
Tim Qwen dari Alibaba sekali lagi mendorong batasan kecerdasan buatan dengan merilis model Qwen2.5-VL-32B-Instruct, sebuah model visi-bahasa (VLM) terobosan yang menjanjikan untuk menjadi lebih pintar dan lebih ringan.
Diumumkan pada tanggal 24 Maret 2025, model 32 miliar parameter ini mencapai keseimbangan optimal antara kinerja dan efisiensi, menjadikannya pilihan ideal bagi pengembang dan peneliti. Dibangun di atas kesuksesan seri Qwen2.5-VL, iterasi baru ini memperkenalkan kemajuan signifikan dalam penalaran matematis, penyelarasan preferensi manusia, dan tugas-tugas visi, sambil mempertahankan ukuran yang mudah dikelola untuk penerapan lokal.
Bagi pengembang yang ingin mengintegrasikan model yang kuat ini ke dalam proyek mereka, menjelajahi alat API yang kuat sangat penting. Itulah mengapa kami merekomendasikan untuk mengunduh Apidog secara gratis — platform pengembangan API yang mudah digunakan yang menyederhanakan pengujian dan mengintegrasikan model seperti Qwen ke dalam aplikasi Anda. Dengan Apidog, Anda dapat berinteraksi dengan mulus dengan API Qwen, merampingkan alur kerja, dan membuka potensi penuh dari VLM inovatif ini. Unduh Apidog hari ini dan mulailah membangun aplikasi yang lebih cerdas!
Alat API ini memungkinkan Anda menguji dan men-debug titik akhir model Anda dengan mudah. Unduh Apidog secara gratis hari ini dan sederhanakan alur kerja Anda saat Anda menjelajahi kemampuan Mistral Small 3.1!
Qwen2.5-VL-32B: Model Visi-Bahasa yang Lebih Cerdas
Apa yang Membuat Qwen2.5-VL-32B Unik?
Qwen2.5-VL-32B menonjol sebagai model visi-bahasa 32 miliar parameter yang dirancang untuk mengatasi keterbatasan model yang lebih besar dan lebih kecil dalam keluarga Qwen. Sementara model 72 miliar parameter seperti Qwen2.5-VL-72B menawarkan kemampuan yang kuat, mereka seringkali membutuhkan sumber daya komputasi yang signifikan, membuatnya tidak praktis untuk penerapan lokal. Sebaliknya, model 7 miliar parameter, meskipun lebih ringan, mungkin kekurangan kedalaman yang diperlukan untuk tugas-tugas kompleks. Qwen2.5-VL-32B mengisi celah ini dengan memberikan kinerja tinggi dengan jejak yang lebih mudah dikelola.
Model ini dibangun di atas seri Qwen2.5-VL, yang mendapatkan pujian luas atas kemampuan multimodalnya. Namun, Qwen2.5-VL-32B memperkenalkan peningkatan penting, termasuk optimasi melalui pembelajaran penguatan (RL). Pendekatan ini meningkatkan keselarasan model dengan preferensi manusia, memastikan keluaran yang lebih rinci dan ramah pengguna. Selain itu, model ini menunjukkan penalaran matematis yang unggul, fitur penting untuk tugas-tugas yang melibatkan pemecahan masalah kompleks dan analisis data.

Peningkatan Teknis Utama
Qwen2.5-VL-32B memanfaatkan pembelajaran penguatan untuk menyempurnakan gaya keluarannya, membuat respons lebih koheren, rinci, dan diformat untuk interaksi manusia yang lebih baik. Selain itu, kemampuan penalaran matematisnya telah mengalami peningkatan signifikan, sebagaimana dibuktikan oleh kinerjanya pada tolok ukur seperti MathVista dan MMMU. Peningkatan ini berasal dari proses pelatihan yang disesuaikan dengan baik yang memprioritaskan akurasi dan deduksi logis, terutama dalam konteks multimodal di mana teks dan data visual berpotongan.
Model ini juga unggul dalam pemahaman dan penalaran gambar yang mendetail, memungkinkan analisis yang tepat dari konten visual, seperti bagan, grafik, dan dokumen. Kemampuan ini memposisikan Qwen2.5-VL-32B sebagai pesaing utama untuk aplikasi yang membutuhkan deduksi logika visual tingkat lanjut dan pengenalan konten.
Tolok Ukur Kinerja Qwen2.5-VL-32B: Mengungguli Model yang Lebih Besar
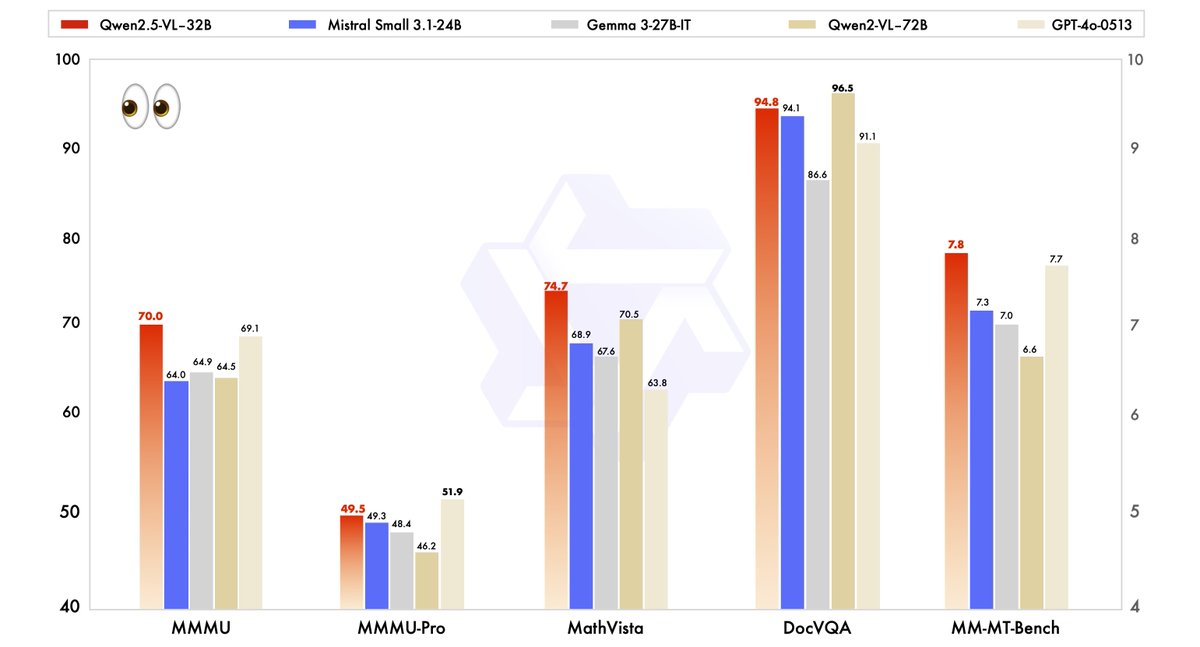
Kinerja Qwen2.5-VL-32B telah dievaluasi secara ketat terhadap model-model canggih, termasuk saudaranya yang lebih besar, Qwen2.5-VL-72B, serta pesaing seperti Mistral-Small-3.1–24B dan Gemma-3–27B-IT. Hasilnya menyoroti keunggulan model di beberapa bidang utama.
- MMMU (Pemahaman Bahasa Multitugas Masif): Qwen2.5-VL-32B mencapai skor 70.0, melampaui 64.5 milik Qwen2.5-VL-72B. Tolok ukur ini menguji penalaran multi-langkah yang kompleks di berbagai tugas, menunjukkan kemampuan kognitif model yang ditingkatkan.
- MathVista: Dengan skor 74.7, Qwen2.5-VL-32B mengungguli 70.5 milik Qwen2.5-VL-72B, menggarisbawahi kekuatannya dalam tugas-tugas penalaran matematis dan visual.
- MM-MT-Bench: Tolok ukur evaluasi pengalaman pengguna subjektif ini menunjukkan Qwen2.5-VL-32B memimpin pendahulunya dengan selisih yang signifikan, mencerminkan peningkatan penyelarasan preferensi manusia.
- Tugas Berbasis Teks (misalnya, MMLU, MATH, HumanEval): Model ini bersaing secara efektif dengan model yang lebih besar seperti GPT-4o-Mini, mencapai skor 78.4 pada MMLU, 82.2 pada MATH, dan 91.5 pada HumanEval, meskipun jumlah parameternya lebih kecil.
Tolok ukur ini menggambarkan bahwa Qwen2.5-VL-32B tidak hanya menyamai tetapi seringkali melebihi kinerja model yang lebih besar, sambil membutuhkan lebih sedikit sumber daya komputasi. Keseimbangan kekuatan dan efisiensi ini menjadikannya pilihan yang menarik bagi pengembang dan peneliti yang bekerja dengan perangkat keras terbatas.
Mengapa Ukuran Penting: Keunggulan 32B
Ukuran 32 miliar parameter dari Qwen2.5-VL-32B mencapai titik ideal untuk penerapan lokal. Tidak seperti model 72B, yang membutuhkan sumber daya GPU yang ekstensif, model yang lebih ringan ini terintegrasi dengan mulus dengan mesin inferensi seperti SGLang dan vLLM, seperti yang dicatat dalam hasil web terkait. Kompatibilitas ini memastikan penerapan yang lebih cepat dan penggunaan memori yang lebih rendah, membuatnya dapat diakses oleh berbagai pengguna yang lebih luas, dari perusahaan rintisan hingga perusahaan besar.
Selain itu, optimasi model untuk kecepatan dan efisiensi tidak mengorbankan kemampuannya. Kemampuannya untuk menangani tugas-tugas multimodal — seperti mengenali objek, menganalisis bagan, dan memproses keluaran terstruktur seperti faktur dan tabel — tetap kuat, memposisikannya sebagai alat serbaguna untuk aplikasi dunia nyata.

Menjalankan Qwen2.5-VL-32B Secara Lokal dengan MLX
Untuk menjalankan model yang kuat ini secara lokal di Mac Anda dengan Apple Silicon, ikuti langkah-langkah berikut:
Persyaratan Sistem
- Mac dengan Apple Silicon (chip M1, M2, atau M3)
- Setidaknya RAM 32GB (disarankan 64GB)
- Ruang penyimpanan kosong 60GB+
- macOS Sonoma atau yang lebih baru
Langkah-Langkah Instalasi
- Instal dependensi Python
pip install mlx mlx-llm transformers pillow
- Unduh model
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- Konversi model ke format MLX
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- Buat skrip sederhana untuk berinteraksi dengan model
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# Muat model
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# Muat gambar
image = Image.open("path/to/your/image.jpg")
# Buat prompt dengan gambar
prompt = "Apa yang Anda lihat di gambar ini?"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
Aplikasi Praktis: Memanfaatkan Qwen2.5-VL-32B
Tugas Visi dan Lebih Jauh
Kemampuan visual canggih Qwen2.5-VL-32B membuka pintu ke berbagai aplikasi. Misalnya, ia dapat berfungsi sebagai agen visual, berinteraksi secara dinamis dengan antarmuka komputer atau telepon untuk melakukan tugas-tugas seperti navigasi atau ekstraksi data. Kemampuannya untuk memahami video panjang (hingga satu jam) dan menunjukkan segmen yang relevan lebih meningkatkan kegunaannya dalam analisis video dan lokalisasi temporal.
Dalam penguraian dokumen, model ini unggul dalam memproses konten multi-adegan dan multibahasa, termasuk teks tulisan tangan, tabel, bagan, dan rumus kimia. Ini membuatnya sangat berharga untuk industri seperti keuangan, pendidikan, dan perawatan kesehatan, di mana ekstraksi data terstruktur yang akurat sangat penting.
Teks dan Penalaran Matematis
Di luar tugas-tugas visi, Qwen2.5-VL-32B bersinar dalam aplikasi berbasis teks, terutama yang melibatkan penalaran matematis dan pengkodean. Skor tingginya pada tolok ukur seperti MATH dan HumanEval menunjukkan kemahirannya dalam memecahkan masalah aljabar yang kompleks, menafsirkan grafik fungsi, dan menghasilkan cuplikan kode yang akurat. Kemahiran ganda dalam visi dan teks ini memposisikan Qwen2.5-VL-32B sebagai solusi holistik untuk tantangan AI multimodal.

Di Mana Anda Dapat Menggunakan Qwen2.5-VL-32B
Akses Sumber Terbuka dan API
Qwen2.5-VL-32B tersedia di bawah lisensi Apache 2.0, menjadikannya sumber terbuka dan dapat diakses oleh pengembang di seluruh dunia. Anda dapat mengakses model melalui beberapa platform:
- Hugging Face: Model ini dihosting di Hugging Face, di mana Anda dapat mengunduhnya untuk penggunaan lokal atau mengintegrasikannya melalui pustaka Transformers.
- ModelScope: Platform ModelScope Alibaba menyediakan jalan lain untuk mengakses dan menerapkan model.
Untuk integrasi yang mulus, pengembang dapat menggunakan API Qwen, yang menyederhanakan interaksi dengan model. Apakah Anda sedang membangun aplikasi khusus atau bereksperimen dengan tugas-tugas multimodal, API Qwen memastikan konektivitas yang efisien dan kinerja yang kuat.
Penerapan dengan Mesin Inferensi
Qwen2.5-VL-32B mendukung penerapan dengan mesin inferensi seperti SGLang dan vLLM. Alat-alat ini mengoptimalkan model untuk inferensi cepat, mengurangi latensi dan penggunaan memori. Dengan memanfaatkan mesin-mesin ini, pengembang dapat menerapkan model pada perangkat keras lokal atau platform cloud, menyesuaikannya dengan kasus penggunaan tertentu.
Untuk memulai, instal pustaka yang diperlukan (misalnya, transformers, vllm) dan ikuti instruksi di halaman GitHub Qwen atau dokumentasi Hugging Face. Proses ini memastikan integrasi yang lancar, memungkinkan Anda untuk memanfaatkan potensi penuh model.
Mengoptimalkan Kinerja Lokal
Saat menjalankan Qwen2.5-VL-32B secara lokal, pertimbangkan tips optimasi ini:
- Kuantisasi: Tambahkan flag
--quantizeselama konversi untuk mengurangi persyaratan memori - Kelola panjang konteks: Batasi token input untuk respons yang lebih cepat
- Tutup aplikasi yang memakan banyak sumber daya saat menjalankan model
- Pemrosesan batch: Untuk beberapa gambar, proses dalam batch daripada satu per satu
Kesimpulan: Mengapa Qwen2.5-VL-32B Penting
Qwen2.5-VL-32B mewakili tonggak penting dalam evolusi model visi-bahasa. Dengan menggabungkan penalaran yang lebih cerdas, persyaratan sumber daya yang lebih ringan, dan kinerja yang kuat, model 32 miliar parameter ini memenuhi kebutuhan pengembang dan peneliti. Kemajuannya dalam penalaran matematis, penyelarasan preferensi manusia, dan tugas-tugas visi memposisikannya sebagai pilihan utama untuk penerapan lokal dan aplikasi dunia nyata.
Apakah Anda sedang membangun alat pendidikan, sistem intelijen bisnis, atau solusi dukungan pelanggan, Qwen2.5-VL-32B menawarkan fleksibilitas dan efisiensi yang Anda butuhkan. Dengan akses melalui platform sumber terbuka dan API Qwen, mengintegrasikan model ini ke dalam proyek Anda lebih mudah dari sebelumnya. Saat tim Qwen terus berinovasi, kita dapat mengharapkan perkembangan yang lebih menarik di masa depan AI multimodal.
Alat API ini memungkinkan Anda menguji dan men-debug titik akhir model Anda dengan mudah. Unduh Apidog secara gratis hari ini dan sederhanakan alur kerja Anda saat Anda menjelajahi kemampuan Mistral Small 3.1!


