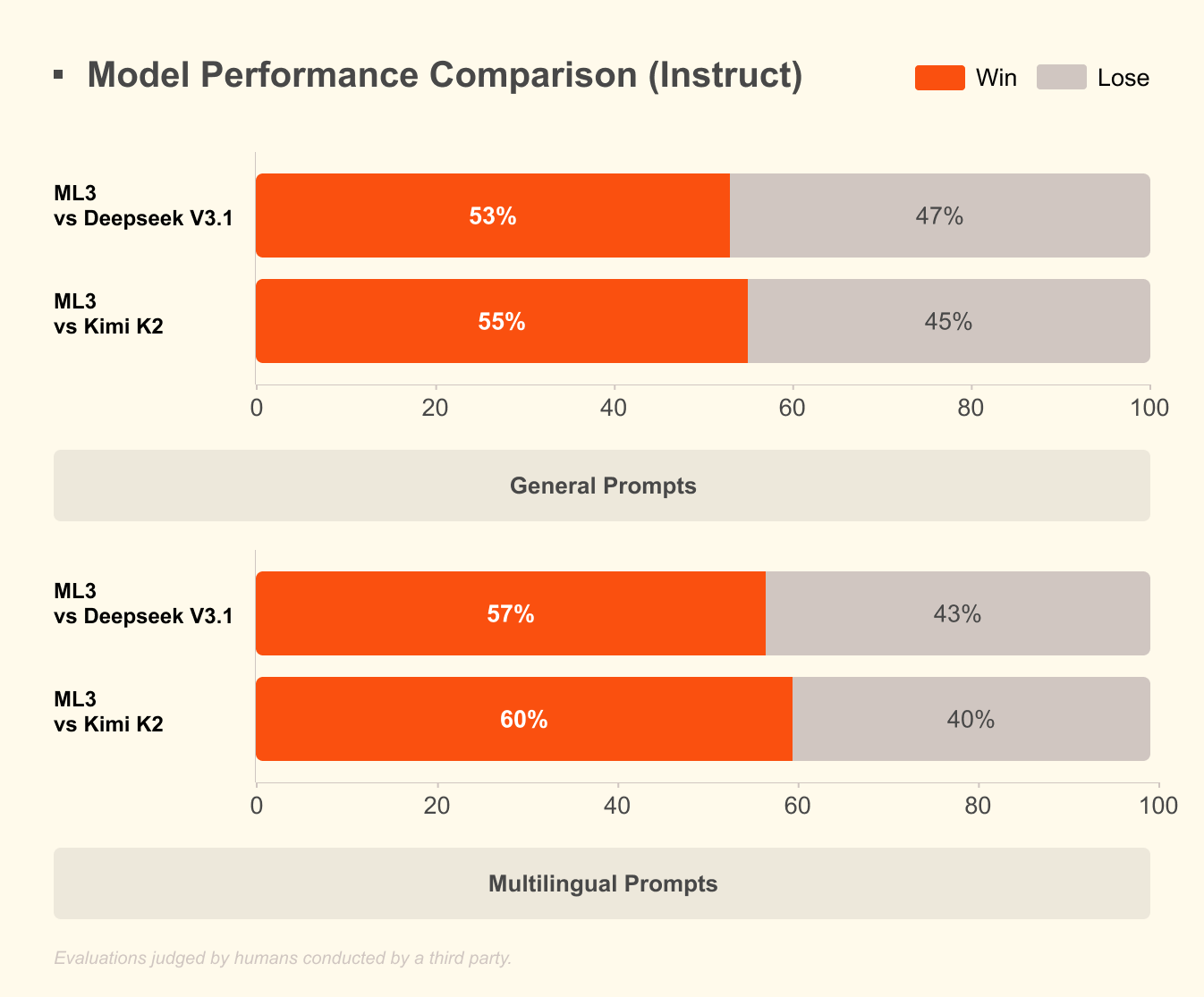
Mistral Large 3, di sisi lain, menggunakan arsitektur campuran-ahli (mixture-of-experts) jarang dengan 41B parameter aktif dan total 675B. Desain ini hanya mengaktifkan ahli yang relevan per kueri, mengurangi overhead komputasi. Pengembang mengakses versi yang disetel instruksi untuk tugas-tugas seperti bantuan pengodean, ringkasan dokumen, dan terjemahan multibahasa. Model ini mendukung lebih dari 40 bahasa secara native, mengungguli rekan-rekannya dalam dialog non-Bahasa Inggris.
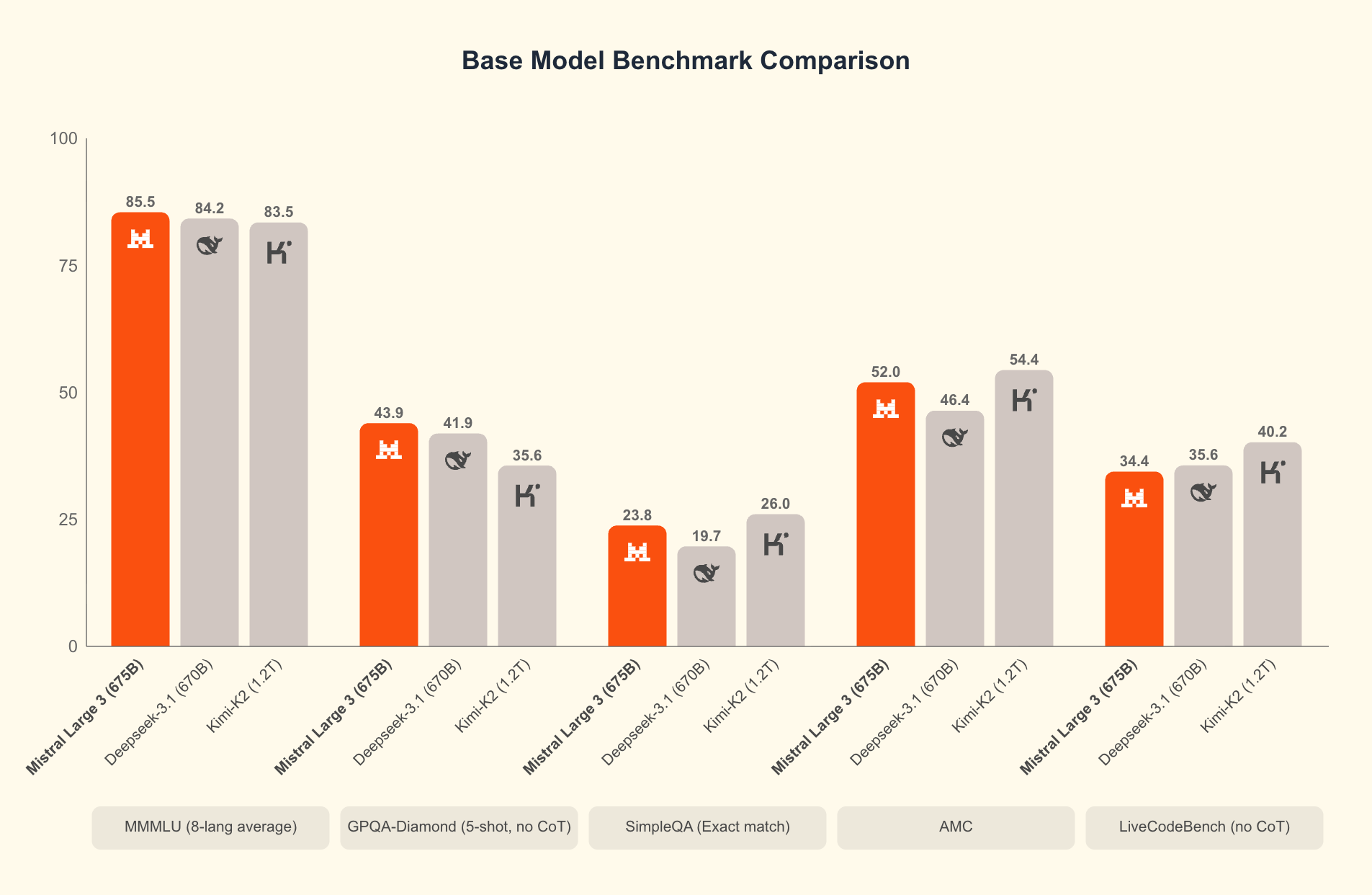
Apa yang membedakan Mistral 3? Tolok ukur mengungkapkan keunggulannya dalam skenario dunia nyata. Pada kumpulan data GPQA Diamond—uji ketat penalaran ilmiah—varian Mistral 3 mempertahankan akurasi tinggi bahkan saat token keluaran meningkat. Misalnya, model Ministral 3B Instruct mempertahankan akurasi sekitar 35-40% hingga 20.000 token, menyaingi model yang lebih besar seperti Gemma 2 9B sambil menggunakan lebih sedikit sumber daya. Efisiensi ini berasal dari teknik kuantisasi canggih, seperti kompresi NVFP4, yang mengurangi ukuran model tanpa menurunkan kualitas keluaran.
Selanjutnya, Mistral 3 mengintegrasikan fitur multimodal, memproses gambar bersama teks untuk aplikasi dalam menjawab pertanyaan visual atau pembuatan konten. Sumber terbuka model-model ini mendorong iterasi cepat; komunitas sudah menyempurnakannya untuk domain khusus seperti analisis hukum atau penulisan kreatif. Akibatnya, Mistral 3 mendemokratisasikan AI mutakhir, memungkinkan startup dan pengembang individu untuk bersaing dengan perusahaan teknologi besar.

Beralih dari teori ke praktik, menjalankan model-model ini secara lokal membuka potensi penuhnya. API cloud memperkenalkan latensi dan biaya, tetapi inferensi lokal memberikan respons di bawah satu detik. Selanjutnya, kita akan memeriksa prasyarat perangkat keras yang memungkinkan hal ini.
Mengapa Menjalankan Mistral 3 Secara Lokal? Manfaat bagi Pengembang dan Peningkatan Efisiensi
Pengembang memilih eksekusi lokal karena beberapa alasan yang kuat. Pertama, privasi adalah yang utama: data sensitif tetap ada di mesin Anda, menghindari server pihak ketiga. Dalam industri yang diatur seperti perawatan kesehatan atau keuangan, keunggulan kepatuhan ini terbukti sangat berharga. Kedua, penghematan biaya menumpuk dengan cepat. Efisiensi tinggi Mistral 3 berarti Anda menghindari biaya per token, ideal untuk pengujian volume tinggi.
Terlebih lagi, eksekusi lokal mempercepat eksperimen. Lakukan iterasi pada prompt, setel parameter secara halus (fine-tune hyperparameters), atau rangkai model tanpa penundaan jaringan. Tolok ukur mengkonfirmasi hal ini: pada perangkat keras konsumen, Ministral 8B mencapai 50-60 token per detik, sebanding dengan pengaturan cloud tetapi tanpa waktu henti.
Efisiensi mendefinisikan daya tarik Mistral 3. Model-model ini dioptimalkan untuk inferensi berbiaya rendah, seperti yang ditunjukkan dalam hasil GPQA Diamond di mana varian Ministral mengungguli Gemma 3 4B dan 12B dalam akurasi berkelanjutan. Ini penting untuk tugas-tugas konteks panjang; karena keluaran meluas hingga 20.000 token, akurasi hanya berkurang sedikit, memastikan kinerja yang andal dalam chatbot atau generator kode.
Selain itu, akses sumber terbuka melalui platform seperti Hugging Face memungkinkan integrasi tanpa batas dengan alat seperti Apidog untuk pembuatan prototipe API. Uji endpoint Mistral 3 secara lokal sebelum melakukan penskalaan, menjembatani kesenjangan antara pengembangan dan produksi.
Namun, keberhasilan bergantung pada pengaturan yang tepat. Dengan perangkat keras yang sudah ada, Anda dapat melanjutkan ke instalasi. Persiapan ini memastikan pengoperasian yang lancar dan memaksimalkan throughput.
Persyaratan Perangkat Keras dan Perangkat Lunak untuk Penyebaran Mistral 3 Lokal
Sebelum meluncurkan Mistral 3, nilai kemampuan sistem Anda. Spesifikasi minimum mencakup CPU modern (Intel i7 atau AMD Ryzen 7) dengan RAM 16GB untuk model 3B. Untuk varian 8B dan 14B, alokasikan RAM 32GB dan GPU NVIDIA dengan VRAM minimal 8GB—misalnya RTX 3060 atau lebih baik. Pengguna Apple Silicon mendapatkan keuntungan dari memori terpadu; M1 Pro dengan 16GB menangani 3B dengan mudah, sementara M3 Max unggul pada 14B.
Kebutuhan penyimpanan bervariasi: model 3B menempati sekitar 2GB terkuantisasi, meningkat menjadi sekitar 9GB untuk 14B. Gunakan SSD untuk pemuatan lebih cepat. Sistem operasi? Linux (Ubuntu 22.04) menawarkan kinerja terbaik, diikuti oleh macOS Ventura+. Windows 11 bekerja melalui WSL2, meskipun passthrough GPU memerlukan penyesuaian.
Dari segi perangkat lunak, Python 3.10+ menjadi tulang punggungnya. Instal CUDA 12.1 untuk kartu NVIDIA untuk mengaktifkan akselerasi GPU—penting untuk latensi di bawah 100ms. Untuk eksekusi hanya CPU, manfaatkan pustaka seperti ONNX Runtime.
Kuantisasi memainkan peran penting di sini. Mistral 3 mendukung format 4-bit dan 8-bit, mengurangi jejak memori sebesar 75% sambil mempertahankan akurasi 95%. Alat seperti bitsandbytes menangani ini secara otomatis.
Setelah dilengkapi, instalasi mengikuti jalur yang mudah. Kami merekomendasikan Ollama karena kesederhanaannya, tetapi ada alternatif. Pilihan ini merampingkan proses, membawa kita ke langkah-langkah pengaturan inti.
Menginstal Ollama: Gerbang Menuju AI Lokal Tanpa Usaha
Ollama menonjol sebagai alat utama untuk menjalankan model sumber terbuka seperti Mistral 3 secara lokal. Platform ringan ini mengabstraksi kompleksitas, menyediakan CLI dan server API dalam satu paket. Pengembang menghargai dukungan lintas platform dan deteksi GPU tanpa konfigurasi.
Mulailah dengan mengunduh Ollama dari situs resminya (ollama.com). Di Linux, jalankan:
curl -fsSL https://ollama.com/install.sh | sh
Skrip ini menginstal binari dan menyiapkan layanan. Verifikasi dengan ollama --version; harapkan keluaran seperti "ollama version 0.3.0". Untuk macOS, penginstal DMG menangani dependensi, termasuk Rosetta untuk emulasi Intel di ARM.
Pengguna Windows mengambil EXE dari rilis GitHub. Setelah instalasi, luncurkan melalui PowerShell: ollama serve. Ollama berjalan sebagai daemon di latar belakang, mengekspos REST API di port 11434.
Mengapa Ollama? Ini menarik model dari registrinya, termasuk Ministral 3, dengan kuantisasi bawaan. Tidak perlu kloning Hugging Face secara manual. Selain itu, ini mendukung Modelfiles untuk penyetelan halus kustom, sejalan dengan etos sumber terbuka Mistral 3.
Dengan Ollama siap, Anda selanjutnya menarik dan menjalankan model. Langkah ini mengubah pengaturan Anda menjadi stasiun kerja AI yang berfungsi.
Menarik dan Menjalankan Model Ministral 3 dengan Ollama
Pustaka Ollama menampung varian Ministral 3.
Mulailah dengan mencantumkan tag yang tersedia:
ollama list
Untuk mengunduh model 3B:
ollama pull ministral:3b-instruct-q4_0
Perintah ini mengambil sekitar 2GB, memverifikasi integritas melalui hash. Bilah kemajuan melacak unduhan, biasanya selesai dalam beberapa menit di koneksi broadband.
Luncurkan sesi interaktif:
ollama run ministral-3
Ollama memuat model ke dalam memori, menghangatkan cache untuk kueri berikutnya. Ketik prompt secara langsung; misalnya:
>> Jelaskan keterikatan kuantum (quantum entanglement) dengan istilah sederhana.

Model merespons secara real-time, memanfaatkan penyetelan instruksi untuk keluaran yang koheren. Keluar dengan /bye.
Memecahkan masalah umum? Jika terjadi pemanfaatan GPU yang kurang, atur variabel lingkungan OLLAMA_NUM_GPU=999. Untuk kesalahan OOM (Out Of Memory), turunkan ke kuantisasi yang lebih rendah seperti q3_K_M.
Di luar dasar-dasar, API Ollama memungkinkan akses terprogram. Lakukan kueri penyelesaian dengan Curl:
curl http://localhost:11434/api/generate -d '{
"model": "ministral:3b-instruct-q4_0",
"prompt": "Tulis fungsi Python untuk mengurutkan daftar.",
"stream": false
}'
Respons JSON ini mencakup teks yang dihasilkan, sempurna untuk diintegrasikan dengan Apidog selama pengembangan API.
Menjalankan model menandai permulaan; optimasi meningkatkan kinerja. Oleh karena itu, kita beralih ke teknik yang memeras setiap tetes efisiensi dari perangkat keras Anda.
Mengoptimalkan Inferensi Mistral 3: Kecepatan, Memori, dan Perimbangan Akurasi
Efisiensi mendefinisikan keberhasilan AI lokal. Desain Mistral 3 sangat menonjol di sini, tetapi penyesuaian akan memperkuat keuntungan. Mulailah dengan kuantisasi: Ollama secara default menggunakan Q4_0, menyeimbangkan ukuran dan fidelitas. Untuk sumber daya ultra-rendah, coba Q2_K—mengurangi separuh memori dengan biaya 10% perpleksitas.
Orkestrasi GPU itu penting. Aktifkan perhatian kilat (flash attention) melalui OLLAMA_FLASH_ATTENTION=1 untuk peningkatan kecepatan 2x pada konteks panjang. Mistral 3 mendukung hingga 128K token; uji dengan prompt gaya GPQA untuk memverifikasi akurasi berkelanjutan.
Pemrosesan batch meningkatkan throughput. Gunakan /api/generate Ollama dengan beberapa prompt secara paralel, memanfaatkan klien Python asinkron. Misalnya, buat skrip loop:
import requests
import json
model = "ministral:8b-instruct-q4_0"
url = "http://localhost:11434/api/generate"
prompts = ["Prompt 1", "Prompt 2"]
for p in prompts:
response = requests.post(url, json={"model": model, "prompt": p})
print(json.loads(response.text)["response"])
Ini menangani 10+ kueri per detik pada pengaturan multi-core.
Manajemen memori mencegah swap. Pantau dengan nvidia-smi; lepas muatan lapisan ke CPU jika VRAM penuh. Pustaka seperti vLLM terintegrasi dengan Ollama untuk batching berkelanjutan, mempertahankan 100 token/detik pada A100.
Penyetelan akurasi? Setel halus (fine-tune) dengan adaptor LoRA pada data domain. Pustaka PEFT Hugging Face menerapkannya ke Ministral 3, membutuhkan sekitar 1GB ruang tambahan. Setelah penyetelan halus, ekspor ke format Ollama melalui ollama create.
Bandingkan pengaturan Anda dengan GPQA Diamond. Buat skrip evaluasi untuk memplot akurasi vs. token, mencerminkan grafik Mistral. Varian efisiensi tinggi seperti Ministral 8B mempertahankan skor 50%+, menggarisbawahi keunggulan mereka dibandingkan Qwen 2.5 VL.
Optimisasi ini mempersiapkan Anda untuk aplikasi tingkat lanjut. Dengan demikian, kita menjelajahi integrasi yang memperluas jangkauan Mistral 3.
Mengintegrasikan Mistral 3 dengan Alat Pengembangan: API dan Selanjutnya
Mistral 3 lokal berkembang pesat dalam ekosistem. Pasangkan dengan Apidog untuk meniru API bertenaga AI. Rancang endpoint yang mengkueri Ollama, uji payload, dan validasi respons—semua secara offline.
Misalnya, buat rute POST /generate di Apidog, meneruskannya ke API Ollama. Impor koleksi untuk template prompt, memastikan Mistral 3 menangani permintaan multibahasa dengan sempurna.
Pengguna LangChain merangkai Mistral 3 dengan alat:
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
llm = OllamaLLM(model="ministral:3b-instruct-q4_0")
prompt = PromptTemplate.from_template("Terjemahkan {text} ke Bahasa Prancis.")
chain = prompt | llm
print(chain.invoke({"text": "Halo dunia"}))
Pengaturan ini memproses 50 kueri/menit, ideal untuk pipeline RAG.
Dasbor Streamlit memvisualisasikan keluaran. Sematkan panggilan Ollama dalam aplikasi untuk obrolan interaktif, memanfaatkan penalaran Mistral 3 untuk Tanya Jawab dinamis.
Pertimbangan keamanan? Jalankan Ollama di belakang proxy NGINX, membatasi laju endpoint. Untuk produksi, kontainerisasi dengan Docker:
FROM ollama/ollama
COPY Modelfile .
RUN ollama create mistral-local -f Modelfile
Ini mengisolasi lingkungan, menskalakan ke Kubernetes.
Seiring berkembangnya aplikasi, pemantauan menjadi kunci. Alat seperti Prometheus melacak latensi, memberi tahu tentang penyimpangan dari efisiensi dasar.
Singkatnya, integrasi ini mengubah Mistral 3 dari model mandiri menjadi mesin serbaguna. Namun, tantangan muncul; mengatasinya memastikan penyebaran yang kuat.
Memecahkan Masalah Umum dalam Eksekusi Mistral 3 Lokal
Bahkan pengaturan yang dioptimalkan pun menghadapi hambatan. Ketidakcocokan CUDA menduduki daftar teratas: verifikasi versi dengan nvcc --version. Turunkan versi jika terjadi konflik, karena Mistral 3 mentolerir 11.8+.
Pemuatan model gagal? Bersihkan cache Ollama: ollama rm ministral:3b-instruct-q4_0 lalu tarik ulang. Unduhan yang rusak berasal dari jaringan; gunakan --insecure sesekali.
Di macOS, akselerasi Metal tertinggal dari CUDA. Paksa CPU untuk stabilitas: OLLAMA_METAL=0. Pengguna WSL Windows mengaktifkan driver NVIDIA melalui wsl --update.
Overheating mengganggu laptop; batasi dengan nvidia-smi -pl 100 untuk membatasi daya. Untuk penurunan akurasi, periksa prompt—Ministral 3 unggul dalam format instruksi.
Forum komunitas di Reddit dan Hugging Face menyelesaikan 90% kasus tepi. Catat kesalahan dengan OLLAMA_DEBUG=1 untuk diagnostik.
Dengan rintangan yang diatasi, Mistral 3 memberikan nilai yang konsisten. Terakhir, kita merenungkan dampak yang lebih luas.
Kesimpulan: Manfaatkan Mistral 3 Secara Lokal untuk Inovasi AI Masa Depan
Mistral 3 mendefinisikan ulang AI sumber terbuka dengan perpaduan kekuatan dan kepraktisannya. Dengan menjalankannya secara lokal melalui Ollama, pengembang mendapatkan kecepatan, privasi, dan kontrol biaya yang tidak dapat dicapai di tempat lain. Dari menarik model hingga menyetel integrasi secara halus, panduan ini membekali Anda dengan langkah-langkah yang dapat ditindaklanjuti.
Bereksperimenlah dengan berani: mulailah dengan varian 3B, skalakan ke 14B, dan ukur terhadap tolok ukur. Seiring dengan iterasi Mistral AI, eksekusi lokal membuat Anda tetap unggul.
Siap membangun? Unduh Apidog secara gratis dan buat prototipe API yang ditenagai oleh pengaturan Mistral 3 Anda. Masa depan AI yang efisien dimulai di mesin Anda—manfaatkan sebaik-baiknya.