
Bidang kecerdasan buatan terus berkembang pesat, menghadirkan model-model inovatif yang mendefinisikan ulang batasan komputasi. Di antara kemajuan ini, MiniMax-M1 muncul sebagai perkembangan terobosan, menandai tempatnya sebagai model penalaran perhatian hibrida skala besar berbobot terbuka pertama di dunia. Dikembangkan oleh MiniMax, model ini menjanjikan transformasi cara kita mendekati tugas penalaran kompleks, menawarkan jendela konteks input 1 juta token dan output 80.000 token yang mengesankan. 💡 Bagi pengembang dan insinyur yang ingin memanfaatkan teknologi ini, mengunduh Apidog secara gratis menyediakan titik awal yang sangat baik untuk mengintegrasikan dan menguji kemampuan MiniMax-M1 dengan mulus. Postingan blog ini mengkaji seluk-beluk teknis MiniMax-M1, arsitekturnya, metrik kinerja, dan potensi aplikasi, memberikan panduan komprehensif bagi mereka yang tertarik untuk memanfaatkan AI mutakhir ini. button
Memahami Arsitektur Inti MiniMax-M1
MiniMax-M1 menonjol karena arsitektur uniknya yang merupakan campuran hibrida dari Mixture-of-Experts (MoE), dikombinasikan dengan mekanisme perhatian yang sangat cepat. Desain ini dibangun di atas fondasi yang diletakkan oleh pendahulunya, MiniMax-Text-01, yang menampilkan 456 miliar parameter yang luar biasa, dengan 45,9 miliar diaktifkan per token. Pendekatan MoE memungkinkan model untuk hanya mengaktifkan subset parameternya berdasarkan input, mengoptimalkan efisiensi komputasi dan memungkinkan skalabilitas. Sementara itu, mekanisme perhatian hibrida meningkatkan kemampuan model untuk memproses data konteks panjang, menjadikannya ideal untuk tugas yang memerlukan pemahaman mendalam atas urutan yang diperluas.

Integrasi komponen-komponen ini menghasilkan model yang menyeimbangkan kinerja dan penggunaan sumber daya secara efektif. Dengan secara selektif melibatkan para ahli dalam kerangka MoE, MiniMax-M1 mengurangi beban komputasi yang biasanya terkait dengan model skala besar. Selain itu, mekanisme perhatian kilat mempercepat pemrosesan bobot perhatian, memastikan bahwa model mempertahankan throughput tinggi bahkan dengan jendela konteksnya yang luas.
Efisiensi Pelatihan: Peran Pembelajaran Penguatan
Salah satu aspek paling luar biasa dari MiniMax-M1 adalah proses pelatihannya, yang memanfaatkan pembelajaran penguatan (RL) skala besar dengan efisiensi yang belum pernah terjadi sebelumnya. Model ini dilatih dengan biaya hanya $534.700, angka yang menggarisbawahi kerangka penskalaan RL inovatif yang dikembangkan oleh MiniMax. Kerangka kerja ini memperkenalkan CISPO (Clipped Importance Sampling with Policy Optimization), sebuah algoritma baru yang memotong bobot importance sampling alih-alih pembaruan token. Pendekatan ini mengungguli varian RL tradisional, memberikan proses pelatihan yang lebih stabil dan efisien.

Selain itu, desain perhatian hibrida memainkan peran penting dalam meningkatkan efisiensi RL. Dengan mengatasi tantangan unik yang terkait dengan penskalaan RL dalam arsitektur hibrida, MiniMax-M1 mencapai tingkat kinerja yang menyaingi model berbobot tertutup, meskipun bersifat sumber terbuka. Metodologi pelatihan ini tidak hanya mengurangi biaya tetapi juga menetapkan tolok ukur baru untuk mengembangkan model AI berperforma tinggi dengan sumber daya terbatas.
Metrik Kinerja: Pembandingan MiniMax-M1
Untuk mengevaluasi kemampuan MiniMax-M1, pengembang melakukan tolok ukur ekstensif di berbagai tugas, termasuk matematika tingkat kompetisi, pengkodean, rekayasa perangkat lunak, penggunaan alat berbasis agen, dan pemahaman konteks panjang. Hasilnya menyoroti keunggulan model dibandingkan model berbobot terbuka lainnya seperti DeepSeek-R1 dan Qwen3-235B-A22B.
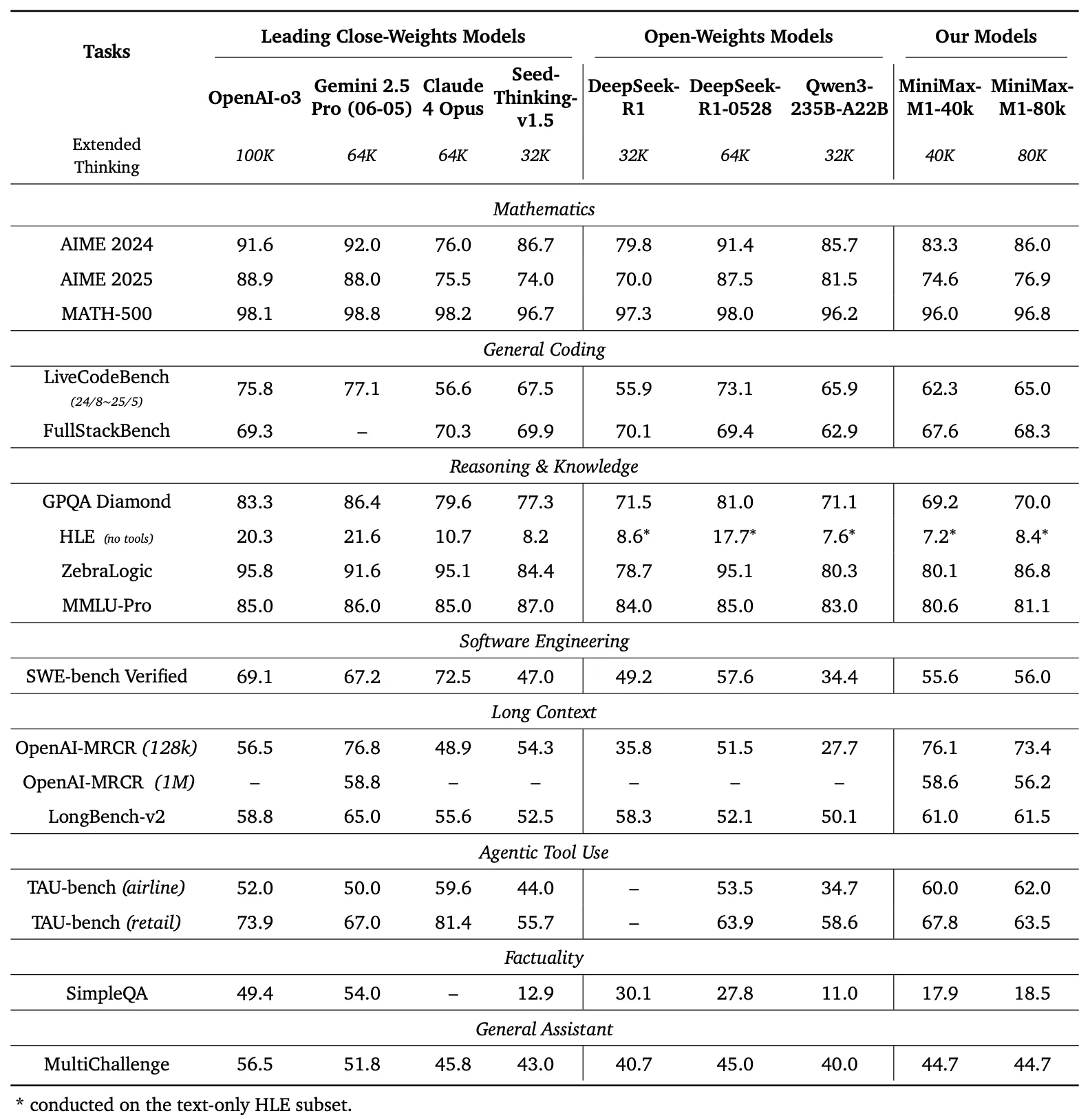
Perbandingan Tolok Ukur
Panel kiri Gambar 1 membandingkan kinerja MiniMax-M1 dengan model komersial dan berbobot terbuka terkemuka di beberapa tolok ukur

- AIME 2024: MiniMax-M1 mencapai akurasi 86,0%, melampaui OpenAI o3 (88,0%) dan Claude 4 Opus (80,0%), menunjukkan kehebatannya dalam penalaran matematika.
- LiveCodeBench: Dengan skor 65,0%, MiniMax-M1 mengungguli DeepSeek-R1-0528 (56,0%) dan menyamai kinerja Seed-Thinking v1.5 (65,0%), menunjukkan kemampuan pengkodean yang kuat.
- SW-E Bench Verified: Model ini mencetak 62,8%, melampaui Qwen3-235B-A22B (60,0%) dalam tugas rekayasa perangkat lunak.
- TAU-bench: MiniMax-M1 mencatat akurasi 73,4%, melebihi Gemini 2.5 Pro (70,0%) dalam penggunaan alat berbasis agen.
- MRCR (4-needle): Dengan akurasi 74,4%, ia memimpin model lain dalam tugas pemahaman konteks panjang.
Hasil ini menggarisbawahi keserbagunaan MiniMax-M1 dan kemampuannya untuk bersaing dengan model proprietary, menjadikannya aset berharga bagi komunitas sumber terbuka.

MiniMax-M1 menunjukkan peningkatan linier dalam FLOPs (Floating Point Operations) seiring dengan perpanjangan panjang generasi dari 32k menjadi 128k token. Skalabilitas ini memastikan bahwa model mempertahankan efisiensi dan kinerja bahkan dengan output yang diperpanjang, faktor penting untuk aplikasi yang memerlukan respons terperinci dan panjang.
Penalaran Konteks Panjang: Batas Baru
Fitur paling khas dari MiniMax-M1 adalah jendela konteksnya yang sangat panjang, mendukung hingga 1 juta token input dan 80.000 token output. Kemampuan ini memungkinkan model untuk memproses data dalam jumlah besar—setara dengan seluruh novel atau serangkaian buku—dalam satu kali jalan, jauh melebihi batas 128.000 token dari model seperti GPT-4 milik OpenAI. Model ini menawarkan dua mode inferensi—anggaran pemikiran 40k dan 80k—yang melayani kebutuhan skenario yang beragam dan memungkinkan penerapan yang fleksibel.

Jendela konteks yang diperluas ini meningkatkan kinerja model dalam tugas konteks panjang, seperti meringkas dokumen panjang, melakukan percakapan multi-giliran, atau menganalisis dataset kompleks. Dengan mempertahankan informasi kontekstual di atas jutaan token, MiniMax-M1 menyediakan fondasi yang kuat untuk aplikasi dalam penelitian, analisis hukum, dan pembuatan konten, di mana menjaga koherensi di atas urutan panjang sangat penting.
Penggunaan Alat Berbasis Agen dan Aplikasi Praktis
Selain jendela konteksnya yang mengesankan, MiniMax-M1 unggul dalam penggunaan alat berbasis agen, sebuah domain di mana model AI berinteraksi dengan alat eksternal untuk memecahkan masalah. Kemampuan model untuk berintegrasi dengan platform seperti MiniMax Chat dan menghasilkan aplikasi web fungsional—seperti tes kecepatan mengetik dan generator labirin—menunjukkan kegunaan praktisnya. Aplikasi ini, dibangun dengan pengaturan minimal dan tanpa plugin, menunjukkan kapasitas model untuk menghasilkan kode siap produksi.

Misalnya, model dapat menghasilkan aplikasi web yang bersih dan fungsional untuk melacak kata per menit (WPM) secara real-time atau membuat generator labirin yang menarik secara visual dengan visualisasi algoritma A*. Kemampuan seperti itu menempatkan MiniMax-M1 sebagai alat yang ampuh bagi pengembang yang ingin mengotomatiskan alur kerja pengembangan perangkat lunak atau menciptakan pengalaman pengguna yang interaktif.
Aksesibilitas Sumber Terbuka dan Dampak Komunitas
Rilis MiniMax-M1 di bawah lisensi Apache 2.0 menandai tonggak penting bagi komunitas sumber terbuka. Tersedia di GitHub dan Hugging Face, model ini mengundang pengembang, peneliti, dan bisnis untuk mengeksplorasi, memodifikasi, dan menerapkannya tanpa batasan proprietary. Keterbukaan ini mendorong inovasi, memungkinkan penciptaan solusi khusus yang disesuaikan dengan kebutuhan spesifik.
Aksesibilitas model juga mendemokratisasi akses ke teknologi AI canggih, memungkinkan organisasi yang lebih kecil dan pengembang independen untuk bersaing dengan entitas yang lebih besar. Dengan menyediakan dokumentasi terperinci dan laporan teknis, MiniMax memastikan bahwa pengguna dapat mereplikasi dan memperluas kemampuan model, lebih lanjut mempercepat kemajuan dalam ekosistem AI.
Implementasi Teknis: Penerapan dan Optimasi
Menerapkan MiniMax-M1 memerlukan pertimbangan cermat terhadap sumber daya komputasi dan teknik optimasi. Laporan teknis merekomendasikan penggunaan vLLM (Virtual Large Language Model) untuk penerapan produksi, yang mengoptimalkan kecepatan inferensi dan penggunaan memori. Alat ini memanfaatkan arsitektur hibrida model untuk mendistribusikan beban komputasi secara efisien, memastikan operasi yang lancar bahkan dengan input skala besar.
Pengembang dapat melakukan fine-tuning MiniMax-M1 untuk tugas-tugas spesifik dengan menyesuaikan anggaran pemikiran (40k atau 80k) berdasarkan kebutuhan mereka. Selain itu, kerangka pelatihan RL model yang efisien memungkinkan penyesuaian lebih lanjut melalui pembelajaran penguatan, memungkinkan adaptasi ke aplikasi khusus seperti terjemahan real-time atau dukungan pelanggan otomatis.
Kesimpulan: Merangkul Revolusi MiniMax-M1
MiniMax-M1 mewakili lompatan signifikan ke depan dalam ranah model penalaran perhatian hibrida skala besar berbobot terbuka. Jendela konteksnya yang mengesankan, proses pelatihan yang efisien, dan kinerja tolok ukur yang unggul menempatkannya sebagai pemimpin dalam lanskap AI. Dengan menawarkan teknologi ini sebagai sumber daya sumber terbuka, MiniMax memberdayakan pengembang dan peneliti untuk mengeksplorasi kemungkinan-kemungkinan baru, mulai dari rekayasa perangkat lunak canggih hingga analisis konteks panjang.
Seiring dengan terus berkembangnya komunitas AI, MiniMax-M1 berfungsi sebagai bukti kekuatan inovasi dan kolaborasi. Bagi mereka yang siap mengeksplorasi potensinya, mengunduh Apidog secara gratis menawarkan titik masuk praktis untuk bereksperimen dengan model transformatif ini. Perjalanan dengan MiniMax-M1 baru saja dimulai, dan dampaknya tidak diragukan lagi akan membentuk masa depan kecerdasan buatan.
button
