
Qwen-Image, sebuah model fondasi gambar MMDiT 20B mutakhir dari tim Qwen Alibaba Cloud, mendefinisikan ulang kemungkinan kreasi visual berbasis AI. Diluncurkan pada 4 Agustus 2025, model ini memberikan kemampuan yang tak tertandingi dalam menghasilkan gambar berkualitas tinggi, merender teks multibahasa yang kompleks, dan melakukan pengeditan gambar yang presisi. Baik Anda membuat visual pemasaran yang dinamis atau menganalisis data gambar yang rumit, Qwen-Image memberdayakan pengembang dengan alat yang tangguh untuk mewujudkan ide.
Apa Itu Qwen-Image? Tinjauan Teknis
Qwen-Image, bagian dari seri Qwen Alibaba Cloud, adalah model transformer difusi multimodal (MMDiT) dengan 20 miliar parameter, dirancang untuk pembuatan dan pengeditan gambar. Berbeda dengan model tradisional yang hanya berfokus pada pembuatan visual, Qwen-Image mengintegrasikan rendering teks canggih dan pemahaman gambar, menjadikannya alat serbaguna untuk tugas kreatif dan analitis. Model ini, yang bersumber terbuka di bawah lisensi Apache 2.0, dapat diakses melalui platform seperti GitHub, Hugging Face, dan ModelScope, memungkinkan pengembang untuk mengintegrasikannya ke dalam alur kerja yang beragam.

Selain itu, Qwen-Image memanfaatkan dataset pratinjau yang kuat, menggabungkan lebih dari 30 triliun token di 119 bahasa, dengan fokus pada bahasa Mandarin dan Inggris. Dataset yang ekstensif ini, dikombinasikan dengan teknik pembelajaran penguatan, memungkinkan model untuk menangani tugas-tugas kompleks seperti rendering teks multibahasa dan manipulasi objek yang presisi. Akibatnya, ia mengungguli banyak model yang ada pada tolok ukur seperti GenEval, DPG, dan LongText-Bench.
Fitur Utama Qwen-Image
Rendering Teks Unggul untuk Visual Multibahasa
Qwen-Image unggul dalam merender teks kompleks dalam gambar, fitur yang membedakannya dari pesaing. Ini mendukung bahasa alfabet (misalnya, Inggris) dan skrip logografis (misalnya, Mandarin), memastikan integrasi teks dengan fidelitas tinggi. Misalnya, model dapat menghasilkan poster film dengan tata letak teks yang presisi, seperti judul “Imagination Unleashed” dan subtitle dalam beberapa baris, menjaga koherensi tipografi. Kemampuan ini berasal dari pelatihannya pada dataset yang beragam, termasuk LongText-Bench dan ChineseWord, di mana ia mencapai kinerja canggih.
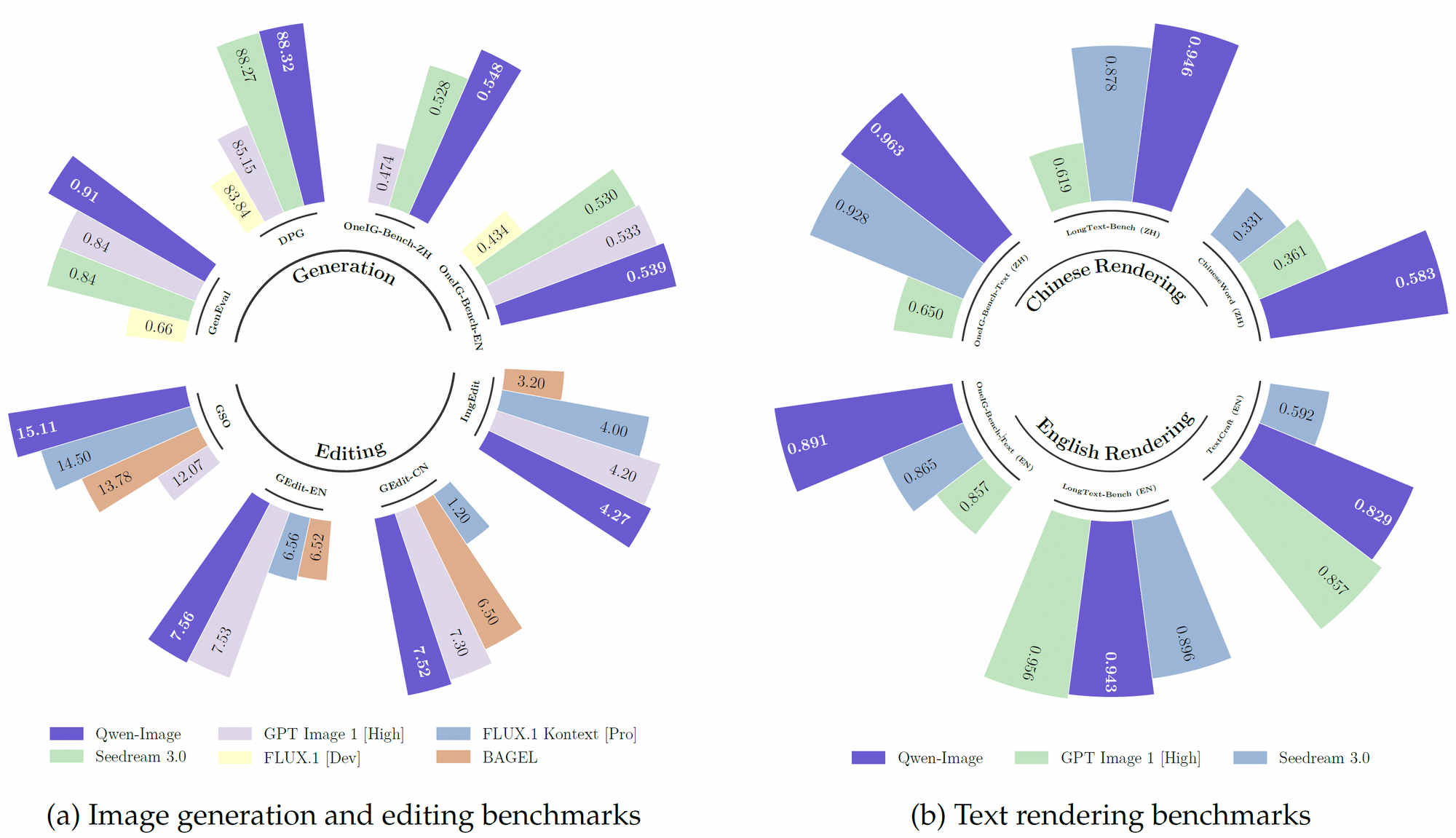
Selain itu, Qwen-Image menangani tata letak multi-baris dan semantik tingkat paragraf dengan akurasi yang luar biasa. Dalam skenario pengujian, ia secara akurat merender puisi tulisan tangan di atas kertas menguning di dalam gambar, meskipun teks menempati kurang dari sepersepuluh ruang visual. Presisi ini membuatnya ideal untuk aplikasi seperti papan nama digital, desain poster, dan visualisasi dokumen.
Kemampuan Pengeditan Gambar Tingkat Lanjut
Selain rendering teks, Qwen-Image menawarkan fitur pengeditan gambar yang canggih. Ini mendukung operasi seperti transfer gaya, penyisipan objek, peningkatan detail, dan manipulasi pose manusia. Misalnya, pengguna dapat menginstruksikan model untuk "menambahkan langit cerah ke gambar ini" atau "mengubah lukisan ini menjadi gaya Van Gogh," dan Qwen-Image memberikan hasil yang koheren. Paradigma pelatihan multi-tugas yang ditingkatkan memastikan bahwa pengeditan mempertahankan makna semantik dan realisme visual.
Selain itu, kemampuan model untuk mengedit teks dalam gambar sangat patut dicatat. Pengembang dapat memodifikasi teks pada tanda atau poster tanpa mengganggu konteks visual di sekitarnya, fitur yang berharga untuk periklanan dan pembuatan konten. Kemampuan ini didukung oleh pemahaman visual mendalam Qwen-Image, yang memungkinkannya untuk menginterpretasikan dan memanipulasi elemen gambar dengan presisi.
Pemahaman Visual Komprehensif
Qwen-Image tidak hanya membuat atau mengedit—ia memahami. Model ini mendukung serangkaian tugas pemahaman gambar, termasuk deteksi objek, segmentasi semantik, estimasi kedalaman, deteksi tepi (Canny), sintesis tampilan baru, dan super-resolusi. Tugas-tugas ini didukung oleh kemampuannya untuk memproses input resolusi tinggi dan mengekstrak detail halus. Misalnya, Qwen-Image dapat menghasilkan kotak pembatas untuk objek yang dijelaskan dalam bahasa alami, seperti "deteksi anjing Husky di adegan kereta bawah tanah," menjadikannya alat yang ampuh untuk analisis visual.
Selain itu, dukungannya untuk berbagai bahasa meningkatkan kegunaannya dalam aplikasi global. Dengan berintegrasi dengan alat seperti Qwen-Plus Prompt Enhancement Tool, pengembang dapat mengoptimalkan prompt untuk kinerja multibahasa yang lebih baik, memastikan hasil yang akurat di berbagai konteks linguistik.
Keunggulan Kinerja Lintas Tolok Ukur
Qwen-Image secara konsisten mengungguli pesaing pada beberapa tolok ukur publik, termasuk GenEval, DPG, OneIG-Bench, GEdit, ImgEdit, dan GSO. Kinerja unggulnya dalam rendering teks, terutama untuk bahasa Mandarin, terlihat jelas dalam tolok ukur seperti TextCraft, di mana ia melampaui model canggih yang ada. Selain itu, kemampuan pembuatan gambar umumnya mendukung berbagai gaya artistik, dari adegan fotorealistik hingga estetika anime, menjadikannya pilihan serbaguna untuk profesional kreatif.
Arsitektur Teknis Qwen-Image
Transformer Difusi Multimodal (MMDiT)
Pada intinya, Qwen-Image menggunakan arsitektur Multimodal Diffusion Transformer (MMDiT), yang menggabungkan kekuatan model difusi dan transformer. Pendekatan hibrida ini memungkinkan model untuk memproses input visual dan tekstual secara efisien. Proses difusi secara iteratif menyempurnakan input yang berisik menjadi gambar yang koheren, sementara komponen transformer menangani hubungan kompleks antara elemen teks dan visual.
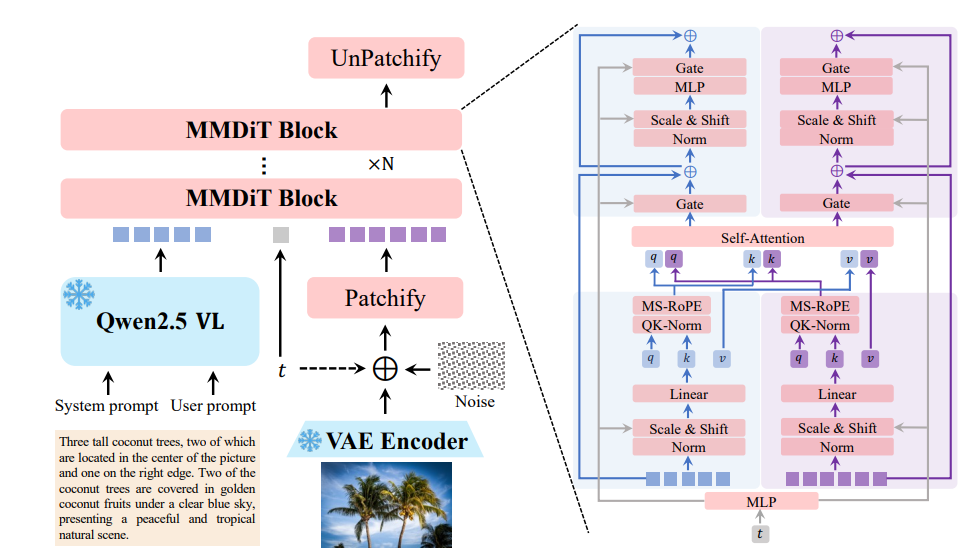
20 miliar parameter model dioptimalkan untuk efisiensi, memungkinkannya berjalan pada perangkat keras kelas konsumen dengan VRAM sesedikit 4GB saat menggunakan teknik seperti kuantisasi FP8 dan offloading lapis demi lapis. Aksesibilitas ini membuat Qwen-Image cocok untuk pengembang perusahaan maupun individu.
Pelatihan Awal dan Penyesuaian (Fine-Tuning)
Dataset pelatihan awal Qwen-Image adalah landasan kinerjanya. Mencakup lebih dari 30 triliun token, dataset ini mencakup data web, dokumen mirip PDF, dan data sintetis yang dihasilkan oleh model seperti Qwen2.5-VL dan Qwen2.5-Coder. Proses pelatihan awal terjadi dalam tiga tahap:

- Tahap 1 (S1): Model dilatih awal pada 30 triliun token dengan panjang konteks 4K token, membangun keterampilan bahasa dan visual dasar.
- Tahap 2: Pembelajaran penguatan meningkatkan kemampuan penalaran dan tugas spesifik model.
- Tahap 3: Penyesuaian dengan dataset yang dikurasi meningkatkan keselarasan dengan preferensi pengguna dan tugas spesifik seperti rendering teks dan pengeditan gambar.
Pendekatan multi-tahap ini memastikan bahwa Qwen-Image tangguh dan mudah beradaptasi, mampu menangani berbagai tugas dengan akurasi tinggi.
Integrasi dengan Alat Pengembangan
Qwen-Image terintegrasi dengan mulus dengan kerangka kerja pengembangan populer seperti Diffusers dan DiffSynth-Studio. Misalnya, pengembang dapat menggunakan kode Python berikut untuk menghasilkan gambar dengan Qwen-Image:
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
prompt = "A coffee shop entrance with a chalkboard sign reading 'Qwen Coffee 😊 $2 per cup.'"
image = pipe(prompt).images[0]
image.save("qwen_coffee.png")
Cuplikan kode ini menunjukkan bagaimana pengembang dapat memanfaatkan kemampuan Qwen-Image untuk menghasilkan visual berkualitas tinggi dengan pengaturan minimal. Alat seperti Apidog lebih lanjut menyederhanakan integrasi API, memungkinkan prototipe dan penyebaran yang cepat.
Aplikasi Praktis Qwen-Image
Pembuatan Konten Kreatif
Kemampuan Qwen-Image untuk menghasilkan adegan fotorealistik, lukisan impresionis, dan visual gaya anime menjadikannya alat yang ampuh bagi seniman dan desainer. Misalnya, seorang desainer grafis dapat membuat poster film dengan tata letak teks dinamis dan citra yang hidup, seperti yang ditunjukkan dalam kasus uji di mana Qwen-Image menghasilkan poster untuk “Imagination Unleashed” dengan komputer futuristik yang memancarkan makhluk aneh.

Periklanan dan Pemasaran
Dalam periklanan, kemampuan rendering dan pengeditan teks Qwen-Image memungkinkan pembuatan kampanye yang menarik secara visual. Pemasar dapat menghasilkan poster dengan penempatan teks yang presisi atau mengedit visual yang ada untuk memperbarui pesan promosi, memastikan konsistensi merek dan koherensi visual.

Analisis Visual dan Otomatisasi
Untuk industri seperti e-commerce dan sistem otonom, tugas pemahaman gambar Qwen-Image—seperti deteksi objek dan segmentasi semantik—menawarkan nilai yang signifikan. Platform ritel dapat menggunakan model untuk secara otomatis menandai produk dalam gambar, sementara kendaraan otonom dapat memanfaatkan estimasi kedalamannya untuk navigasi.
Alat Pendidikan
Kemampuan Qwen-Image untuk menghasilkan visual pendidikan, seperti diagram dengan anotasi teks yang akurat, mendukung platform e-learning. Misalnya, ia dapat membuat ilustrasi rinci tentang konsep ilmiah dengan komponen berlabel, meningkatkan keterlibatan dan pemahaman siswa.

Membandingkan Qwen-Image dengan Pesaing
Ketika dibandingkan dengan model seperti DALL-E 3 dan Stable Diffusion, Qwen-Image menonjol karena rendering teks multibahasa dan kemampuan pengeditan canggihnya. Sementara DALL-E 3 unggul dalam pembuatan gambar kreatif, ia kesulitan dengan tata letak teks yang kompleks, terutama untuk skrip logografis. Stable Diffusion, meskipun serbaguna, tidak memiliki pemahaman visual mendalam yang ditawarkan oleh serangkaian tugas pemahaman Qwen-Image.
Selain itu, sifat sumber terbuka Qwen-Image dan kompatibilitas dengan perangkat keras memori rendah memberinya keunggulan bagi pengembang dengan sumber daya terbatas. Kinerjanya pada tolok ukur seperti TextCraft dan GEdit semakin memperkuat posisinya sebagai model terkemuka dalam AI multimodal.
Tantangan dan Keterbatasan
Meskipun memiliki kekuatan, Qwen-Image menghadapi tantangan. Ketergantungan model pada dataset berskala besar menimbulkan kekhawatiran tentang privasi data dan sumber etis, meskipun Alibaba Cloud mematuhi pedoman ketat. Selain itu, meskipun model mendukung lebih dari 100 bahasa, kinerjanya mungkin bervariasi untuk dialek yang kurang terwakili, memerlukan penyesuaian lebih lanjut.
Selain itu, tuntutan komputasi model parameter 20B dapat signifikan tanpa teknik optimasi seperti kuantisasi FP8. Pengembang harus menyeimbangkan kinerja dan batasan sumber daya saat menyebarkan Qwen-Image di lingkungan produksi.
Prospek Masa Depan untuk Qwen-Image
Ke depan, Qwen-Image siap untuk berkembang lebih jauh. Tim Qwen berencana untuk merilis versi model khusus pengeditan, meningkatkan kemampuannya untuk aplikasi kelas profesional. Integrasi dengan kerangka kerja yang muncul seperti vLLM dan dukungan berkelanjutan untuk alur kerja LoRA dan penyesuaian akan memperluas aksesibilitasnya.
Selain itu, kemajuan dalam pembelajaran penguatan, seperti yang terlihat pada model seperti Qwen3, menunjukkan bahwa Qwen-Image dapat menggabungkan kemampuan penalaran yang lebih dalam, memungkinkan tugas penalaran visual yang lebih kompleks. Seiring komunitas AI terus berkontribusi pada pengembangannya, Qwen-Image memiliki potensi untuk mendefinisikan ulang kreasi dan pemahaman visual.
Memulai dengan Qwen-Image
Untuk mulai menggunakan Qwen-Image, pengembang dapat mengakses bobot model di GitHub atau Hugging Face. Blog resmi di qwenlm.github.io menyediakan instruksi pengaturan dan kasus penggunaan terperinci. Untuk pengalaman langsung, kunjungi Qwen Chat dan pilih “Image Generation” untuk menguji kemampuan model.
Untuk integrasi API, alat seperti Apidog menyederhanakan proses dengan menawarkan antarmuka yang ramah pengguna untuk menguji dan menyebarkan fitur Qwen-Image. Unduh Apidog secara gratis untuk menyederhanakan alur kerja pengembangan Anda.
Kesimpulan: Mengapa Qwen-Image Penting
Qwen-Image mewakili lompatan signifikan dalam AI multimodal, menggabungkan rendering teks canggih, pengeditan gambar yang presisi, dan pemahaman visual yang kuat. Ketersediaan sumber terbukanya, pelatihan awal yang ekstensif, dan kompatibilitas dengan alat pengembangan menjadikannya pilihan serbaguna untuk kreator, pengembang, dan peneliti. Dengan mengatasi tantangan seperti dukungan multibahasa dan efisiensi sumber daya, Qwen-Image menetapkan standar baru untuk kreasi visual berbasis AI.
Seiring AI terus berkembang, model seperti Qwen-Image akan memainkan peran penting dalam menjembatani kesenjangan antara bahasa dan citra, membuka kemungkinan baru untuk aplikasi kreatif dan analitis. Baik Anda membangun kampanye pemasaran, menganalisis data visual, atau membuat konten pendidikan, Qwen-Image menawarkan alat untuk mewujudkan visi Anda.