
Jika Anda pernah berharap bisa mengajukan pertanyaan langsung ke PDF atau manual teknis, panduan ini cocok untuk Anda. Hari ini, kita akan membangun sistem Retrieval-Augmented Generation (RAG) menggunakan DeepSeek R1, pusat kekuatan penalaran sumber terbuka, dan Ollama, kerangka kerja ringan untuk menjalankan model AI lokal.
Siap Meningkatkan Pengujian API Anda? Jangan lupa untuk memeriksa Apidog! Apidog bertindak sebagai platform terpadu untuk membuat, mengelola, dan menjalankan pengujian dan server mock, memungkinkan Anda menentukan hambatan dan menjaga API Anda tetap andal.
Alih-alih menggunakan banyak alat atau menulis skrip yang ekstensif, Anda dapat mengotomatiskan bagian-bagian penting dari alur kerja Anda, mencapai pipeline CI/CD yang lancar, dan menghabiskan lebih banyak waktu untuk menyempurnakan fitur produk Anda.
Jika itu terdengar seperti sesuatu yang dapat menyederhanakan hidup Anda, coba Apidog!
Dalam postingan ini, kita akan menjelajahi bagaimana DeepSeek R1—model yang menyaingi o1 OpenAI dalam kinerja tetapi harganya 95% lebih murah—dapat meningkatkan sistem RAG Anda. Mari kita uraikan mengapa pengembang berbondong-bondong ke teknologi ini dan bagaimana Anda dapat membangun pipeline RAG Anda sendiri dengannya.
Berapa Biaya Sistem RAG Lokal Ini?
| Komponen | Biaya |
|---|---|
| DeepSeek R1 1.5B | Gratis |
| Ollama | Gratis |
| PC RAM 16GB | $0 |
Model 1.5B DeepSeek R1 bersinar di sini karena:
- Pengambilan terfokus: Hanya 3 potongan dokumen yang masuk ke setiap jawaban
- Prompting ketat: "Saya tidak tahu" mencegah halusinasi
- Eksekusi lokal: Latensi nol vs. API cloud
Apa yang Anda Butuhkan
Sebelum kita membuat kode, mari siapkan toolkit kita:
1. Ollama
Ollama memungkinkan Anda menjalankan model seperti DeepSeek R1 secara lokal.
- Unduh: https://ollama.com/
- Instal, lalu buka terminal Anda dan jalankan:
ollama run deepseek-r1 # Untuk model 7B (default)
2. Varian Model DeepSeek R1
DeepSeek R1 hadir dalam ukuran dari 1.5B hingga 671B parameter. Untuk demo ini, kita akan menggunakan model 1.5B—sempurna untuk RAG ringan:
ollama run deepseek-r1:1.5b
Tip pro: Model yang lebih besar seperti 70B menawarkan penalaran yang lebih baik tetapi membutuhkan lebih banyak RAM. Mulai dari yang kecil, lalu tingkatkan!

Membangun Pipeline RAG: Penjelasan Kode
Langkah 1: Impor Pustaka
Kita akan menggunakan:
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
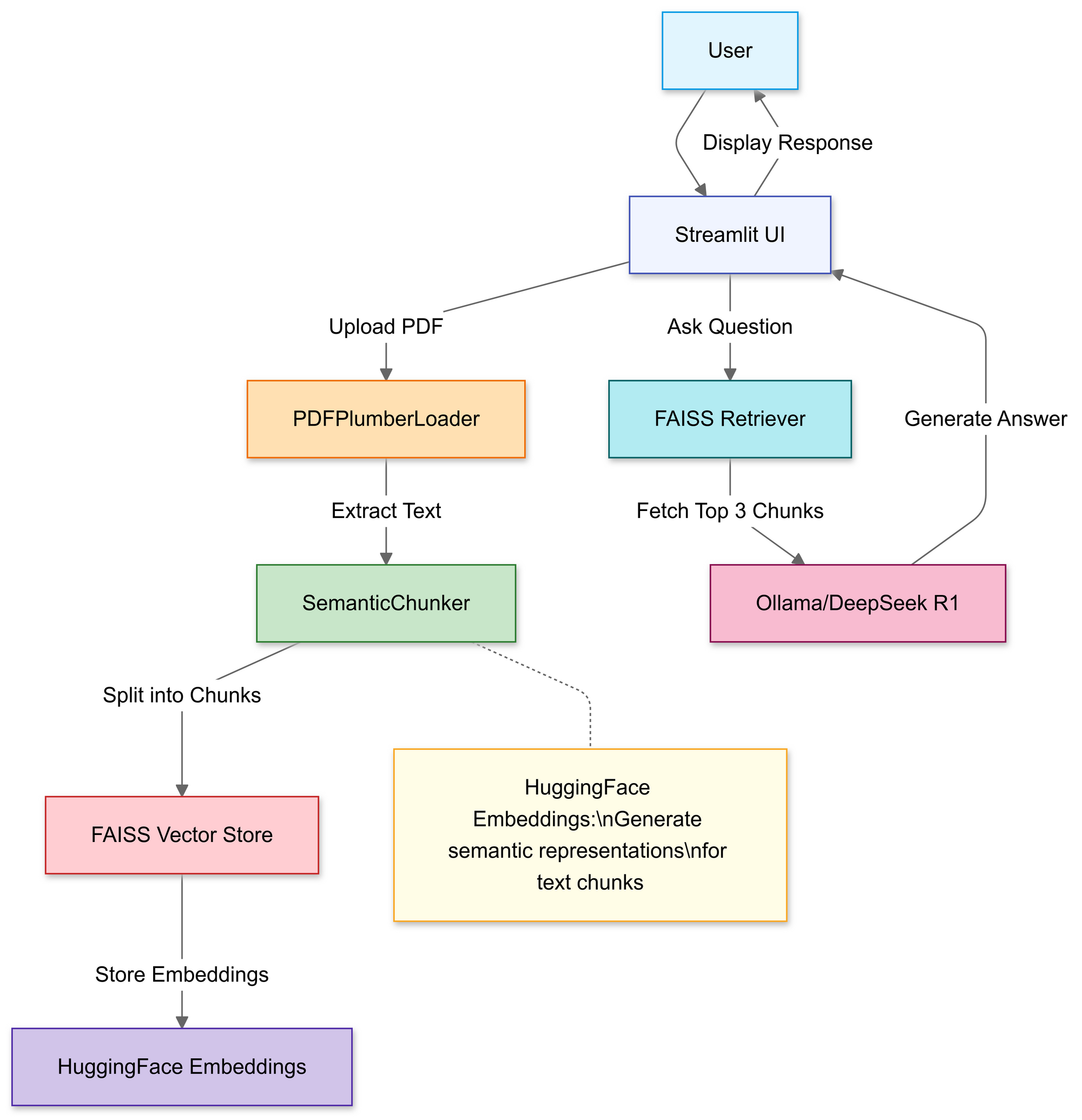
Langkah 2: Unggah & Proses PDF
Di bagian ini, Anda menggunakan pengunggah file Streamlit untuk memungkinkan pengguna memilih file PDF lokal.
# Pengunggah file Streamlit
uploaded_file = st.file_uploader("Unggah file PDF", type="pdf")
if uploaded_file:
# Simpan PDF sementara
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Muat teks PDF
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
Setelah diunggah, fungsi PDFPlumberLoader mengekstrak teks dari PDF, menyiapkannya untuk tahap selanjutnya dari pipeline. Pendekatan ini nyaman karena menangani pembacaan konten file tanpa memerlukan penguraian manual yang ekstensif.
Langkah 3: Potong Dokumen Secara Strategis
Kita ingin menggunakan RecursiveCharacterTextSplitter, kode memecah teks PDF asli menjadi segmen yang lebih kecil (potongan). Mari kita jelaskan konsep potongan yang baik vs potongan yang buruk di sini:
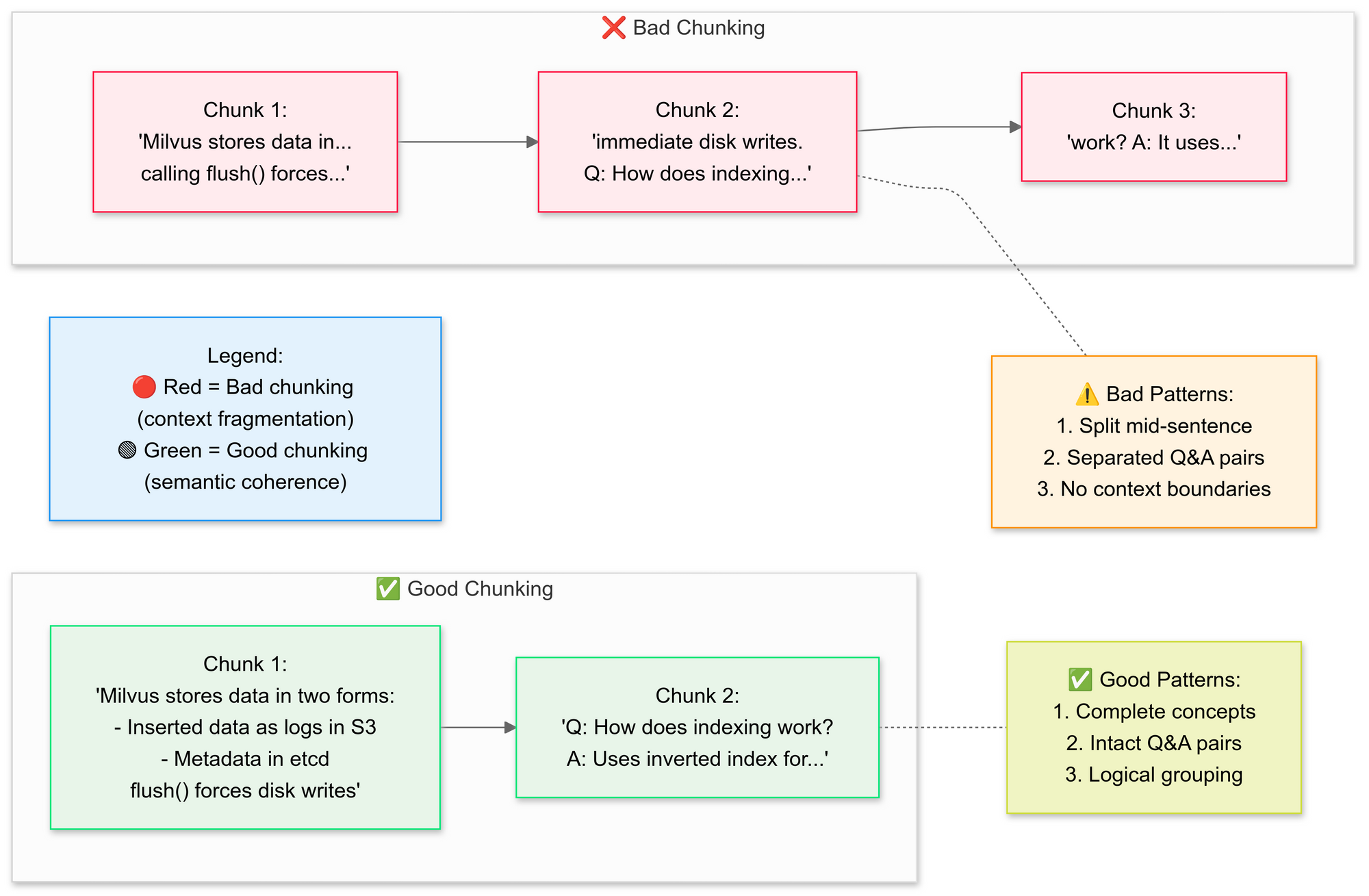
Mengapa potongan semantik?
- Mengelompokkan kalimat terkait (misalnya, "Bagaimana Milvus menyimpan data" tetap utuh)
- Menghindari pemisahan tabel atau diagram
# Pisahkan teks menjadi potongan semantik
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
Langkah ini mempertahankan konteks dengan sedikit tumpang tindih segmen, yang membantu model bahasa menjawab pertanyaan dengan lebih akurat. Potongan dokumen yang kecil dan terdefinisi dengan baik juga membuat pencarian lebih efisien dan relevan.
Langkah 4: Buat Basis Pengetahuan yang Dapat Dicari
Setelah pemisahan, pipeline menghasilkan penyematan vektor untuk segmen dan menyimpannya dalam indeks FAISS.
# Hasilkan penyematan
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# Hubungkan pengambil
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Ambil 3 potongan teratas
Ini mengubah teks menjadi representasi numerik yang jauh lebih mudah untuk dikueri. Kueri kemudian dijalankan terhadap indeks ini untuk menemukan potongan yang paling relevan secara kontekstual.
Langkah 5: Konfigurasikan DeepSeek R1
Di sini, Anda membuat rantai RetrievalQA menggunakan Deepseek R1 1.5B sebagai LLM lokal.
llm = Ollama(model="deepseek-r1:1.5b") # Model parameter 1.5B kami
# Buat templat prompt
prompt = """
1. Gunakan HANYA konteks di bawah ini.
2. Jika tidak yakin, katakan "Saya tidak tahu".
3. Jaga agar jawaban di bawah 4 kalimat.
Konteks: {context}
Pertanyaan: {question}
Jawaban:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
Templat ini memaksa model untuk mendasarkan jawaban pada konten PDF Anda. Dengan membungkus model bahasa dengan pengambil yang terikat pada indeks FAISS, setiap kueri yang dibuat melalui rantai akan mencari konteks dari konten PDF, membuat jawaban didasarkan pada materi sumber.
Langkah 6: Kumpulkan Rantai RAG
Selanjutnya, Anda dapat mengikat bersama langkah-langkah pengunggahan, pemotongan, dan pengambilan ke dalam pipeline yang koheren.
# Rantai 1: Hasilkan jawaban
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Rantai 2: Gabungkan potongan dokumen
document_prompt = PromptTemplate(
template="Konteks:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
# Pipeline RAG akhir
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
Ini adalah inti dari desain RAG (Retrieval-Augmented Generation), menyediakan model bahasa besar dengan konteks terverifikasi alih-alih membiarkannya bergantung murni pada pelatihan internalnya.
Langkah 7: Luncurkan Antarmuka Web
Akhirnya, kode menggunakan input teks dan fungsi tulis Streamlit sehingga pengguna dapat mengetik pertanyaan dan melihat respons dengan segera.
# UI Streamlit
user_input = st.text_input("Ajukan pertanyaan ke PDF Anda:")
if user_input:
with st.spinner("Berpikir..."):
response = qa(user_input)["result"]
st.write(response)
Segera setelah pengguna memasukkan kueri, rantai mengambil potongan yang paling cocok, memasukkannya ke dalam model bahasa, dan menampilkan jawaban. Dengan pustaka langchain yang terinstal dengan benar, kode sekarang harus berfungsi tanpa memicu kesalahan modul yang hilang.
Ajukan dan kirim pertanyaan dan dapatkan jawaban instan!
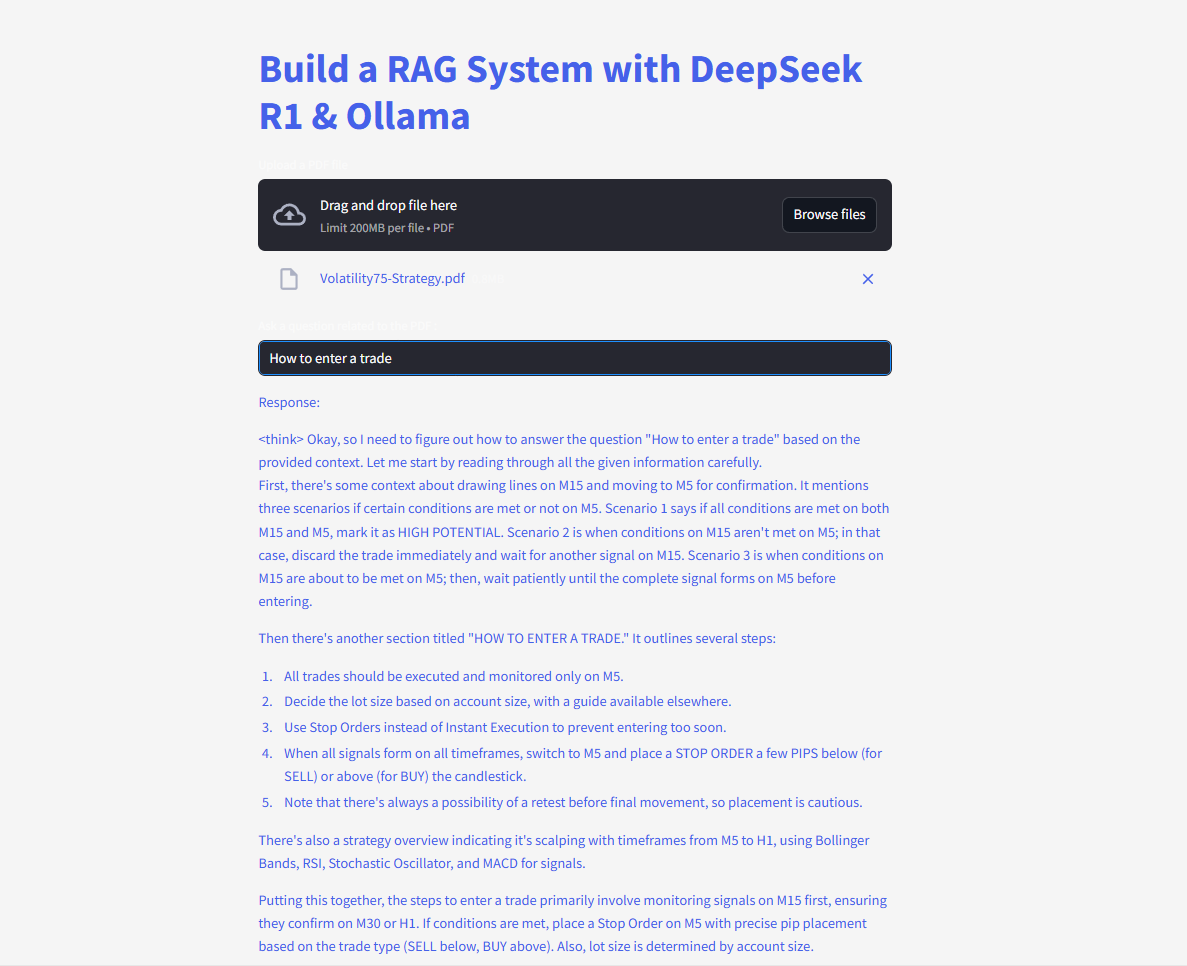
Berikut kode lengkapnya:
Masa Depan RAG dengan DeepSeek
Dengan fitur-fitur seperti verifikasi diri dan penalaran multi-hop dalam pengembangan, DeepSeek R1 siap untuk membuka aplikasi RAG yang lebih canggih. Bayangkan AI yang tidak hanya menjawab pertanyaan tetapi memperdebatkan logikanya sendiri—secara otonom.


