
Menjalankan Gemma 3 secara lokal dengan Ollama memberi Anda kendali penuh atas lingkungan AI Anda tanpa bergantung pada layanan cloud. Panduan ini memandu Anda melalui pengaturan Ollama, mengunduh Gemma 3, dan menjalankannya di mesin Anda.
Mari kita mulai.
Mengapa Menjalankan Gemma 3 Secara Lokal dengan Ollama?
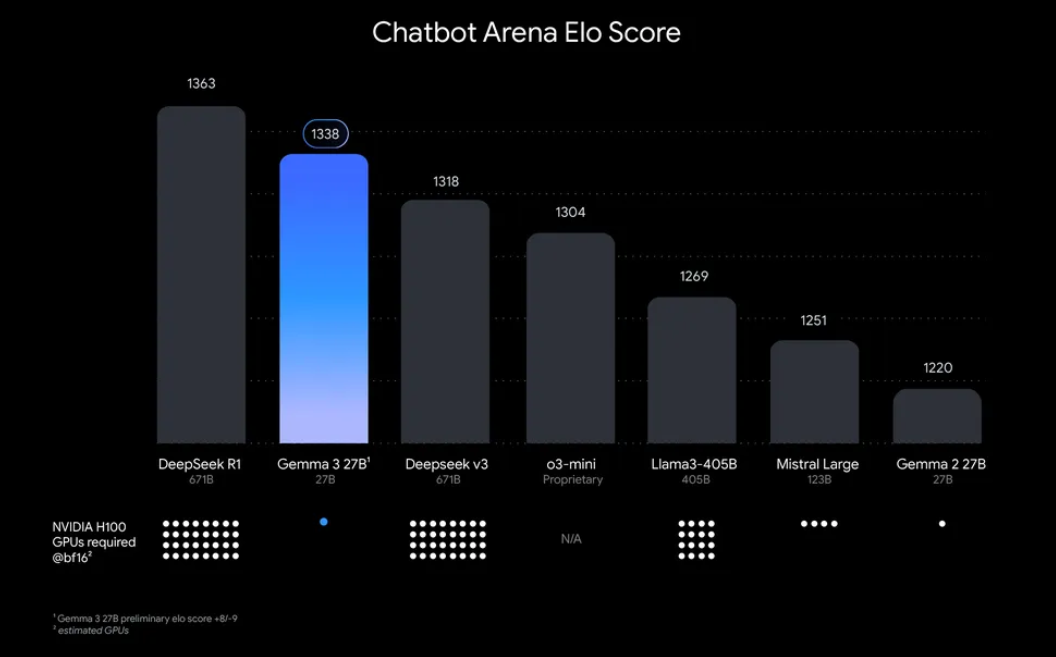
“Mengapa repot menjalankan Gemma 3 secara lokal?” Nah, ada beberapa alasan yang menarik. Salah satunya, penerapan lokal memberi Anda kendali penuh atas data dan privasi Anda tidak perlu mengirim informasi sensitif ke cloud. Selain itu, ini hemat biaya, karena Anda menghindari biaya penggunaan API yang berkelanjutan. Ditambah lagi, efisiensi Gemma 3 berarti bahkan model 27B dapat berjalan pada satu GPU, membuatnya dapat diakses oleh pengembang dengan perangkat keras yang sederhana.
Ollama, platform ringan untuk menjalankan model bahasa besar (LLM) secara lokal, menyederhanakan proses ini. Ini mengemas semua yang Anda butuhkan bobot model, konfigurasi, dan dependensi ke dalam format yang mudah digunakan. Kombinasi Gemma 3 dan Ollama ini sangat cocok untuk bereksperimen, membangun aplikasi, atau menguji alur kerja AI di mesin Anda. Jadi, mari kita singsingkan lengan baju dan mulai!
Apa yang Anda Butuhkan untuk Menjalankan Gemma 3 dengan Ollama
Sebelum kita masuk ke pengaturan, pastikan Anda memiliki prasyarat berikut:
- Mesin yang Kompatibel: Anda memerlukan komputer dengan GPU (sebaiknya NVIDIA untuk kinerja optimal) atau CPU yang kuat. Model 27B membutuhkan sumber daya yang signifikan, tetapi versi yang lebih kecil seperti 1B atau 4B dapat berjalan pada perangkat keras yang kurang kuat.
- Ollama Terpasang: Unduh dan pasang Ollama, tersedia untuk MacOS, Windows, dan Linux. Anda dapat mengambilnya dari ollama.com.
- Keterampilan Baris Perintah Dasar: Anda akan berinteraksi dengan Ollama melalui terminal atau command prompt.
- Koneksi Internet: Awalnya, Anda perlu mengunduh model Gemma 3, tetapi setelah diunduh, Anda dapat menjalankannya secara offline.
- Opsional: Apidog untuk Pengujian API: Jika Anda berencana untuk mengintegrasikan Gemma 3 dengan API atau menguji responsnya secara terprogram, antarmuka intuitif Apidog dapat menghemat waktu dan tenaga Anda.
Sekarang Anda sudah siap, mari kita selami proses instalasi dan pengaturan.
Panduan Langkah demi Langkah: Memasang Ollama dan Mengunduh Gemma 3
1. Pasang Ollama di Mesin Anda
Ollama membuat penerapan LLM lokal menjadi mudah, dan memasangnya sangat mudah. Begini caranya:
- Untuk MacOS/Windows: Kunjungi ollama.com dan unduh pemasang untuk sistem operasi Anda. Ikuti petunjuk di layar untuk menyelesaikan instalasi.
- Untuk Linux (misalnya, Ubuntu): Buka terminal Anda dan jalankan perintah berikut:
curl -fsSL https://ollama.com/install.sh | sh
Skrip ini secara otomatis mendeteksi perangkat keras Anda (termasuk GPU) dan memasang Ollama.
Setelah terpasang, verifikasi instalasi dengan menjalankan:
ollama --version

Anda akan melihat nomor versi saat ini, yang mengonfirmasi bahwa Ollama siap digunakan.
2. Tarik Model Gemma 3 Menggunakan Ollama
Pustaka model Ollama menyertakan Gemma 3, berkat integrasinya dengan platform seperti Hugging Face dan penawaran AI Google. Untuk mengunduh Gemma 3, gunakan perintah ollama pull.
ollama pull gemma3

Untuk model yang lebih kecil, Anda dapat menggunakan:
ollama pull gemma3:12bollama pull gemma3:4bollama pull gemma3:1b
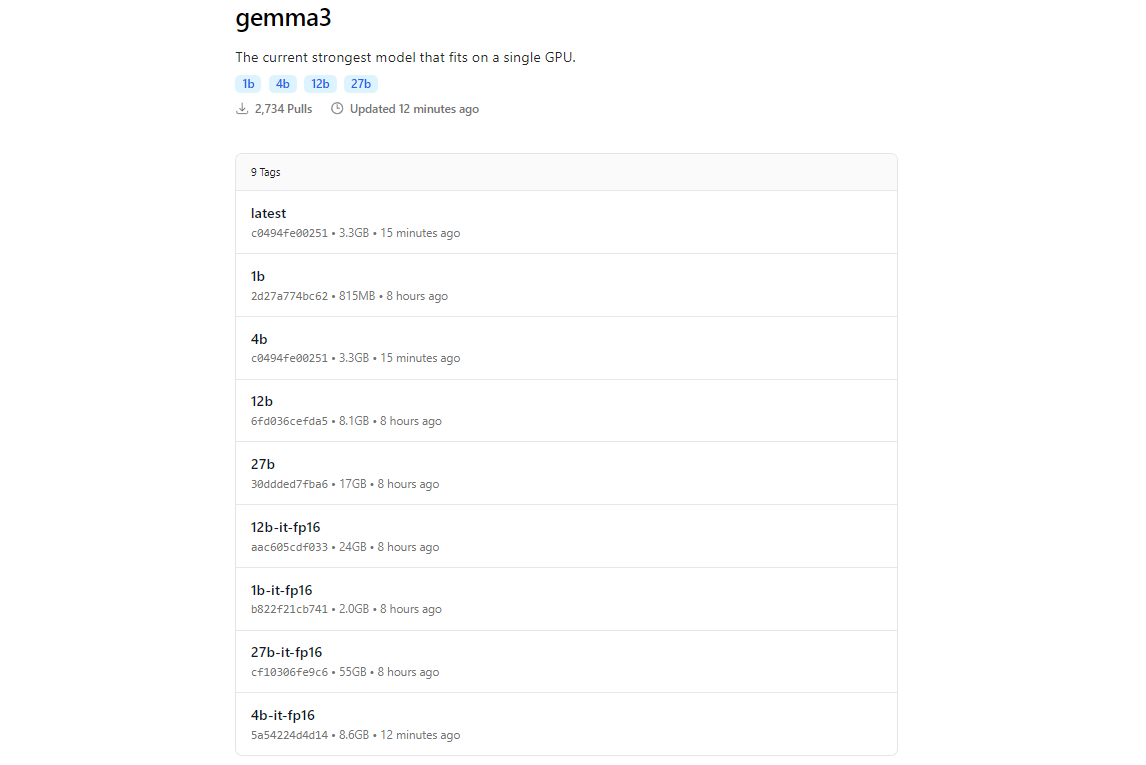
Ukuran unduhan bervariasi menurut model harapkan model 27B berukuran beberapa gigabyte, jadi pastikan Anda memiliki penyimpanan yang cukup. Model Gemma 3 dioptimalkan untuk efisiensi, tetapi mereka masih membutuhkan perangkat keras yang layak untuk varian yang lebih besar.
3. Verifikasi Instalasi
Setelah diunduh, periksa apakah model tersedia dengan mencantumkan semua model:
ollama list

Anda akan melihat gemma3 (atau ukuran yang Anda pilih) dalam daftar. Jika ada, Anda siap menjalankan Gemma 3 secara lokal!
Menjalankan Gemma 3 dengan Ollama: Mode Interaktif dan Integrasi API
Mode Interaktif: Mengobrol dengan Gemma 3
Mode interaktif Ollama memungkinkan Anda mengobrol dengan Gemma 3 langsung dari terminal. Untuk memulai, jalankan:
ollama run gemma3
Anda akan melihat prompt tempat Anda dapat mengetik kueri. Misalnya, coba:
What are the key features of Gemma 3?
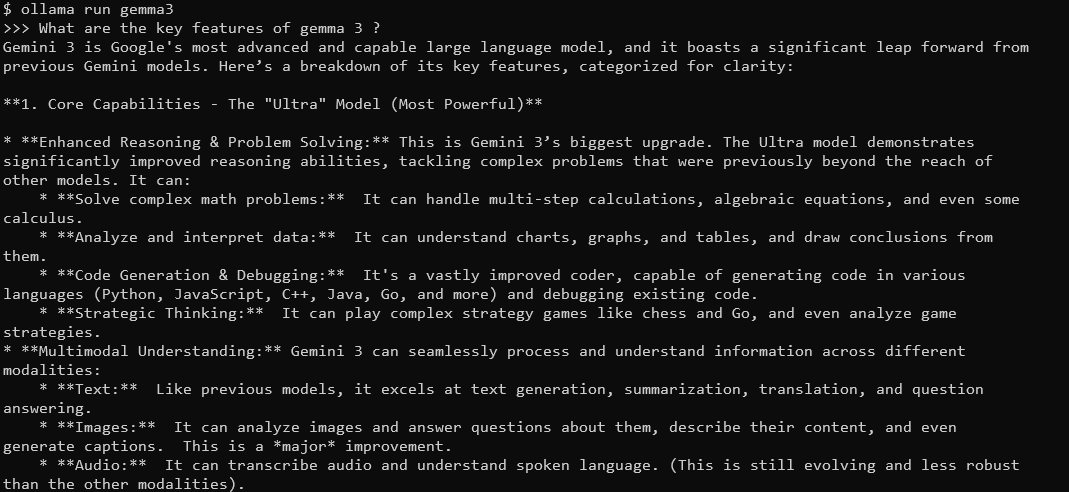
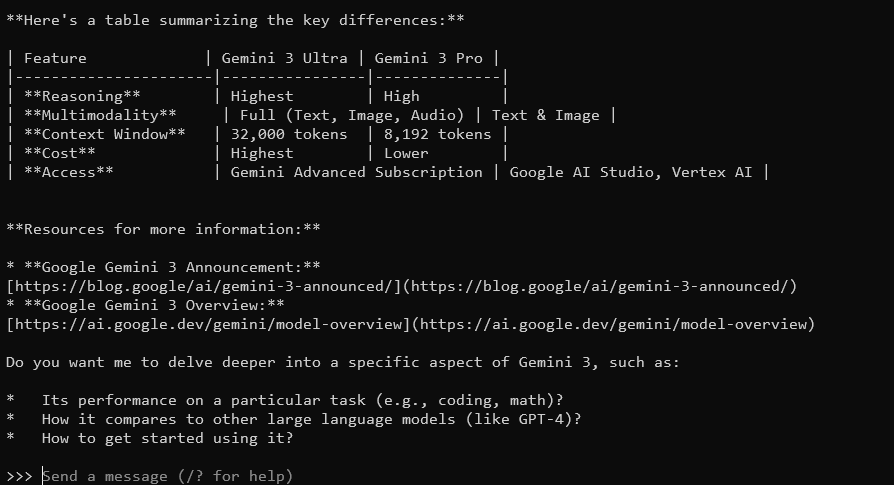
Gemma 3, dengan jendela konteks 128K dan kemampuan multimodal, akan merespons dengan jawaban yang detail dan sadar konteks. Ini mendukung lebih dari 140 bahasa dan dapat memproses teks, gambar, dan bahkan input video (untuk ukuran tertentu).
Untuk keluar, ketik Ctrl+D atau /bye.
Mengintegrasikan Gemma 3 dengan API Ollama
Jika Anda ingin membangun aplikasi atau mengotomatiskan interaksi, Ollama menyediakan API yang dapat Anda gunakan. Di sinilah Apidog bersinar antarmuka yang ramah pengguna membantu Anda menguji dan mengelola permintaan API secara efisien. Begini cara memulainya:
Mulai Server Ollama: Jalankan perintah berikut untuk meluncurkan server API Ollama:
ollama serve
Ini memulai server di localhost:11434 secara default.
Buat Permintaan API: Anda dapat berinteraksi dengan Gemma 3 melalui permintaan HTTP. Misalnya, gunakan curl untuk mengirim prompt:
curl http://localhost:11434/api/generate -d '{"model": "gemma3", "prompt": "What is the capital of France?"}'
Respons akan menyertakan output Gemma 3, diformat sebagai JSON.
Gunakan Apidog untuk Pengujian: Unduh Apidog secara gratis dan buat permintaan API untuk menguji respons Gemma 3. Antarmuka visual Apidog memungkinkan Anda memasukkan endpoint (http://localhost:11434/api/generate), mengatur payload JSON, dan menganalisis respons tanpa menulis kode yang kompleks. Ini sangat berguna untuk debugging dan mengoptimalkan integrasi Anda.
Panduan Langkah demi Langkah untuk Menggunakan Pengujian SSE di Apidog
Mari kita telusuri proses penggunaan fitur pengujian SSE yang dioptimalkan di Apidog, lengkap dengan peningkatan Auto-Merge yang baru. Ikuti langkah-langkah ini untuk menyiapkan dan memaksimalkan pengalaman debugging waktu nyata Anda.
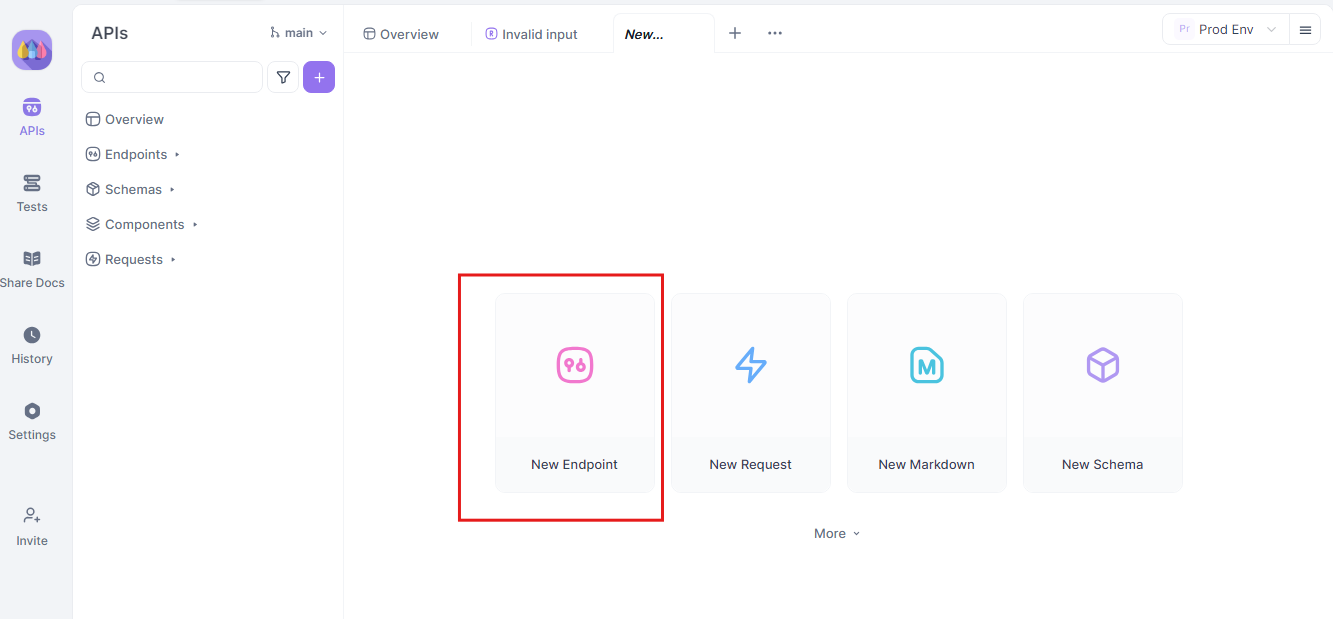
Langkah 1: Buat Permintaan API Baru
Mulailah dengan meluncurkan proyek HTTP baru di Apidog. Tambahkan endpoint baru dan masukkan URL untuk endpoint API atau model AI Anda. Ini adalah titik awal Anda untuk menguji dan men-debug aliran data waktu nyata Anda.
Langkah 2: Kirim Permintaan
Setelah endpoint Anda disiapkan, kirim permintaan API. Amati dengan cermat header respons. Jika header menyertakan Content-Type: text/event-stream, Apidog akan secara otomatis mengenali dan menafsirkan respons sebagai aliran SSE. Deteksi ini sangat penting untuk proses penggabungan otomatis berikutnya.

Langkah 3: Pantau Timeline Waktu Nyata
Setelah koneksi SSE dibuat, Apidog akan membuka tampilan timeline khusus tempat semua peristiwa SSE yang masuk ditampilkan secara waktu nyata. Timeline ini terus diperbarui saat data baru tiba, memungkinkan Anda memantau aliran data dengan presisi yang tepat. Timeline ini bukan hanya dump data mentah ini adalah visualisasi terstruktur dengan cermat yang membantu Anda melihat dengan tepat kapan dan bagaimana data ditransmisikan.
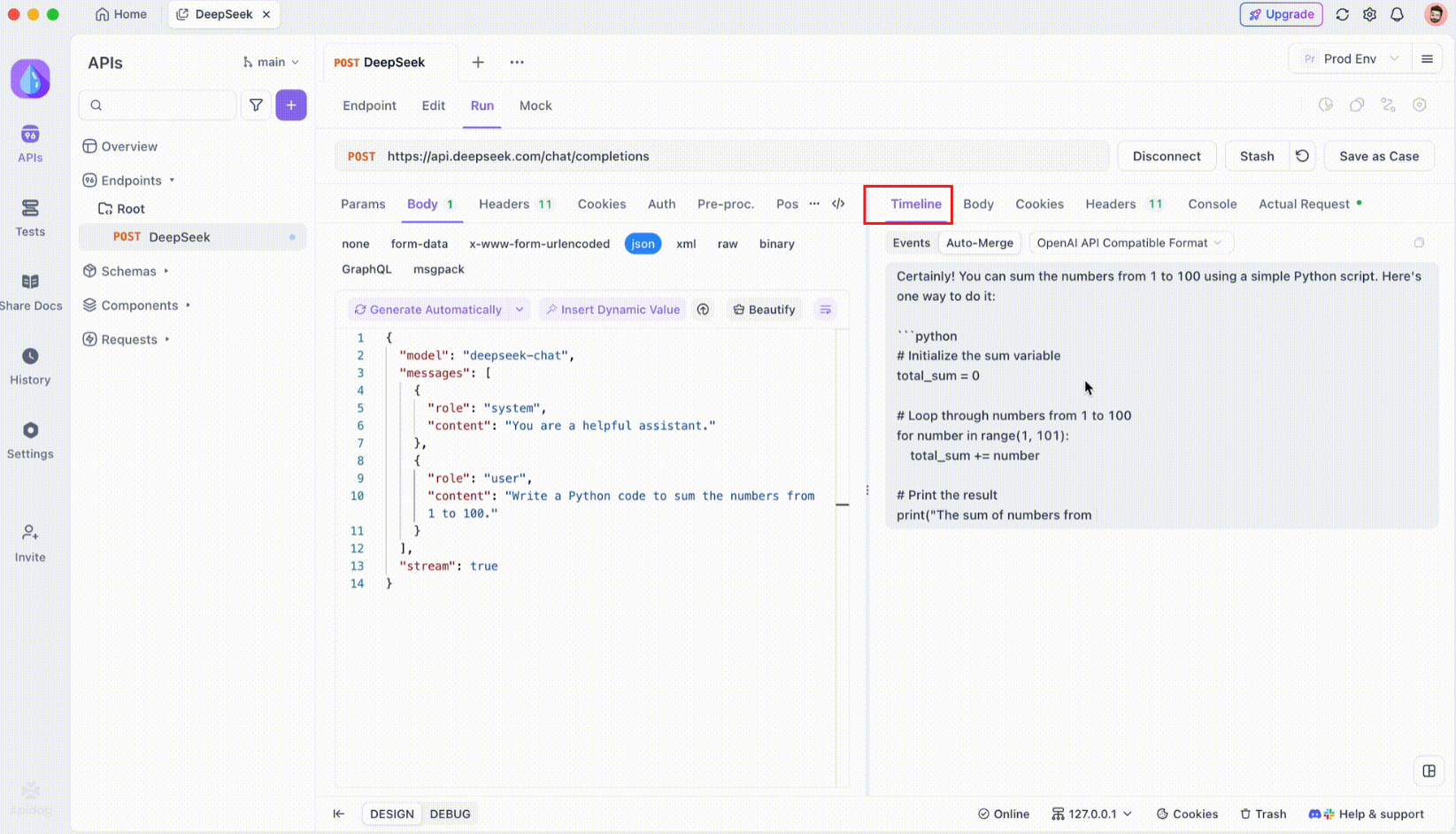
Langkah 4: Pesan Penggabungan Otomatis
Di sinilah keajaiban terjadi. Dengan peningkatan Auto-Merge, Apidog secara otomatis mengenali format model AI populer dan menggabungkan respons SSE yang terfragmentasi menjadi balasan lengkap. Langkah ini meliputi:
- Pengenalan Otomatis: Apidog memeriksa apakah respons dalam format yang didukung (OpenAI, Gemini, atau Claude).
- Penggabungan Pesan: Jika format dikenali, platform secara otomatis menggabungkan semua fragmen SSE, memberikan respons lengkap yang mulus.
- Visualisasi yang Ditingkatkan: Untuk model AI tertentu, seperti DeepSeek R1, timeline juga menampilkan proses pemikiran model, menawarkan lapisan wawasan tambahan ke dalam alasan di balik respons yang dihasilkan.
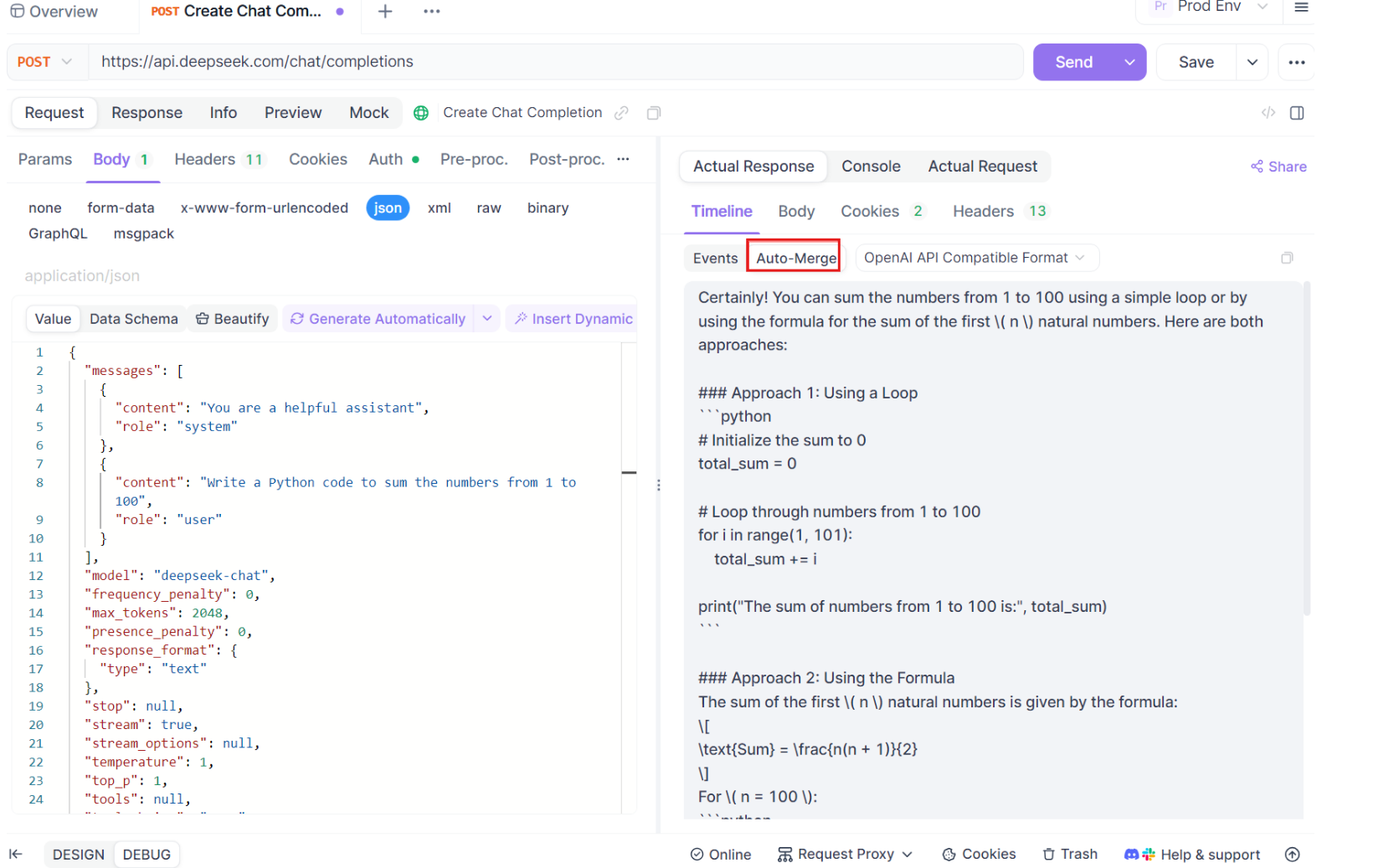
Fitur ini sangat berguna saat berhadapan dengan aplikasi berbasis AI, memastikan bahwa setiap bagian dari respons ditangkap dan disajikan secara utuh tanpa intervensi manual.
Langkah 5: Konfigurasikan Aturan Ekstraksi JSONPath
Tidak semua respons SSE akan secara otomatis sesuai dengan format bawaan. Saat berhadapan dengan respons JSON yang memerlukan ekstraksi khusus, Apidog memungkinkan Anda mengonfigurasi aturan JSONPath. Misalnya, jika respons SSE mentah Anda berisi objek JSON dan Anda perlu mengekstrak bidang content, Anda dapat menyiapkan konfigurasi JSONPath sebagai berikut:
- JSONPath:
$.choices[0].message.content - Penjelasan:
$mengacu pada akar objek JSON.choices[0]memilih elemen pertama dari arraychoices.message.contentmenentukan bidang konten di dalam objek pesan.
Konfigurasi ini menginstruksikan Apidog tentang cara mengekstrak data yang diinginkan dari respons SSE Anda, memastikan bahwa bahkan respons non-standar pun ditangani secara efektif.
Kesimpulan
Menjalankan Gemma 3 secara lokal dengan Ollama adalah cara yang menarik untuk memanfaatkan kemampuan AI canggih Google tanpa meninggalkan mesin Anda. Mulai dari memasang Ollama dan mengunduh model hingga berinteraksi melalui terminal atau API, panduan ini telah memandu Anda melalui setiap langkah. Dengan fitur multimodal, dukungan multibahasa, dan kinerja yang mengesankan, Gemma 3 adalah pengubah permainan bagi pengembang dan penggemar AI. Jangan lupa untuk memanfaatkan alat seperti Apidog untuk pengujian dan integrasi API yang mulus unduh secara gratis hari ini untuk meningkatkan proyek Gemma 3 Anda!
Baik Anda bereksperimen dengan model 1B di laptop atau mendorong batasan model 27B di rig GPU, Anda sekarang siap untuk menjelajahi kemungkinan-kemungkinannya. Selamat membuat kode, dan mari kita lihat hal-hal luar biasa apa yang Anda bangun dengan Gemma 3!


