
Qwen, inisiatif model fondasi terbuka dari Alibaba, secara konsisten mendorong batas-batas kecerdasan buatan melalui iterasi dan rilis yang cepat. Para pengembang dan peneliti dengan antusias menantikan setiap pembaruan, karena model Qwen sering kali menetapkan standar baru dalam kinerja dan keserbagunaan. Baru-baru ini, Qwen merilis tiga model inovatif: Qwen-Image-Edit-2509, Qwen3-TTS-Flash, dan Qwen3-Omni. Rilis-rilis ini meningkatkan kemampuan dalam pengeditan gambar, sintesis teks-ke-suara, dan pemrosesan omni-modal, secara berurutan.
Selain itu, model-model ini hadir pada momen penting dalam pengembangan AI, di mana integrasi multimodal menjadi esensial untuk aplikasi praktis. Qwen-Image-Edit-2509 menjawab permintaan akan manipulasi visual yang presisi, sementara Qwen3-TTS-Flash mengatasi masalah latensi dalam generasi suara. Sementara itu, Qwen3-Omni menyatukan berbagai input ke dalam kerangka kerja yang kohesif. Bersama-sama, mereka menunjukkan komitmen Qwen terhadap AI yang mudah diakses dan berkinerja tinggi. Namun, memahami dasar teknisnya memerlukan pemeriksaan lebih dekat. Artikel ini membedah setiap model, menyoroti fitur, arsitektur, tolok ukur, dan dampak potensialnya.
Qwen-Image-Edit-2509: Meningkatkan Presisi Pengeditan Gambar
Qwen-Image-Edit-2509 mewakili kemajuan signifikan dalam manipulasi gambar berbasis AI. Para insinyur di Qwen membangun kembali model ini untuk melayani para kreator, desainer, dan pengembang yang membutuhkan kontrol granular atas konten visual. Berbeda dengan iterasi sebelumnya, versi ini mendukung pengeditan multi-gambar, memungkinkan pengguna untuk menggabungkan elemen seperti seseorang dengan produk atau pemandangan dengan mudah. Akibatnya, ini menghilangkan artefak umum seperti perpaduan yang tidak cocok, menghasilkan keluaran yang koheren.

Model ini unggul dalam konsistensi gambar tunggal. Model ini mempertahankan identitas wajah di berbagai pose, gaya, dan filter, yang terbukti sangat berharga untuk aplikasi dalam periklanan dan personalisasi. Untuk gambar produk, Qwen-Image-Edit-2509 menjaga integritas objek, memastikan bahwa pengeditan tidak mendistorsi atribut-atribut penting. Selain itu, model ini menangani elemen teks secara komprehensif, memungkinkan modifikasi pada konten, font, warna, dan bahkan tekstur. Keserbagunaan ini berasal dari mekanisme ControlNet terintegrasi, yang menggabungkan peta kedalaman, deteksi tepi, dan titik kunci untuk panduan yang presisi.
Secara teknis, Qwen-Image-Edit-2509 dibangun di atas arsitektur dasar Qwen-Image tetapi menggabungkan teknik pelatihan canggih. Pengembang melatihnya menggunakan metode konkatenasi gambar untuk memfasilitasi input multi-gambar. Misalnya, menggabungkan "person + person" atau "person + scene" memanfaatkan aliran data yang digabungkan, meningkatkan kemampuan model untuk menggabungkan visual yang berbeda. Selain itu, arsitektur ini mengintegrasikan proses berbasis difusi, di mana noise secara progresif dihilangkan untuk menghasilkan gambar yang disempurnakan. Pendekatan ini, umum dalam varian difusi stabil, memungkinkan generasi kondisional berdasarkan perintah pengguna.
Dalam hal tolok ukur, Qwen-Image-Edit-2509 menunjukkan kinerja superior dalam metrik konsistensi. Evaluasi internal menunjukkan bahwa model ini mengungguli pesaing dalam pelestarian wajah, dengan skor kesamaan melebihi 95% di berbagai pengeditan. Tolok ukur konsistensi produk menunjukkan distorsi minimal, menjadikannya ideal untuk e-commerce. Namun, data kuantitatif dari sumber eksternal masih terbatas karena rilisnya yang baru-baru ini. Meskipun demikian, demonstrasi pengguna di platform seperti Hugging Face menyoroti keunggulannya dibandingkan model seperti Stable Diffusion XL dalam perpaduan multi-elemen.
Aplikasi berlimpah untuk Qwen-Image-Edit-2509. Pemasar menggunakannya untuk membuat iklan yang disesuaikan dengan mengedit penempatan produk secara mulus. Desainer menggunakannya untuk pembuatan prototipe cepat, mengubah pemandangan tanpa sentuhan manual. Selain itu, dalam game, ini memfasilitasi pembuatan aset dinamis. Salah satu contoh ilustratif melibatkan transformasi pakaian seseorang: gambar masukan seorang wanita dengan pakaian kasual, digabungkan dengan referensi gaun hitam, menghasilkan keluaran di mana gaun itu pas secara alami, mempertahankan postur dan pencahayaan. Kemampuan ini, seperti yang ditunjukkan dalam demo visual, menggarisbawahi kegunaan praktisnya.


Beralih ke implementasi, pengembang mengakses Qwen-Image-Edit-2509 melalui repositori GitHub dan ruang Hugging Face. Instalasi biasanya melibatkan kloning repositori dan pengaturan dependensi seperti PyTorch. Skrip penggunaan dasar mungkin terlihat seperti ini:
import torch
from qwen_image_edit import QwenImageEdit
model = QwenImageEdit.from_pretrained("Qwen/Qwen-Image-Edit-2509")
input_image = load_image("person.jpg")
reference_image = load_image("dress.jpg")
output = model.edit_multi(input_image, reference_image, prompt="Apply the black dress to the person")
output.save("edited.jpg")
Kode seperti itu memungkinkan iterasi cepat. Namun, pengguna harus mempertimbangkan persyaratan komputasi, karena inferensi membutuhkan akselerasi GPU untuk kecepatan optimal.
Meskipun memiliki kekuatan, Qwen-Image-Edit-2509 menghadapi tantangan. Pengeditan resolusi tinggi dapat mengonsumsi memori yang signifikan, dan perintah yang kompleks terkadang menyebabkan inkonsistensi. Meskipun demikian, kontribusi komunitas yang berkelanjutan melalui saluran sumber terbuka mengurangi masalah ini. Secara keseluruhan, model ini mendefinisikan ulang pengeditan gambar dengan menggabungkan presisi dengan aksesibilitas.
Qwen3-TTS-Flash: Mempercepat Sintesis Teks-ke-Suara
Qwen3-TTS-Flash muncul sebagai kekuatan besar dalam teknologi teks-ke-suara (TTS), memprioritaskan kecepatan dan kealamian. Insinyur Qwen merancangnya untuk menghasilkan suara seperti manusia dengan latensi minimal, mengatasi hambatan dalam aplikasi waktu nyata. Secara khusus, model ini mencapai latensi paket pertama hanya 97ms dalam lingkungan single-threaded, memungkinkan interaksi yang lancar dalam chatbot dan asisten virtual.
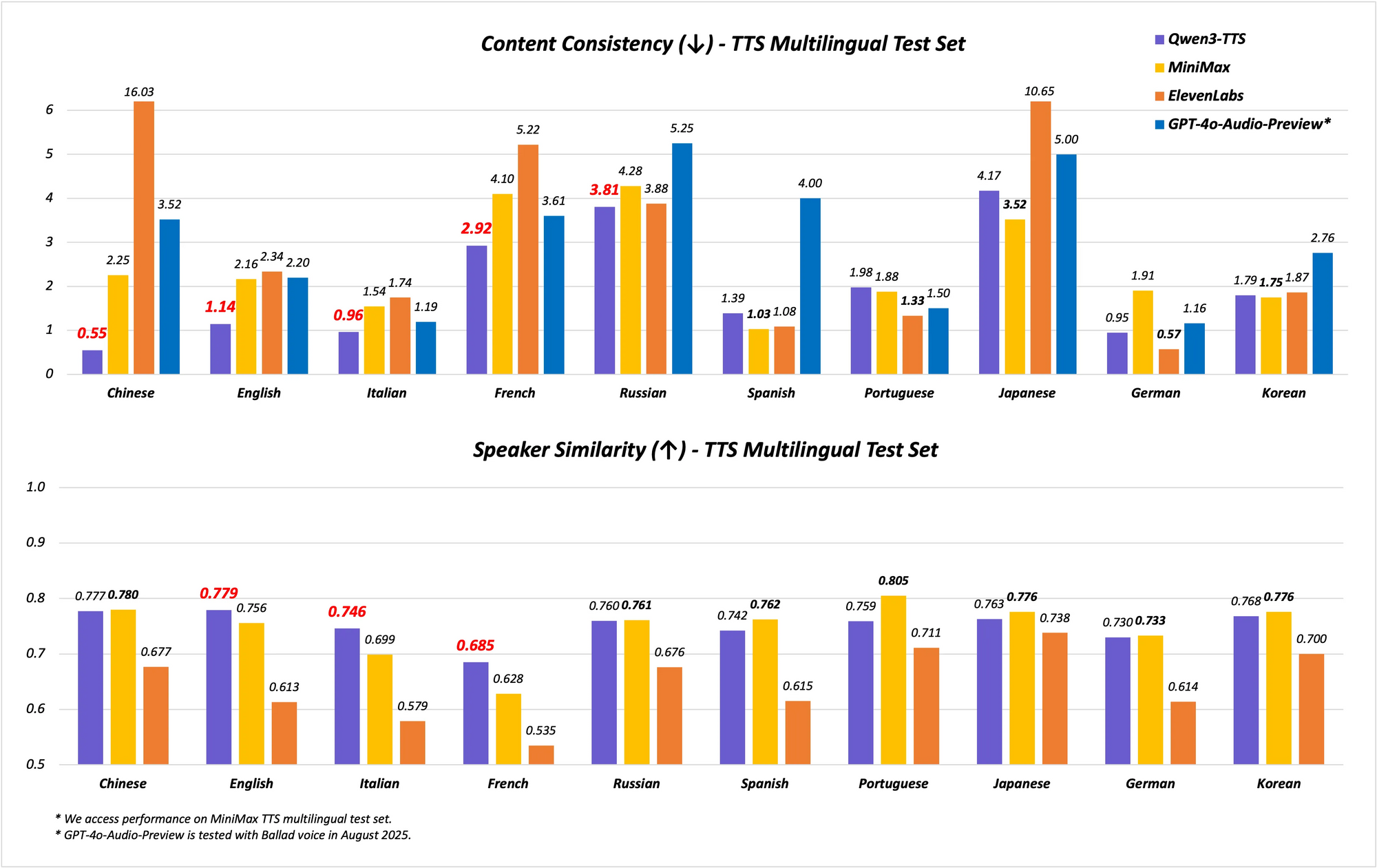
Model ini mendukung kemampuan multibahasa dan multi-dialek, mencakup 10 bahasa dengan 17 suara ekspresif. Model ini unggul dalam stabilitas bahasa Mandarin dan Inggris, mencapai kinerja tercanggih (SOTA) pada tolok ukur seperti set uji Seed-TTS-Eval. Di sini, model ini melampaui model seperti SeedTTS, MiniMax, dan GPT-4o-Audio-Preview dalam metrik stabilitas. Selain itu, dalam evaluasi multibahasa pada set uji MiniMax TTS, Qwen3-TTS-Flash mencatat Tingkat Kesalahan Kata (WER) terendah untuk bahasa Mandarin, Inggris, Italia, dan Prancis.
Dukungan dialek membedakan Qwen3-TTS-Flash. Model ini menangani sembilan dialek Mandarin, termasuk Kanton, Hokkien, Sichuan, Beijing, Nanjing, Tianjin, dan Shaanxi. Fitur ini memungkinkan ucapan yang bernuansa budaya, penting di pasar yang beragam. Selain itu, model ini menyesuaikan nada secara otomatis, mengambil dari data pelatihan skala besar untuk mencocokkan sentimen masukan. Penanganan teks yang kuat semakin meningkatkan keandalan, karena mengekstrak informasi kunci dari format kompleks seperti tanggal, angka, dan akronim.
Secara arsitektur, Qwen3-TTS-Flash menggunakan kerangka kerja encoder-decoder berbasis transformer, yang dioptimalkan untuk inferensi latensi rendah. Model ini menggunakan representasi multi-codebook untuk pemodelan suara yang lebih kaya, meningkatkan ekspresivitas. Pelatihan melibatkan kumpulan data besar yang mencakup 119 bahasa untuk teks dan 19 untuk pemahaman ucapan, meskipun output berfokus pada 10 bahasa. Pengaturan ini memungkinkan generasi lintas bahasa, di mana input dalam satu bahasa menghasilkan output dalam bahasa lain secara mulus.

Tolok ukur mengilustrasikan kehebatannya. Pada uji stabilitas, Qwen3-TTS-Flash mencetak skor lebih tinggi dalam kesamaan timbre dan kealamian dibandingkan dengan ElevenLabs dan GPT-4o. Misalnya:
| Tolok Ukur | Qwen3-TTS-Flash | MiniMax | GPT-4o-Audio-Preview |
|---|---|---|---|
| Stabilitas Bahasa Mandarin | SOTA | Lebih Rendah | Lebih Rendah |
| WER Bahasa Inggris | Terendah | Lebih Tinggi | Lebih Tinggi |
| Kesamaan Timbre Multibahasa | SOTA | Lebih Rendah | Lebih Rendah |
Hasil-hasil ini berasal dari evaluasi yang ketat, memposisikannya sebagai pemimpin dalam TTS.
Dalam demonstrasi, Qwen3-TTS-Flash menghasilkan ucapan ekspresif, seperti mendeskripsikan "honey lavender latte" dengan antusiasme atau menangani dialog dalam dialek. Transkrip video mengungkapkan kemampuannya untuk memproses input bahasa campuran, seperti "I'm really happy today. I know that girl from China," yang disampaikan dengan suara beraksen. Aplikasi termasuk sistem respons suara interaktif (IVR), NPC game, dan pembuatan konten, di mana latensi rendah menggandakan efisiensi.
Implementasi memerlukan akses ke model melalui API atau demo Hugging Face. Contoh pemanggilan Python:
from qwen_tts import QwenTTSFlash
model = QwenTTSFlash.from_pretrained("Qwen/Qwen3-TTS-Flash")
audio = model.synthesize(text="Hello, world!", voice="expressive_english", dialect="sichuanese")
audio.save("output.wav")
Kesederhanaan ini mempercepat pengembangan. Namun, akurasi dialek dapat bervariasi dengan input yang jarang, sehingga memerlukan penyesuaian.
Qwen3-TTS-Flash mengubah TTS dengan menyeimbangkan kecepatan, kualitas, dan keragaman, menjadikannya sangat diperlukan untuk sistem AI modern.
Memperkenalkan Qwen3-Omni: Kekuatan Multimodal Terpadu
Memperkenalkan Qwen3-Omni menandai tonggak sejarah dalam AI multimodal, karena Qwen mengintegrasikan teks, gambar, audio, dan video ke dalam satu model end-to-end. Unifikasi asli ini menghindari pertukaran modalitas, memungkinkan penalaran lintas-modal yang lebih dalam. Model ini memproses 119 bahasa untuk teks, 19 untuk input ucapan, dan 10 untuk output ucapan, dengan latensi respons yang luar biasa 211ms.
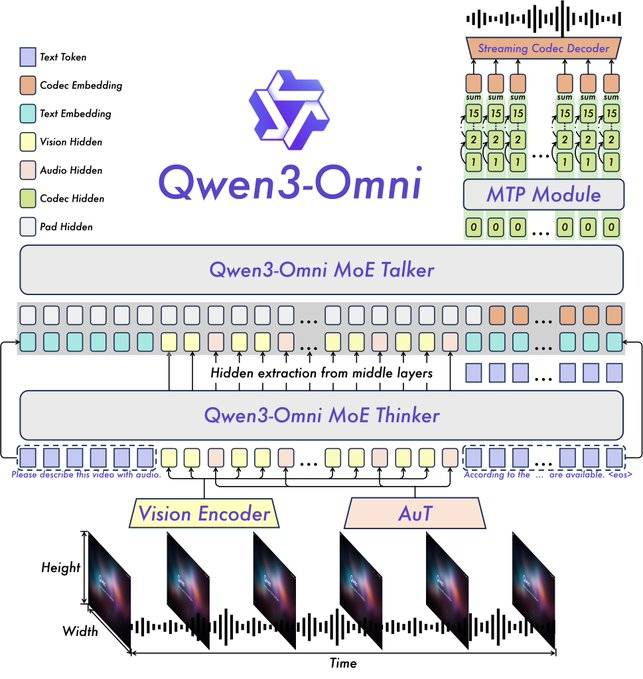
Fitur-fitur utama meliputi kinerja SOTA pada 22 dari 36 tolok ukur audio dan audio-visual, prompt sistem yang dapat disesuaikan, pemanggilan alat bawaan, dan model captioner sumber terbuka dengan tingkat halusinasi rendah. Qwen merilis varian sumber terbuka seperti Qwen3-Omni-30B-A3B-Instruct untuk mengikuti instruksi dan Qwen3-Omni-30B-A3B-Thinking untuk penalaran yang ditingkatkan.
Arsitekturnya dibangun di atas kerangka kerja Thinker-Talker dari Qwen2.5-Omni, dengan peningkatan seperti penggantian encoder audio Whisper dengan Audio Transformer (AuT) untuk representasi yang lebih baik. Penanganan ucapan multi-codebook memperkaya output suara, sementara konteks yang diperluas mendukung audio lebih dari 30 menit. Ini memungkinkan penalaran modalitas penuh, di mana input video menginformasikan respons audio.
Tolok ukur mengkonfirmasi dominasinya. Model ini mencapai SOTA keseluruhan pada 32 tolok ukur, unggul dalam pemahaman dan generasi audio. Misalnya, dalam tugas audio-visual, model ini mengungguli model seperti GPT-4o dalam latensi dan akurasi. Tabel perbandingan:
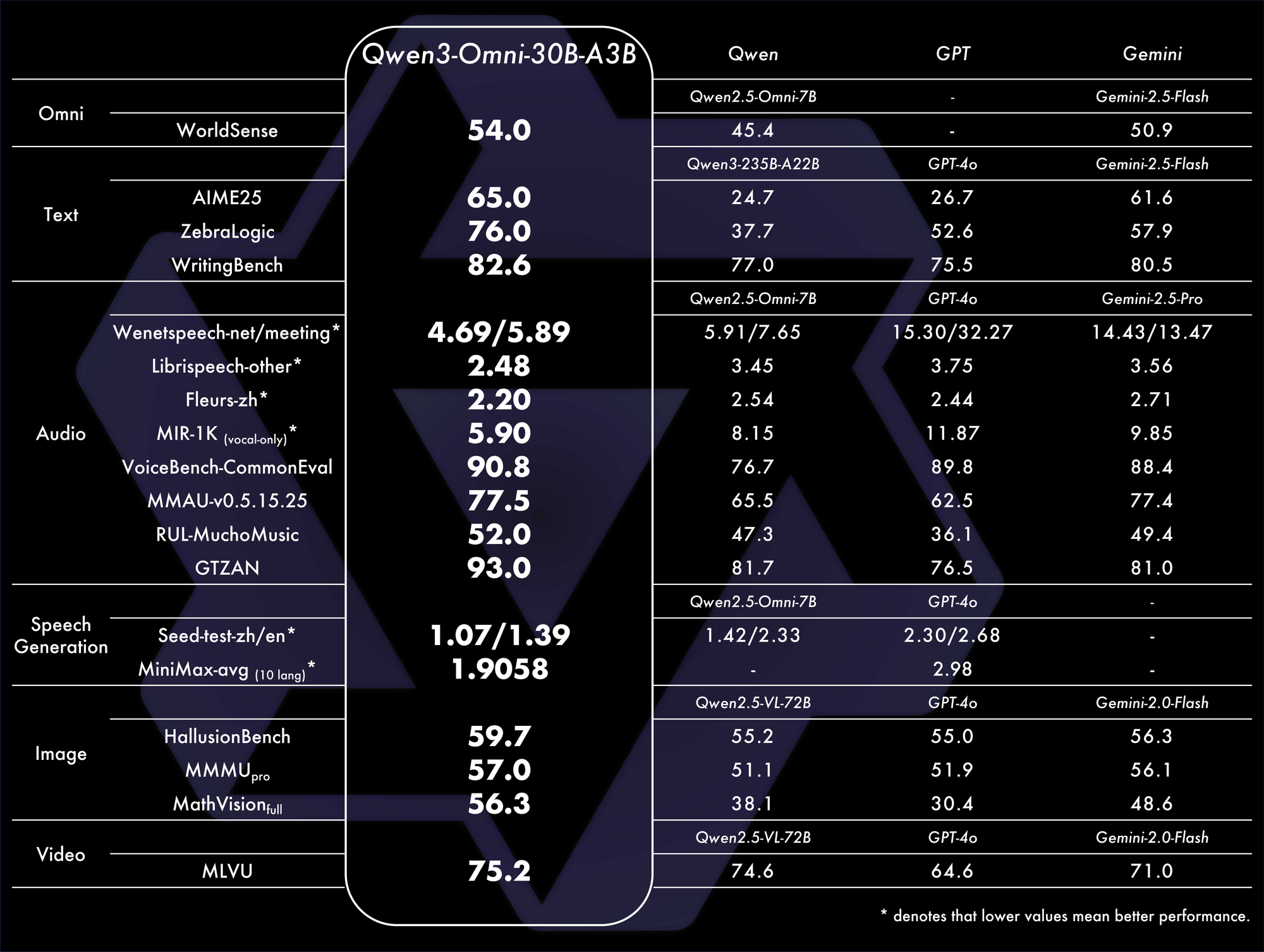
Metrik-metrik ini menyoroti efisiensinya dalam skenario dunia nyata.
Aplikasi mencakup obrolan suara, analisis video, dan agen multimodal. Misalnya, model ini menganalisis klip video dan menghasilkan ringkasan lisan, ideal untuk alat aksesibilitas. Demo di Qwen Chat menampilkan interaksi suara dan video, di mana pengguna menanyakan gambar atau audio secara verbal.
Dari GitHub, README menggambarkannya sebagai mampu menghasilkan ucapan waktu nyata dari berbagai input. Pengaturan melibatkan:
from qwen_omni import Qwen3Omni
model = Qwen3Omni.from_pretrained("Qwen/Qwen3-Omni-30B-A3B-Instruct")
response = model.process(inputs={"text": "Describe this", "image": "img.jpg", "audio": "clip.wav"})
print(response.text)
response.audio.save("reply.wav")
Pendekatan modular ini memfasilitasi kustomisasi. Tantangan termasuk tuntutan komputasi tinggi untuk pemrosesan video, tetapi optimasi seperti kuantisasi membantu.
Memperkenalkan Qwen3-Omni mengkonsolidasikan modalitas, mendorong ekosistem AI yang inovatif.
Sinergi Antara Model-Model Baru Qwen dan Implikasi Masa Depan
Qwen-Image-Edit-2509, Qwen3-TTS-Flash, dan Qwen3-Omni saling melengkapi, memungkinkan alur kerja end-to-end. Misalnya, edit gambar dengan Qwen-Image-Edit-2509, deskripsikan melalui Qwen3-Omni, dan suarakan output dengan Qwen3-TTS-Flash. Integrasi ini memperkuat utilitas dalam pembuatan konten dan otomatisasi.
Selain itu, sifat sumber terbuka mereka mengundang peningkatan komunitas. Pengembang yang menggunakan Apidog dapat menguji API secara efisien, memastikan integrasi yang kuat.
Namun, pertimbangan etika muncul, seperti penyalahgunaan dalam deepfake. Qwen mengurangi hal ini melalui perlindungan.
Sebagai kesimpulan, rilis-rilis Qwen mendefinisikan ulang lanskap AI. Dengan memajukan batas-batas teknis, mereka memberdayakan pengguna untuk mencapai lebih banyak. Seiring dengan pertumbuhan adopsi, model-model ini akan mendorong gelombang inovasi berikutnya.