
Lanskap kecerdasan buatan telah mengalami transformasi mendasar dengan dirilisnya Llama 4 dari Meta—bukan hanya melalui peningkatan bertahap, tetapi melalui terobosan arsitektur yang mendefinisikan ulang rasio kinerja terhadap biaya di seluruh industri. Model-model baru ini mewakili konvergensi dari tiga inovasi penting: multimodality asli melalui teknik fusi awal, arsitektur sparse mixture-of-experts (MoE) yang secara radikal meningkatkan efisiensi parameter, dan perluasan jendela konteks yang meluas hingga 10 juta token yang belum pernah terjadi sebelumnya.
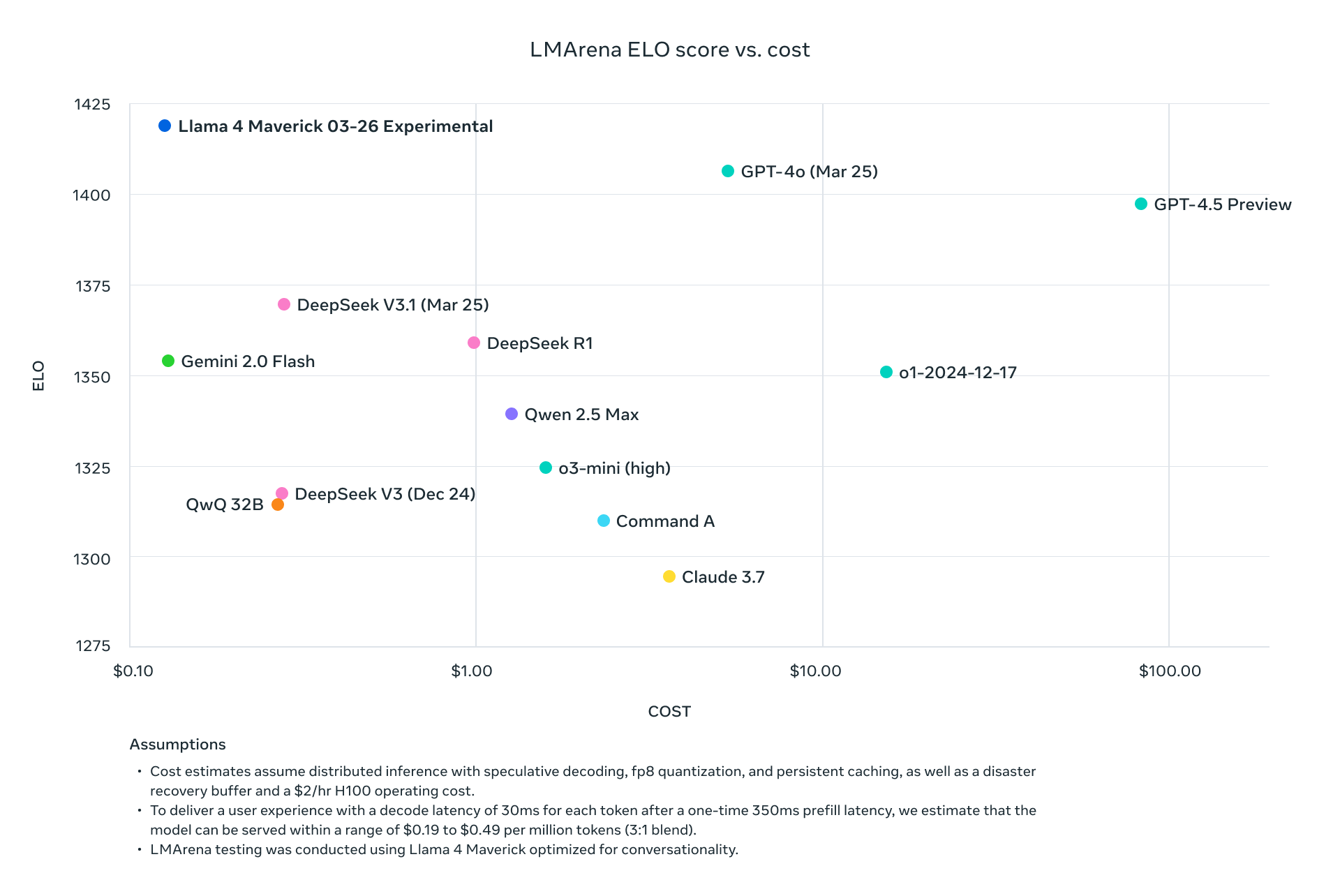
Llama 4 Scout dan Maverick tidak hanya bersaing dengan para pemimpin industri saat ini—mereka secara sistematis mengungguli mereka di seluruh tolok ukur standar sambil secara dramatis mengurangi persyaratan komputasi. Dengan Maverick mencapai hasil yang lebih baik daripada GPT-4o dengan biaya per token sekitar sepersembilan, dan Scout yang muat pada satu GPU H100 sambil mempertahankan kinerja yang lebih unggul daripada model yang membutuhkan banyak GPU, Meta telah secara fundamental mengubah ekonomi penerapan AI tingkat lanjut.
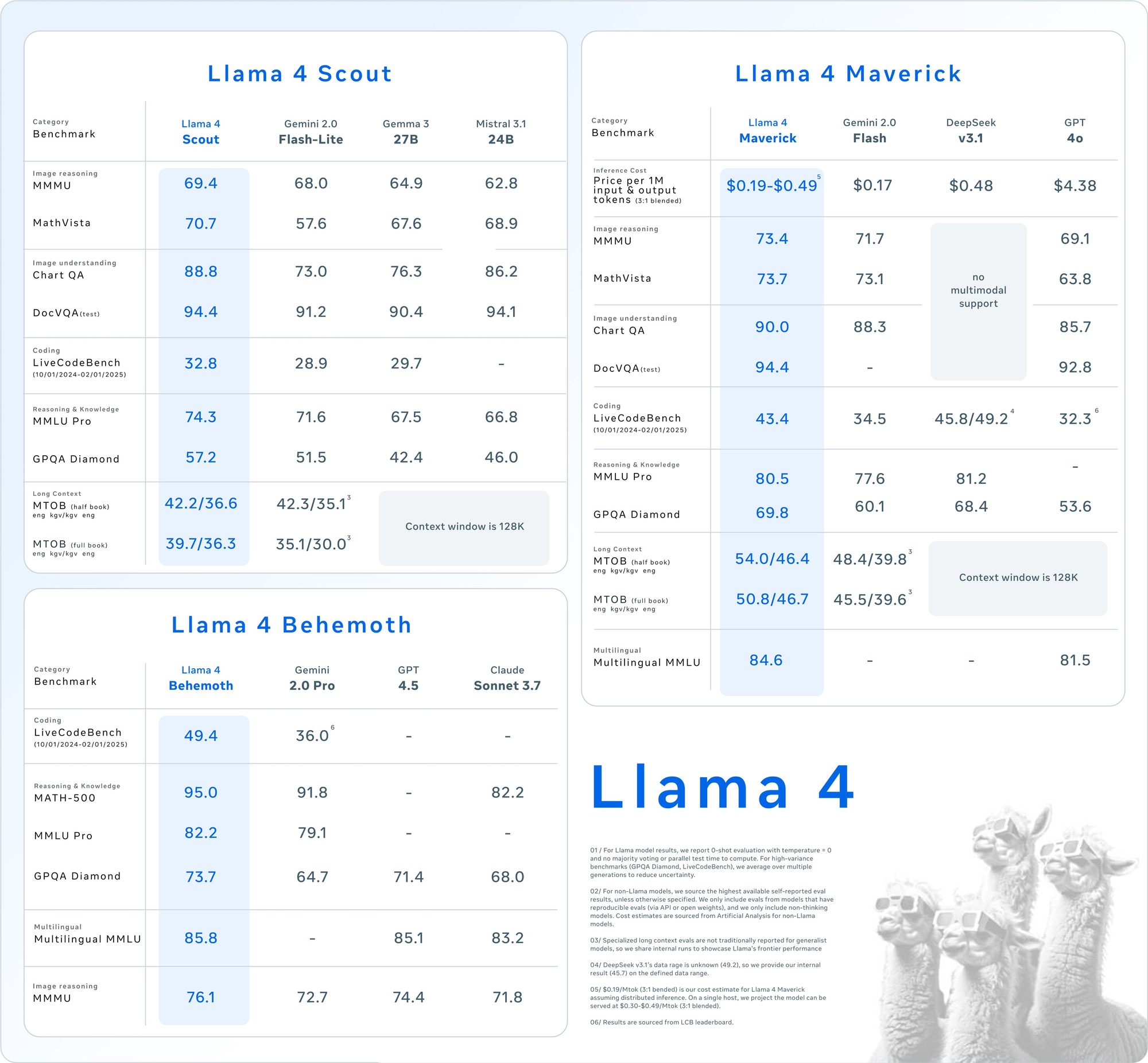
Analisis teknis ini membedah inovasi arsitektur yang mendukung model-model ini, menyajikan data tolok ukur komprehensif di seluruh penalaran, pengkodean, multibahasa, dan tugas multimodal, dan memeriksa struktur harga API di seluruh penyedia utama. Untuk para pengambil keputusan teknis yang mengevaluasi opsi infrastruktur AI, kami menyediakan perbandingan kinerja/biaya terperinci dan strategi penerapan untuk memaksimalkan efisiensi model-model inovatif ini di lingkungan produksi.
Anda dapat mengunduh Meta Llama 4 Sumber Terbuka dan Bobot Terbuka di Hugging Face, mulai hari ini:
https://huggingface.co/collections/meta-llama/llama-4-67f0c30d9fe03840bc9d0164

Bagaimana Llama 4 Mengarsipkan Jendela Konteks 10J?
Implementasi Mixture-of-Experts (MoE)
Semua model Llama 4 menggunakan arsitektur MoE canggih yang secara fundamental mengubah persamaan efisiensi:
| Model | Parameter Aktif | Jumlah Pakar | Total Parameter | Metode Aktivasi Parameter |
|---|---|---|---|---|
| Llama 4 Scout | 17M | 16 | 109M | Perutean khusus token |
| Llama 4 Maverick | 17M | 128 | 400M | Pakar yang dirutekan bersama + tunggal per token |
| Llama 4 Behemoth | 288M | 16 | ~2T | Perutean khusus token |
Desain MoE di Llama 4 Maverick sangat canggih, menggunakan lapisan padat dan MoE yang bergantian. Setiap token mengaktifkan pakar bersama ditambah salah satu dari 128 pakar yang dirutekan, yang berarti hanya sekitar 17M dari total 400M parameter yang aktif untuk memproses token tertentu.
Arsitektur Multimodal
Arsitektur Multimodal Llama 4:
├── Token Teks
│ └── Jalur pemrosesan teks asli
├── Penyandi Visi (MetaCLIP yang Ditingkatkan)
│ ├── Pemrosesan gambar
│ └── Mengonversi gambar menjadi urutan token
└── Lapisan Fusi Awal
└── Menyatukan token teks dan visi di tulang punggung model
Pendekatan fusi awal ini memungkinkan pra-pelatihan pada 30+ triliun token data teks, gambar, dan video campuran, menghasilkan kemampuan multimodal yang jauh lebih koheren daripada pendekatan retrofit.
Arsitektur iRoPE untuk Jendela Konteks yang Diperluas
Jendela konteks 10J token Llama 4 Scout memanfaatkan arsitektur iRoPE yang inovatif:
# Pseudocode untuk arsitektur iRoPE
def iRoPE_layer(tokens, layer_index):
if layer_index % 2 == 0:
# Lapisan genap: Perhatian berselang-seling tanpa penyematan posisional
return attention_no_positional(tokens)
else:
# Lapisan ganjil: RoPE (Rotary Position Embeddings)
return attention_with_rope(tokens)
def inference_scaling(tokens, temperature_factor):
# Penskalaan suhu selama inferensi meningkatkan generalisasi panjang
return scale_attention_scores(tokens, temperature_factor)
Arsitektur ini memungkinkan Scout untuk memproses dokumen dengan panjang yang belum pernah terjadi sebelumnya sambil mempertahankan koherensi di seluruhnya, dengan faktor penskalaan sekitar 80x lebih besar daripada jendela konteks model Llama sebelumnya.
Analisis Tolok Ukur Komprehensif
Metrik Kinerja Tolok Ukur Standar
Hasil tolok ukur terperinci di seluruh rangkaian evaluasi utama mengungkapkan posisi kompetitif model Llama 4:
| Kategori | Tolok Ukur | Llama 4 Maverick | GPT-4o | Gemini 2.0 Flash | DeepSeek v3.1 |
|---|---|---|---|---|---|
| Penalaran Gambar | MMMU | 73.4 | 69.1 | 71.7 | Tidak ada dukungan multimodal |
| MathVista | 73.7 | 63.8 | 73.1 | Tidak ada dukungan multimodal | |
| Pemahaman Gambar | ChartQA | 90.0 | 85.7 | 88.3 | Tidak ada dukungan multimodal |
| DocVQA (uji) | 94.4 | 92.8 | - | Tidak ada dukungan multimodal | |
| Pengkodean | LiveCodeBench | 43.4 | 32.3 | 34.5 |


