
Seri Qwen dari Alibaba terus mendorong batas dalam model bahasa besar, dan Qwen3-Next-80B-A3B menonjol sebagai contoh utama efisiensi yang berpadu dengan kinerja tinggi. Insinyur dan pengembang mencari model yang memberikan penalaran yang kuat tanpa beban komputasi dari model besar yang padat. Model ini secara langsung memenuhi permintaan tersebut, dengan 80 miliar parameter namun hanya mengaktifkan 3 miliar per token. Akibatnya, tim mencapai kecepatan inferensi yang lebih cepat dan mengurangi biaya pelatihan, menjadikannya ideal untuk penerapan di dunia nyata.
Dalam postingan ini, Anda akan menjelajahi komponen inti Qwen3-Next-80B-A3B, membedah arsitektur inovatifnya, meninjau data kinerja empiris, dan menguasai API-nya melalui langkah-langkah praktis. Selain itu, Anda akan mengintegrasikan alat seperti Apidog untuk meningkatkan alur kerja Anda. Pada akhirnya, Anda akan memiliki pengetahuan untuk menerapkan model ini secara efektif dalam aplikasi Anda.
Apa yang Mendefinisikan Qwen3-Next-80B-A3B? Fitur Inti dan Inovasi
Qwen3-Next-80B-A3B muncul dari keluarga Qwen Alibaba sebagai model Mixture of Experts (MoE) yang jarang (sparse) yang dioptimalkan untuk kecepatan dan kemampuan. Pengembang hanya mengaktifkan sebagian kecil parameternya selama inferensi, yang berarti penghematan sumber daya yang substansial. Secara khusus, model ini menggunakan pengaturan MoE ultra-jarang dengan 512 pakar, merutekan ke 10 per token bersama satu pakar bersama. Akibatnya, ia menyaingi kinerja model yang lebih padat seperti Qwen3-32B sambil mengonsumsi daya yang jauh lebih sedikit.
Selain itu, model ini mendukung prediksi multi-token, sebuah teknik yang mempercepat speculative decoding. Fitur ini memungkinkan model untuk menghasilkan beberapa token secara bersamaan, meningkatkan throughput dalam tahap decoding. Para pengembang menghargai ini untuk aplikasi yang membutuhkan respons cepat, seperti chatbot atau alat analisis waktu nyata.
Seri ini mencakup varian yang disesuaikan dengan kebutuhan spesifik: model dasar untuk pelatihan awal umum, versi instruksi untuk tugas percakapan yang disempurnakan, dan varian berpikir untuk rantai penalaran tingkat lanjut. Misalnya, Qwen3-Next-80B-A3B-Thinking unggul dalam pemecahan masalah kompleks, mengungguli model seperti Gemini-2.5-Flash-Thinking pada benchmark. Selain itu, ia menangani 119 bahasa, memungkinkan penerapan multibahasa tanpa pelatihan ulang.
Detail pelatihan menunjukkan efisiensi lebih lanjut. Insinyur Alibaba melatih model ini menggunakan metode yang efisien dalam penskalaan, hanya menanggung 10% dari biaya dibandingkan dengan Qwen3-32B. Mereka memanfaatkan tata letak hibrida di 48 lapisan dengan dimensi tersembunyi 2048, memastikan distribusi komputasi yang seimbang. Akibatnya, model ini menunjukkan pemahaman konteks panjang yang unggul, mempertahankan akurasi di luar 32K token di mana model lain gagal.
Dalam praktiknya, fitur-fitur ini memberdayakan pengembang untuk menskalakan solusi AI secara hemat biaya. Baik Anda membangun mesin pencari perusahaan atau generator konten otomatis, Qwen3-Next-80B-A3B menyediakan tulang punggung untuk aplikasi inovatif. Berdasarkan fondasi ini, bagian selanjutnya akan mengkaji elemen arsitektur yang memungkinkan efisiensi tersebut.
Membongkar Arsitektur Qwen3-Next-80B-A3B: Sebuah Cetak Biru Teknis
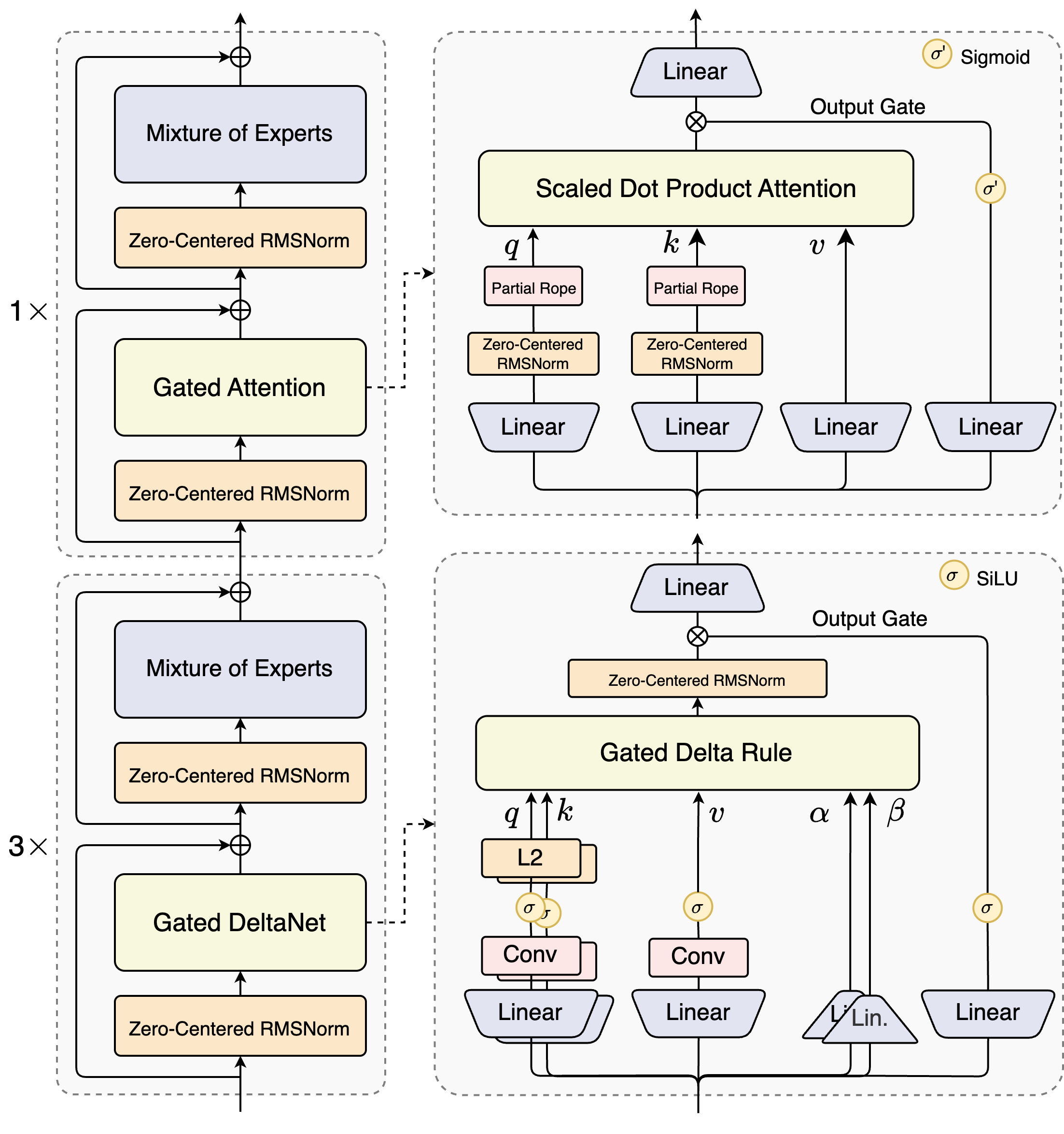
Arsitek Qwen3-Next-80B-A3B memperkenalkan desain hibrida yang menggabungkan mekanisme gated dengan teknik normalisasi canggih. Intinya terletak pada lapisan Mixture of Experts (MoE), di mana para ahli berspesialisasi dalam jalur komputasi yang berbeda. Model ini merutekan input secara dinamis, mengaktifkan subset untuk meminimalkan overhead. Misalnya, blok perhatian gated memproses kueri, kunci, dan nilai melalui embedding RoPE parsial dan lapisan RMSNorm yang berpusat nol, meningkatkan stabilitas dalam urutan panjang.
Pertimbangkan modul perhatian dot-product berskala. Ini mengintegrasikan proyeksi linier yang diikuti oleh gerbang keluaran yang dimodulasi oleh aktivasi sigmoid. Pengaturan ini memungkinkan kontrol yang tepat atas aliran informasi, mencegah pengenceran dalam ruang berdimensi tinggi. Selain itu, RMSNorm yang berpusat nol mendahului dan mengikuti operasi ini, memusatkan aktivasi di sekitar nol untuk mengurangi masalah gradien selama pelatihan.
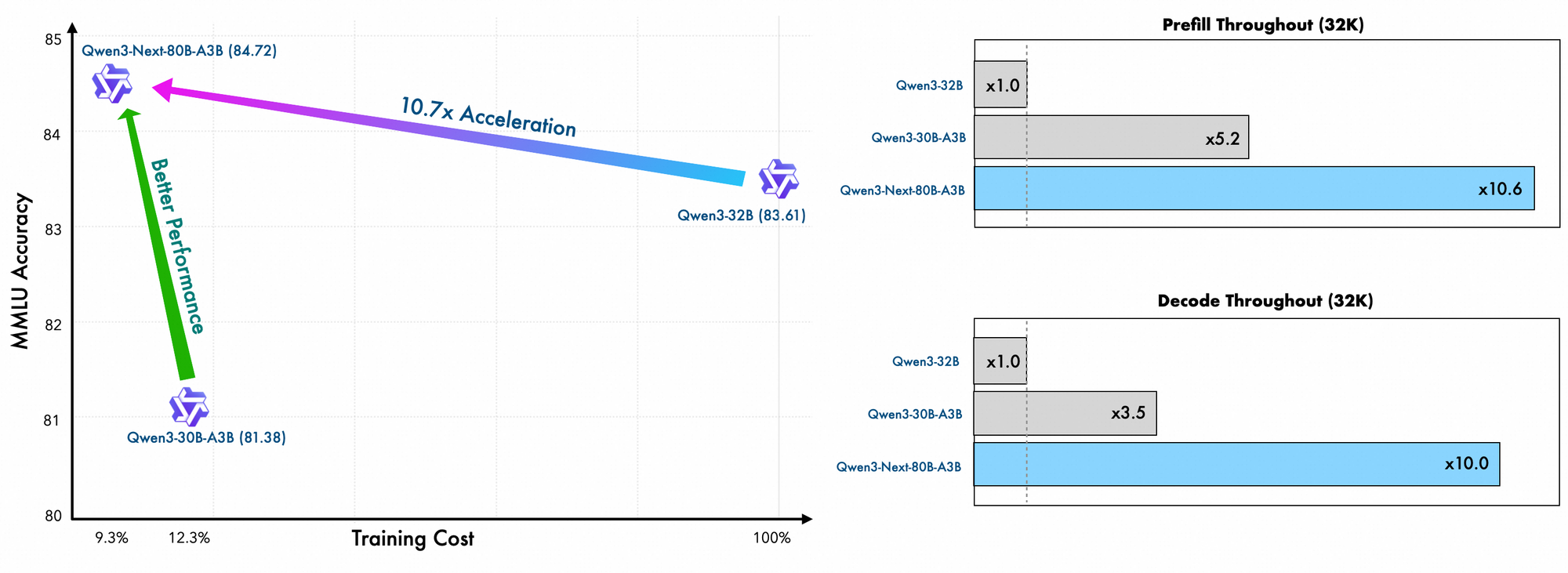
Diagram ini mengilustrasikan dua blok utama: yang atas berfokus pada perhatian gated dengan perhatian dot-product berskala, sementara yang bawah menekankan DeltaNet gated. Dalam jalur perhatian (ekspansi 1x), input mengalir melalui RMSNorm yang berpusat nol, lalu masuk ke inti perhatian gated. Di sini, proyeksi kueri (q), kunci (k), dan nilai (v) menggunakan RoPE parsial untuk pengkodean posisi. Setelah perhatian, RMSNorm lain dan lapisan linier masuk ke MoE, yang menggunakan keluaran sigmoid-gated.
Beralih ke jalur DeltaNet (ekspansi 3x), arsitektur ini menggunakan aturan Delta gated untuk prediksi yang lebih halus. Ini menampilkan normalisasi L2 pada q dan k, lapisan konvolusional untuk ekstraksi fitur lokal, dan aktivasi SiLU untuk non-linearitas. Gerbang keluaran, dikombinasikan dengan proyeksi linier, memastikan keluaran multi-token yang koheren. Desain blok ini mendukung speculative decoding model, di mana ia memprediksi beberapa token di depan, yang diverifikasi dalam lintasan berikutnya.
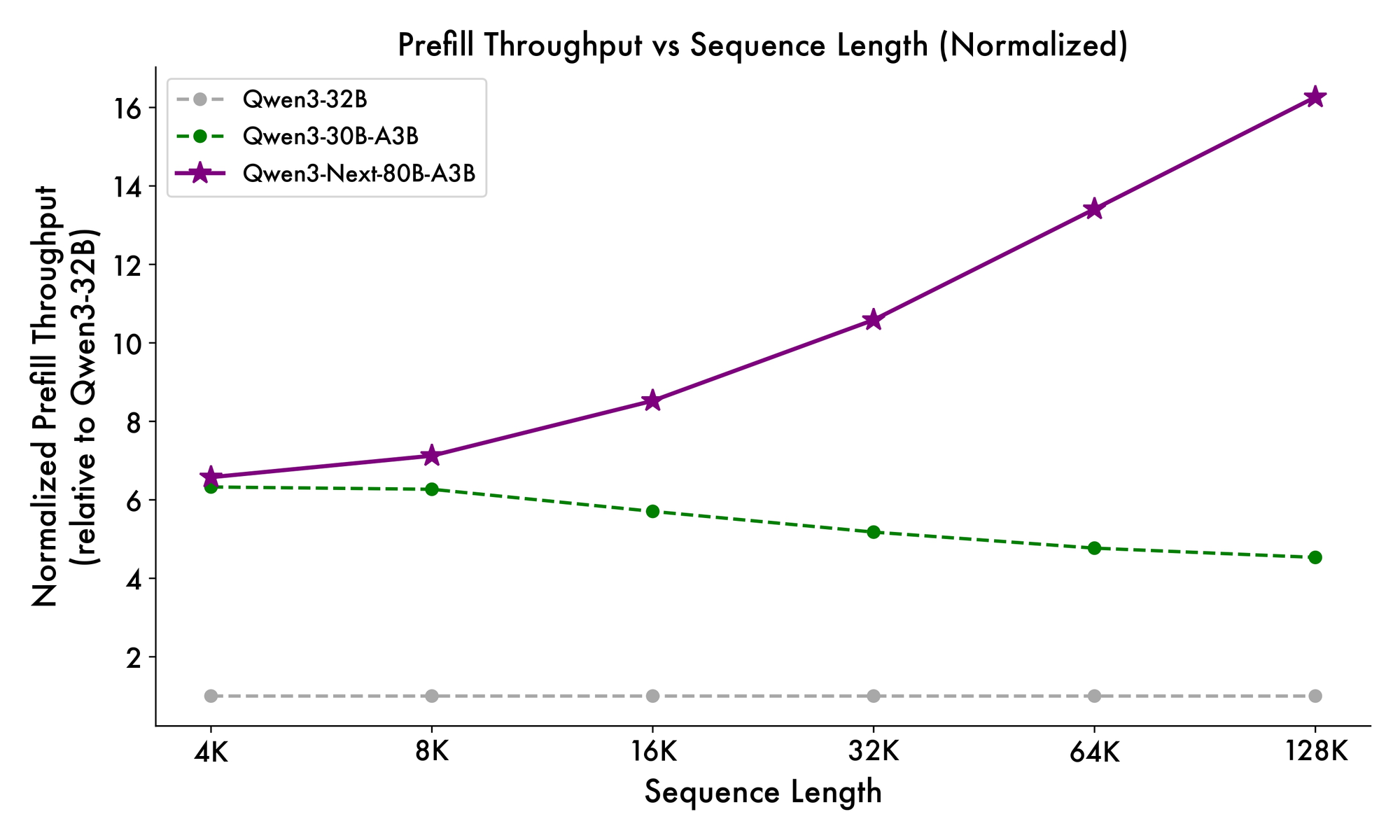
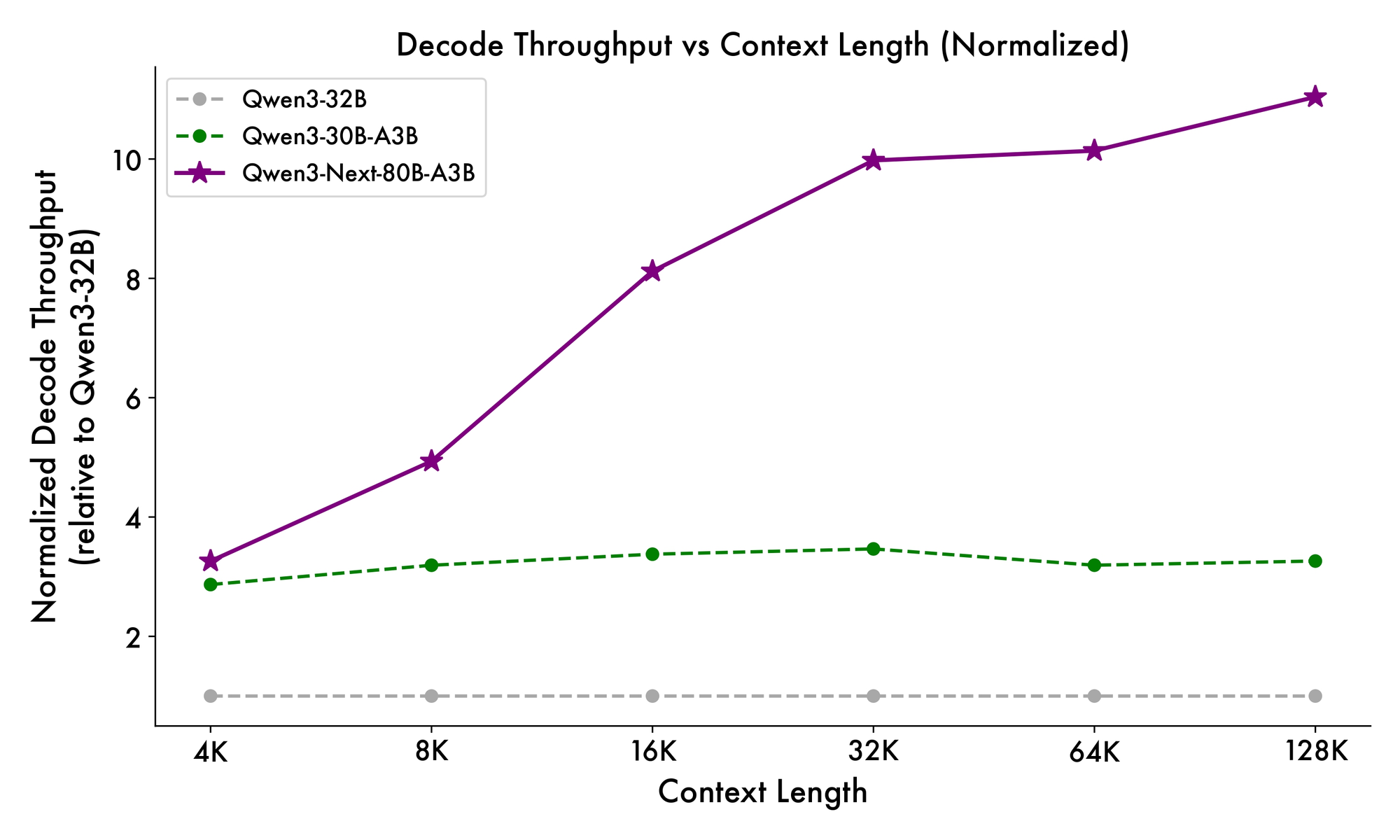
Selain itu, struktur keseluruhan menggabungkan pakar bersama dalam MoE untuk menangani pola umum di seluruh token, mengurangi redundansi. Embedding rope parsial dalam proyeksi mempertahankan invarian rotasi untuk konteks yang diperpanjang. Seperti yang dibuktikan dalam benchmark, konfigurasi ini menghasilkan throughput hampir 7x lebih tinggi pada panjang konteks 4K dibandingkan dengan Qwen3-32B. Di luar 32K token, kecepatan melebihi 10x, membuatnya cocok untuk analisis dokumen atau tugas pembuatan kode.
Pengembang mendapatkan manfaat dari modularitas ini saat melakukan fine-tuning. Anda dapat menukar pakar atau menyesuaikan ambang batas perutean untuk mengkhususkan model pada domain seperti keuangan atau perawatan kesehatan. Intinya, arsitektur ini tidak hanya mengoptimalkan komputasi tetapi juga mendorong adaptasi. Dengan wawasan ini, Anda sekarang beralih ke bagaimana elemen-elemen ini diterjemahkan menjadi peningkatan kinerja yang terukur.
Benchmarking Qwen3-Next-80B-A3B: Metrik Kinerja yang Penting
Evaluasi empiris menempatkan Qwen3-Next-80B-A3B sebagai pemimpin dalam AI yang didorong efisiensi. Pada benchmark standar seperti MMLU dan HumanEval, model dasar ini melampaui Qwen3-32B meskipun hanya menggunakan sepersepuluh parameter aktif. Secara khusus, ia mencapai 78,5% pada MMLU untuk pengetahuan umum, mengungguli pesaing sebesar 2-3 poin dalam subset penalaran.
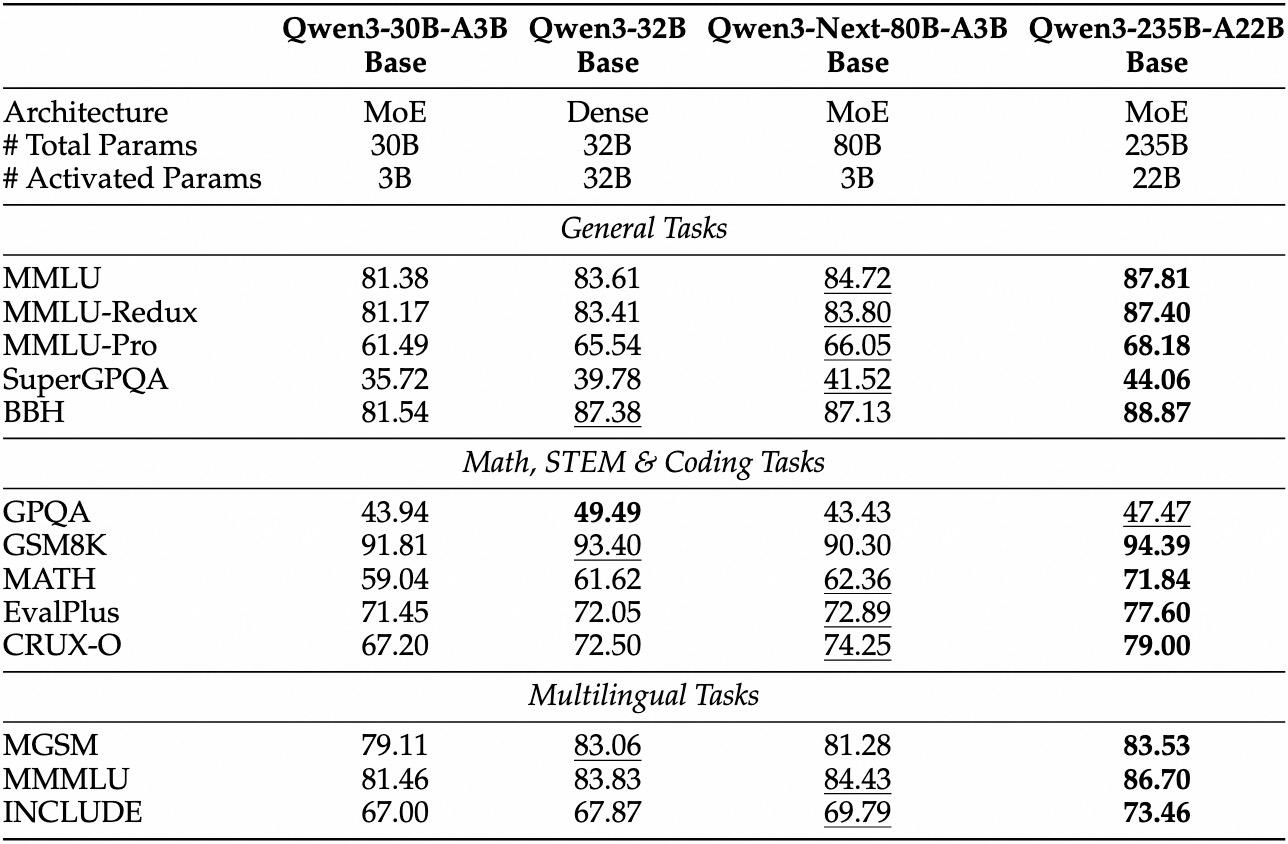
Untuk varian instruksi, tugas percakapan menunjukkan kekuatan dalam mengikuti instruksi. Ia mencetak 85% pada MT-Bench, menunjukkan dialog multi-giliran yang koheren. Sementara itu, model berpikir bersinar dalam skenario chain-of-thought, mencapai 92% pada GSM8K untuk masalah matematika—mengungguli Qwen3-30B-A3B-Thinking sebesar 4%.
Kecepatan inferensi menjadi landasan daya tariknya. Pada konteks 4K, throughput decode mencapai 4x dari Qwen3-32B, meningkat hingga 10x pada panjang yang lebih besar. Tahap prefill, yang penting untuk pemrosesan prompt, menunjukkan peningkatan 7x, berkat MoE yang jarang. Konsumsi daya turun secara proporsional, dengan biaya pelatihan sebesar 10% dari model yang lebih padat.
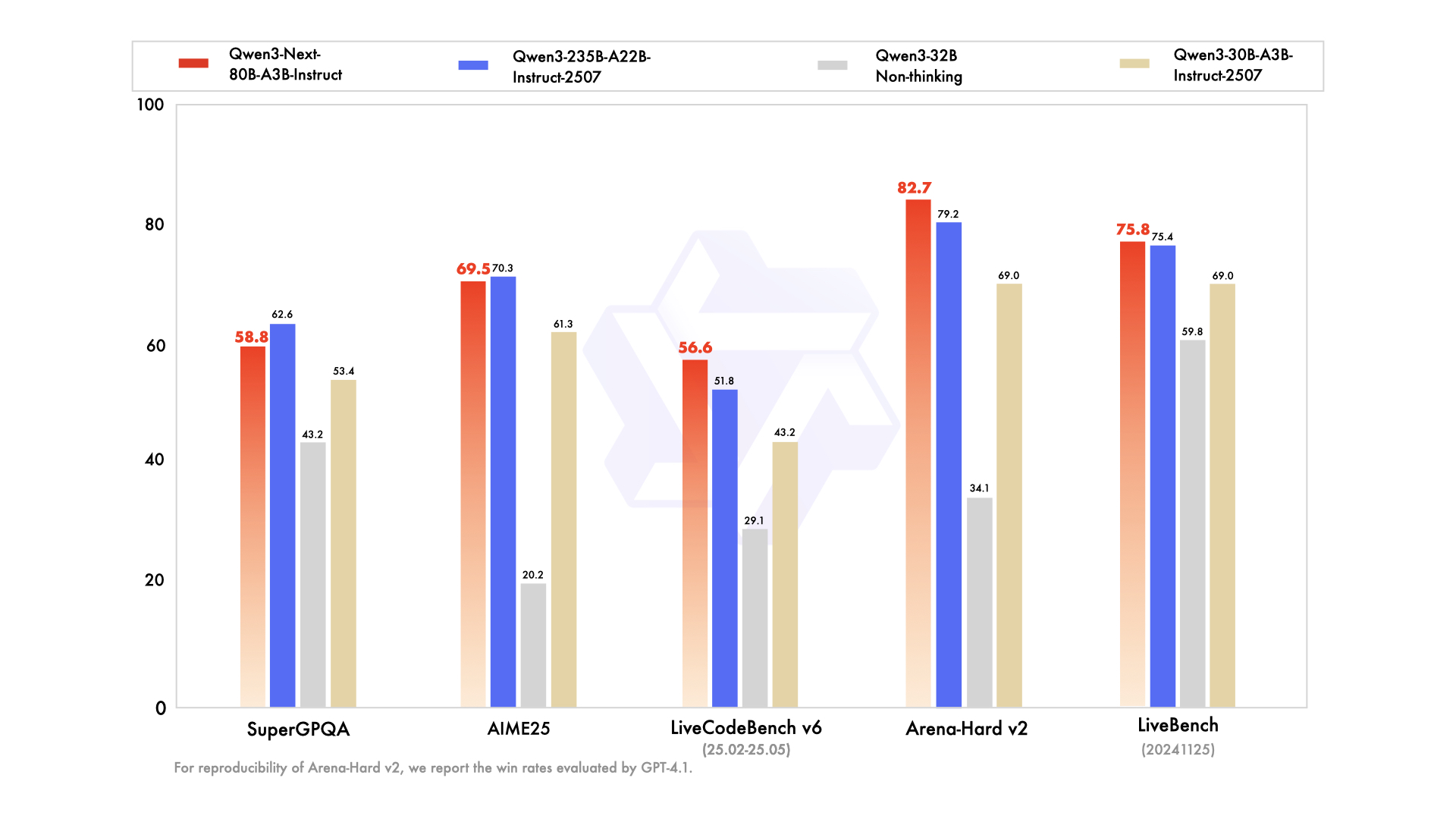
Perbandingan dengan pesaing menyoroti keunggulannya. Terhadap Llama 3.1-70B, Qwen3-Next-80B-A3B-Thinking memimpin dalam RULER (long-context recall) sebesar 15%, mengingat detail dari 128K token secara akurat. Dibandingkan DeepSeek-V2, ia menawarkan dukungan multibahasa yang lebih baik tanpa mengorbankan kecepatan.

| Benchmark | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Llama 3.1-70B |
|---|---|---|---|
| MMLU | 78.5% | 76.2% | 77.8% |
| HumanEval | 82.1% | 79.5% | 81.2% |
| GSM8K | 91.2% | 88.7% | 90.1% |
| MT-Bench | 84.3% (Instruksi) | 81.9% | 83.5% |
Tabel ini menggarisbawahi kinerja yang konsisten melebihi ekspektasi. Akibatnya, organisasi mengadopsinya untuk produksi, menyeimbangkan kualitas dan biaya. Beralih dari teori ke praktik, Anda sekarang melengkapi diri dengan alat akses API.
Menyiapkan Akses ke API Qwen3-Next-80B-A3B: Prasyarat dan Autentikasi
Alibaba menyediakan API Qwen melalui DashScope, platform cloud mereka, memastikan integrasi yang mulus. Pertama, buat akun Alibaba Cloud dan navigasikan ke konsol Model Studio. Pilih Qwen3-Next-80B-A3B dari daftar model—tersedia dalam mode dasar, instruksi, dan berpikir.
Dapatkan kunci API Anda dari dasbor di bawah "API Keys". Kunci ini mengautentikasi permintaan, dengan batasan laju berdasarkan tingkatan Anda (tingkatan gratis menawarkan 1 juta token/bulan). Untuk panggilan yang kompatibel dengan OpenAI, atur URL dasar ke https://dashscope.aliyuncs.com/compatible-mode/v1. Titik akhir DashScope asli menggunakan https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation.
Instal Python SDK melalui pip: pip install dashscope. Pustaka ini menangani serialisasi, percobaan ulang, dan penguraian kesalahan. Atau, gunakan klien HTTP seperti requests untuk implementasi kustom.
Praktik terbaik keamanan menentukan penyimpanan kunci dalam variabel lingkungan: export DASHSCOPE_API_KEY='your_key_here'. Akibatnya, kode Anda tetap portabel di berbagai lingkungan. Dengan penyiapan selesai, Anda melanjutkan untuk membuat panggilan API pertama Anda.
Panduan Praktis: Menggunakan API Qwen3-Next-80B-A3B dengan Python dan DashScope
DashScope menyederhanakan interaksi dengan Qwen3-Next-80B-A3B. Mulailah dengan permintaan generasi dasar menggunakan varian instruksi untuk respons seperti obrolan.
Berikut adalah skrip awal:
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")
Kode ini mengirimkan prompt dan mengambil hingga 200 token. Model merespons dengan penjelasan singkat, menyoroti peningkatan efisiensi. Untuk mode berpikir, beralihlah ke 'qwen3-next-80b-a3b-thinking' dan tambahkan instruksi penalaran: "Berpikir langkah demi langkah sebelum menjawab."
Parameter lanjutan meningkatkan kontrol. Atur top_p=0.9 untuk nucleus sampling, atau repetition_penalty=1.1 untuk menghindari pengulangan. Untuk konteks panjang, tentukan max_context_length=131072 untuk memanfaatkan kemampuan 128K model.
Tangani streaming untuk aplikasi waktu nyata:
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
break
Ini menghasilkan keluaran token-demi-token, ideal untuk integrasi UI. Penanganan kesalahan termasuk memeriksa response.code untuk masalah kuota (misalnya, 10402 untuk saldo tidak mencukupi).
Selain itu, pemanggilan fungsi memperluas utilitas. Definisikan alat dalam skema JSON:
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)
Model menguraikan maksud dan mengembalikan panggilan alat, yang Anda eksekusi secara eksternal. Pola ini menggerakkan alur kerja agentic. Dengan contoh-contoh ini, Anda membangun pipeline yang kuat. Selanjutnya, gabungkan Apidog untuk menguji dan menyempurnakan panggilan ini tanpa perlu mengkode setiap saat.
Meningkatkan Alur Kerja Anda: Mengintegrasikan Apidog untuk Pengujian API Qwen3-Next-80B-A3B
Apidog mengubah pengembangan API menjadi proses yang disederhanakan, terutama untuk titik akhir AI seperti Qwen3-Next-80B-A3B. Platform ini menggabungkan desain, mocking, pengujian, dan dokumentasi dalam satu antarmuka, didukung oleh AI untuk otomatisasi cerdas.
Mulailah dengan mengimpor skema DashScope ke Apidog. Buat proyek baru, tambahkan titik akhir POST https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generation, dan tempel kunci API Anda sebagai header: X-DashScope-API-Key: your_key.
Rancang permintaan secara visual: Atur parameter model ke 'qwen3-next-80b-a3b-instruct', masukkan prompt di body sebagai JSON {"input": {"messages": [{"role": "user", "content": "Your prompt here"}]}}. AI Apidog menyarankan kasus uji, menghasilkan variasi seperti prompt kasus tepi atau sampel suhu tinggi.
Jalankan koleksi pengujian secara berurutan. Misalnya, ukur latensi di berbagai suhu:
- Uji 1: Suhu 0.1, panjang prompt 100 token.
- Uji 2: Suhu 1.0, konteks 10K token.
Alat ini melacak metrik—waktu respons, penggunaan token, tingkat kesalahan—dan memvisualisasikan tren di dasbor. Respons tiruan untuk pengembangan offline: Apidog mensimulasikan keluaran Qwen berdasarkan data historis, mempercepat pembangunan frontend.
Dokumentasi dihasilkan secara otomatis dari koleksi Anda. Ekspor spesifikasi OpenAPI dengan contoh, termasuk spesifikasi Qwen3-Next-80B-A3B seperti catatan perutean MoE. Fitur kolaborasi memungkinkan tim untuk berbagi lingkungan, memastikan pengujian yang konsisten.
Dalam satu skenario, seorang pengembang menguji prompt multibahasa. AI Apidog mendeteksi inkonsistensi, menyarankan perbaikan seperti menambahkan petunjuk bahasa. Akibatnya, waktu integrasi turun 40%, menurut laporan pengguna. Untuk pengujian khusus AI, manfaatkan pembuatan data cerdasnya: Masukkan skema, dan ia akan membuat prompt realistis yang meniru lalu lintas produksi.
Selain itu, Apidog mendukung hook CI/CD, menjalankan pengujian API dalam pipeline. Sambungkan ke GitHub Actions untuk validasi otomatis setelah deployment. Pendekatan closed-loop ini meminimalkan bug dalam aplikasi yang didukung Qwen.
Strategi Lanjutan: Mengoptimalkan Panggilan API Qwen3-Next-80B-A3B untuk Produksi
Optimasi meningkatkan penggunaan dasar ke keandalan tingkat perusahaan. Pertama, batch permintaan jika memungkinkan—DashScope mendukung hingga 10 prompt per panggilan, mengurangi overhead untuk tugas paralel seperti ringkasan massal.
Pantau ekonomi token: Model mengenakan biaya per parameter aktif, jadi prompt yang ringkas menghasilkan penghematan. Gunakan result_format='message' API untuk keluaran terstruktur, mengurai JSON secara langsung untuk menghindari pasca-pemrosesan.
Untuk ketersediaan tinggi, terapkan percobaan ulang dengan exponential backoff:
import time
from dashscope import Generation
def call_with_retry(prompt, max_retries=3):
for attempt in range(max_retries):
response = Generation.call(model='qwen3-next-80b-a3b-instruct', prompt=prompt)
if response.status_code == 200:
return response
time.sleep(2 ** attempt)
raise Exception("Max retries exceeded")
Ini menangani kesalahan sementara seperti batasan laju 429. Skalakan secara horizontal dengan mendistribusikan panggilan ke seluruh wilayah—DashScope menawarkan titik akhir di Singapura dan AS.
Pertimbangan keamanan meliputi sanitasi input untuk mencegah prompt injection. Validasi input pengguna terhadap daftar putih sebelum meneruskan ke API. Selain itu, catat respons yang dianonimkan untuk audit, mematuhi GDPR.
Dalam kasus-kasus ekstrem, seperti konteks ultra-panjang, potong input dan rantai prediksi. Varian berpikir membantu di sini: Prompt dengan "Langkah 1: Analisis bagian A; Langkah 2: Sintesis dengan B." Ini mempertahankan koherensi di atas 100K+ token.
Pengembang juga menjelajahi fine-tuning melalui platform Alibaba, meskipun pengguna API tetap menggunakan prompt engineering. Akibatnya, taktik ini memastikan deployment yang skalabel dan aman.
Penutup: Mengapa Qwen3-Next-80B-A3B Layak Mendapat Perhatian Anda
Qwen3-Next-80B-A3B mendefinisikan ulang AI yang efisien dengan MoE yang jarang, gerbang hibrida, dan benchmark yang unggul. Pengembang memanfaatkan API-nya melalui DashScope untuk prototyping cepat, ditingkatkan oleh alat seperti Apidog untuk ketelitian pengujian.
Anda kini memegang cetak biru: dari nuansa arsitektur hingga optimasi produksi. Terapkan wawasan ini untuk membangun sistem yang lebih cepat dan cerdas. Bereksperimenlah hari ini—masa depan intelijen yang skalabel menanti.