
Di dunia kecerdasan buatan yang berkembang pesat, tonggak sejarah baru telah tercapai dengan dirilisnya Qwen 2.5 Omni 7B. Model revolusioner dari Alibaba Cloud ini mewakili lompatan signifikan dalam AI multimodal, menggabungkan kemampuan untuk memproses dan memahami berbagai bentuk input sambil menghasilkan output teks dan ucapan. Mari kita selami apa yang membuat model ini benar-benar istimewa dan bagaimana model ini membentuk kembali pemahaman kita tentang kemampuan AI.
Arti Sebenarnya dari "Omni" dalam Qwen 2.5 Omni 7B
Istilah "Omni" dalam Qwen 2.5 Omni 7B bukan hanya merek yang cerdas—ini adalah deskripsi mendasar dari kemampuan model. Tidak seperti banyak model multimodal yang unggul dalam satu atau dua jenis data, Qwen 2.5 Omni 7B dirancang dari awal untuk memahami dan mengerti:
- Teks (bahasa tertulis)
- Gambar (informasi visual)
- Audio (suara dan bahasa lisan)
- Video (konten visual bergerak dengan dimensi temporal)
Voice Chat + Video Chat! Just in Qwen Chat (https://t.co/FmQ0B9tiE7)! You can now chat with Qwen just like making a phone call or making a video call! Check the demo in https://t.co/42iDe4j1Hs
— Qwen (@Alibaba_Qwen) March 26, 2025
What's more, we opensource the model behind all this, Qwen2.5-Omni-7B, under the… pic.twitter.com/LHQOQrl9Ha
Yang lebih mengesankan adalah bahwa model ini tidak hanya menerima input yang bervariasi ini—ia dapat merespons dengan output teks dan ucapan alami secara streaming. Kemampuan "apa pun ke apa pun" ini mewakili kemajuan signifikan menuju interaksi AI yang lebih alami dan mirip manusia.
Arsitektur Inovatif Qwen 2.5 Omni 7B: Dijelaskan
Thinker-Talker: Paradigma Baru
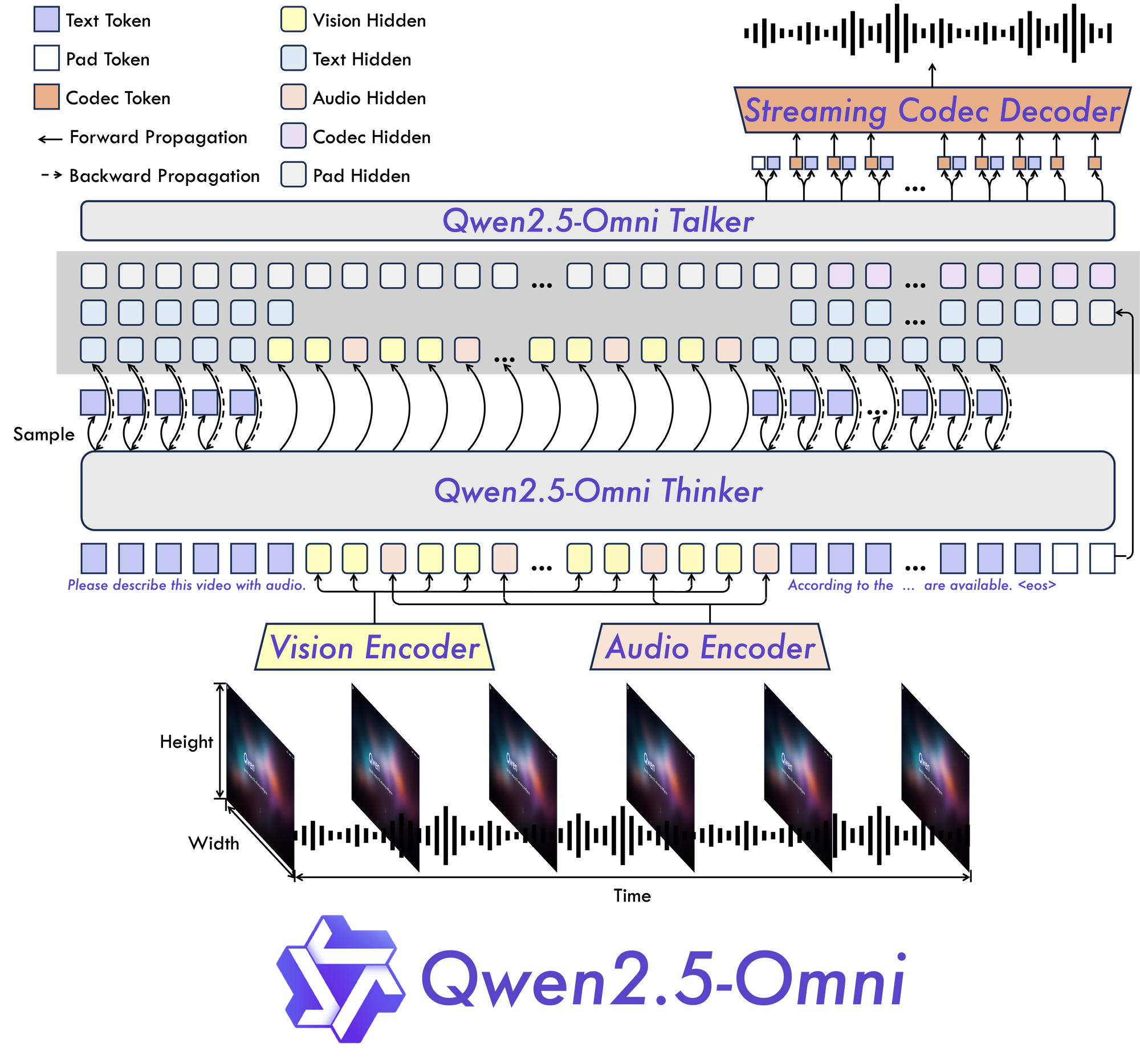
Inti dari Qwen 2.5 Omni 7B terletak pada arsitektur dasar "Thinker-Talker". Desain baru ini menciptakan model yang secara khusus dibangun untuk menjadi multimodal ujung-ke-ujung, memungkinkan pemrosesan yang mulus di berbagai jenis informasi.
Seperti namanya, arsitektur ini memisahkan pemrosesan kognitif informasi (berpikir) dari pembuatan output (berbicara). Pemisahan ini memungkinkan model untuk secara efektif mengelola kompleksitas inheren dari data multimodal dan menghasilkan respons yang sesuai dalam berbagai format.
TMRoPE: Memecahkan Tantangan Penyelarasan Temporal
Salah satu inovasi paling signifikan dalam Qwen 2.5 Omni 7B adalah mekanisme Time-aligned Multimodal RoPE (TMRoPE). Terobosan ini mengatasi salah satu aspek paling menantang dari AI multimodal: menyinkronkan data temporal dari berbagai sumber.
Saat memproses video dan audio secara bersamaan, model perlu memahami bagaimana peristiwa visual selaras dengan suara atau ucapan yang sesuai. Misalnya, mencocokkan gerakan bibir seseorang dengan kata-kata yang diucapkannya memerlukan penyelarasan temporal yang tepat. TMRoPE menyediakan kerangka kerja canggih untuk mencapai sinkronisasi ini, memungkinkan model untuk membangun pemahaman yang koheren tentang input multimodal yang terungkap dari waktu ke waktu.
Dirancang untuk Interaksi Waktu Nyata
Qwen 2.5 Omni 7B dibangun dengan mempertimbangkan aplikasi waktu nyata. Arsitektur ini mendukung streaming latensi rendah, memungkinkan pemrosesan input yang dipotong-potong dan pembuatan output segera. Ini membuatnya ideal untuk aplikasi yang membutuhkan interaksi responsif, seperti asisten suara, analisis video langsung, atau layanan terjemahan waktu nyata.
Kinerja Qwen 2.5 Omni 7B: Tolok Ukur Berbicara Sendiri
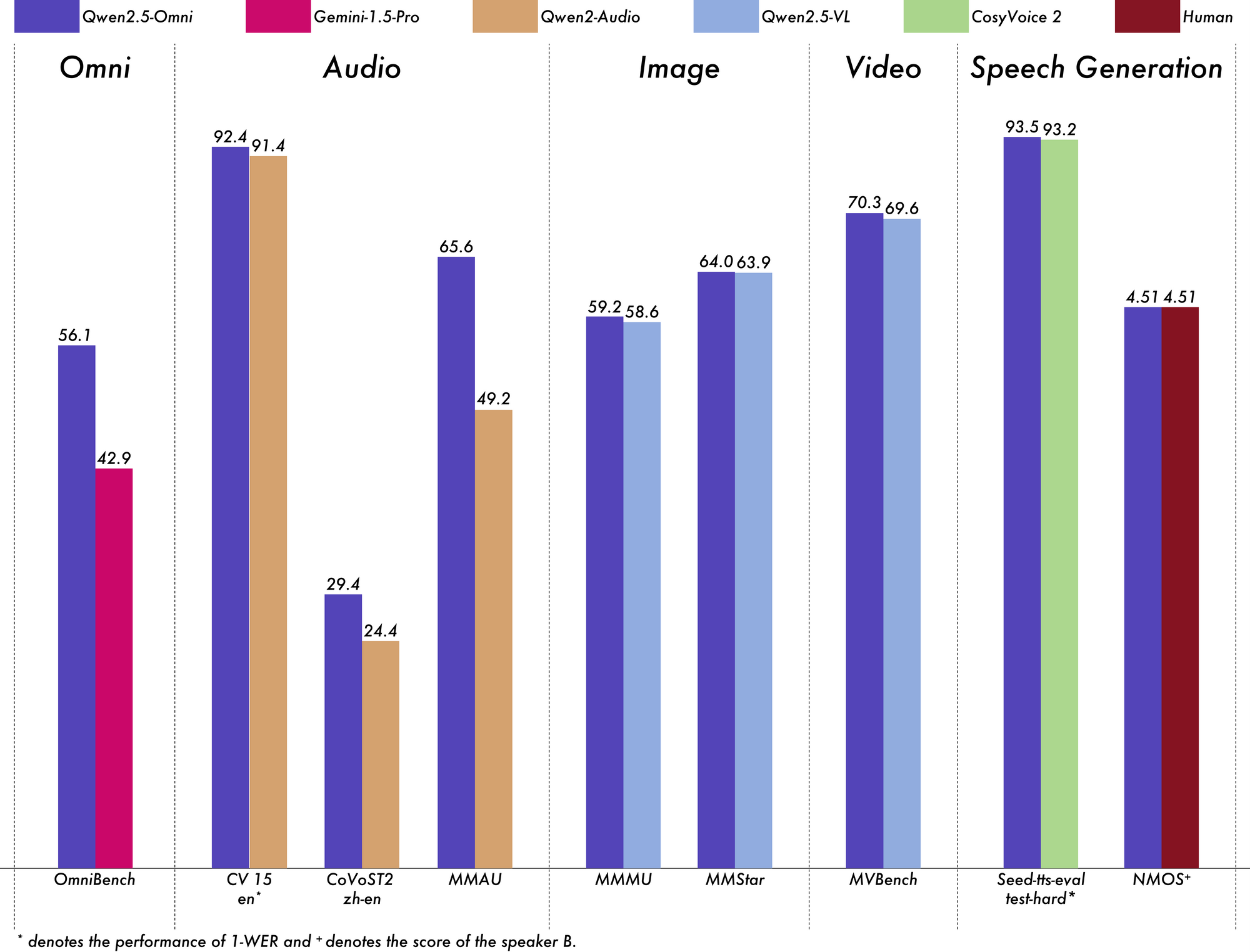
Uji sebenarnya dari setiap model AI adalah kinerjanya di seluruh tolok ukur yang ketat, dan Qwen 2.5 Omni 7B memberikan hasil yang mengesankan di seluruh bidang.
Memimpin dalam Pemahaman Multimodal
Pada tolok ukur OmniBench untuk pemahaman multimodal umum, Qwen 2.5 Omni 7B mencapai skor rata-rata 56,13%. Ini secara signifikan mengungguli model lain seperti Gemini-1.5-Pro (42,91%) dan MIO-Instruct (33,80%). Kinerja luar biasa dalam kategori OmniBench tertentu sangat penting:
- Tugas ucapan: 55,25%
- Tugas Peristiwa Suara: 60,00%
- Tugas musik: 52,83%
Kinerja komprehensif ini menunjukkan kemampuan model untuk secara efektif mengintegrasikan dan bernalar di berbagai modalitas.
Unggul dalam Pemrosesan Audio
Untuk tugas audio-ke-teks, Qwen 2.5 Omni 7B menunjukkan hasil mendekati state-of-the-art dalam Pengenalan Ucapan Otomatis (ASR). Pada dataset Librispeech, ia mencapai Word Error Rates (WER) mulai dari 1,6% hingga 3,5%, sebanding dengan model khusus seperti Whisper-large-v3.
Dalam Pengenalan Peristiwa Suara pada dataset Meld, ia mencapai kinerja terbaik di kelasnya dengan skor 0,570. Model ini bahkan unggul dalam pemahaman musik, dengan skor 0,88 pada tolok ukur GiantSteps Tempo.
Pemahaman Gambar yang Kuat
Dalam hal tugas gambar-ke-teks, Qwen 2.5 Omni 7B mencapai skor 59,2 pada tolok ukur MMMU, sangat dekat dengan 60,0 GPT-4o-mini. Pada tugas RefCOCO Grounding, ia mencapai akurasi 90,5%, mengungguli 73,2% Gemini 1.5 Pro.
Pemahaman Video yang Mengesankan
Untuk tugas video-ke-teks tanpa subtitle, model ini mencetak 64,3 pada Video-MME, hampir menyamai kinerja model video khusus. Ketika subtitle ditambahkan, kinerja melonjak menjadi 72,4, menunjukkan kemampuan model untuk mengintegrasikan berbagai sumber informasi secara efektif.
Pembuatan Ucapan Alami
Qwen 2.5 Omni 7B tidak hanya memahami—ia berbicara. Untuk pembuatan ucapan, ia mencapai skor kesamaan pembicara mulai dari 0,754 hingga 0,752, sebanding dengan model text-to-speech khusus seperti Seed-TTS_RL. Ini menunjukkan kemampuannya untuk menghasilkan ucapan terdengar alami yang mempertahankan karakteristik suara pembicara asli.
Mempertahankan Kemampuan Teks yang Kuat
Terlepas dari fokus multimodalnya, Qwen 2.5 Omni 7B masih berkinerja mengagumkan pada tugas khusus teks. Ia mencapai hasil yang kuat pada penalaran matematis (skor GSM8K: 88,7%) dan pembuatan kode. Meskipun ada sedikit trade-off dibandingkan dengan model Qwen2.5-7B khusus teks (yang mencetak 91,6% pada GSM8K), penurunan kecil ini merupakan kompromi yang wajar untuk mendapatkan kemampuan multimodal yang komprehensif.
Aplikasi Dunia Nyata dari Qwen 2.5 Omni 7B:
Qwen 2.5 Omni is NUTS!
— Jeff Boudier 🤗 (@jeffboudier) March 26, 2025
I can't believe a 7B model
can take text, images, audio, video as input
give text and audio as output
and work so well!
Open source Apache 2.0
Try it, link below!
You really cooked @Alibaba_Qwen ! pic.twitter.com/pn0dnwOqjY
Keserbagunaan Qwen 2.5 Omni 7B membuka berbagai aplikasi praktis di berbagai domain.
Antarmuka Komunikasi yang Ditingkatkan
Kemampuan streaming latensi rendahnya membuatnya ideal untuk aplikasi obrolan suara dan video waktu nyata. Bayangkan asisten virtual yang dapat melihat, mendengar, dan berbicara secara alami, memahami isyarat komunikasi verbal dan non-verbal sambil merespons dengan ucapan alami.
Analisis Konten Tingkat Lanjut
Kemampuan model untuk memproses dan memahami berbagai modalitas memposisikannya sebagai alat yang ampuh untuk analisis konten yang komprehensif. Ia dapat mengekstrak wawasan dari dokumen multimedia, secara otomatis mengidentifikasi informasi kunci dari teks, gambar, audio, dan video secara bersamaan.
Antarmuka Suara yang Dapat Diakses
Dengan kinerjanya yang kuat dalam mengikuti instruksi ucapan ujung-ke-ujung, Qwen 2.5 Omni 7B memungkinkan interaksi yang lebih alami dan benar-benar hands-free dengan teknologi. Ini dapat merevolusi fitur aksesibilitas untuk pengguna dengan disabilitas atau situasi di mana pengoperasian hands-free sangat penting.
Pembuatan Konten Kreatif
Kemampuan model untuk menghasilkan teks dan ucapan alami membuka kemungkinan baru untuk pembuatan konten. Dari secara otomatis menghasilkan narasi untuk video hingga membuat materi pendidikan interaktif yang merespons pertanyaan siswa dengan penjelasan yang sesuai, aplikasinya sangat luas.
Layanan Pelanggan Multimodal
Bisnis dapat menerapkan Qwen 2.5 Omni 7B untuk mendukung sistem layanan pelanggan yang dapat menganalisis pertanyaan pelanggan dari berbagai saluran—panggilan suara, obrolan video, pesan tertulis—dan merespons secara alami dan tepat untuk masing-masing saluran.
Pertimbangan dan Keterbatasan Praktis
Meskipun Qwen 2.5 Omni 7B mewakili kemajuan signifikan dalam AI multimodal, ada beberapa pertimbangan praktis yang perlu diingat saat bekerja dengannya.
Persyaratan Perangkat Keras
Kemampuan komprehensif model hadir dengan tuntutan komputasi yang substansial. Memproses bahkan video 15 detik yang relatif pendek dalam presisi FP32 membutuhkan sekitar 93,56 GB memori GPU. Bahkan dengan presisi BF16, video 60 detik masih membutuhkan sekitar 60,19 GB.
Persyaratan ini dapat membatasi aksesibilitas bagi pengguna tanpa akses ke perangkat keras kelas atas. Namun, model ini mendukung berbagai optimasi seperti Flash Attention 2, yang dapat membantu meningkatkan kinerja pada perangkat keras yang kompatibel.
Kustomisasi Jenis Suara
Menariknya, Qwen 2.5 Omni 7B mendukung beberapa jenis suara untuk output audionya. Saat ini, ia menawarkan dua opsi suara:
- Chelsie: Suara wanita yang digambarkan sebagai "bermadu, lembut" dengan "kehangatan lembut dan kejernihan bercahaya"
- Ethan: Suara pria yang dicirikan sebagai "cerah, ceria" dengan "energi menular dan getaran hangat, mudah didekati"
Kustomisasi ini menambahkan dimensi lain pada fleksibilitas model dalam aplikasi dunia nyata.
Pertimbangan Integrasi Teknis
Saat menerapkan Qwen 2.5 Omni 7B, beberapa detail teknis perlu diperhatikan:
- Model ini memerlukan pola prompting khusus untuk output audio
- Pengaturan yang konsisten untuk parameter
use_audio_in_videodiperlukan untuk percakapan multi-putaran yang tepat - Kompatibilitas URL video bergantung pada versi pustaka tertentu (torchvision ≥ 0.19.0 untuk dukungan HTTPS)
- Model ini saat ini tidak tersedia melalui Hugging Face Inference API karena keterbatasan dalam mendukung model "apa pun ke apa pun"
Masa Depan AI Multimodal
Qwen 2.5 Omni 7B mewakili lebih dari sekadar model AI lain—ini adalah sekilas ke masa depan kecerdasan buatan. Dengan menyatukan beberapa modalitas sensorik dalam arsitektur ujung-ke-ujung yang terpadu, ia membawa kita lebih dekat ke sistem AI yang dapat memahami dan berinteraksi dengan dunia lebih seperti manusia.
Integrasi TMRoPE untuk penyelarasan temporal memecahkan tantangan mendasar dalam pemrosesan multimodal, sementara arsitektur Thinker-Talker menyediakan kerangka kerja untuk secara efektif menggabungkan berbagai input dan menghasilkan output yang sesuai. Kinerjanya yang kuat di seluruh tolok ukur menunjukkan bahwa model multimodal terpadu dapat bersaing dengan dan terkadang melampaui model single-modalitas khusus.
Karena sumber daya komputasi menjadi lebih mudah diakses dan teknik untuk penyebaran model yang efisien meningkat, kita dapat mengharapkan untuk melihat adopsi yang lebih luas dari AI multimodal sejati seperti Qwen 2.5 Omni 7B. Aplikasinya mencakup hampir setiap industri—dari perawatan kesehatan dan pendidikan hingga hiburan dan layanan pelanggan.
Kesimpulan
Qwen 2.5 Omni 7B berdiri sebagai pencapaian luar biasa dalam evolusi AI multimodal. Kemampuan "Omni" yang komprehensif, arsitektur inovatif, dan kinerja lintas-modal yang mengesankan menjadikannya contoh terkemuka dari generasi sistem kecerdasan buatan berikutnya.
Dengan menggabungkan kemampuan untuk melihat, mendengar, membaca, dan berbicara dalam satu model terpadu, Qwen 2.5 Omni 7B memecah hambatan tradisional antara kemampuan AI yang berbeda. Ini mewakili langkah signifikan menuju menciptakan sistem AI yang dapat berinteraksi dengan manusia dan memahami dunia dengan cara yang lebih alami dan intuitif.
Meskipun ada keterbatasan praktis yang perlu dipertimbangkan, terutama mengenai persyaratan perangkat keras, pencapaian model ini menunjuk ke masa depan yang menarik di mana AI dapat dengan mulus memproses dan merespons dunia multimodal yang kaya yang kita huni. Karena teknologi ini terus berkembang dan menjadi lebih mudah diakses, kita dapat mengharapkan teknologi ini mengubah cara kita berinteraksi dengan teknologi di berbagai aplikasi dan domain.
Qwen 2.5 Omni 7B bukan hanya pencapaian teknologi—ini adalah sekilas ke masa depan di mana batas antara berbagai bentuk komunikasi mulai menghilang, menciptakan cara yang lebih alami dan intuitif bagi manusia dan AI untuk berinteraksi.


