
Pengembang terus mencari cara efisien untuk mengintegrasikan model AI canggih ke dalam aplikasi mereka, dan Qwen Next muncul sebagai pilihan yang menarik. Model ini, bagian dari seri Qwen Alibaba, menawarkan arsitektur Mixture of Experts (MoE) yang jarang, yang hanya mengaktifkan sebagian kecil parameternya selama inferensi. Hasilnya, Anda mendapatkan waktu pemrosesan yang lebih cepat dan biaya lebih rendah tanpa mengorbankan kinerja.
Memahami Arsitektur Inti Qwen Next dan Mengapa Penting bagi Pengguna API
Qwen Next’s arsitektur hibrida menggabungkan mekanisme gerbang dengan normalisasi canggih, mengoptimalkannya untuk tugas-tugas berbasis API. Lapisan MoE-nya mengarahkan input ke 10 dari 512 ahli khusus per token, ditambah satu ahli bersama, hanya mengaktifkan 3 miliar parameter. Kerapatan ini mengurangi tuntutan sumber daya, memungkinkan inferensi lebih cepat bagi pengguna Qwen API.

Selain itu, model ini menggunakan perhatian dot-product berskala dengan Partial Rotary Position Embeddings (RoPE), menjaga konteks dalam urutan hingga 128K token. Lapisan RMSNorm berpusat nol menstabilkan gradien, memastikan keluaran yang andal selama panggilan API bervolume tinggi. Jalur DeltaNet, dengan faktor ekspansi 3x, menggunakan normalisasi L2, lapisan konvolusional, dan aktivasi SiLU untuk mendukung speculative decoding, menghasilkan beberapa token secara bersamaan.
Bagi pengembang, ini berarti Integrasi Selanjutnya ke dalam aplikasi seperti alat analisis dokumen menjadi efisien dan terukur. Modularitas arsitektur memungkinkan penyesuaian untuk domain seperti keuangan, membuatnya dapat diadaptasi melalui Qwen API. Selanjutnya, mari kita periksa bagaimana fitur-fitur ini diterjemahkan ke dalam kinerja yang terukur.
Mengevaluasi Tolok Ukur Kinerja untuk Qwen Next dalam Aplikasi Berbasis API
Pengembang yang mengintegrasikan Qwen Next ke dalam alur kerja berbasis API memprioritaskan model yang menyeimbangkan kinerja tinggi dengan efisiensi komputasi. Qwen3-Next-80B-A3B, dengan arsitektur Mixture of Experts (MoE) yang jarang dan hanya mengaktifkan 3 miliar parameter selama inferensi, unggul dalam domain ini. Bagian ini mengevaluasi tolok ukur utama, menyoroti bagaimana Qwen Next mengungguli rekan-rekannya yang lebih padat seperti Qwen3-32B sambil memberikan kecepatan inferensi yang superior—penting untuk respons API real-time. Dengan memeriksa metrik di seluruh tugas pengetahuan umum, pengkodean, penalaran, dan konteks panjang, Anda mendapatkan wawasan tentang kesesuaiannya untuk aplikasi yang terukur.
Efisiensi Pra-Pelatihan dan Kinerja Model Dasar
Pra-pelatihan Qwen Next menunjukkan efisiensi yang luar biasa. Dilatih pada subset 15 triliun token dari korpus 36 triliun token Qwen3, model Qwen3-Next-80B-A3B-Base mengonsumsi kurang dari 80% jam GPU yang dibutuhkan oleh Qwen3-30B-A3B dan hanya 9,3% dari biaya komputasi Qwen3-32B. Meskipun demikian, ia hanya mengaktifkan sepersepuluh dari parameter non-embedding yang digunakan oleh Qwen3-32B-Base, namun melampaui model tersebut pada sebagian besar tolok ukur standar dan secara signifikan mengungguli Qwen3-30B-A3B.
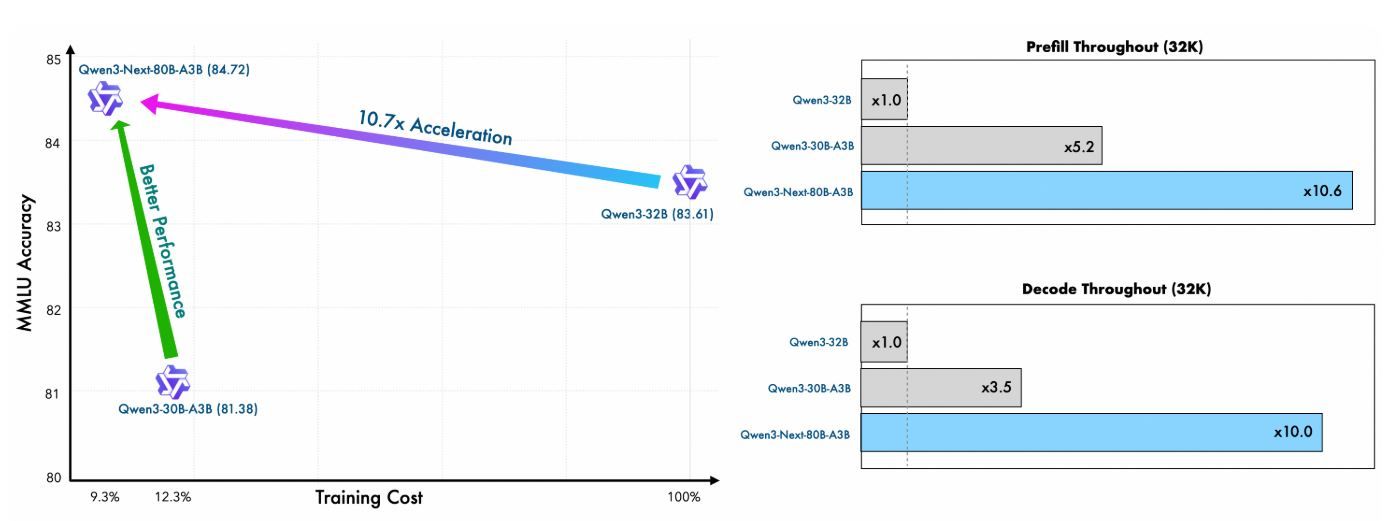
Efisiensi ini berasal dari arsitektur hibrida—menggabungkan Gated DeltaNet (75% lapisan) dengan Gated Attention (25%)—yang mengoptimalkan stabilitas pelatihan dan throughput inferensi. Bagi pengguna API, ini berarti biaya penyebaran yang lebih rendah dan prototipe yang lebih cepat, karena model mencapai perplexity dan pengurangan kerugian yang lebih baik dengan lebih sedikit sumber daya.
Metrik | Qwen3-Next-80B-A3B-Base | Qwen3-32B-Base | Qwen3-30B-A3B-Base |
|---|---|---|---|
Jam GPU Pelatihan (% dari Qwen3-32B) | 9.3% | 100% | ~125% |
Rasio Parameter Aktif | 10% | 100% | 10% |
Kinerja Tolok Ukur yang Unggul | Mengungguli pada sebagian besar | Dasar | Jauh lebih baik |
Angka-angka ini menggarisbawahi nilai Qwen Next dalam lingkungan API yang terbatas sumber daya, di mana pelatihan varian kustom melalui fine-tuning tetap memungkinkan.
Kecepatan Inferensi: Tahap Prefill dan Decode untuk Latensi API
Kecepatan inferensi secara langsung memengaruhi waktu respons API, terutama dalam skenario throughput tinggi seperti layanan obrolan atau pembuatan konten. Qwen Next unggul di sini, memanfaatkan MoE ultra-jarang (512 ahli, mengarahkan 10 + 1 bersama) dan Multi-Token Prediction (MTP) untuk speculative decoding.
Pada tahap prefill (pemrosesan prompt), Qwen Next mencapai throughput hampir 7x lebih tinggi daripada Qwen3-32B pada panjang konteks 4K. Di luar 32K token, keunggulan ini melebihi 10x, menjadikannya ideal untuk API analisis dokumen panjang.
Untuk tahap decode (pembuatan token), throughput mencapai hampir 4x pada konteks 4K dan lebih dari 10x pada panjang yang lebih lama. Mekanisme MTP, yang dioptimalkan untuk konsistensi multi-langkah, meningkatkan tingkat penerimaan dalam speculative decoding, lebih lanjut mempercepat inferensi dunia nyata.
Panjang Konteks | Throughput Prefill (vs. Qwen3-32B) | Throughput Decode (vs. Qwen3-32B) |
|---|---|---|
4K Token | 7x Lebih Cepat | 4x Lebih Cepat |
>32K Token | >10x Lebih Cepat | >10x Lebih Cepat |
Pengembang API sangat diuntungkan: latensi yang berkurang memungkinkan respons di bawah satu detik dalam produksi, sementara efisiensi daya (dari hanya mengaktifkan 3,7% parameter) menurunkan biaya cloud. Kerangka kerja seperti vLLM dan SGLang memperkuat keuntungan ini, mendukung hingga 256K konteks dengan paralelisme tensor.
Melakukan Panggilan API Pertama Anda dengan Qwen Next: Implementasi Langkah demi Langkah
Untuk memanfaatkan kemampuan Qwen Next, ikuti langkah-langkah yang jelas dan dapat ditindaklanjuti ini untuk menyiapkan dan menjalankan panggilan *Qwen API* melalui platform DashScope Alibaba. Panduan ini memastikan Anda dapat mengintegrasikan model secara efisien, baik untuk kueri sederhana maupun skenario *Integrasi Selanjutnya* yang kompleks.
Langkah 1: Buat Akun Alibaba Cloud dan Akses Model Studio
Mulailah dengan mendaftar akun Alibaba Cloud di alibabacloud.com. Setelah memverifikasi akun Anda, navigasikan ke konsol Model Studio dalam platform DashScope. Pilih Qwen3-Next-80B-A3B dari daftar model, pilih varian dasar, instruksi, atau pemikiran berdasarkan kasus penggunaan Anda—misalnya, instruksi untuk tugas percakapan atau pemikiran untuk penalaran kompleks.
Langkah 2: Hasilkan dan Amankan Kunci API Anda
Di dasbor DashScope, temukan bagian “Kunci API” dan hasilkan kunci baru. Kunci ini mengautentikasi permintaan *Qwen API* Anda. Perhatikan batas laju: tingkatan gratis menawarkan 1 juta token setiap bulan, cukup untuk pengujian awal. Simpan kunci dengan aman dalam variabel lingkungan untuk mencegah paparan:
bash
export DASHSCOPE_API_KEY='your_key_here'Praktik ini menjaga kode Anda tetap portabel dan aman.
Langkah 3: Instal DashScope Python SDK
Instal DashScope SDK untuk menyederhanakan interaksi *Qwen API*. Jalankan perintah berikut di terminal Anda:
bash
pip install dashscopeSDK menangani serialisasi, percobaan ulang, dan penguraian kesalahan, menyederhanakan proses integrasi Anda. Atau, gunakan klien HTTP seperti requests untuk pengaturan kustom, tetapi SDK direkomendasikan untuk kemudahan.
Langkah 4: Konfigurasi Titik Akhir API
Untuk klien yang kompatibel dengan OpenAI, atur URL dasar ke:
text
https://dashscope.aliyuncs.com/compatible-mode/v1Untuk panggilan DashScope asli, gunakan:
text
https://dashscope.aliyuncs.com/api/v1/services/aigc/text-generation/generationSertakan kunci API Anda di header permintaan sebagai X-DashScope-API-Key. Konfigurasi ini memastikan perutean yang tepat ke Qwen Next.
Langkah 5: Lakukan Panggilan API Pertama Anda
Buat permintaan generasi dasar menggunakan varian instruksi. Di bawah ini adalah skrip Python untuk mengkueri Qwen Next:
python
import os
from dashscope import Generation
os.environ['DASHSCOPE_API_KEY'] = 'your_api_key'
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Explain the benefits of MoE architectures in LLMs.',
max_tokens=200,
temperature=0.7
)
if response.status_code == 200:
print(response.output['text'])
else:
print(f"Error: {response.message}")Skrip ini mengirimkan prompt, membatasi keluaran hingga 200 token, dan mengontrol kreativitas dengan temperature=0.7. Kode status 200 menunjukkan keberhasilan; jika tidak, tangani kesalahan seperti batas kuota (kode 10402).
Langkah 6: Implementasikan Streaming untuk Respons Real-Time
Untuk aplikasi yang membutuhkan umpan balik instan, gunakan streaming:
python
from dashscope import Streaming
for response in Streaming.call(
model='qwen3-next-80b-a3b-instruct',
prompt='Generate a Python function for sentiment analysis.',
max_tokens=500,
incremental_output=True
):
if response.status_code == 200:
print(response.output['text_delta'], end='', flush=True)
else:
print(f"Error: {response.message}")
breakIni menghasilkan keluaran token demi token, sempurna untuk antarmuka obrolan langsung dalam Integrasi Selanjutnya.
Langkah 7: Tambahkan Pemanggilan Fungsi untuk Alur Kerja Agen
Perluas fungsionalitas dengan integrasi alat. Definisikan skema JSON untuk alat, seperti pengambilan cuaca:
python
tools = [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get current weather",
"parameters": {
"type": "object",
"properties": {"city": {"type": "string"}}
}
}
}]
response = Generation.call(
model='qwen3-next-80b-a3b-instruct',
prompt='What\'s the weather in Beijing?',
tools=tools,
tool_choice='auto'
)*Qwen API* mengurai prompt, memicu panggilan alat. Jalankan fungsi secara eksternal dan umpan balik hasilnya.
Langkah 8: Uji dan Validasi dengan Apidog
Gunakan *Apidog* untuk menguji panggilan API Anda. Impor skema DashScope ke proyek *Apidog* baru, tambahkan titik akhir, dan sertakan kunci API Anda di header. Buat badan JSON dengan prompt Anda, lalu jalankan kasus uji untuk memverifikasi respons. *Apidog* menghasilkan metrik seperti latensi dan menyarankan kasus ekstrem, meningkatkan keandalan.
Langkah 9: Pantau dan Debug Respons
Periksa kode respons untuk kesalahan (misalnya, 429 untuk batas laju). Catat keluaran yang dianonimkan untuk audit. Gunakan dasbor *Apidog* untuk melacak penggunaan token dan waktu respons, memastikan panggilan *Qwen API* Anda tetap dalam kuota.
Langkah-langkah ini menyediakan dasar yang kuat untuk mengintegrasikan Qwen Next. Selanjutnya, sederhanakan pengujian Anda dengan *Apidog*.
Memanfaatkan Pemanggilan Fungsi di Qwen Next API untuk Alur Kerja Agen
Pemanggilan fungsi memperluas utilitas Qwen Next di luar generasi teks. Definisikan alat dalam skema JSON, tentukan nama, deskripsi, dan parameter. Untuk kueri cuaca, gambarkan fungsi get_weather dengan parameter city.
Dalam panggilan API Anda, sertakan array `tools` dan atur `tool_choice` ke 'auto'. Model menganalisis prompt, mengidentifikasi maksud, dan mengembalikan panggilan alat. Jalankan fungsi secara eksternal dan umpan balik hasilnya untuk respons akhir.
Pola ini menciptakan sistem agen, di mana Qwen Next mengoordinasikan beberapa alat. Misalnya, gabungkan data cuaca dengan analisis sentimen untuk rekomendasi yang dipersonalisasi. Qwen API menangani penguraian secara efisien, mengurangi kebutuhan kode kustom.
Optimalkan dengan memvalidasi skema secara ketat. Pastikan parameter cocok dengan tipe yang diharapkan untuk menghindari kesalahan saat runtime. Saat Anda mengintegrasikan, uji panggilan ini secara menyeluruh—alat seperti Apidog terbukti sangat berharga di sini, mensimulasikan respons tanpa panggilan API langsung.
Mengintegrasikan Apidog untuk Pengujian dan Dokumentasi API Qwen yang Efisien
Panduan ini menyediakan alur kerja komprehensif untuk mengintegrasikan Apidog dengan Qwen API (Qwen Next/3.0 Alibaba Cloud) untuk pengujian, dokumentasi, dan manajemen siklus hidup API yang efisien.
Fase 1: Penyiapan Awal & Konfigurasi Akun
Langkah 1: Penyiapan Akun
1.1 Buat Akun yang Diperlukan
1. Akun Alibaba Cloud
2. Kunjungi: https://www.alibabacloud.com
3. Daftar & selesaikan verifikasi
4. Aktifkan layanan "Model Studio"
5. Akun Apidog
6. Kunjungi: https://apidog.com
7. Daftar dengan email/Google/GitHub
1.2 Dapatkan Kredensial API Qwen
1. Navigasikan ke: Konsol Alibaba Cloud → Model Studio → Kunci API
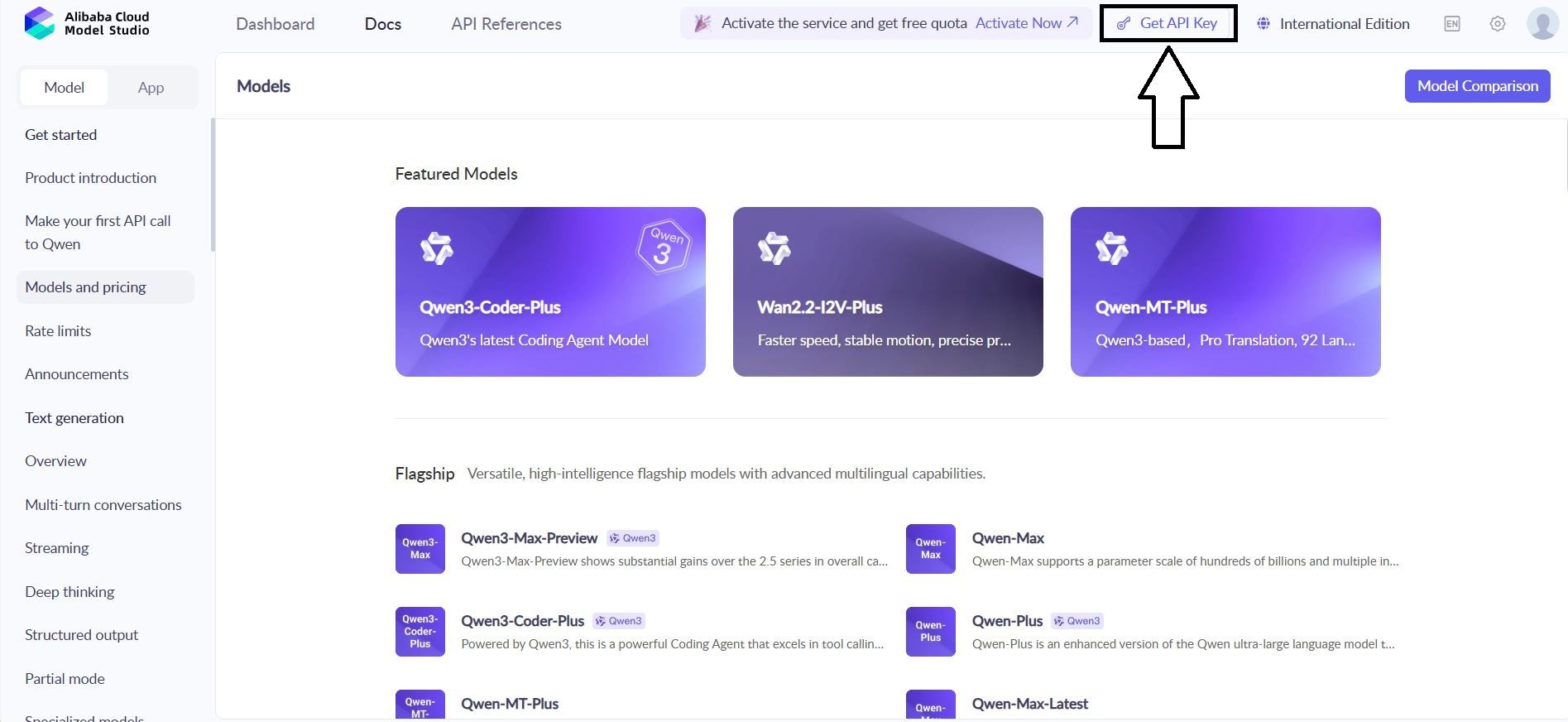
2. Buat kunci baru: qwen-testing-key
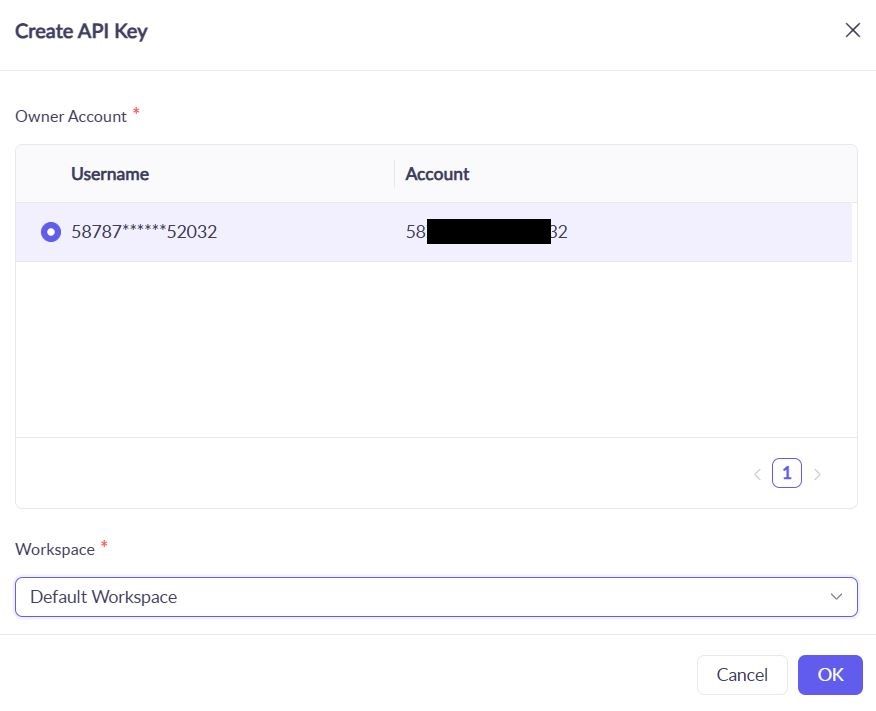
3. Simpan kunci Anda: sk-[kunci-aktual-Anda-di-sini]

1.3 Buat Proyek Apidog
- Masuk ke Apidog → Klik "Proyek Baru"
2. Konfigurasi Proyek :
1. Nama Proyek: Integrasi API Qwen
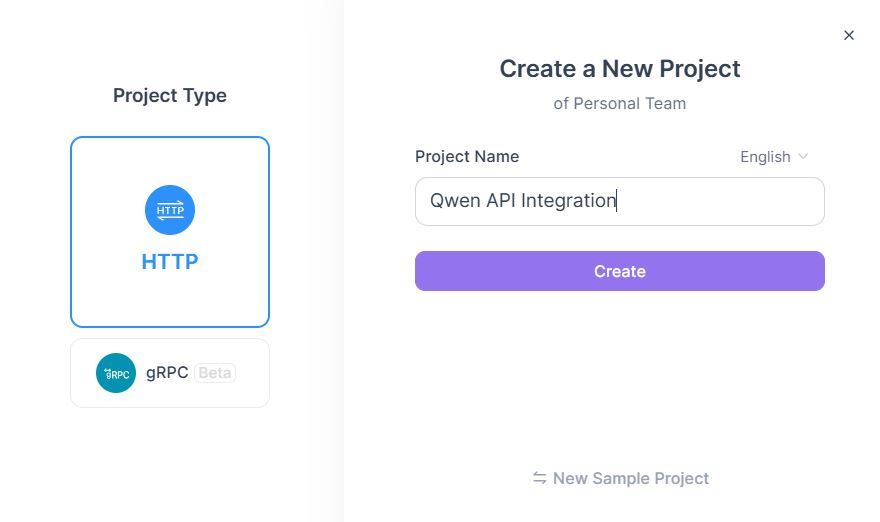
2. Deskripsi: Pengujian & dokumentasi API Qwen Next
Fase 2: Impor & Konfigurasi API
Langkah 2: Impor Spesifikasi API Qwen
Metode A: Pembuatan API Manual
- Tambah API Baru → "Buat API Secara Manual"
- Konfigurasi Titik Akhir Obrolan Qwen :

3. Atur Konfigurasi Permintaan :
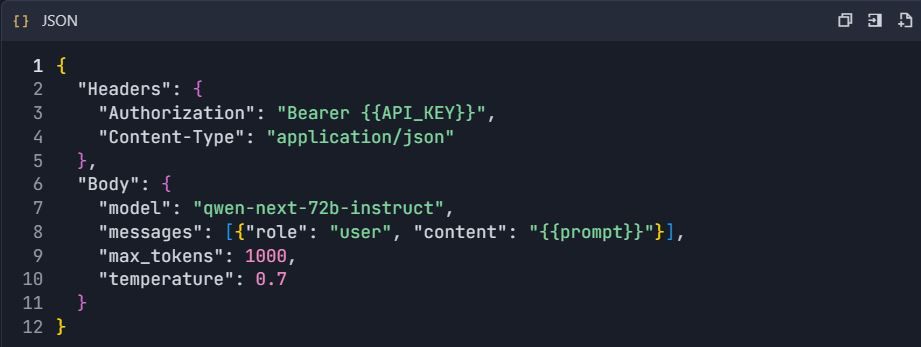
Metode B: Impor OpenAPI
- Unduh spesifikasi OpenAPI Qwen (jika tersedia)
- Buka Proyek → "Impor" → "OpenAPI/Swagger"
- Unggah file spesifikasi → "Impor"
Fase 3: Penyiapan Lingkungan & Otentikasi
Langkah 3: Konfigurasi Lingkungan
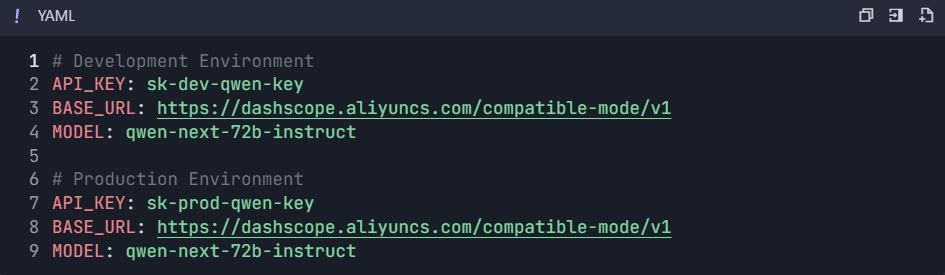
3.1 Buat Variabel Lingkungan
- Buka Pengaturan Proyek → "Lingkungan"
- Buat lingkungan :
Fase 4: Suite Pengujian Komprehensif
Langkah 4: Buat Skenario Pengujian
4.1 Pengujian Generasi Teks Dasar
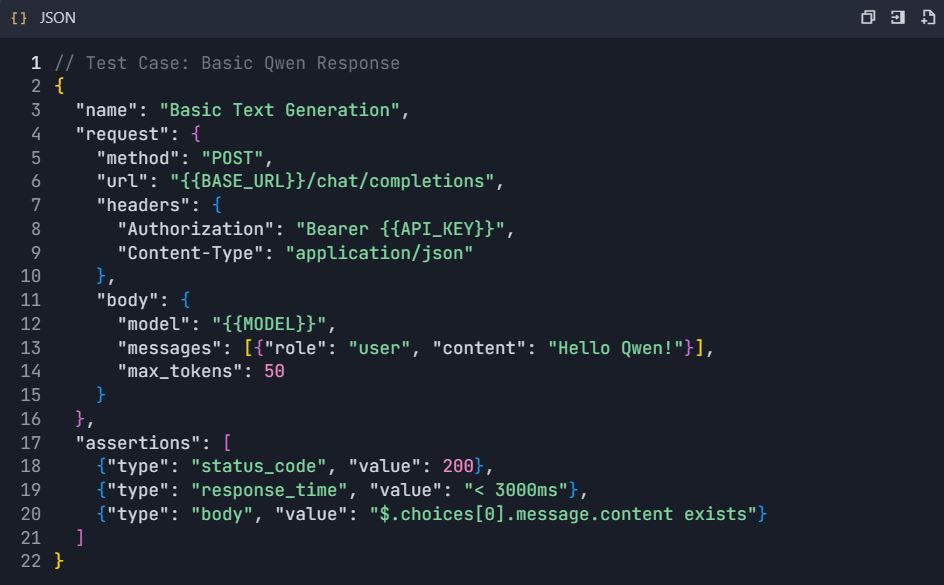
4.2 Skenario Pengujian Lanjutan
Suite Pengujian: Pengujian Komprehensif API Qwen
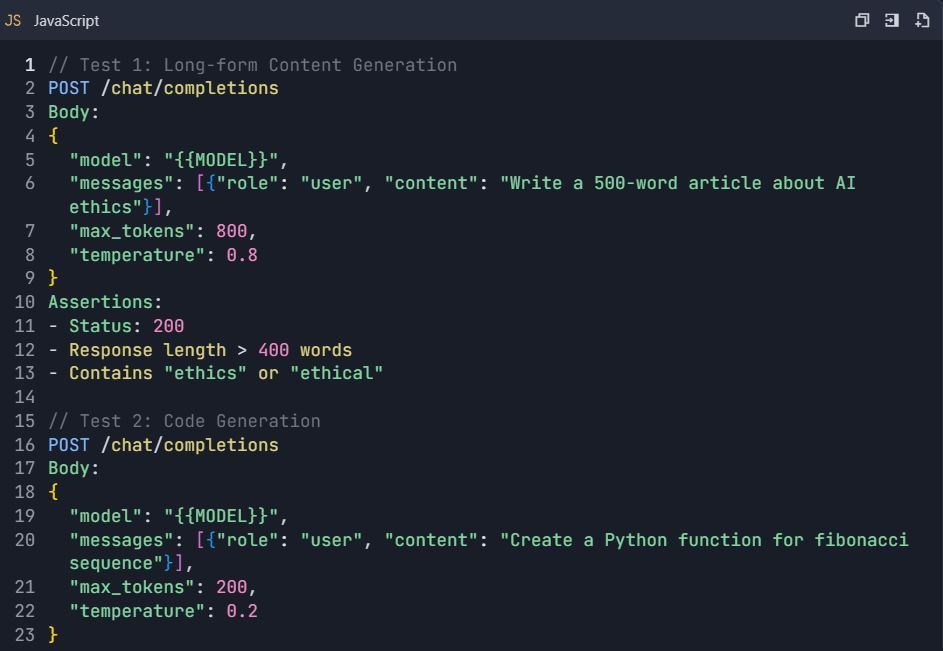
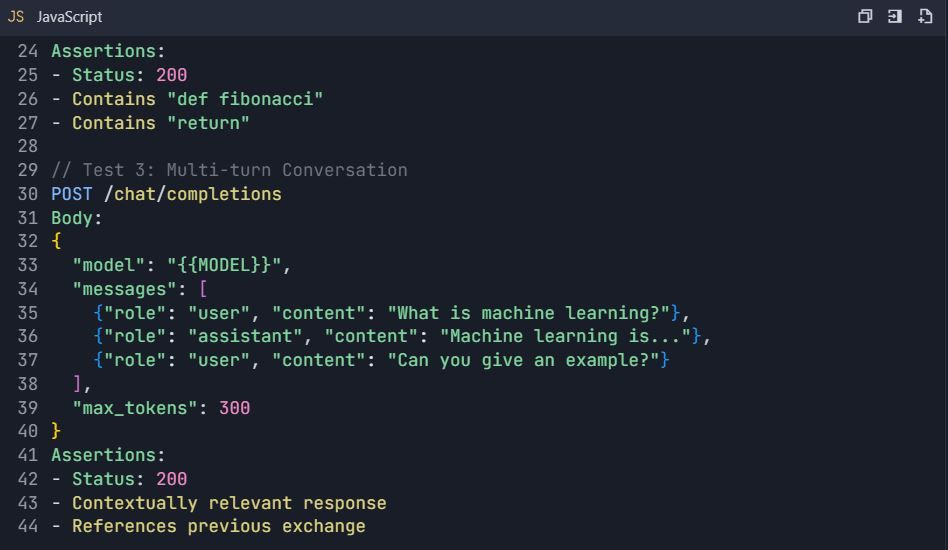
4.3 Pengujian Penanganan Kesalahan
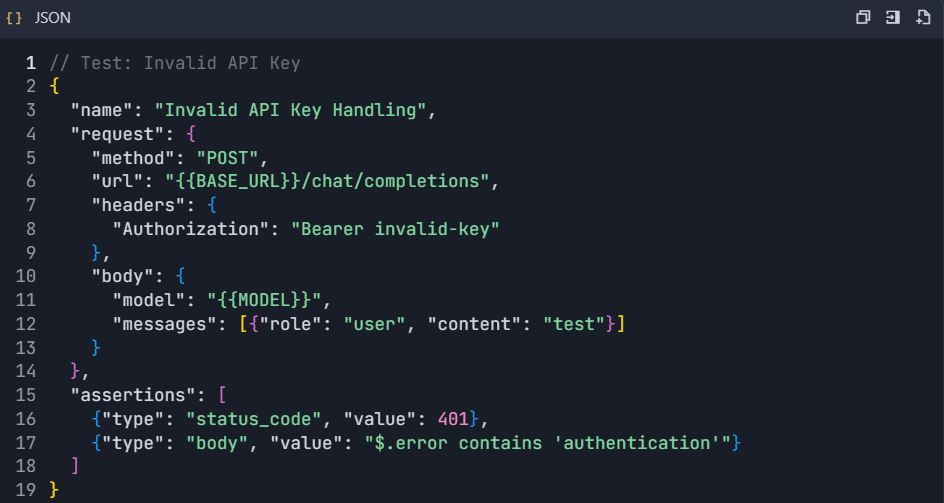
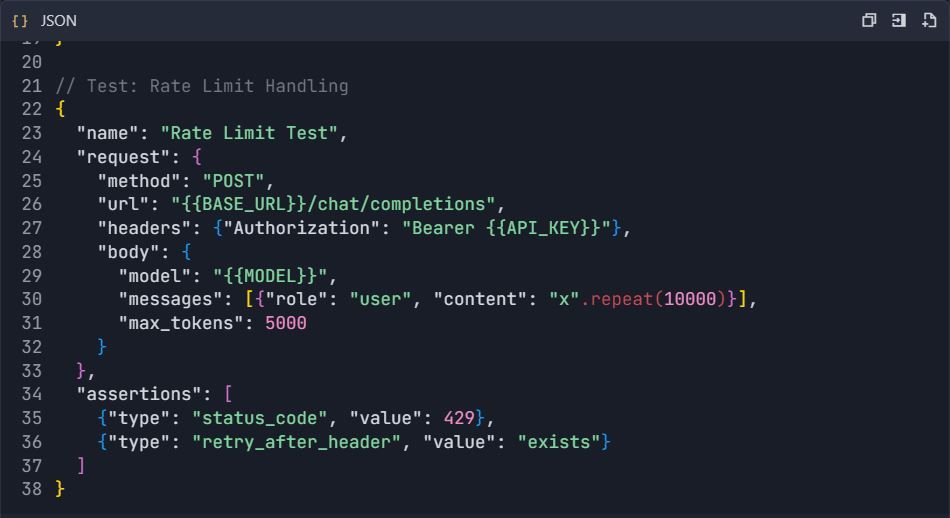
Fase 5: Generasi Dokumentasi
Langkah 5: Hasilkan Dokumentasi API Secara Otomatis 5.1 Buat Struktur Dokumentasi
- Buka Proyek → "Dokumentasi"
- Buat bagian :
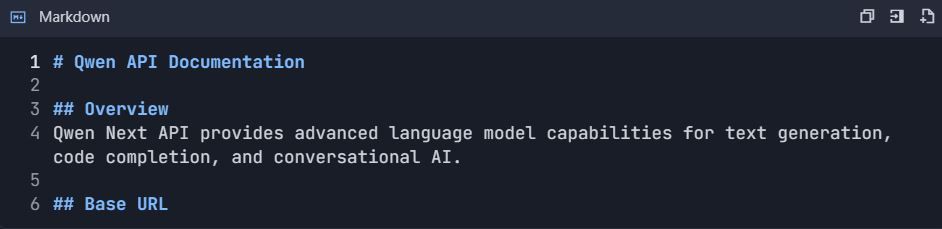
https://dashscope.aliyuncs.com/compatible-mode/v1

Otorisasi: Bearer sk-[kunci-api-Anda]

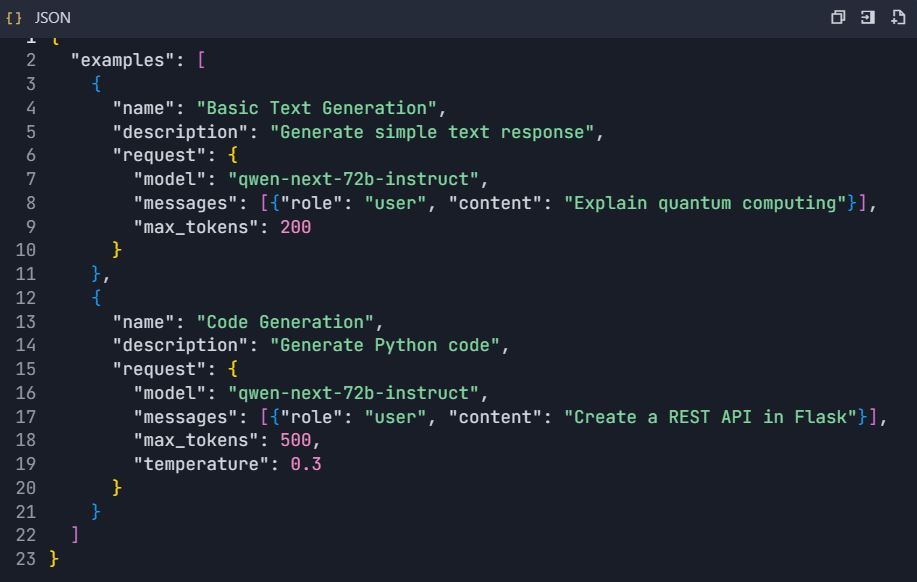
5.2 Penjelajah API Interaktif
- Konfigurasi contoh interaktif:
Fase 6: Fitur Lanjutan & Otomatisasi
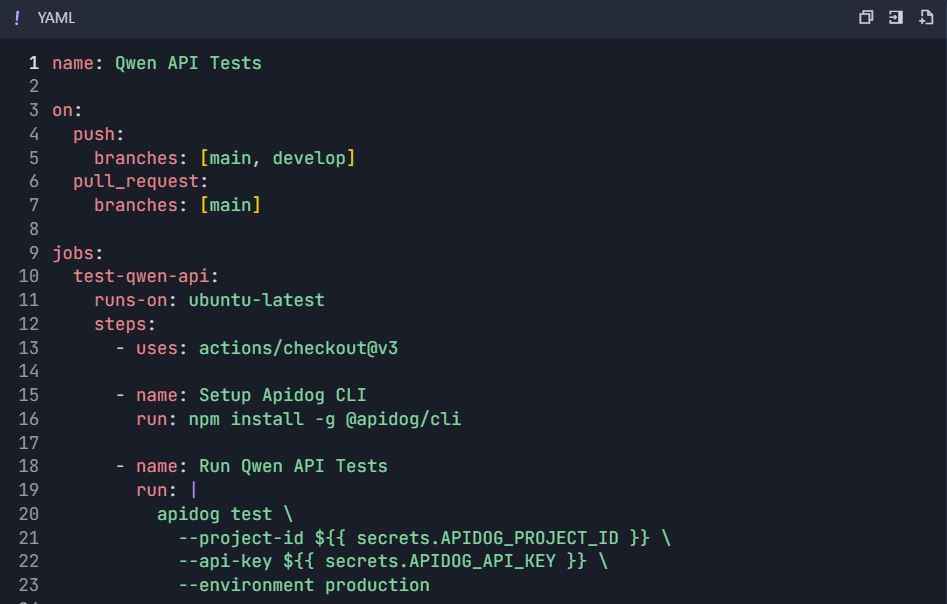
Langkah 6: Alur Kerja Pengujian Otomatis 6.1 Integrasi CI/CD
Alur Kerja GitHub Actions ( .github/workflows/qwen-tests.yml ):
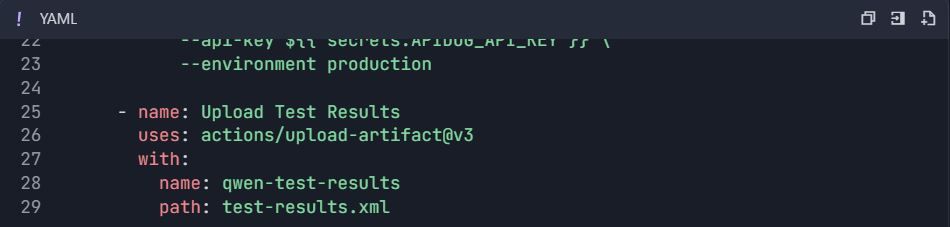
6.2 Pengujian Kinerja
- Buat suite pengujian kinerja:

2. Pantau metrik:
- Waktu respons (p50, p95, p99)
- Throughput (permintaan/detik)
- Tingkat kesalahan
- Efisiensi penggunaan token
6.3 Penyiapan Server Mock
- Aktifkan server mock:

2. Konfigurasi respons mock:
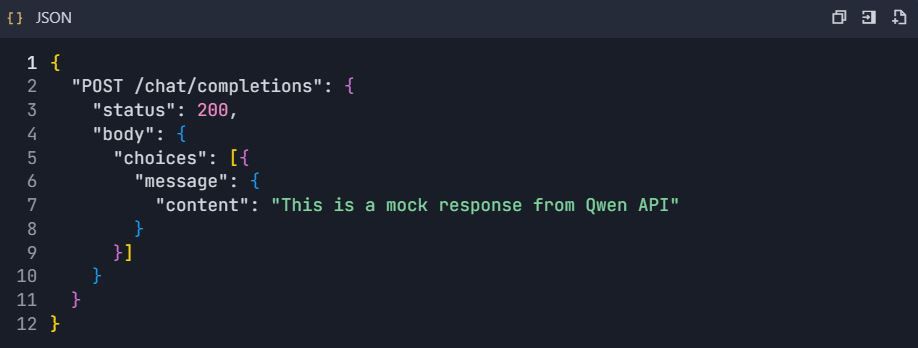
Fase 7: Pemantauan & Analitik
Langkah 7: Dasbor Analitik Penggunaan
7.1 Metrik Utama untuk Dilacak
- Statistik Penggunaan API :
- Jumlah permintaan per titik akhir
- Konsumsi token
- Tren waktu respons
- Analisis tingkat kesalahan
2. Pemantauan Biaya :
- Penggunaan token harian
- Estimasi biaya per permintaan
- Peringatan anggaran
7.2 Penyiapan Dasbor Kustom
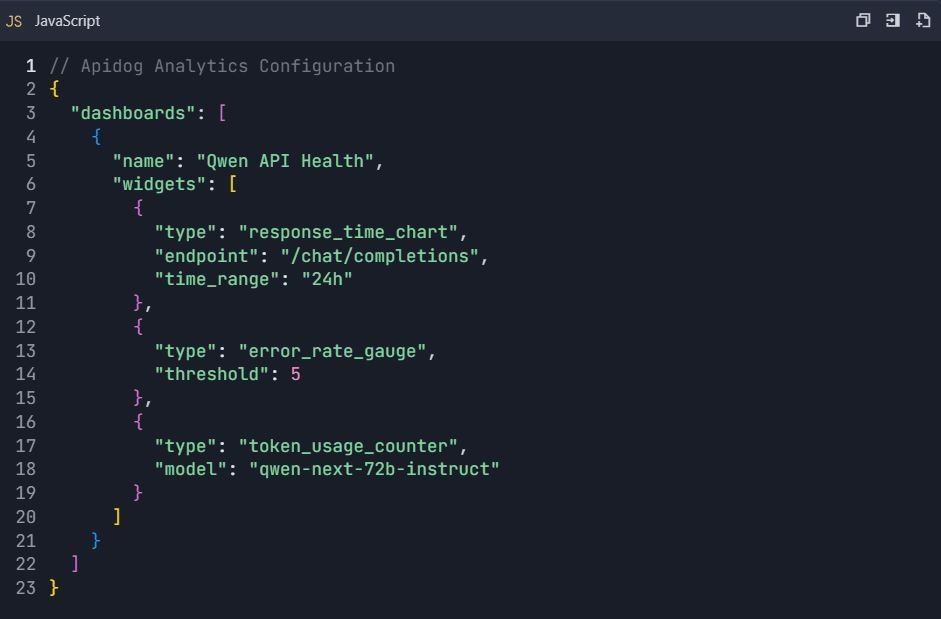
Fase 8: Kolaborasi Tim & Kontrol Versi
Langkah 8: Penyiapan Alur Kerja Tim
8.1 Konfigurasi Peran Tim

8.2 Integrasi Kontrol Versi
- Hubungkan ke repositori Git:

2. Strategi Percabangan :

Contoh Alur Kerja Pengujian Lengkap
Skenario Pengujian End-to-End
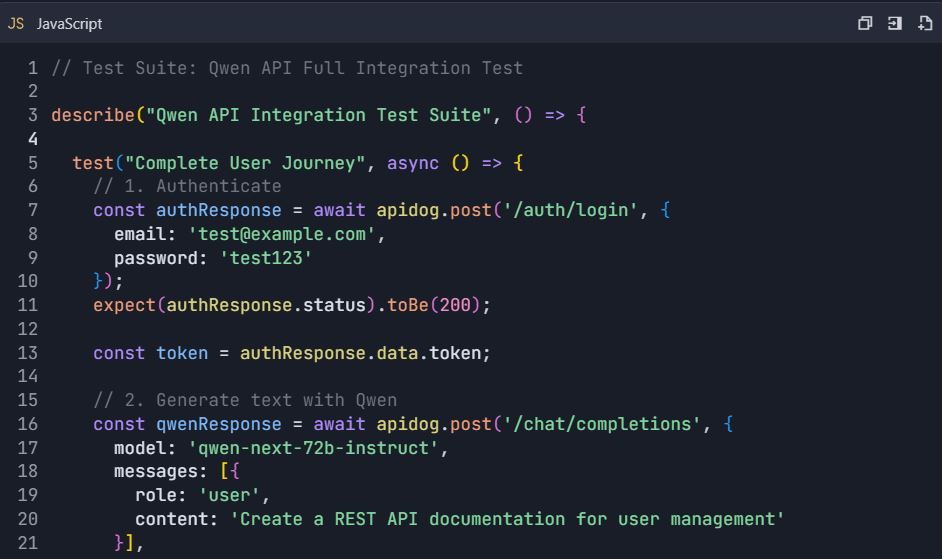
📋 Perintah Pengujian:
Panduan integrasi komprehensif ini menyediakan semua yang diperlukan untuk menguji dan mendokumentasikan API Qwen secara efisien menggunakan Apidog. Penyiapan ini memungkinkan pengujian otomatis, pemantauan kinerja, kolaborasi tim, dan integrasi berkelanjutan untuk pengembangan API yang kuat.
Teknik Optimasi Lanjutan untuk Qwen Next API di Lingkungan Produksi
Pemrosesan batch memaksimalkan efisiensi dalam skenario bervolume tinggi. DashScope memungkinkan hingga 10 prompt per panggilan, mengkonsolidasikan permintaan untuk meminimalkan overhead latensi. Ini cocok untuk aplikasi seperti ringkasan massal.
Pantau penggunaan token dengan cermat, karena biaya terkait dengan parameter aktif. Buat prompt yang ringkas untuk menghemat biaya, dan gunakan result_format='message' untuk keluaran yang dapat diurai, melewati pemrosesan tambahan.
Implementasikan percobaan ulang dengan exponential backoff untuk menangani transien. Sebuah fungsi yang membungkus panggilan mencoba beberapa kali, tidur lebih lama secara progresif di antara percobaan. Ini memastikan keandalan di bawah beban.
Untuk skalabilitas, distribusikan ke seluruh wilayah seperti Singapura atau AS. Bersihkan input untuk menggagalkan injeksi prompt, memvalidasi terhadap daftar putih. Catat respons yang dianonimkan untuk kepatuhan.
Dalam kasus konteks panjang, pecah data dan rangkai panggilan. Varian pemikiran mendukung prompt terstruktur untuk koherensi di atas token yang diperpanjang. Strategi ini mengamankan penyebaran yang kuat.
Menjelajahi Integrasi Selanjutnya: Menyematkan Qwen Next dalam Aplikasi Web
Integrasi Selanjutnya mengacu pada penggabungan Qwen Next ke dalam kerangka kerja Next.js, memanfaatkan rendering sisi server untuk fitur AI. Siapkan rute API di Next.js untuk memproksi panggilan Qwen, menyembunyikan kunci dari klien.
Dalam penangan API Anda, gunakan DashScope SDK untuk memproses permintaan, mengembalikan respons streaming jika diperlukan. Penyiapan ini memungkinkan konten dinamis, seperti halaman yang dipersonalisasi yang dihasilkan secara instan.
Tangani otentikasi sisi server, menggunakan manajemen sesi. Untuk pembaruan real-time, integrasikan WebSockets dengan keluaran streaming. Uji ini dengan Apidog, mensimulasikan permintaan klien.
Penyetelan kinerja melibatkan caching kueri yang sering. Gunakan Redis untuk menyimpan respons, mengurangi hit API. Kombinasi ini memberdayakan aplikasi interaktif secara efisien.
Kemampuan Multibahasa dan Konteks Panjang di Qwen Next API
Qwen Next mendukung 119 bahasa, menjadikannya serbaguna untuk aplikasi global. Tentukan bahasa dalam prompt untuk terjemahan atau generasi yang akurat. API menangani peralihan dengan mulus, menjaga konteks.
Untuk konteks panjang, perluas hingga 128K token dengan mengatur max_context_length. Ini unggul dalam menganalisis dokumen besar. Chain-of-thought prompting meningkatkan penalaran di atas volume.
Benchmarking menunjukkan recall yang superior, ideal untuk mesin pencari. Integrasikan dengan database untuk memasukkan konteks secara dinamis.
Praktik Terbaik Keamanan untuk Penyebaran Qwen API
Lindungi kunci dengan brankas seperti AWS Secrets Manager. Pantau penggunaan untuk anomali, atur peringatan pada lonjakan. Patuhi peraturan dengan menganonimkan data.
Pembatasan laju sisi klien mencegah penyalahgunaan. Enkripsi transmisi dengan HTTPS.
Memantau dan Menskalakan Penggunaan Qwen Next API
Dasbor DashScope melacak metrik seperti konsumsi token. Tetapkan anggaran untuk menghindari kelebihan. Skalakan dengan meningkatkan tingkatan untuk batas yang lebih tinggi.
Infrastruktur auto-scaling merespons lalu lintas. Alat seperti Kubernetes mengelola kontainer yang menghosting Integrasi Selanjutnya.
Studi Kasus: Aplikasi Dunia Nyata Qwen Next melalui API
Dalam e-commerce, Qwen Next memberdayakan mesin rekomendasi, menganalisis riwayat pengguna untuk saran. Panggilan API menghasilkan deskripsi secara dinamis.
Aplikasi perawatan kesehatan menggunakan varian pemikiran untuk alat bantu diagnostik, memproses laporan dengan akurasi tinggi.
Platform konten menggunakan model instruksi untuk penulisan otomatis, menskalakan produksi.
Prospek dan Pembaruan Masa Depan untuk Qwen Next
Alibaba terus mengembangkan seri ini, dengan potensi lebih banyak ahli atau perutean yang lebih baik. Tetap terbarui melalui saluran resmi seperti akun X QwenAI_Plus.
Peningkatan API mungkin termasuk dukungan alat yang lebih baik.
Memanfaatkan Qwen Next untuk Solusi Inovatif
Qwen Next melalui API menawarkan efisiensi tak tertandingi. Dari penyiapan hingga optimasi, Anda kini memiliki alat untuk mengimplementasikan secara efektif. Bereksperimenlah dengan integrasi, memanfaatkan Apidog untuk alur kerja yang lancar.