
Pengantar ke Kerangka Kerja OpenAI Evals API
OpenAI Evals API, yang diperkenalkan pada tanggal 9 April 2025, mewakili kemajuan signifikan dalam evaluasi sistematis Model Bahasa Besar (LLM). Meskipun kemampuan evaluasi telah tersedia melalui dasbor OpenAI selama beberapa waktu, Evals API sekarang memungkinkan pengembang untuk mendefinisikan pengujian secara terprogram, mengotomatiskan proses evaluasi, dan melakukan iterasi dengan cepat pada perintah dan implementasi model dalam alur kerja mereka sendiri. Antarmuka yang kuat ini mendukung penilaian metodis terhadap keluaran model, memfasilitasi pengambilan keputusan berbasis bukti saat memilih model atau menyempurnakan strategi rekayasa perintah.
Tutorial ini memberikan panduan teknis komprehensif untuk mengimplementasikan dan memanfaatkan OpenAI Evals API. Kita akan menjelajahi arsitektur dasar, pola implementasi, dan teknik lanjutan untuk membuat saluran evaluasi yang kuat yang secara objektif dapat mengukur kinerja aplikasi LLM Anda.
OpenAI Evals API: Bagaimana Cara Kerjanya?
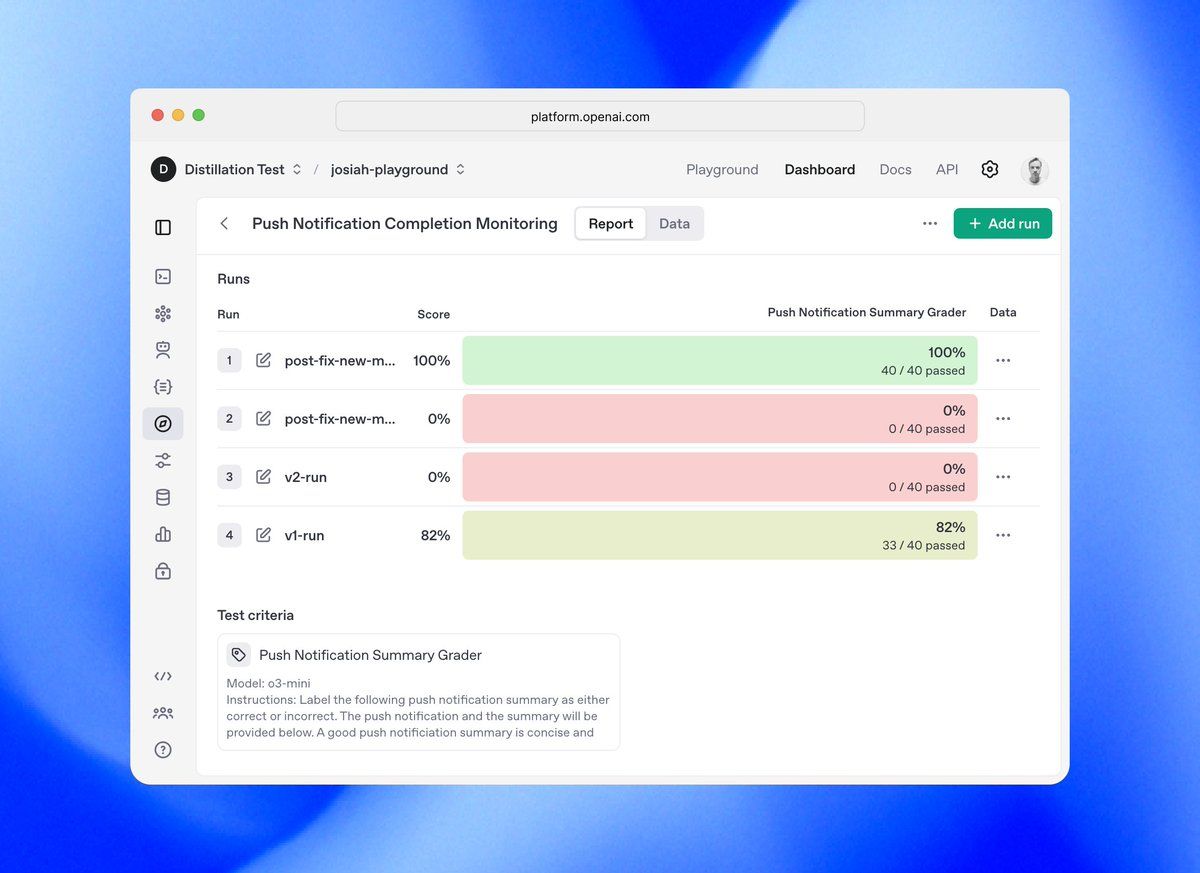
OpenAI Evals API mengikuti struktur hierarkis yang dibangun di sekitar dua abstraksi utama:
- Konfigurasi Eval - Kontainer untuk spesifikasi evaluasi yang mencakup:
- Definisi skema sumber data
- Konfigurasi kriteria pengujian
- Metadata untuk organisasi dan pengambilan
2. Proses Eval - Eksekusi evaluasi individual yang mencakup:
- Referensi ke konfigurasi eval induk
- Sampel data spesifik untuk evaluasi
- Respons model dan hasil evaluasi
Pemisahan perhatian ini memungkinkan penggunaan kembali di berbagai skenario pengujian sambil mempertahankan konsistensi dalam standar evaluasi.
Model Objek Evals API
Objek inti dalam Evals API mengikuti hubungan ini:
- data_source_config (definisi skema)
- testing_criteria (metode evaluasi)
- metadata (deskripsi, tag, dll.)
- Run 1 (terhadap data spesifik)
- Run 2 (implementasi alternatif)
- ...
- Run N (perbandingan versi)
Menyiapkan Lingkungan Anda untuk OpenAI Evals API
Saat mengimplementasikan OpenAI Evals API, pilihan alat pengujian dan pengembangan Anda dapat secara signifikan memengaruhi produktivitas dan kualitas hasil Anda.

Apidog menonjol sebagai platform API utama yang mengungguli solusi tradisional seperti Postman dalam beberapa aspek penting, menjadikannya pendamping ideal untuk bekerja dengan Evals API yang kompleks secara teknis.
Sebelum mengimplementasikan evaluasi, Anda perlu mengonfigurasi lingkungan pengembangan Anda dengan benar:
import openai
import os
import pydantic
import json
from typing import Dict, List, Any, Optional
# Configure API access with appropriate permissions
os.environ["OPENAI_API_KEY"] = os.environ.get("OPENAI_API_KEY", "your-api-key")
# For production environments, consider using a more secure method
# such as environment variables loaded from a .env file
Pustaka klien Python OpenAI menyediakan antarmuka untuk berinteraksi dengan Evals API. Pastikan Anda menggunakan versi terbaru yang menyertakan dukungan Evals API:
pip install --upgrade openai>=1.20.0 # Version that includes Evals API support
Membuat Evaluasi Pertama Anda dengan OpenAI Evals API
Mari kita implementasikan alur kerja evaluasi lengkap menggunakan OpenAI Evals API. Kita akan membuat sistem evaluasi untuk tugas peringkasan teks, yang menunjukkan proses lengkap dari desain evaluasi hingga analisis hasil.
Mendefinisikan Model Data untuk OpenAI Evals API
Pertama, kita perlu mendefinisikan struktur data pengujian kita menggunakan model Pydantic:
class ArticleSummaryData(pydantic.BaseModel):
"""Data structure for article summarization evaluation."""
article: str
reference_summary: Optional[str] = None # Optional reference for comparison
class Config:
frozen = True # Ensures immutability for consistent evaluation
Model ini mendefinisikan skema untuk data evaluasi kita, yang akan digunakan oleh Evals API untuk memvalidasi input dan menyediakan variabel templat untuk kriteria pengujian kita.
Mengimplementasikan Fungsi Target untuk Pengujian Evals API
Selanjutnya, kita akan mengimplementasikan fungsi yang menghasilkan output yang ingin kita evaluasi:
def generate_article_summary(article_text: str) -> Dict[str, Any]:
"""
Generate a concise summary of an article using OpenAI's models.
Args:
article_text: The article content to summarize
Returns:
Completion response object with summary
"""
summarization_prompt = """
Summarize the following article in a concise, informative manner.
Capture the key points while maintaining accuracy and context.
Keep the summary to 1-2 paragraphs.
Article:
{{article}}
"""
response = openai.chat.completions.create(
model="gpt-4o",
messages=[
{"role": "system", "content": summarization_prompt.replace("{{article}}", article_text)},
],
temperature=0.3, # Lower temperature for more consistent summaries
max_tokens=300
)
return response.model_dump() # Convert to serializable dictionary
Mengonfigurasi Sumber Data untuk OpenAI Evals API
Evals API memerlukan konfigurasi sumber data yang ditentukan yang menentukan skema data evaluasi Anda:
data_source_config = {
"type": "custom",
"item_schema": ArticleSummaryData.model_json_schema(),
"include_sample_schema": True, # Includes model output schema automatically
}
print("Data Source Schema:")
print(json.dumps(data_source_config, indent=2))
Konfigurasi ini memberi tahu Evals API bidang apa yang diharapkan dalam data evaluasi Anda dan bagaimana memprosesnya.
Mengimplementasikan Kriteria Pengujian dengan OpenAI Evals API
Sekarang kita akan mendefinisikan bagaimana Evals API harus mengevaluasi output model. Kita akan membuat evaluasi komprehensif dengan beberapa kriteria:
# 1. Accuracy evaluation using model-based judgment
accuracy_grader = {
"name": "Summary Accuracy Evaluation",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
You are an expert evaluator assessing the accuracy of article summaries.
Evaluate if the summary accurately represents the main points of the original article.
Label the summary as one of:
- "accurate": Contains all key information, no factual errors
- "partially_accurate": Contains most key information, minor errors or omissions
- "inaccurate": Significant errors, missing critical information, or misrepresentation
Provide a detailed explanation for your assessment.
"""
},
{
"role": "user",
"content": """
Original Article:
{{item.article}}
Summary to Evaluate:
{{sample.choices[0].message.content}}
Assessment:
"""
}
],
"passing_labels": ["accurate", "partially_accurate"],
"labels": ["accurate", "partially_accurate", "inaccurate"],
}
# 2. Conciseness evaluation
conciseness_grader = {
"name": "Summary Conciseness Evaluation",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
You are an expert evaluator assessing the conciseness of article summaries.
Evaluate if the summary expresses information efficiently without unnecessary details.
Label the summary as one of:
- "concise": Perfect length, no unnecessary information
- "acceptable": Slightly verbose but generally appropriate
- "verbose": Excessively long or containing unnecessary details
Provide a detailed explanation for your assessment.
"""
},
{
"role": "user",
"content": """
Summary to Evaluate:
{{sample.choices[0].message.content}}
Assessment:
"""
}
],
"passing_labels": ["concise", "acceptable"],
"labels": ["concise", "acceptable", "verbose"],
}
# 3. If reference summaries are available, add a reference comparison
reference_comparison_grader = {
"name": "Reference Comparison Evaluation",
"type": "label_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
Compare the generated summary with the reference summary.
Evaluate how well the generated summary captures the same key information as the reference.
Label the comparison as one of:
- "excellent": Equivalent or better than reference
- "good": Captures most important information from reference
- "inadequate": Missing significant information present in reference
Provide a detailed explanation for your assessment.
"""
},
{
"role": "user",
"content": """
Reference Summary:
{{item.reference_summary}}
Generated Summary:
{{sample.choices[0].message.content}}
Assessment:
"""
}
],
"passing_labels": ["excellent", "good"],
"labels": ["excellent", "good", "inadequate"],
"condition": "item.reference_summary != null" # Only apply when reference exists
}
Membuat Konfigurasi Evaluasi dengan OpenAI Evals API
Dengan skema data dan kriteria pengujian kita yang telah ditentukan, kita sekarang dapat membuat konfigurasi evaluasi:
eval_create_result = openai.evals.create(
name="Article Summarization Quality Evaluation",
metadata={
"description": "Comprehensive evaluation of article summarization quality across multiple dimensions",
"version": "1.0",
"created_by": "Your Organization",
"tags": ["summarization", "content-quality", "accuracy"]
},
data_source_config=data_source_config,
testing_criteria=[
accuracy_grader,
conciseness_grader,
reference_comparison_grader
],
)
eval_id = eval_create_result.id
print(f"Created evaluation with ID: {eval_id}")
print(f"View in dashboard: {eval_create_result.dashboard_url}")
Menjalankan Proses Evaluasi dengan OpenAI Evals API
Mempersiapkan Data Evaluasi
Sekarang kita akan mempersiapkan data pengujian untuk evaluasi kita:
test_articles = [
{
"article": """
The European Space Agency (ESA) announced today the successful deployment of its new Earth observation satellite, Sentinel-6.
This satellite will monitor sea levels with unprecedented accuracy, providing crucial data on climate change impacts.
The Sentinel-6 features advanced radar altimetry technology capable of measuring sea-level changes down to millimeter precision.
Scientists expect this data to significantly improve climate models and coastal planning strategies.
The satellite, launched from Vandenberg Air Force Base in California, is part of the Copernicus program, a collaboration
between ESA, NASA, NOAA, and other international partners.
""",
"reference_summary": """
The ESA has successfully deployed the Sentinel-6 Earth observation satellite, designed to monitor sea levels
with millimeter precision using advanced radar altimetry. This mission, part of the international Copernicus program,
will provide crucial data for climate change research and coastal planning.
"""
},
# Additional test articles would be added here
]
# Process our test data for evaluation
run_data = []
for item in test_articles:
# Generate summary using our function
article_data = ArticleSummaryData(**item)
result = generate_article_summary(article_data.article)
# Prepare the run data entry
run_data.append({
"item": article_data.model_dump(),
"sample": result
})
Membuat dan Menjalankan Proses Evaluasi
Dengan data kita yang telah disiapkan, kita dapat membuat proses evaluasi:
eval_run_result = openai.evals.runs.create(
eval_id=eval_id,
name="baseline-summarization-run",
metadata={
"model": "gpt-4o",
"temperature": 0.3,
"max_tokens": 300
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": run_data,
}
},
)
print(f"Evaluation run created: {eval_run_result.id}")
print(f"View detailed results: {eval_run_result.report_url}")
Mengambil dan Menganalisis Hasil Evaluasi dari Evals API
Setelah proses evaluasi selesai, Anda dapat mengambil hasil terperinci:
def analyze_run_results(run_id: str) -> Dict[str, Any]:
"""
Retrieve and analyze results from an evaluation run.
Args:
run_id: The ID of the evaluation run
Returns:
Dictionary containing analyzed results
"""
# Retrieve the run details
run_details = openai.evals.runs.retrieve(run_id)
# Extract the results
results = {}
# Calculate overall pass rate
if run_details.results and "pass_rate" in run_details.results:
results["overall_pass_rate"] = run_details.results["pass_rate"]
# Extract criterion-specific metrics
if run_details.criteria_results:
results["criteria_performance"] = {}
for criterion, data in run_details.criteria_results.items():
results["criteria_performance"][criterion] = {
"pass_rate": data.get("pass_rate", 0),
"sample_count": data.get("total_count", 0)
}
# Extract failures for further analysis
if run_details.raw_results:
results["failure_analysis"] = [
{
"item": item.get("item", {}),
"result": item.get("result", {}),
"criteria_results": item.get("criteria_results", {})
}
for item in run_details.raw_results
if not item.get("passed", True)
]
return results
# Analyze our run
results_analysis = analyze_run_results(eval_run_result.id)
print(json.dumps(results_analysis, indent=2))
Teknik Lanjutan OpenAI Evals API
Mengimplementasikan Pengujian A/B dengan Evals API
Evals API unggul dalam membandingkan implementasi yang berbeda. Berikut cara menyiapkan pengujian A/B antara dua konfigurasi model:
def generate_summary_alternative_model(article_text: str) -> Dict[str, Any]:
"""Alternative implementation using a different model configuration."""
response = openai.chat.completions.create(
model="gpt-4o-mini", # Using a different model
messages=[
{"role": "system", "content": "Summarize this article concisely."},
{"role": "user", "content": article_text},
],
temperature=0.7, # Higher temperature for comparison
max_tokens=250
)
return response.model_dump()
# Process our test data with the alternative model
alternative_run_data = []
for item in test_articles:
article_data = ArticleSummaryData(**item)
result = generate_summary_alternative_model(article_data.article)
alternative_run_data.append({
"item": article_data.model_dump(),
"sample": result
})
# Create the alternative evaluation run
alternative_eval_run = openai.evals.runs.create(
eval_id=eval_id,
name="alternative-model-run",
metadata={
"model": "gpt-4o-mini",
"temperature": 0.7,
"max_tokens": 250
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": alternative_run_data,
}
},
)
# Compare the results programmatically
def compare_evaluation_runs(run_id_1: str, run_id_2: str) -> Dict[str, Any]:
"""
Compare results from two evaluation runs.
Args:
run_id_1: ID of first evaluation run
run_id_2: ID of second evaluation run
Returns:
Dictionary containing comparative analysis
"""
run_1_results = analyze_run_results(run_id_1)
run_2_results = analyze_run_results(run_id_2)
comparison = {
"overall_comparison": {
"run_1_pass_rate": run_1_results.get("overall_pass_rate", 0),
"run_2_pass_rate": run_2_results.get("overall_pass_rate", 0),
"difference": run_1_results.get("overall_pass_rate", 0) - run_2_results.get("overall_pass_rate", 0)
},
"criteria_comparison": {}
}
# Compare each criterion
all_criteria = set(run_1_results.get("criteria_performance", {}).keys()) | set(run_2_results.get("criteria_performance", {}).keys())
for criterion in all_criteria:
run_1_criterion = run_1_results.get("criteria_performance", {}).get(criterion, {})
run_2_criterion = run_2_results.get("criteria_performance", {}).get(criterion, {})
comparison["criteria_comparison"][criterion] = {
"run_1_pass_rate": run_1_criterion.get("pass_rate", 0),
"run_2_pass_rate": run_2_criterion.get("pass_rate", 0),
"difference": run_1_criterion.get("pass_rate", 0) - run_2_criterion.get("pass_rate", 0)
}
return comparison
# Compare our two runs
comparison_results = compare_evaluation_runs(eval_run_result.id, alternative_eval_run.id)
print(json.dumps(comparison_results, indent=2))
Mendeteksi Regresi dengan OpenAI Evals API
Salah satu aplikasi Evals API yang paling berharga adalah deteksi regresi saat memperbarui perintah:
def create_regression_detection_pipeline(eval_id: str, baseline_run_id: str) -> None:
"""
Create a regression detection pipeline that compares a new prompt
against a baseline run.
Args:
eval_id: The ID of the evaluation configuration
baseline_run_id: The ID of the baseline run to compare against
"""
def test_prompt_for_regression(new_prompt: str, threshold: float = 0.95) -> Dict[str, Any]:
"""
Test if a new prompt causes regression compared to baseline.
Args:
new_prompt: The new prompt to test
threshold: Minimum acceptable performance ratio (new/baseline)
Returns:
Dictionary containing regression analysis
"""
# Define function using new prompt
def generate_summary_new_prompt(article_text: str) -> Dict[str, Any]:
response = openai.chat.completions.create(
model="gpt-4o", # Same model as baseline
messages=[
{"role": "system", "content": new_prompt},
{"role": "user", "content": article_text},
],
temperature=0.3,
max_tokens=300
)
return response.model_dump()
# Process test data with new prompt
new_prompt_run_data = []
for item in test_articles:
article_data = ArticleSummaryData(**item)
result = generate_summary_new_prompt(article_data.article)
new_prompt_run_data.append({
"item": article_data.model_dump(),
"sample": result
})
# Create evaluation run for new prompt
new_prompt_run = openai.evals.runs.create(
eval_id=eval_id,
name=f"regression-test-{int(time.time())}",
metadata={
"prompt": new_prompt,
"test_type": "regression"
},
data_source={
"type": "jsonl",
"source": {
"type": "file_content",
"content": new_prompt_run_data,
}
},
)
# Wait for completion (in production, you might want to implement async handling)
# This is a simplified implementation
time.sleep(10) # Wait for evaluation to complete
# Compare against baseline
comparison = compare_evaluation_runs(baseline_run_id, new_prompt_run.id)
# Determine if there's a regression
baseline_pass_rate = comparison["overall_comparison"]["run_1_pass_rate"]
new_pass_rate = comparison["overall_comparison"]["run_2_pass_rate"]
regression_detected = (new_pass_rate / baseline_pass_rate if baseline_pass_rate > 0 else 0) < threshold
return {
"regression_detected": regression_detected,
"baseline_pass_rate": baseline_pass_rate,
"new_pass_rate": new_pass_rate,
"performance_ratio": new_pass_rate / baseline_pass_rate if baseline_pass_rate > 0 else 0,
"threshold": threshold,
"detailed_comparison": comparison,
"report_url": new_prompt_run.report_url
}
return test_prompt_for_regression
# Create a regression detection pipeline
regression_detector = create_regression_detection_pipeline(eval_id, eval_run_result.id)
# Test a potentially problematic prompt
problematic_prompt = """
Summarize this article in excessive detail, making sure to include every minor point.
The summary should be comprehensive and leave nothing out.
"""
regression_analysis = regression_detector(problematic_prompt)
print(json.dumps(regression_analysis, indent=2))
Bekerja dengan Metrik Kustom di OpenAI Evals API
Untuk kebutuhan evaluasi khusus, Anda dapat mengimplementasikan metrik kustom:
# Example of a custom numeric score evaluation
numeric_score_grader = {
"name": "Summary Quality Score",
"type": "score_model",
"model": "gpt-4o",
"input": [
{
"role": "system",
"content": """
You are an expert evaluator assessing the quality of article summaries.
Rate the overall quality of the summary on a scale from 1.0 to 10.0, where:
- 1.0-3.9: Poor quality, significant issues
- 4.0-6.9: Acceptable quality with room for improvement
- 7.0-8.9: Good quality, meets expectations
- 9.0-10.0: Excellent quality, exceeds expectations
Provide a specific numeric score and detailed justification.
"""
},
{
"role": "user",
"content": """
Original Article:
{{item.article}}
Summary to Evaluate:
{{sample.choices[0].message.content}}
Score (1.0-10.0):
"""
}
],
"passing_threshold": 7.0, # Minimum score to pass
"min_score": 1.0,
"max_score": 10.0
}
# Add this to your testing criteria when creating an eval
Mengintegrasikan OpenAI Evals API ke dalam Alur Kerja Pengembangan
Integrasi CI/CD dengan Evals API
Mengintegrasikan Evals API ke dalam saluran CI/CD Anda memastikan kualitas yang konsisten:
def ci_cd_evaluation_workflow(
prompt_file_path: str,
baseline_eval_id: str,
baseline_run_id: str,
threshold: float = 0.95
) -> bool:
"""
CI/CD integration for evaluating model prompts before deployment.
Args:
prompt_file_path: Path to the prompt file being updated
baseline_eval_id: ID of the baseline evaluation configuration
baseline_run_id: ID of the baseline run to compare against
threshold: Minimum acceptable performance ratio
Returns:
Boolean indicating whether the new prompt passed evaluation
"""
# Load the new prompt from version control
with open(prompt_file_path, 'r') as f:
new_prompt = f.read()
# Create regression detector using the baseline
regression_detector = create_regression_detection_pipeline(baseline_eval_id, baseline_run_id)
# Test the new prompt
regression_analysis = regression_detector(new_prompt)
# Determine if the prompt is safe to deploy
is_approved = not regression_analysis["regression_detected"]
# Log the evaluation results
print(f"Evaluation Results for {prompt_file_path}")
print(f"Baseline Pass Rate: {regression_analysis['baseline_pass_rate']:.2f}")
print(f"New Prompt Pass Rate: {regression_analysis['new_pass_rate']:.2f}")
print(f"Performance Ratio: {regression_analysis['performance_ratio']:.2f}")
print(f"Deployment Decision: {'APPROVED' if is_approved else 'REJECTED'}")
print(f"Detailed Report: {regression_analysis['report_url']}")
return is_approved
Pemantauan Terjadwal dengan OpenAI Evals API
Evaluasi rutin membantu mendeteksi penyimpangan atau penurunan model:
def schedule_periodic_evaluation(
eval_id: str,
baseline_run_id: str,
interval_hours: int = 24
) -> None:
"""
Schedule periodic evaluations to monitor for performance changes.
Args:
eval_id: ID of the evaluation configuration
baseline_run_id: ID of the baseline run to compare against
interval_hours: Frequency of evaluations in hours
"""
# In a production system, you would use a task scheduler like Airflow,
# Celery, or cloud-native solutions. This is a simplified example.
def perform_periodic_evaluation():
while True:
try:
# Run the current production configuration against the eval
print(f"Running scheduled evaluation at {datetime.now()}")
# Implement your evaluation logic here, similar to regression testing
# Sleep until next scheduled run
time.sleep(interval_hours * 60 * 60)
except Exception as e:
print(f"Error in scheduled evaluation: {e}")
# Implement error handling and alerting
# In a real implementation, you would manage this thread properly
# or use a dedicated scheduling system
import threading
evaluation_thread = threading.Thread(target=perform_periodic_evaluation)
evaluation_thread.daemon = True
evaluation_thread.start()
Pola Penggunaan Lanjutan OpenAI Evals API
Saluran Evaluasi Multi-tahap
Untuk aplikasi kompleks, implementasikan saluran evaluasi multi-tahap:
def create_multi_stage_evaluation_pipeline(
article_data: List[Dict[str, str]]
) -> Dict[str, Any]:
"""
Create a multi-stage evaluation pipeline for content generation.
Args:
article_data: List of articles for evaluation
Returns:
Dictionary containing evaluation results from each stage
"""
# Stage 1: Content generation evaluation
generation_eval_id = create_content_generation_eval()
generation_run_id = run_content_generation_eval(generation_eval_id, article_data)
# Stage 2: Factual accuracy evaluation
accuracy_eval_id = create_factual_accuracy_eval()
accuracy_run_id = run_factual_accuracy_eval(accuracy_eval_id, article_data)
# Stage 3: Tone and style evaluation
tone_eval_id = create_tone_style_eval()
tone_run_id = run_tone_style_eval(tone_eval_id, article_data)
# Aggregate results from all stages
results = {
"generation": analyze_run_results(generation_run_id),
"accuracy": analyze_run_results(accuracy_run_id),
"tone": analyze_run_results(tone_run_id)
}
# Calculate composite score
composite_score = (
results["generation"].get("overall_pass_rate", 0) * 0.4 +
results["accuracy"].get("overall_pass_rate", 0) * 0.4 +
results["tone"].get("overall_pass_rate", 0) * 0.2
)
results["composite_score"] = composite_score
return results
Kesimpulan: Menguasai OpenAI Evals API
OpenAI Evals API mewakili kemajuan signifikan dalam evaluasi LLM sistematis, menyediakan pengembang dengan alat yang ampuh untuk secara objektif menilai kinerja model dan membuat keputusan berdasarkan data.
Seiring LLM semakin terintegrasi ke dalam aplikasi penting, pentingnya evaluasi sistematis tumbuh seiring dengan itu. OpenAI Evals API menyediakan infrastruktur yang dibutuhkan untuk mengimplementasikan praktik evaluasi ini dalam skala besar, memastikan bahwa sistem AI Anda tetap kuat, andal, dan selaras dengan harapan Anda dari waktu ke waktu.
Tetapi mengapa berhenti di sini? Dengan mengintegrasikan Apidog ke dalam alur kerja OpenAI Evals API Anda memberikan keuntungan yang signifikan:
- Pengujian yang Disederhanakan: Templat permintaan dan kemampuan pengujian otomatis Apidog mengurangi waktu pengembangan untuk mengimplementasikan saluran evaluasi
- Dokumentasi yang Ditingkatkan: Pembuatan dokumentasi API otomatis memastikan kriteria dan implementasi evaluasi Anda terdokumentasi dengan baik
- Kolaborasi Tim: Ruang kerja bersama memfasilitasi standar evaluasi yang konsisten di seluruh tim pengembangan
- Integrasi CI/CD: Kemampuan baris perintah memungkinkan integrasi dengan saluran CI/CD yang ada untuk pengujian otomatis
- Analisis Visual: Alat visualisasi bawaan membantu menafsirkan hasil evaluasi yang kompleks dengan cepat


