
Dalam lanskap model bahasa besar yang berkembang pesat, Llama Nemotron Ultra 253B dari NVIDIA menonjol sebagai pusat kekuatan bagi perusahaan yang mencari kemampuan penalaran tingkat lanjut. Panduan komprehensif ini menguji tolok ukur model yang mengesankan, membandingkannya dengan model sumber terbuka terkemuka lainnya, dan memberikan langkah-langkah jelas untuk mengimplementasikan API-nya dalam aplikasi Anda.
Tolok Ukur llama-3.1-nemotron-ultra-253b
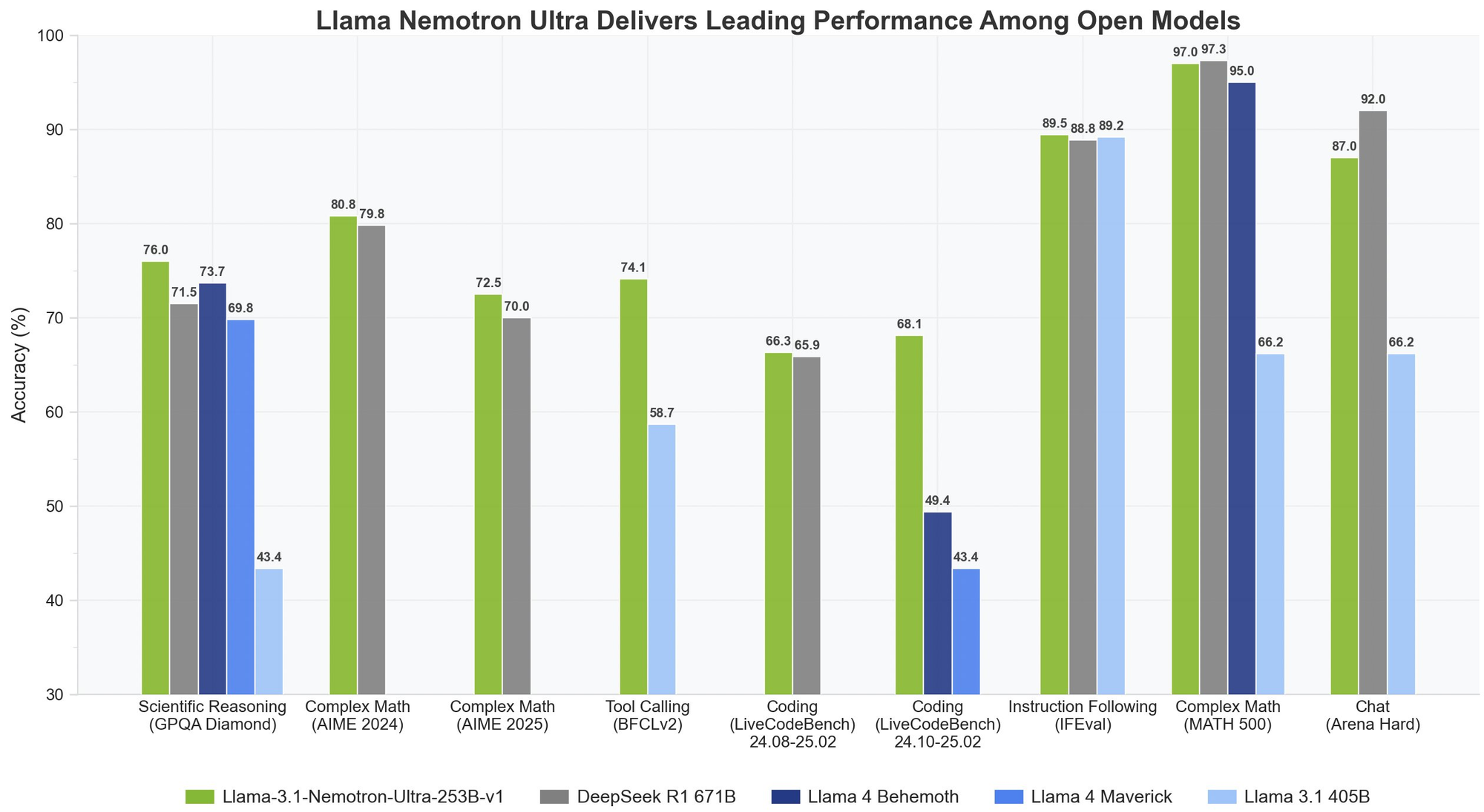
Llama Nemotron Ultra 253B memberikan hasil yang luar biasa di seluruh tolok ukur penalaran dan keagenan penting, dengan kemampuan unik "Penalaran ON/OFF" yang menunjukkan perbedaan kinerja yang dramatis:
Penalaran Matematis
Llama Nemotron Ultra 253B benar-benar bersinar dalam tugas penalaran matematis:
- MATH500
- Penalaran OFF: 80.4% pass@1
- Penalaran ON: 97.0% pass@1
Dengan akurasi 97% dengan Penalaran ON, Llama Nemotron Ultra 253B hampir menyempurnakan tolok ukur matematis yang menantang ini.
- AIME25 (American Invitational Mathematics Examination)
- Penalaran OFF: 16.7% pass@1
- Penalaran ON: 72.50% pass@1
Peningkatan 56 poin yang luar biasa ini menunjukkan bagaimana kemampuan penalaran Llama Nemotron Ultra 253B mengubah kinerjanya pada masalah matematika yang kompleks.
Penalaran Ilmiah
- GPQA (Graduate-level Physics Questions and Answers)
- Penalaran OFF: 56.6% pass@1
- Penalaran ON: 76.01% pass@1
Peningkatan signifikan menunjukkan bagaimana Llama Nemotron Ultra 253B dapat mengatasi masalah fisika tingkat pascasarjana melalui analisis metodis ketika penalaran diaktifkan.
Pemrograman dan Penggunaan Alat
- LiveCodeBench (20240801-20250201)
- Penalaran OFF: 29.03% pass@1
- Penalaran ON: 66.31% pass@1
Llama Nemotron Ultra 253B lebih dari dua kali lipat kinerja pengkodeannya dengan penalaran yang diaktifkan.
- BFCL V2 Live (Function Calling)
- Penalaran OFF: 73.62 skor
- Penalaran ON: 74.10 skor
Tolok ukur ini menunjukkan kemampuan penggunaan alat yang kuat dari model dalam kedua mode, yang penting untuk membangun agen AI yang efektif.
Mengikuti Instruksi
- IFEval (Instruction Following Evaluation)
- Penalaran OFF: 88.85% akurasi ketat
- Penalaran ON: 89.45% akurasi ketat
Kedua mode berkinerja sangat baik, menunjukkan bahwa Llama Nemotron Ultra 253B mempertahankan kemampuan mengikuti instruksi yang kuat terlepas dari mode penalaran.
Llama Nemotron Ultra 253B vs. DeepSeek-R1
DeepSeek-R1 telah menjadi standar emas untuk model penalaran sumber terbuka, tetapi Llama Nemotron Ultra 253B menyamai atau melampaui kinerjanya pada tolok ukur penalaran utama:
- Pada GPQA, Llama Nemotron Ultra 253B mencapai akurasi 76.01%, bersaing dengan kinerja tingkat atas DeepSeek-R1
- Llama Nemotron Ultra 253B menawarkan mode penalaran ganda, tidak seperti pendekatan penalaran tetap DeepSeek-R1
- Llama Nemotron Ultra 253B menyediakan kemampuan pemanggilan fungsi yang unggul, membuatnya lebih serbaguna untuk aplikasi keagenan
Llama Nemotron Ultra 253B vs. Llama 4
Jika dibandingkan dengan model Llama 4 Behemoth dan Maverick yang akan datang:
- Llama Nemotron Ultra 253B menunjukkan kinerja yang unggul pada tolok ukur penalaran matematis ilmiah dan kompleks
- Sakelar penalaran eksplisit di Llama Nemotron Ultra 253B menawarkan lebih banyak fleksibilitas daripada model Llama 4 standar
- Llama Nemotron Ultra 253B secara khusus dioptimalkan untuk perangkat keras NVIDIA, memberikan efisiensi inferensi yang lebih baik
Mari Uji Llama Nemotron Ultra 253B melalui API
Mengimplementasikan Llama Nemotron Ultra 253B dalam aplikasi Anda memerlukan mengikuti langkah-langkah khusus untuk memastikan kinerja optimal:
Langkah 1: Dapatkan Akses API
Untuk mengakses Llama Nemotron Ultra 253B:
- Kunjungi portal API NVIDIA di https://build.nvidia.com/nvidia/llama-3_1-nemotron-ultra-253b-v1
- Daftar untuk kunci API jika Anda belum memilikinya
- Jika berjalan di dalam lingkungan NGC NVIDIA, konfigurasi kunci API dapat disederhanakan
Langkah 2: Siapkan Lingkungan Pengembangan Anda
Sebelum melakukan panggilan API:
- Instal paket OpenAI Python menggunakan
pip install openai - Impor pustaka yang diperlukan:
from openai import OpenAI - Konfigurasikan lingkungan Anda untuk menyimpan kunci API dengan aman
Langkah 3: Konfigurasikan Klien API
Inisialisasi klien OpenAI dengan titik akhir NVIDIA:
client = OpenAI(
base_url = "<https://integrate.api.nvidia.com/v1>",
api_key = "YOUR_API_KEY_HERE"
)

- Tidak seperti Postman, Apidog menawarkan pengalaman yang lebih terintegrasi dengan dokumentasi API bawaan, pengujian otomatis, dan server mock yang secara khusus dioptimalkan untuk titik akhir model AI.
- Antarmuka intuitif Apidog memudahkan untuk mengonfigurasi set parameter kompleks yang diperlukan untuk pengujian API, dan fitur visualisasi responsnya sangat membantu untuk menganalisis output streaming model.
- Meskipun Postman tetap menjadi alat pengujian API tujuan umum yang populer, fitur yang berfokus pada AI dan alur kerja yang disederhanakan dari Apidog dapat secara signifikan mempercepat proses pengembangan Anda.

Langkah 4: Tentukan Mode Penalaran yang Sesuai
Llama Nemotron Ultra 253B menawarkan dua mode operasi yang berbeda:
- Penalaran ON: Terbaik untuk masalah kompleks yang membutuhkan pemikiran langkah demi langkah (matematika, fisika, pengkodean)
- Penalaran OFF: Optimal untuk mengikuti instruksi langsung dan obrolan umum
Langkah 5: Buat Prompt Sistem dan Pengguna Anda
Untuk mode Penalaran ON:
- Atur prompt sistem ke
"detailed thinking on" - Tempatkan semua instruksi dalam pesan pengguna
- Pertimbangkan untuk menggunakan templat khusus untuk tugas yang diukur (seperti masalah matematika)
Untuk mode Penalaran OFF:
- Hapus prompt sistem penalaran
- Gunakan instruksi yang ringkas dan jelas dalam pesan pengguna
Langkah 6: Konfigurasikan Parameter Generasi
Untuk hasil yang optimal:
- Penalaran ON: Atur temperature=0.6 dan top_p=0.95 seperti yang direkomendasikan oleh NVIDIA
- Penalaran OFF: Gunakan decoding serakah dengan temperature=0
- Atur
max_tokensyang sesuai berdasarkan panjang respons yang diharapkan - Pertimbangkan untuk mengaktifkan streaming untuk respons waktu nyata
Langkah 7: Buat Permintaan API dan Tangani Respons
Buat permintaan penyelesaian Anda dengan semua parameter yang dikonfigurasi:
completion = client.chat.completions.create(
model="nvidia/llama-3.1-nemotron-ultra-253b-v1",
messages=[
{"role": "system", "content": "detailed thinking on"},
{"role": "user", "content": "Your prompt here"}
],
temperature=0.6,
top_p=0.95,
max_tokens=4096,
stream=True
)
Langkah 8: Proses dan Tampilkan Respons
Jika menggunakan streaming:
for chunk in completion:
if chunk.choices[0].delta.content is not None:
print(chunk.choices[0].delta.content, end="")
Untuk respons non-streaming, cukup akses completion.choices[0].message.content.
Kesimpulan
Llama Nemotron Ultra 253B mewakili kemajuan signifikan dalam model penalaran sumber terbuka, memberikan kinerja canggih di berbagai tolok ukur. Mode penalaran ganda yang unik, dikombinasikan dengan kemampuan pemanggilan fungsi yang luar biasa dan jendela konteks yang besar, menjadikannya pilihan ideal untuk aplikasi AI perusahaan yang membutuhkan kemampuan penalaran tingkat lanjut.
Dengan panduan implementasi API langkah demi langkah yang diuraikan dalam artikel ini, pengembang dapat memanfaatkan potensi penuh Llama Nemotron Ultra 253B untuk membangun sistem AI canggih yang mengatasi masalah kompleks dengan penalaran seperti manusia. Baik membangun agen AI, meningkatkan sistem RAG, atau mengembangkan aplikasi khusus, Llama Nemotron Ultra 253B menyediakan fondasi yang kuat untuk kemampuan AI generasi berikutnya dalam paket sumber terbuka yang ramah secara komersial.


