
Dunia model bahasa besar (LLM) berkembang pesat, namun tantangan dalam efisiensi dan adaptabilitas waktu nyata masih ada. Pada tanggal 10 September 2025, Moonshot AI—kekuatan inovatif di balik seri Kimi—meluncurkan checkpoint-engine, sebuah middleware sumber terbuka yang mendefinisikan ulang pembaruan bobot dalam mesin inferensi LLM. Dirancang khusus untuk pembelajaran penguatan (RL), alat ringan ini dapat menyegarkan raksasa 1-triliun-parameter seperti Kimi-K2 di ribuan GPU hanya dalam 20 detik, memangkas waktu henti dan meningkatkan skalabilitas.
Artikel ini membahas mekanisme checkpoint-engine, mulai dari arsitektur hingga tolok ukurnya, sekaligus menyoroti implikasi RL dan kesesuaian ekosistemnya yang lebih luas. Dengan menjadikan permata ini sumber terbuka, Moonshot AI memberdayakan komunitas untuk mendorong batas LLM lebih jauh. Mari kita bedah inovasi ini lapis demi lapis.
Memahami Checkpoint-Engine: Konsep Inti dan Arsitektur
Apa itu Checkpoint-Engine?
Pada intinya, checkpoint-engine adalah middleware yang memfasilitasi pembaruan bobot di tempat yang mulus untuk LLM selama inferensi. Ini sangat penting dalam RL, di mana model berevolusi melalui umpan balik iteratif tanpa pelatihan ulang penuh. Metode tradisional membebani sistem dengan pemuatan ulang yang panjang; checkpoint-engine mengatasi ini dengan pendekatan yang ramping dan berbiaya rendah.
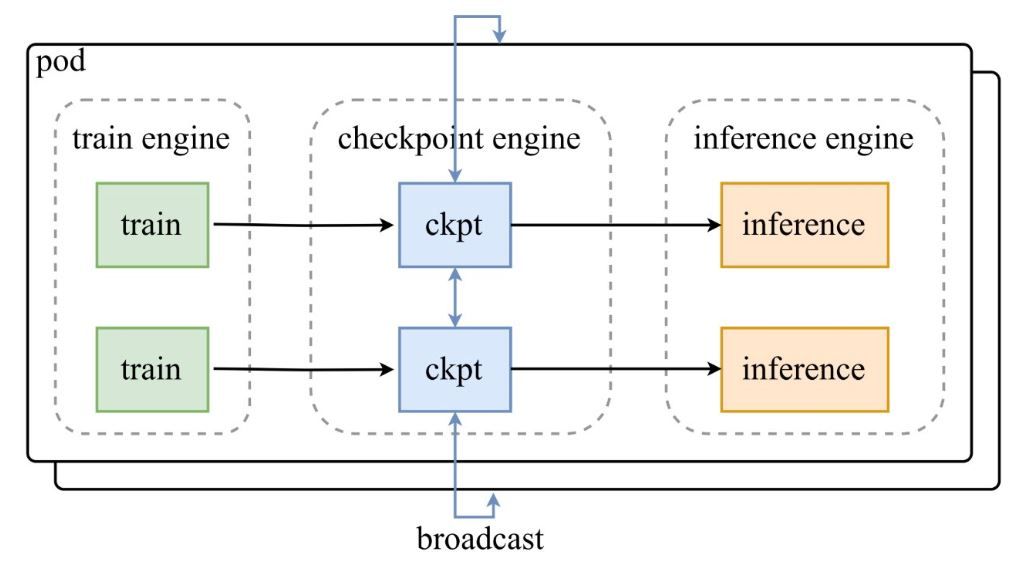
Seperti yang ditunjukkan dalam diagram arsitektur dari tweet pengumuman Moonshot AI, pod mesin pelatihan mengirimkan checkpoint ke checkpoint-engine pusat, yang kemudian menyiarkan pembaruan ke mesin inferensi. Repositori GitHub menyelami lebih dalam kode, menyoroti kelas ParameterServer sebagai orkestrator pembaruan.
Komponen Arsitektur
- Mesin Pelatihan (Train Engine): Menghasilkan bobot baru dari pelatihan RL yang sedang berlangsung, menangkap penyempurnaan kebijakan di lingkungan dinamis.
- Checkpoint Engine: Inti middleware, ditempatkan bersama inferensi untuk latensi minimal. Ini menangani pengumpulan metadata dan menjalankan pembaruan melalui mode Broadcast atau P2P.
- Mesin Inferensi (Inference Engine): Mengintegrasikan pembaruan secara langsung, menjaga kontinuitas layanan di seluruh kluster GPU terdistribusi.
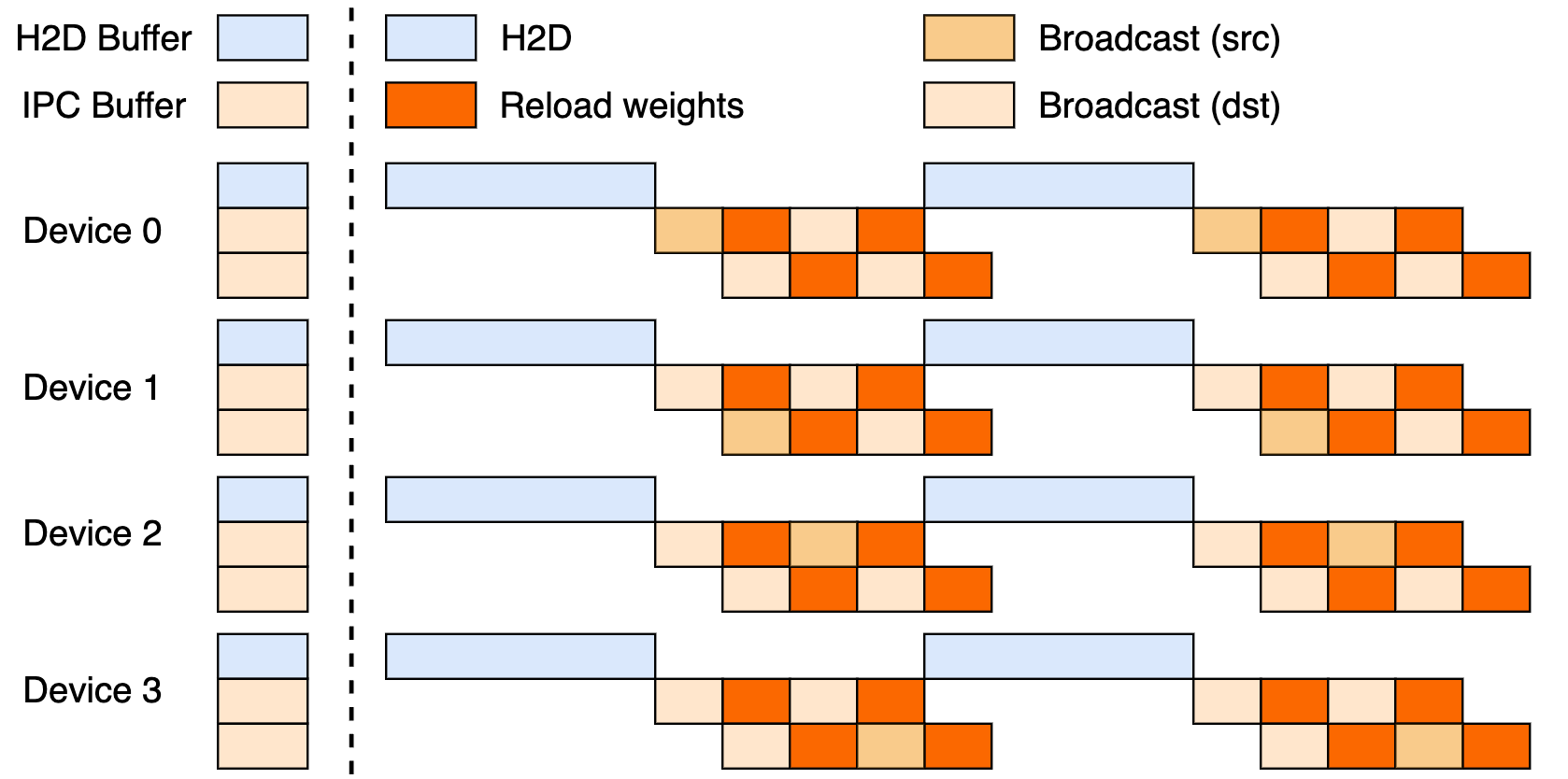
Pengaturan ini memanfaatkan pipeline tiga tahap: transfer Host-to-Device (H2D), siaran antar-pekerja menggunakan CUDA IPC, dan pemuatan ulang yang ditargetkan. Dengan tumpang tindih ini, ia memaksimalkan pemanfaatan GPU dan mengekang hambatan transfer.
Pembaruan Broadcast vs. P2P
Broadcast unggul dalam pembaruan sinkron di seluruh kluster—mode defaultnya untuk kecepatan puncak, mengelompokkan data untuk aliran optimal. P2P, sementara itu, unggul dalam skenario elastis, seperti penskalaan keluar selama puncak, dengan menggunakan RDMA melalui mooncake-transfer-engine untuk menghindari gangguan. Dualitas ini membuat checkpoint-engine serbaguna untuk penyebaran yang stabil maupun yang fluid.
Tolok Ukur Kinerja: Seberapa Cepatkah yang Cukup Cepat?
Memperbarui Model Triliun-Parameter dalam 20 Detik
Fitur utama checkpoint-engine? Memperbarui 1T parameter Kimi-K2 di ribuan GPU dalam waktu sekitar 20 detik. Ini berasal dari pipelining cerdas: perencanaan metadata menetapkan ukuran bucket yang efisien, soket ZeroMQ mengoordinasikan transfer, dan tahap H2D/broadcast yang tumpang tindih menyembunyikan latensi.
Bandingkan ini dengan teknik lama, yang mungkin membuat sistem menganggur selama beberapa menit di tengah pengacakan data besar-besaran. Etos in-place checkpoint-engine menjaga inferensi tetap berjalan, ideal untuk kebutuhan RL akan adaptasi yang cepat.
Analisis Tolok Ukur
Tabel tolok ukur menunjukkan hasil yang luar biasa di berbagai model dan pengaturan, diuji dengan vLLM v0.10.2rc1:
| Model | Info Perangkat | GatherMetas | Pembaruan (Broadcast) | Pembaruan (P2P) |
|---|---|---|---|---|
| GLM-4.5-Air (BF16) | 8xH800 TP8 | 0.17s | 3.94s (1.42GiB) | 8.83s (4.77GiB) |
| Qwen3-235B-A22B-Instruct-2507 (BF16) | 8xH800 TP8 | 0.46s | 6.75s (2.69GiB) | 16.47s (4.05GiB) |
| DeepSeek-V3.1 (FP8) | 16xH20 TP16 | 1.44s | 12.22s (2.38GiB) | 25.77s (3.61GiB) |
| Kimi-K2-Instruct (FP8) | 16xH20 TP16 | 1.81s | 15.45s (2.93GiB) | 36.24s (4.46GiB) |
| DeepSeek-V3.1 (FP8) | 256xH20 TP16 | 1.40s | 13.88s (2.54GiB) | 33.30s (3.86GiB) |
| Kimi-K2-Instruct (FP8) | 256xH20 TP16 | 1.88s | 21.50s (2.99GiB) | 34.49s (4.57GiB) |
Reproduksi ini melalui examples/update.py di repo. Jalankan FP8 memerlukan patch vLLM, menggarisbawahi efisiensi pada skala besar.
Implikasi untuk Pembelajaran Penguatan (Reinforcement Learning)
RL berkembang pesat pada iterasi cepat; siklus sub-20-detik checkpoint-engine memungkinkan loop pembelajaran berkelanjutan, melampaui metode batch. Ini membuka aplikasi responsif—mulai dari agen adaptif hingga chatbot yang berkembang—di mana setiap detik sangat berarti dalam penyetelan kebijakan.
Implementasi Teknis: Menyelami Kode Sumber
Aksesibilitas Sumber Terbuka
Rilis GitHub Moonshot AI mendemokratisasikan alat RL elit. ParameterServer menjadi jangkar pembaruan, menawarkan Broadcast (berbagi CUDA IPC cepat) dan P2P (RDMA untuk pendatang baru). Contoh seperti update.py dan tes (test_update.py) memudahkan orientasi.
Kompatibilitas dimulai dengan vLLM (melalui ekstensi pekerja), dengan kait untuk SGLang yang akan dipertimbangkan selanjutnya. Pipeline tiga tahap parsial mengisyaratkan potensi yang belum dimanfaatkan.
Teknik Optimasi
Kecerdasan utama meliputi:
- Tumpang Tindih Pipelined: Komunikasi dan penyalinan berjalan bersamaan, memangkas waktu efektif.
- Optimasi Bucket: Ukuran yang didorong metadata disesuaikan dengan sharding dan jaringan.
- Kontrol ZeroMQ: Pensinyalan latensi rendah ke mesin inferensi.
Ini mengatasi hambatan triliun-parameter, mulai dari bentrokan PCIe hingga tekanan memori (kembali ke serial jika diperlukan).
Batasan Saat Ini
Fungsi rank-0 P2P dapat tersendat pada skala besar, dan pipeline penuh menunggu penyempurnaan. Fokus vLLM membatasi cakupan, tetapi patch menjembatani celah FP8 untuk model seperti DeepSeek-V3.1. Pantau repo untuk evolusi.
Integrasi dengan Kerangka Kerja yang Ada: vLLM dan Selanjutnya
Kolaborasi dengan vLLM
Checkpoint-engine berpasangan secara native dengan PagedAttention vLLM untuk inferensi RL yang mulus. Duo ini mencapai sinkronisasi 20 detik pada model 1T, seperti yang diisyaratkan dalam pembaruan vLLM—sebuah anggukan untuk kolaborasi terbuka yang memperkuat throughput.
Potensi Ekstensi ke Claude dan Apidog
Memperluas ke Claude dari Anthropic dapat menyuntikkan dinamisme RL ke dalam obrolan yang berfokus pada keamanan, memungkinkan penyetelan halus secara langsung. Apidog sangat cocok untuk mocking endpoint selama penyesuaian ZeroMQ—unduh Apidog secara gratis untuk membuat prototipe jembatan ini dengan mudah.
Dampak Ekosistem yang Lebih Luas
Menghubungkan ke Ollama atau LM Studio dapat melokalisasi kekuatan triliun-parameter, menyamakan kedudukan bagi pengembang independen. Efek riak ini mendorong lanskap AI yang lebih inklusif.
Prospek Masa Depan: Apa yang Menanti Checkpoint-Engine?
Peningkatan Skalabilitas dan Kinerja
Peluncuran pipeline penuh dapat memangkas beberapa detik lagi, sementara desentralisasi P2P menghilangkan hambatan untuk elastisitas sejati. Penyesuaian RDMA menjanjikan kehebatan cloud-native.
Kontribusi Komunitas
Sumber terbuka mengundang perbaikan dan port—pikirkan penggabungan SGLang atau mode agnostik PCIe. Tanggapan awal di tweet penuh kegembiraan, memicu momentum.
Aplikasi Industri
Dari terjemahan waktu nyata hingga RL swakemudi, checkpoint-engine cocok untuk domain yang sangat fluktuatif. Kecepatannya menjaga model tetap segar, mengungguli pesaing dalam kelincahan.
Era Baru untuk Inferensi LLM?
Checkpoint-engine mengantarkan masa depan LLM yang gesit, mengatasi masalah bobot dengan gaya sumber terbuka. Pembaruan 1T 20 detik itu, didukung oleh arsitektur dan tolok ukur yang cerdas, mengukuhkan takhta RL-nya—terlepas dari keterbatasan.
Pasangkan dengan Apidog untuk alur pengembangan atau Claude untuk kecerdasan hibrida, dan inovasi akan melambung. Lacak GitHub, dapatkan Apidog gratis, dan bergabunglah dengan revolusi yang membentuk kembali inferensi hari ini!