Model Llama 4 Meta, yaitu Llama 4 Maverick dan Llama 4 Scout, mewakili lompatan maju dalam teknologi AI multimodal. Dirilis pada tanggal 5 April 2025, model-model ini memanfaatkan arsitektur Mixture-of-Experts (MoE), memungkinkan pemrosesan teks dan gambar yang efisien dengan rasio kinerja terhadap biaya yang luar biasa. Pengembang dapat memanfaatkan kemampuan ini melalui API yang disediakan oleh berbagai platform, membuat integrasi ke dalam aplikasi menjadi lancar dan kuat.
Memahami Llama 4 Maverick dan Llama 4 Scout
Sebelum menyelami penggunaan API, pahami spesifikasi inti dari model-model ini. Llama 4 memperkenalkan multimodality asli, yang berarti ia memproses teks dan gambar bersama-sama dari awal. Selain itu, desain MoE-nya hanya mengaktifkan sebagian parameter per tugas, meningkatkan efisiensi.
Llama 4 Scout: Andalan Multimodal yang Efisien
- Parameter: 17 miliar aktif, 109 miliar total, 16 ahli.
- Jendela Konteks: Hingga 10 juta token.
- Fitur Utama: Unggul dalam tugas-tugas konteks panjang seperti peringkasan multi-dokumen dan penalaran atas basis kode yang besar. Cocok untuk satu GPU NVIDIA H100 dengan kuantisasi INT4.
- Kasus Penggunaan: Ideal untuk pengembang yang membutuhkan pemrosesan multimodal yang cepat dan hemat sumber daya.
Llama 4 Maverick: Pusat Kekuatan Serbaguna
- Parameter: 17 miliar aktif, 400 miliar total, 128 ahli.
- Jendela Konteks: Hingga 1 juta token.
- Fitur Utama: Menawarkan pemahaman teks dan gambar berkualitas tinggi, mendukung 12 bahasa (misalnya, Inggris, Spanyol, Hindi). Dioptimalkan untuk obrolan dan penulisan kreatif.
- Kasus Penggunaan: Cocok untuk asisten tingkat perusahaan dan aplikasi multibahasa.
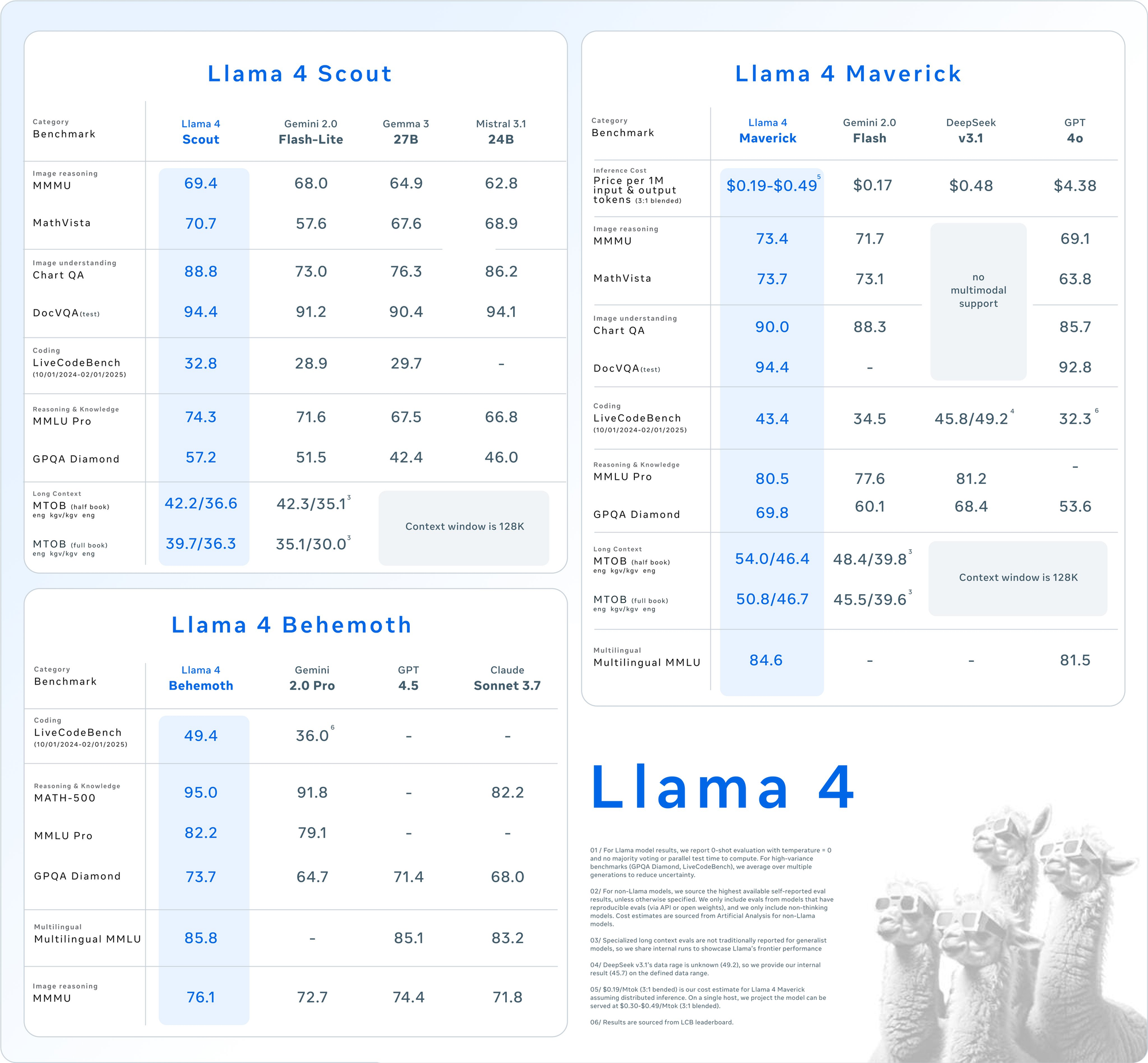
Kedua model ini mengungguli pendahulunya seperti Llama 3 dan bersaing dengan raksasa industri seperti GPT-4o, menjadikannya pilihan yang menarik untuk proyek berbasis API.
Mengapa Menggunakan API Llama 4?
Mengintegrasikan Llama 4 melalui API menghilangkan kebutuhan untuk menghosting model-model besar ini secara lokal, yang seringkali membutuhkan perangkat keras yang signifikan (misalnya, NVIDIA H100 DGX untuk Maverick). Sebagai gantinya, platform seperti Groq, Together AI, dan OpenRouter menyediakan API terkelola, menawarkan:
- Skalabilitas: Menangani berbagai beban tanpa overhead infrastruktur.
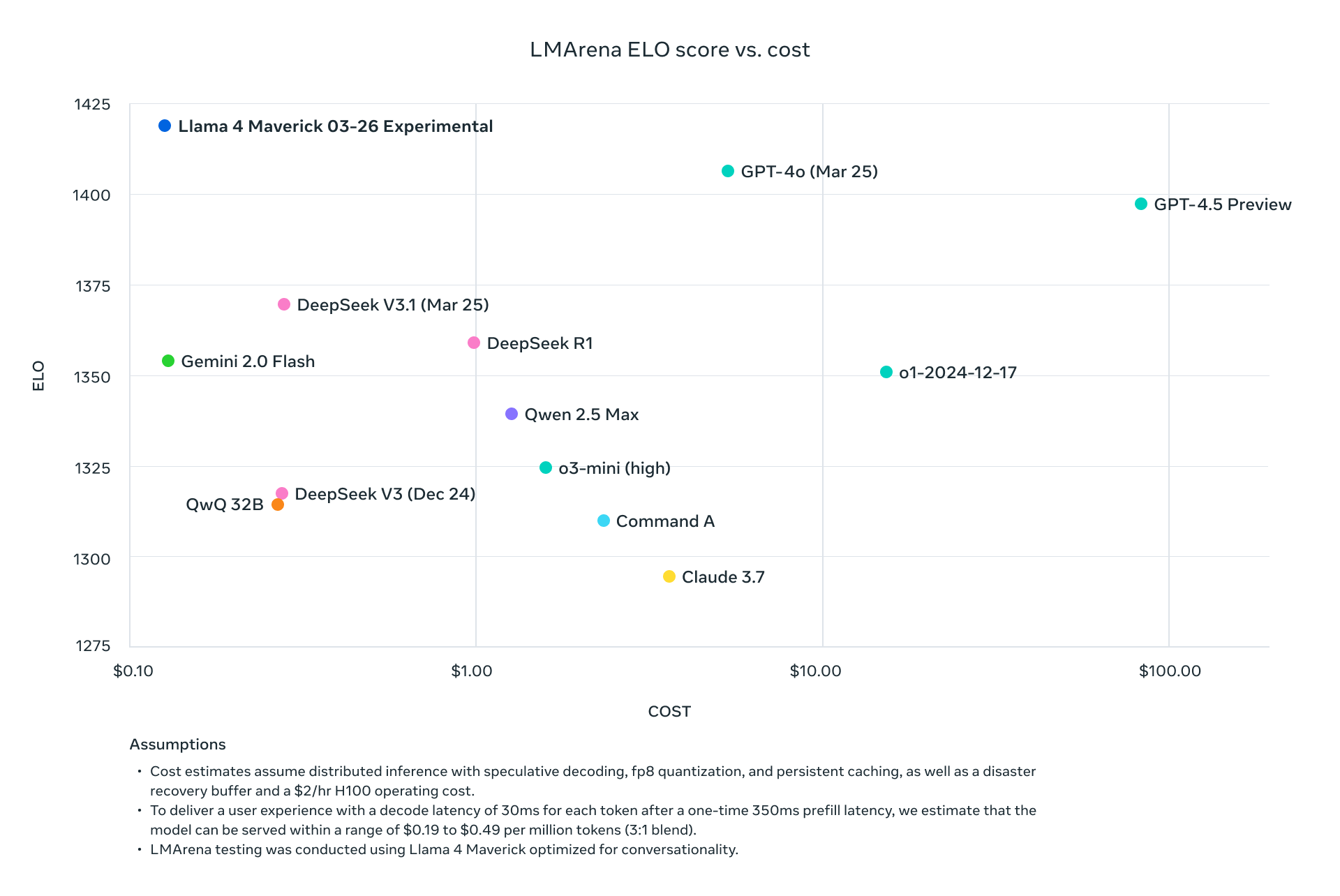
- Efisiensi Biaya: Bayar per token, dengan tarif serendah $0,11/M token input (Scout di Groq).
- Kemudahan Penggunaan: Akses fitur multimodal dengan permintaan HTTP sederhana.
Selanjutnya, mari siapkan lingkungan Anda untuk memanggil API ini.
Menyiapkan Lingkungan Anda untuk Panggilan API Llama 4
Untuk berinteraksi dengan Llama 4 Maverick dan Llama 4 Scout melalui API, siapkan lingkungan pengembangan Anda. Ikuti langkah-langkah ini:
Langkah 1: Pilih Penyedia API
Beberapa platform menghosting API Llama 4. Berikut adalah opsi populer:
- Groq: Menawarkan inferensi berbiaya rendah (Scout: $0,11/M input, Maverick: $0,50/M input).
- Together AI: Menyediakan endpoint khusus dengan penskalaan khusus.
- OpenRouter: Tingkat gratis tersedia, ideal untuk pengujian.
- Cloudflare Workers AI: Penerapan tanpa server dengan dukungan Scout.
Untuk panduan ini, kita akan menggunakan Groq dan Together AI sebagai contoh karena dokumentasi dan kinerjanya yang kuat.
Langkah 2: Dapatkan Kunci API
- Groq: Daftar di groq.com, navigasikan ke Konsol Pengembang, dan hasilkan kunci API.
- Together AI: Daftar di together.ai, lalu akses kunci API Anda dari dasbor.
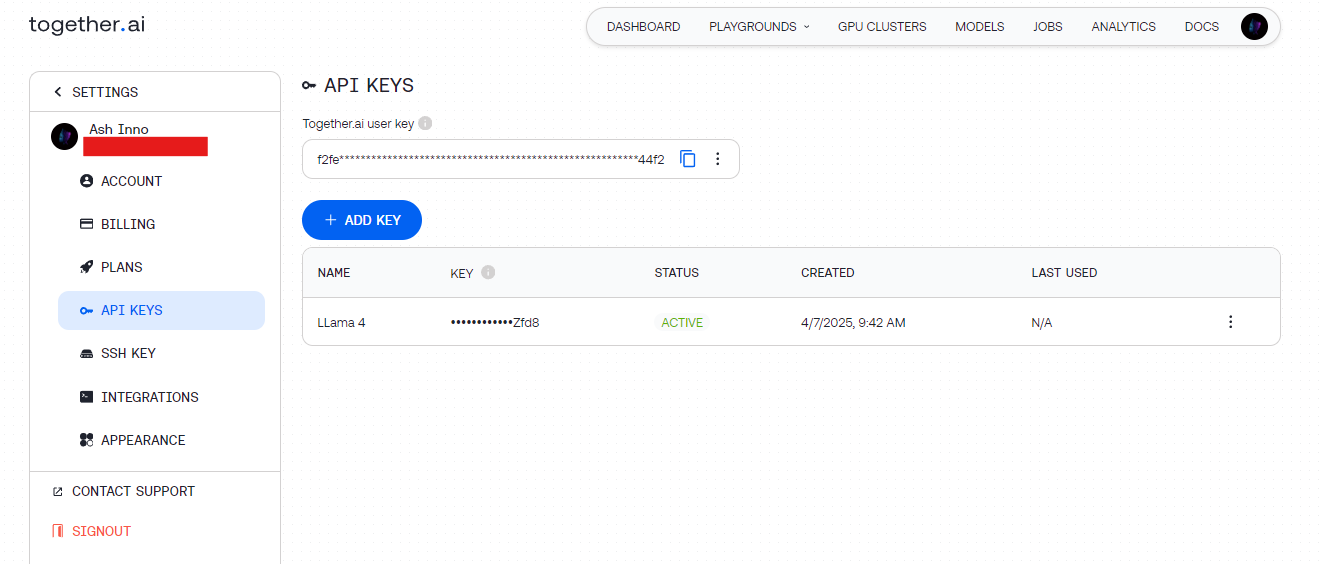
Simpan kunci ini dengan aman (misalnya, dalam variabel lingkungan) untuk menghindari pengkodean keras.
Langkah 3: Instal Dependensi
Gunakan Python untuk kesederhanaan. Instal pustaka yang diperlukan:
pip install requests
Untuk pengujian, Apidog melengkapi pengaturan ini dengan membiarkan Anda men-debug endpoint API secara visual.
Melakukan Panggilan API Llama 4 Pertama Anda
Dengan lingkungan Anda siap, kirim permintaan ke API Llama 4. Mari kita mulai dengan contoh pembuatan teks dasar.
Contoh 1: Pembuatan Teks dengan Llama 4 Scout (Groq)
import requests
import os
# Set API key
API_KEY = os.getenv("GROQ_API_KEY")
URL = "https://api.groq.com/v1/chat/completions"
# Define payload
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": "Write a short poem about AI."}
],
"max_tokens": 150,
"temperature": 0.7
}
# Set headers
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Send request
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: Sebuah puisi ringkas yang dihasilkan oleh Scout, memanfaatkan arsitektur MoE-nya yang efisien.
Contoh 2: Input Multimodal dengan Llama 4 Maverick (Together AI)
Maverick bersinar dalam tugas-tugas multimodal. Berikut cara mendeskripsikan sebuah gambar:
import requests
import os
# Set API key
API_KEY = os.getenv("TOGETHER_API_KEY")
URL = "https://api.together.ai/v1/chat/completions"
# Define payload with image and text
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/sample.jpg"}
},
{
"type": "text",
"text": "Describe this image."
}
]
}
],
"max_tokens": 200
}
# Set headers
headers = {
"Authorization": f"Bearer {API_KEY}",
"Content-Type": "application/json"
}
# Send request
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: Deskripsi rinci dari gambar, yang menunjukkan keselarasan gambar-teks Maverick.
Mengoptimalkan Permintaan API untuk Kinerja
Untuk memaksimalkan efisiensi, sesuaikan panggilan API Llama 4 Anda. Pertimbangkan teknik-teknik ini:
Sesuaikan Panjang Konteks
- Scout: Gunakan jendela token 10M-nya untuk dokumen panjang. Atur
max_model_len(jika didukung) untuk menangani input besar. - Maverick: Batasi hingga 1 juta token untuk aplikasi obrolan untuk menyeimbangkan kecepatan dan kualitas.
Parameter Fine-Tune
- Temperature: Lebih rendah (misalnya, 0,5) untuk respons faktual, lebih tinggi (misalnya, 1,0) untuk kreativitas.
- Max Tokens: Batasi panjang output untuk menghindari komputasi yang tidak perlu.
Pemrosesan Batch
Kirim beberapa perintah dalam satu permintaan (jika API mendukungnya) untuk mengurangi latensi. Periksa dokumen penyedia untuk endpoint batch.
Kasus Penggunaan Tingkat Lanjut dengan API Llama 4
Sekarang, jelajahi integrasi tingkat lanjut untuk membuka potensi penuh Llama 4.
Kasus Penggunaan 1: Chatbot Multibahasa
Maverick mendukung 12 bahasa. Bangun bot dukungan pelanggan:
payload = {
"model": "meta-llama/Llama-4-Maverick-17B-128E-Instruct-FP8",
"messages": [
{"role": "user", "content": "Hola, ¿cómo puedo resetear mi contraseña?"}
],
"max_tokens": 100
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: Respons Spanyol, memanfaatkan kefasihan multibahasa Maverick.
Kasus Penggunaan 2: Peringkasan Dokumen dengan Scout
Jendela token 10M Scout unggul dalam meringkas teks besar:
long_text = "..." # Insert a lengthy document here
payload = {
"model": "meta-llama/Llama-4-Scout-17B-16E-Instruct",
"messages": [
{"role": "user", "content": f"Summarize this: {long_text}"}
],
"max_tokens": 300
}
response = requests.post(URL, json=payload, headers=headers)
print(response.json()["choices"][0]["message"]["content"])
Output: Ringkasan ringkas, diproses secara efisien oleh Scout.
Debugging dan Pengujian dengan Apidog
Menguji API bisa jadi rumit, terutama dengan input multimodal. Di sinilah Apidog bersinar:
- Antarmuka Visual: Bangun dan kirim permintaan tanpa pengkodean.
- Pelacakan Kesalahan: Identifikasi masalah seperti batas tarif atau payload yang salah format.
- Respons Mock: Simulasikan output Llama 4 untuk pengembangan frontend.
Untuk menguji contoh di atas di Apidog:
- Buka Apidog dan buat permintaan baru.
- Atur URL (misalnya,
https://api.groq.com/v1/chat/completions).

- Tambahkan header (
Authorization,Content-Type).
- Tempel payload JSON.

- Kirim dan tinjau respons.

Alur kerja ini memastikan integrasi API Llama 4 Anda berjalan dengan lancar.
Membandingkan Penyedia API untuk Llama 4
Memilih penyedia yang tepat memengaruhi biaya dan kinerja. Berikut adalah rinciannya:
| Penyedia | Dukungan Model | Harga (Input/Output per M) | Batas Konteks | Catatan |
|---|---|---|---|---|
| Groq | Scout, Maverick | $0,11/$0,34 (Scout), $0,50/$0,77 (Maverick) | 128K (dapat diperluas) | Biaya terendah, kecepatan tinggi |
| Together AI | Scout, Maverick | Kustom (endpoint khusus) | 1M (Maverick) | Terukur, fokus pada perusahaan |
| OpenRouter | Keduanya | Tingkat gratis tersedia | 128K | Bagus untuk pengujian |
| Cloudflare | Scout | Berdasarkan penggunaan | 131K | Kesederhanaan tanpa server |
Pilih berdasarkan skala dan anggaran proyek Anda. Untuk pembuatan prototipe, mulai dengan tingkat gratis OpenRouter, lalu skala dengan Groq atau Together AI.
Praktik Terbaik untuk Integrasi API Llama 4
Untuk memastikan integrasi yang kuat, ikuti panduan ini:
- Pembatasan Tarif: Hormati batas penyedia (misalnya, 100 permintaan/menit Groq). Terapkan backoff eksponensial untuk percobaan ulang.
- Penanganan Kesalahan: Tangkap kesalahan HTTP (misalnya, 429 Terlalu Banyak Permintaan) dan catat.
- Keamanan: Enkripsi kunci API dan gunakan endpoint HTTPS.
- Pemantauan: Lacak penggunaan token untuk mengelola biaya, terutama dengan tarif Maverick yang lebih tinggi.
Memecahkan Masalah API Umum
Menemui masalah? Atasi dengan cepat:
- 401 Tidak Sah: Verifikasi kunci API Anda.
- 429 Batas Tarif Terlampaui: Kurangi frekuensi permintaan atau tingkatkan paket Anda.
- Kesalahan Payload: Pastikan format JSON sesuai dengan spesifikasi penyedia (misalnya, larik
messages).
Apidog membantu mendiagnosis masalah ini secara visual, menghemat waktu.
Kesimpulan
Mengintegrasikan Llama 4 Maverick dan Llama 4 Scout melalui API memberdayakan pengembang untuk membangun aplikasi mutakhir dengan overhead minimal. Apakah Anda memerlukan efisiensi konteks panjang Scout atau kehebatan multibahasa Maverick, model-model ini memberikan kinerja tingkat atas melalui endpoint yang dapat diakses. Dengan mengikuti panduan ini, Anda dapat mengatur, mengoptimalkan, dan memecahkan masalah panggilan API Anda secara efektif.
Siap untuk menyelami lebih dalam? Bereksperimenlah dengan penyedia seperti Groq dan Together AI, dan manfaatkan Apidog untuk menyempurnakan alur kerja Anda. Masa depan AI multimodal ada di sini—mulai membangun hari ini!