
Hari ini adalah hari yang luar biasa lainnya bagi komunitas AI sumber terbuka, khususnya, yang berkembang pesat pada momen-momen seperti ini, dengan antusias membongkar, menguji, dan membangun di atas teknologi terkini. Pada Juli 2025, tim Qwen Alibaba memicu salah satu peristiwa tersebut dengan peluncuran seri Qwen3-nya, sebuah keluarga model baru yang kuat yang siap mendefinisikan ulang tolok ukur kinerja. Inti dari rilis ini adalah varian yang menarik dan sangat terspesialisasi: Qwen3-235B-A22B-Thinking-2507.
Model ini bukan sekadar pembaruan inkremental lainnya; ini merupakan langkah yang disengaja dan strategis menuju penciptaan sistem AI dengan kemampuan penalaran yang mendalam. Namanya saja sudah merupakan deklarasi niat, menandakan fokus pada logika, perencanaan, dan pemecahan masalah multi-langkah. Artikel ini menawarkan tinjauan mendalam tentang arsitektur, tujuan, dan dampak potensial dari Qwen3-Thinking, mengkaji posisinya dalam ekosistem Qwen3 yang lebih luas dan apa artinya bagi masa depan pengembangan AI.
Ingin platform Terintegrasi, All-in-One untuk Tim Pengembang Anda bekerja sama dengan produktivitas maksimum?
Apidog memenuhi semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!
Keluarga Qwen3: Serangan Multi-Faset pada Teknologi Terkini
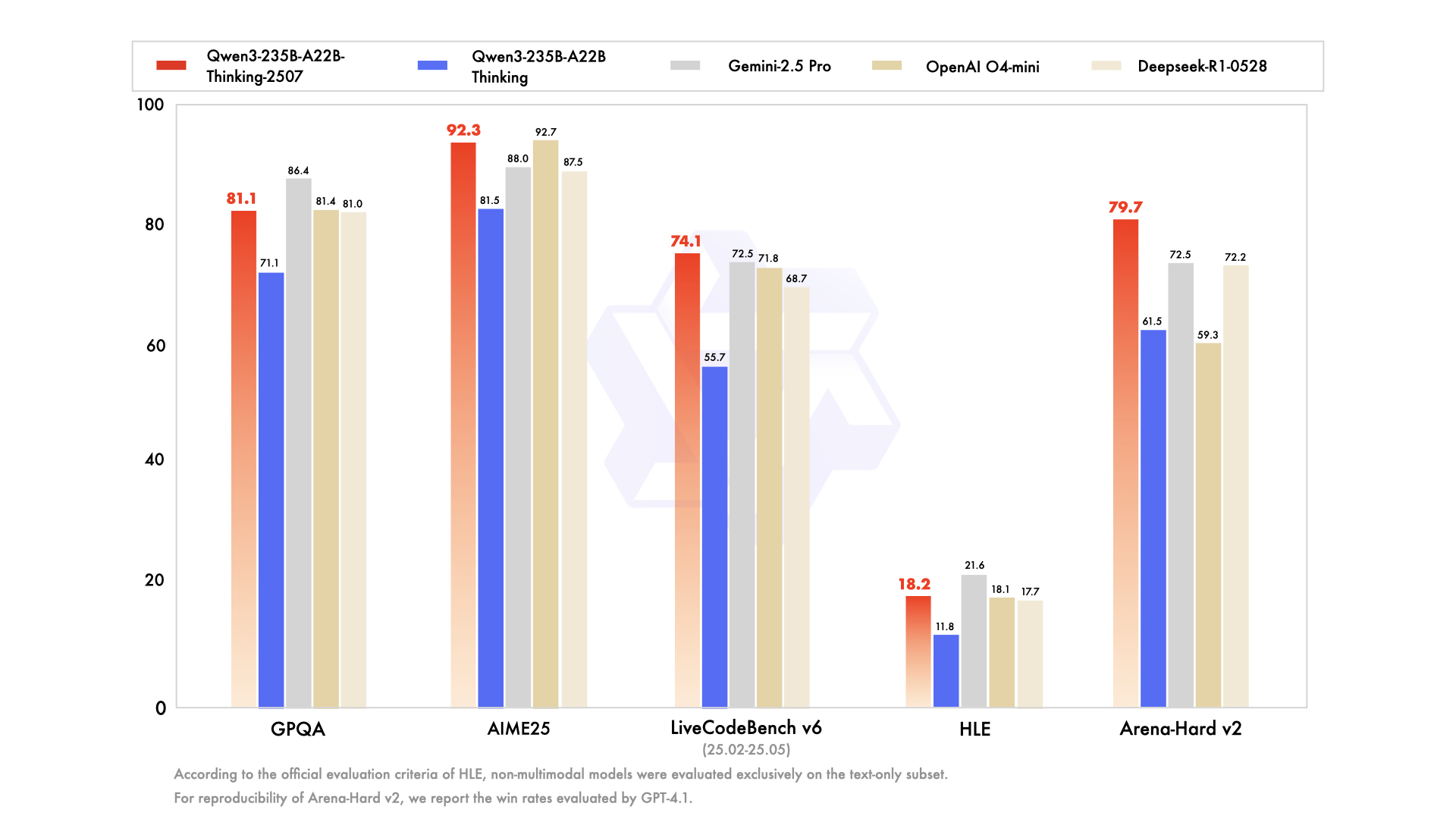
Untuk memahami model Thinking, seseorang harus terlebih dahulu menghargai konteks kelahirannya. Model ini tidak muncul secara terpisah, melainkan sebagai bagian dari keluarga model Qwen3 yang komprehensif dan beragam secara strategis. Seri Qwen telah mengumpulkan pengikut yang sangat besar, dengan riwayat unduhan mencapai ratusan juta dan menumbuhkan komunitas yang bersemangat yang telah menciptakan lebih dari 100.000 model turunan di platform seperti Hugging Face.
Seri Qwen3 mencakup beberapa varian kunci, masing-masing disesuaikan untuk domain yang berbeda:
- Qwen3-Instruct: Model pengikut instruksi serbaguna yang dirancang untuk berbagai aplikasi percakapan dan berorientasi tugas. Varian
Qwen3-235B-A22B-Instruct-2507, misalnya, dikenal karena penyelarasan yang ditingkatkan dengan preferensi pengguna dalam tugas-tugas terbuka dan cakupan pengetahuan yang luas. - Qwen3-Coder: Serangkaian model yang secara eksplisit dirancang untuk pengkodean agen. Yang paling kuat di antaranya, model dengan 480 miliar parameter yang masif, menetapkan standar baru untuk generasi kode sumber terbuka dan otomatisasi pengembangan perangkat lunak. Bahkan dilengkapi dengan alat baris perintah, Qwen Code, untuk memanfaatkan kemampuan agennya dengan lebih baik.
- Qwen3-Thinking: Fokus analisis kami, khusus untuk tugas-tugas kognitif kompleks yang melampaui instruksi sederhana atau generasi kode.
Pendekatan keluarga ini menunjukkan strategi yang canggih: alih-alih satu model monolitik yang mencoba menjadi serba bisa, Alibaba menyediakan serangkaian alat khusus, memungkinkan pengembang untuk memilih fondasi yang tepat untuk kebutuhan spesifik mereka.
Mari Bicara tentang Bagian "Thinking" dari Qwen3-235B-A22B-Thinking-2507
Nama model, Qwen3-235B-A22B-Thinking-2507, padat dengan informasi yang mengungkapkan arsitektur dasar dan filosofi desainnya. Mari kita uraikan satu per satu.
Qwen3: Ini menandakan bahwa model tersebut termasuk dalam generasi ketiga dari seri Qwen, dibangun di atas pengetahuan dan kemajuan pendahulunya.235B-A22B(Mixture of Experts - MoE): Ini adalah detail arsitektur yang paling krusial. Model ini bukanlah jaringan padat 235 miliar parameter, di mana setiap parameter digunakan untuk setiap perhitungan tunggal. Sebaliknya, model ini menggunakan arsitektur Mixture-of-Experts (MoE).Thinking: Sufiks ini menunjukkan spesialisasi model, yang disetel dengan baik pada data yang menghargai deduksi logis dan analisis langkah demi langkah.2507: Ini adalah tag versi, kemungkinan singkatan dari Juli 2025, menunjukkan tanggal rilis atau penyelesaian pelatihan model.
Arsitektur MoE adalah kunci kombinasi kekuatan dan efisiensi model ini. Ini dapat dianggap sebagai tim besar "pakar" khusus—jaringan saraf yang lebih kecil—yang dikelola oleh "jaringan gerbang" atau "router." Untuk setiap token masukan yang diberikan, router secara dinamis memilih subset kecil dari pakar yang paling relevan untuk memproses informasi tersebut.
Dalam kasus Qwen3-235B-A22B, spesifikasinya adalah:
- Total Parameter (
235B): Ini merepresentasikan repositori pengetahuan yang luas yang didistribusikan di seluruh pakar yang tersedia. Model ini berisi total 128 pakar yang berbeda. - Parameter Aktif (
A22B): Untuk setiap lintasan inferensi tunggal, jaringan gerbang memilih 8 pakar untuk diaktifkan. Ukuran gabungan dari pakar aktif ini adalah sekitar 22 miliar parameter.
Manfaat dari pendekatan ini sangat besar. Ini memungkinkan model untuk memiliki pengetahuan, nuansa, dan kemampuan yang luas dari model 235B-parameter sambil memiliki biaya komputasi dan kecepatan inferensi yang lebih dekat dengan model padat 22B-parameter yang jauh lebih kecil. Ini membuat penerapan dan menjalankan model sebesar itu lebih layak tanpa mengorbankan kedalaman pengetahuannya.
Spesifikasi Teknis dan Profil Kinerja
Di luar arsitektur tingkat tinggi, spesifikasi detail model melukiskan gambaran yang lebih jelas tentang kemampuannya.
- Arsitektur Model: Mixture-of-Experts (MoE)
- Total Parameter: ~235 Miliar
- Parameter Aktif: ~22 Miliar per token
- Jumlah Pakar: 128
- Pakar yang Diaktifkan per Token: 8
- Panjang Konteks: Model ini mendukung jendela konteks 128.000 token. Ini adalah peningkatan besar yang memungkinkannya memproses dan bernalar atas dokumen yang sangat panjang, seluruh basis kode, atau riwayat percakapan yang panjang tanpa kehilangan informasi penting dari awal masukan.
- Tokenizer: Ini menggunakan tokenizer Byte Pair Encoding (BPE) kustom dengan kosakata lebih dari 150.000 token. Ukuran kosakata yang besar ini menunjukkan pelatihan multibahasa yang kuat, memungkinkannya untuk secara efisien mengkodekan teks dari berbagai bahasa, termasuk Inggris, Cina, Jerman, Spanyol, dan banyak lainnya, serta bahasa pemrograman.
- Data Pelatihan: Meskipun komposisi pasti dari korpus pelatihan adalah hak milik, model
Thinkingtentu saja dilatih pada campuran data khusus yang dirancang untuk mendorong penalaran. Dataset ini akan jauh melampaui teks web standar dan kemungkinan akan mencakup: - Makalah Akademik dan Ilmiah: Volume teks yang besar dari sumber-sumber seperti arXiv, PubMed, dan repositori penelitian lainnya untuk menyerap penalaran ilmiah dan matematis yang kompleks.
- Dataset Logis dan Matematis: Dataset seperti GSM8K (Grade School Math) dan dataset MATH, yang berisi soal cerita yang membutuhkan solusi langkah demi langkah.
- Masalah Pemrograman dan Kode: Dataset seperti HumanEval dan MBPP, yang menguji penalaran logis melalui generasi kode.
- Teks Filosofis dan Hukum: Dokumen yang membutuhkan pemahaman argumen logis yang padat, abstrak, dan sangat terstruktur.
- Data Chain-of-Thought (CoT): Contoh yang dihasilkan secara sintetis atau dikurasi manusia di mana model secara eksplisit ditunjukkan bagaimana "berpikir langkah demi langkah" untuk mencapai jawaban.
Campuran data yang dikurasi inilah yang membedakan model Thinking dari saudaranya, Instruct. Model ini tidak hanya dilatih untuk membantu; model ini dilatih untuk menjadi teliti.
Kekuatan "Thinking": Fokus pada Kognisi Kompleks
Janji model Qwen3-Thinking terletak pada kemampuannya untuk mengatasi masalah yang secara historis menjadi tantangan besar bagi model bahasa besar. Ini adalah tugas-tugas di mana pencocatan pola sederhana atau pengambilan informasi tidak cukup. Spesialisasi "Thinking" menunjukkan kemahiran dalam bidang-bidang seperti:
- Penalaran Multi-Langkah: Memecahkan masalah yang memerlukan penguraian kueri menjadi serangkaian langkah logis. Misalnya, menghitung implikasi keuangan dari keputusan bisnis berdasarkan beberapa variabel pasar atau merencanakan lintasan proyektil dengan batasan fisik tertentu.
- Deduksi Logis: Menganalisis serangkaian premis dan menarik kesimpulan yang valid. Ini bisa melibatkan pemecahan teka-teki kisi logika, mengidentifikasi kesalahan logika dalam sebuah teks, atau menentukan konsekuensi dari serangkaian aturan dalam konteks hukum atau kontraktual.
- Perencanaan Strategis: Merancang urutan tindakan untuk mencapai tujuan. Ini memiliki aplikasi dalam permainan kompleks (seperti catur atau Go), simulasi strategi bisnis, optimasi rantai pasokan, dan manajemen proyek otomatis.
- Inferensi Kausal: Berusaha mengidentifikasi hubungan sebab-akibat dalam sistem kompleks yang dijelaskan dalam teks, sebuah landasan penalaran ilmiah dan analitis yang seringkali sulit bagi model.
- Penalaran Abstrak: Memahami dan memanipulasi konsep dan analogi abstrak. Ini penting untuk pemecahan masalah kreatif dan kecerdasan tingkat manusia sejati, bergerak melampaui fakta konkret ke hubungan di antaranya.
Model ini dirancang untuk unggul dalam tolok ukur yang secara khusus mengukur kemampuan kognitif tingkat lanjut ini, seperti MMLU (Massive Multitask Language Understanding) untuk pengetahuan umum dan pemecahan masalah, serta GSM8K dan MATH yang disebutkan di atas untuk penalaran matematis.
Aksesibilitas, Kuantisasi, dan Keterlibatan Komunitas
Kekuatan sebuah model hanya berarti jika dapat diakses dan dimanfaatkan. Tetap setia pada komitmen sumber terbukanya, Alibaba telah membuat keluarga Qwen3, termasuk varian Thinking, tersedia secara luas di platform seperti Hugging Face dan ModelScope.
Menyadari sumber daya komputasi yang signifikan yang diperlukan untuk menjalankan model sebesar ini, versi kuantisasi juga tersedia. Model Qwen3-235B-A22B-Thinking-2507-FP8 adalah contoh utama. FP8 (8-bit floating point) adalah teknik kuantisasi mutakhir yang secara dramatis mengurangi jejak memori model dan meningkatkan kecepatan inferensi.
Mari kita uraikan dampaknya:
- Model 235B parameter dalam presisi standar 16-bit (BF16/FP16) akan membutuhkan lebih dari 470 GB VRAM, jumlah yang sangat besar kecuali untuk klaster server kelas perusahaan terbesar.
- Namun, versi kuantisasi FP8 mengurangi kebutuhan ini menjadi di bawah 250 GB. Meskipun masih substansial, ini membawa model ke ranah kemungkinan bagi institusi penelitian, startup, dan bahkan individu dengan workstation multi-GPU yang dilengkapi dengan perangkat keras konsumen atau prosumer kelas atas.
Ini membuat penalaran tingkat lanjut dapat diakses oleh audiens yang jauh lebih luas. Untuk pengguna perusahaan yang lebih memilih layanan terkelola, model-model ini juga diintegrasikan ke dalam platform cloud Alibaba. Akses API melalui Model Studio dan integrasi ke dalam asisten AI unggulan Alibaba, Quark, memastikan bahwa teknologi ini dapat dimanfaatkan pada skala apa pun.
Kesimpulan: Alat Baru untuk Kelas Masalah Baru
Rilis Qwen3-235B-A22B-Thinking-2507 lebih dari sekadar titik lain pada grafik kinerja model AI yang terus meningkat. Ini adalah pernyataan tentang arah masa depan pengembangan AI: pergeseran dari model monolitik serbaguna menuju ekosistem alat yang beragam, kuat, dan terspesialisasi. Dengan menggunakan arsitektur Mixture-of-Experts yang efisien, Alibaba telah menghadirkan model dengan pengetahuan luas dari jaringan 235 miliar parameter dan keramahan komputasi relatif dari model 22 miliar parameter.
Dengan secara eksplisit menyempurnakan model ini untuk "Thinking," tim Qwen menyediakan alat bagi dunia yang didedikasikan untuk memecahkan tantangan analitis dan penalaran terberat. Ini memiliki potensi untuk mempercepat penemuan ilmiah dengan membantu peneliti menganalisis data kompleks, memberdayakan bisnis untuk membuat keputusan strategis yang lebih baik, dan berfungsi sebagai lapisan dasar untuk generasi baru aplikasi cerdas yang dapat merencanakan, menyimpulkan, dan bernalar dengan kecanggihan yang belum pernah terjadi sebelumnya. Saat komunitas sumber terbuka mulai sepenuhnya menjelajahi kedalamannya, Qwen3-Thinking siap menjadi blok bangunan penting dalam pencarian berkelanjutan untuk AI yang lebih mampu dan benar-benar cerdas.
Ingin platform Terintegrasi, All-in-One untuk Tim Pengembang Anda bekerja sama dengan produktivitas maksimum?
Apidog memenuhi semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!