
Model bahasa besar (LLM) seperti Qwen3 merevolusi lanskap AI dengan kemampuan mengesankan dalam pengkodean, penalaran, dan pemahaman bahasa alami. Dikembangkan oleh tim Qwen di Alibaba, Qwen3 menawarkan model terkuantisasi yang memungkinkan penerapan lokal yang efisien, membuatnya dapat diakses oleh pengembang, peneliti, dan penggemar untuk menjalankan model canggih ini di perangkat keras mereka sendiri. Baik Anda menggunakan Ollama, LM Studio, atau vLLM, panduan ini akan memandu Anda melalui proses pengaturan dan menjalankan model terkuantisasi Qwen3 secara lokal.
Dalam panduan teknis ini, kita akan menjelajahi proses pengaturan, pemilihan model, metode penerapan, dan integrasi API. Mari kita mulai.
Apa Itu Model Terkuantisasi Qwen3?
Qwen3 adalah generasi terbaru LLM dari Alibaba, dirancang untuk kinerja tinggi di berbagai tugas seperti pengkodean, matematika, dan penalaran umum. Model terkuantisasi, seperti yang dalam format BF16, FP8, GGUF, AWQ, dan GPTQ, mengurangi kebutuhan komputasi dan memori, menjadikannya ideal untuk penerapan lokal pada perangkat keras kelas konsumen.
Keluarga Qwen3 mencakup berbagai model:
- Qwen3-235B-A22B (MoE): Model mixture-of-experts dengan format BF16, FP8, GGUF, dan GPTQ-int4.
- Qwen3-30B-A3B (MoE): Varian MoE lainnya dengan opsi kuantisasi serupa.
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense): Model dense tersedia dalam format BF16, FP8, GGUF, AWQ, dan GPTQ-int8.
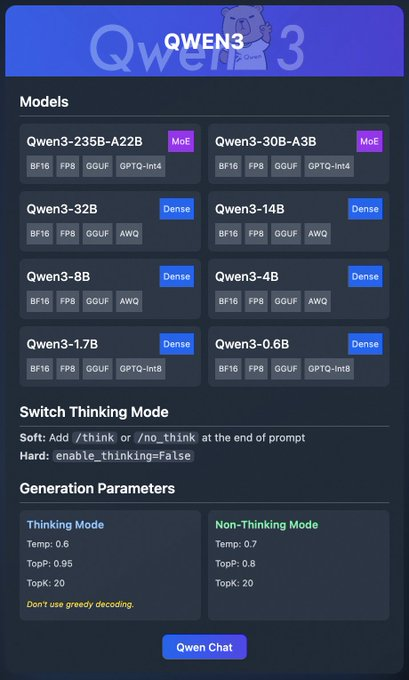
Model-model ini mendukung penerapan fleksibel melalui platform seperti Ollama, LM Studio, dan vLLM, yang akan kita bahas secara rinci. Selain itu, Qwen3 menawarkan fitur seperti "thinking mode," yang dapat diaktifkan untuk penalaran yang lebih baik, dan parameter generasi untuk menyempurnakan kualitas output.
Sekarang kita memahami dasar-dasarnya, mari kita lanjutkan ke prasyarat untuk menjalankan Qwen3 secara lokal.
Prasyarat untuk Menjalankan Qwen3 Secara Lokal
Sebelum menerapkan model terkuantisasi Qwen3, pastikan sistem Anda memenuhi persyaratan berikut:
Perangkat Keras:
- CPU atau GPU modern (GPU NVIDIA direkomendasikan untuk vLLM).
- Setidaknya 16GB RAM untuk model yang lebih kecil seperti Qwen3-4B; 32GB atau lebih untuk model yang lebih besar seperti Qwen3-32B.
- Penyimpanan yang cukup (misalnya, Qwen3-235B-A22B GGUF mungkin memerlukan ~150GB).
Perangkat Lunak:
- Sistem operasi yang kompatibel (Windows, macOS, atau Linux).
- Python 3.8+ untuk vLLM dan interaksi API.
- Docker (opsional, untuk vLLM).
- Git untuk mengkloning repositori.
Dependensi:
- Instal pustaka yang diperlukan seperti
torch,transformers, danvllm(untuk vLLM). - Unduh biner Ollama atau LM Studio dari situs web resmi mereka.
Dengan prasyarat ini, mari kita lanjutkan untuk mengunduh model terkuantisasi Qwen3.
Langkah 1: Unduh Model Terkuantisasi Qwen3
Pertama, Anda perlu mengunduh model terkuantisasi dari sumber terpercaya. Tim Qwen menyediakan model Qwen3 di Hugging Face dan ModelScope
- Hugging Face: Koleksi Qwen3
- ModelScope: Koleksi Qwen3
Cara Mengunduh dari Hugging Face
- Kunjungi koleksi Hugging Face Qwen3.
- Pilih model, seperti Qwen3-4B dalam format GGUF untuk penerapan ringan.
- Klik tombol "Download" atau gunakan perintah
git cloneuntuk mengambil file model:
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- Simpan file model dalam direktori, seperti
/models/qwen3-4b-gguf.
Cara Mengunduh dari ModelScope
- Navigasi ke koleksi ModelScope Qwen3.
- Pilih model dan format kuantisasi yang Anda inginkan (misalnya, AWQ atau GPTQ).
- Unduh file secara manual atau gunakan API mereka untuk akses terprogram.
Setelah model diunduh, mari kita jelajahi cara menerapkannya menggunakan Ollama.
Langkah 2: Terapkan Qwen3 Menggunakan Ollama
Ollama menyediakan cara yang ramah pengguna untuk menjalankan LLM secara lokal dengan pengaturan minimal. Ini mendukung format GGUF Qwen3, menjadikannya ideal untuk pemula.
Instal Ollama
- Kunjungi situs web resmi Ollama dan unduh biner untuk sistem operasi Anda.
- Instal Ollama dengan menjalankan penginstal atau mengikuti instruksi baris perintah:
curl -fsSL https://ollama.com/install.sh | sh
- Verifikasi instalasi:
ollama --version
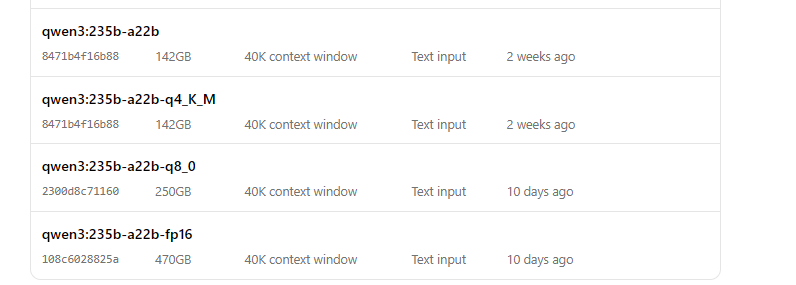
Jalankan Qwen3 dengan Ollama
- Mulai model:
ollama run qwen3:235b-a22b-q8_0- Setelah model berjalan, Anda dapat berinteraksi dengannya melalui baris perintah:
>>> Halo, bagaimana saya bisa membantu Anda hari ini?
Ollama juga menyediakan titik akhir API lokal (biasanya http://localhost:11434) untuk akses terprogram, yang akan kita uji nanti menggunakan Apidog.
Selanjutnya, mari kita jelajahi cara menggunakan LM Studio untuk menjalankan Qwen3.
Langkah 3: Terapkan Qwen3 Menggunakan LM Studio
LM Studio adalah alat populer lainnya untuk menjalankan LLM secara lokal, menawarkan antarmuka grafis untuk manajemen model.
Instal LM Studio
- Unduh LM Studio dari situs web resminya.
- Instal aplikasi dengan mengikuti instruksi di layar.
- Luncurkan LM Studio dan pastikan aplikasi berjalan.
Muat Qwen3 di LM Studio
Di LM Studio, buka bagian "Local Models".
Klik "Add Model" dan cari model untuk mengunduhnya:
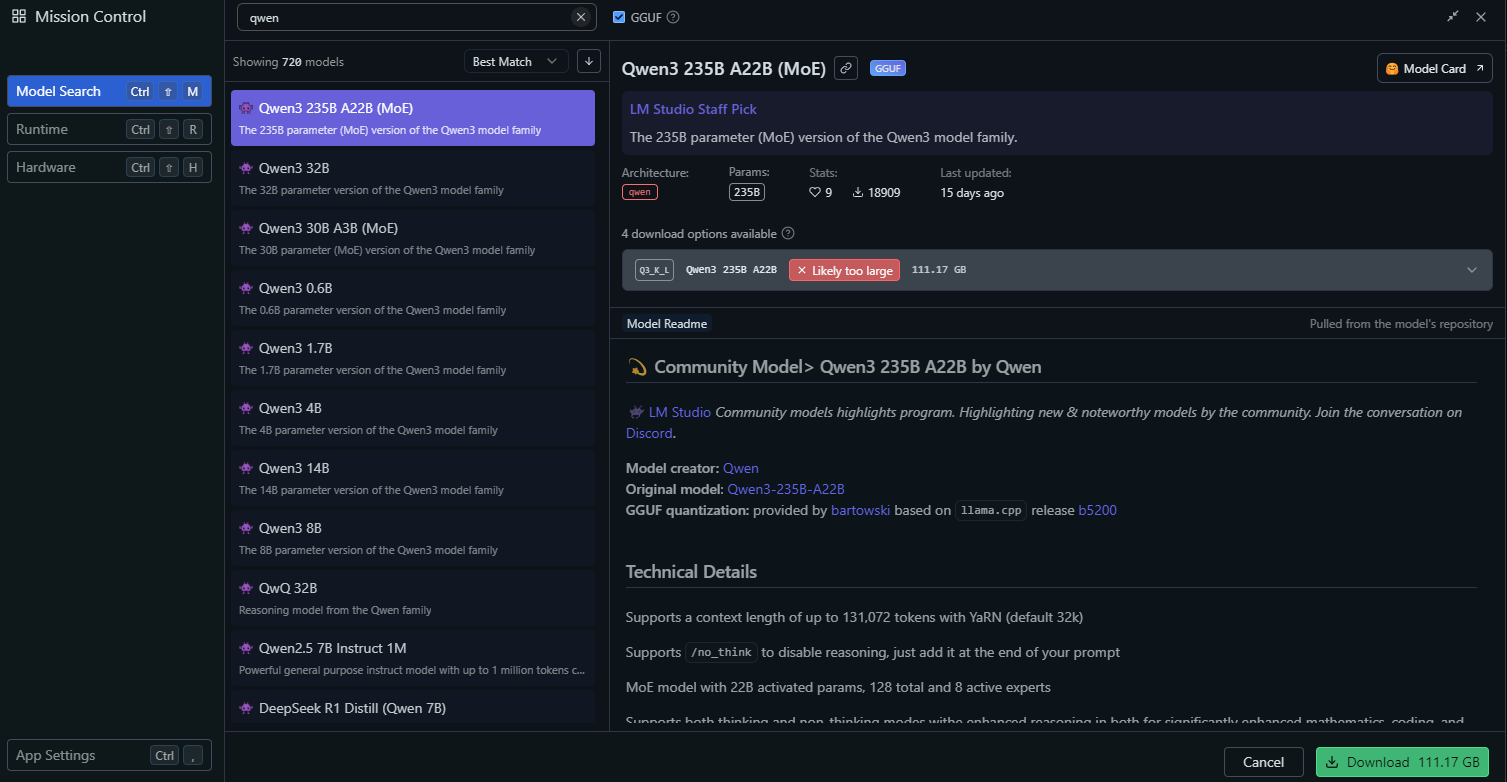
Konfigurasi pengaturan model, seperti:
- Temperature: 0.6
- Top-P: 0.95
- Top-K: 20
Pengaturan ini cocok dengan parameter thinking mode yang direkomendasikan Qwen3.
Mulai server model dengan mengklik "Start Server." LM Studio akan menyediakan titik akhir API lokal (misalnya, http://localhost:1234).
Berinteraksi dengan Qwen3 di LM Studio
- Gunakan antarmuka obrolan bawaan LM Studio untuk menguji model.
- Atau, akses model melalui titik akhir API-nya, yang akan kita jelajahi di bagian pengujian API.
Dengan LM Studio yang sudah diatur, mari kita lanjutkan ke metode penerapan yang lebih canggih menggunakan vLLM.
Langkah 4: Terapkan Qwen3 Menggunakan vLLM
vLLM adalah solusi penyajian berkinerja tinggi yang dioptimalkan untuk LLM, mendukung model terkuantisasi FP8 dan AWQ Qwen3. Ini ideal untuk pengembang yang membangun aplikasi yang kuat.
Instal vLLM
- Pastikan Python 3.8+ terinstal di sistem Anda.
- Instal vLLM menggunakan pip:
pip install vllm
- Verifikasi instalasi:
python -c "import vllm; print(vllm.__version__)"
Jalankan Qwen3 dengan vLLM
Mulai server vLLM dengan model Qwen3 Anda
# Muat dan jalankan model:
vllm serve "Qwen/Qwen3-235B-A22B"Flag --enable-thinking=False menonaktifkan thinking mode Qwen3.
Setelah server dimulai, server akan menyediakan titik akhir API di http://localhost:8000.
Konfigurasi vLLM untuk Kinerja Optimal
vLLM mendukung konfigurasi lanjutan, seperti:
- Tensor Parallelism: Sesuaikan
--tensor-parallel-sizeberdasarkan pengaturan GPU Anda. - Context Length: Qwen3 mendukung hingga 32.768 token, yang dapat diatur melalui
--max-model-len 32768. - Generation Parameters: Gunakan API untuk mengatur
temperature,top_p, dantop_k(misalnya, 0.7, 0.8, 20 untuk mode non-thinking).
Dengan vLLM berjalan, mari kita uji titik akhir API menggunakan Apidog.
Langkah 5: Uji API Qwen3 dengan Apidog
Apidog adalah alat canggih untuk menguji titik akhir API, menjadikannya sempurna untuk berinteraksi dengan model Qwen3 yang Anda terapkan secara lokal.
Siapkan Apidog
- Unduh dan instal Apidog dari situs web resmi.
- Luncurkan Apidog dan buat proyek baru.
Uji API Ollama
- Buat permintaan API baru di Apidog.
- Atur titik akhir ke
http://localhost:11434/api/generate. - Konfigurasi permintaan:
- Method: POST
- Body (JSON):
{
"model": "qwen3-4b",
"prompt": "Halo, bagaimana saya bisa membantu Anda hari ini?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- Kirim permintaan dan verifikasi respons.
Uji API vLLM
- Buat permintaan API lain di Apidog.
- Atur titik akhir ke
http://localhost:8000/v1/completions. - Konfigurasi permintaan:
- Method: POST
- Body (JSON):
{
"model": "qwen3-4b-awq",
"prompt": "Tulis skrip Python untuk menghitung faktorial.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- Kirim permintaan dan periksa output.
Apidog memudahkan validasi penerapan Qwen3 Anda dan memastikan API berfungsi dengan benar. Sekarang, mari kita menyempurnakan kinerja model.
Langkah 6: Menyempurnakan Kinerja Qwen3
Untuk mengoptimalkan kinerja Qwen3, sesuaikan pengaturan berikut berdasarkan kasus penggunaan Anda:
Thinking Mode
Qwen3 mendukung "thinking mode" untuk penalaran yang ditingkatkan, seperti yang disorot dalam gambar posting X. Anda dapat mengontrolnya dengan dua cara:
- Soft Switch: Tambahkan
/thinkatau/no_thinkke prompt Anda.
- Contoh:
Selesaikan soal matematika ini /think.
- Hard Switch: Nonaktifkan thinking mode sepenuhnya di vLLM dengan
--enable-thinking=False.
Parameter Generasi
Sempurnakan parameter generasi untuk kualitas output yang lebih baik:
- Temperature: Gunakan 0.6 untuk thinking mode atau 0.7 untuk mode non-thinking.
- Top-P: Atur ke 0.95 (thinking) atau 0.8 (non-thinking).
- Top-K: Gunakan 20 untuk kedua mode.
- Hindari greedy decoding, seperti yang direkomendasikan oleh tim Qwen.
Bereksperimenlah dengan pengaturan ini untuk mencapai keseimbangan yang diinginkan antara kreativitas dan akurasi.
Pemecahan Masalah Umum
Saat menerapkan Qwen3, Anda mungkin mengalami beberapa masalah. Berikut adalah solusi untuk masalah umum:
Model Gagal Dimuat di Ollama:
- Pastikan jalur file GGUF di
Modelfilesudah benar. - Periksa apakah sistem Anda memiliki cukup memori untuk memuat model.
Kesalahan Tensor Parallelism vLLM:
- Jika Anda melihat kesalahan seperti "output_size is not divisible by weight quantization block_n," kurangi
--tensor-parallel-size(misalnya, menjadi 4).
Permintaan API Gagal di Apidog:
- Verifikasi bahwa server (Ollama, LM Studio, atau vLLM) sedang berjalan.
- Periksa kembali URL titik akhir dan payload permintaan.
Dengan mengatasi masalah ini, Anda dapat memastikan pengalaman penerapan yang lancar.
Kesimpulan
Menjalankan model terkuantisasi Qwen3 secara lokal adalah proses yang mudah dengan alat seperti Ollama, LM Studio, dan vLLM. Baik Anda seorang pengembang yang membangun aplikasi atau peneliti yang bereksperimen dengan LLM, Qwen3 menawarkan fleksibilitas dan kinerja yang Anda butuhkan. Dengan mengikuti panduan ini, Anda telah mempelajari cara mengunduh model dari Hugging Face dan ModelScope, menerapkannya menggunakan berbagai kerangka kerja, dan menguji titik akhir API-nya dengan Apidog.
Mulai jelajahi Qwen3 hari ini dan buka kekuatan LLM lokal untuk proyek Anda!