
Ingin mengobrol dengan 100+ model bahasa besar (LLM) seolah-olah semuanya adalah API OpenAI? Baik Anda sedang membangun chatbot, mengotomatiskan tugas, atau sekadar iseng, LiteLLM adalah tiket Anda untuk memanggil LLM dari OpenAI, Anthropic, Ollama, dan banyak lagi, semuanya menggunakan format gaya OpenAI yang sama. Saya mendalami LiteLLM untuk menyederhanakan panggilan API saya, dan izinkan saya memberi tahu Anda—ini adalah penyelamat untuk menjaga kode tetap bersih dan fleksibel. Dalam panduan pemula ini, saya akan menunjukkan cara menyiapkan LiteLLM, memanggil model Ollama lokal dan GPT-4o OpenAI, dan bahkan melakukan streaming respons, semuanya berdasarkan dokumen resmi. Siap membuat proyek AI Anda lebih mulus dari sore yang cerah? Mari kita mulai!
Apa itu LiteLLM? Kekuatan Super API LLM Anda
LiteLLM adalah pustaka Python sumber terbuka dan server proxy yang memungkinkan Anda memanggil lebih dari 100 API LLM—seperti OpenAI, Anthropic, Azure, Hugging Face, dan model lokal melalui Ollama—menggunakan format OpenAI Chat Completions. Ini menstandardisasi input dan output, menangani kunci API, dan menambahkan fitur tambahan seperti streaming, fallback, dan pelacakan biaya, sehingga Anda tidak perlu menulis ulang kode untuk setiap penyedia. Dengan lebih dari 22,7 ribu bintang GitHub dan adopsi oleh perusahaan seperti Adobe dan Lemonade, LiteLLM adalah favorit pengembang. Baik Anda mendokumentasikan API (seperti dengan MkDocs) atau membangun aplikasi AI, LiteLLM menyederhanakan alur kerja Anda. Mari kita siapkan dan lihat aksinya!
Menyiapkan Lingkungan Anda untuk LiteLLM
Sebelum kita memanggil LLM dengan LiteLLM, mari kita siapkan sistem Anda. Ini ramah bagi pemula, dengan setiap langkah dijelaskan untuk menjaga Anda tetap pada jalurnya.
1. Periksa Prasyarat: Anda akan memerlukan alat-alat ini:
- Python: Versi 3.8 atau lebih tinggi. Jalankan
python --versiondi terminal Anda. Jika tidak ada atau terlalu lama, ambil dari python.org. Python menjalankan skrip LiteLLM. - pip: Manajer paket Python, disertakan dengan Python 3.4+. Verifikasi dengan
pip --version. Jika tidak ada, unduhget-pip.pydan jalankanpython get-pip.py. - Ollama: Untuk model lokal. Unduh dari ollama.com dan verifikasi dengan
ollama --version(misalnya, 0.1.44). Kita akan menggunakannya untuk uji LLM lokal.
Ada yang hilang? Instal sekarang untuk menjaga semuanya berjalan lancar.
2. Buat Folder Proyek: Mari tetap terorganisir:
mkdir litellm-api-test
cd litellm-api-test
Folder ini akan menampung proyek LiteLLM Anda, dan cd membuat Anda siap.
3. Siapkan Lingkungan Virtual: Hindari konflik paket dengan lingkungan virtual Python:
python -m venv venv
Aktifkan:
- Mac/Linux:
source venv/bin/activate - Windows:
venv\Scripts\activate
Melihat (venv) di terminal Anda berarti Anda berada di lingkungan yang bersih, mengisolasi dependensi LiteLLM.
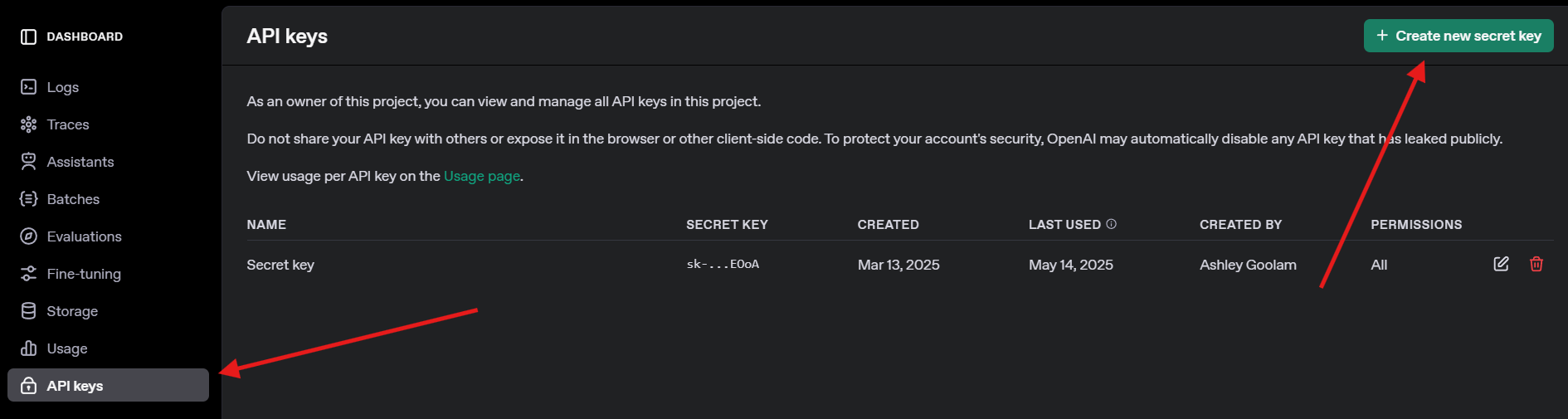
4. Dapatkan Kunci API OpenAI: Untuk uji GPT-4o, daftar di openai.com, navigasikan ke kunci API, dan buat kunci. Simpan dengan aman—Anda akan membutuhkannya nanti.
Menginstal LiteLLM dan Ollama
Sekarang, mari kita instal LiteLLM dan siapkan Ollama untuk model lokal. Ini cepat dan menyiapkan panggung untuk panggilan API kita.
1. Instal LiteLLM: Di lingkungan virtual yang diaktifkan, jalankan:
pip install litellm openai
Ini menginstal LiteLLM dan OpenAI SDK (diperlukan untuk kompatibilitas). Ini menarik dependensi seperti pydantic dan httpx.
2. Verifikasi LiteLLM: Periksa instalasi:
python -c "import litellm; print(litellm.__version__)"
Harapkan versi seperti 1.40.14 atau yang lebih baru. Jika gagal, perbarui pip (pip install --upgrade pip).
3. Siapkan Ollama: Pastikan Ollama berjalan dan tarik model ringan seperti Llama 3 (8B):
ollama pull llama3
Ini mengunduh ~4,7GB, jadi ambil camilan jika koneksi Anda lambat. Verifikasi dengan ollama list untuk melihat llama3:latest. Ollama menghosting model lokal untuk dipanggil oleh LiteLLM.
Memanggil LLM dengan LiteLLM: Contoh OpenAI dan Ollama
Mari kita ke bagian yang menyenangkan—memanggil LLM! Kita akan membuat skrip Python untuk memanggil GPT-4o OpenAI dan model Llama 3 lokal melalui Ollama, keduanya menggunakan format yang kompatibel dengan OpenAI dari LiteLLM. Kita juga akan mencoba streaming untuk respons real-time.
1. Buat Skrip Uji: Di folder litellm-api-test Anda, buat test_llm.py dengan kode ini:
from litellm import completion
import os
# Set environment variables
os.environ["OPENAI_API_KEY"] = "your-openai-api-key" # Replace with your key
os.environ["OLLAMA_API_BASE"] = "http://localhost:11434" # Default Ollama endpoint
# Messages for the LLM
messages = [{"content": "Write a short poem about the moon", "role": "user"}]
# Call OpenAI GPT-4o
print("Calling GPT-4o...")
gpt_response = completion(
model="openai/gpt-4o",
messages=messages,
max_tokens=50
)
print("GPT-4o Response:", gpt_response.choices[0].message.content)
# Call Ollama Llama 3
print("\nCalling Ollama Llama 3...")
ollama_response = completion(
model="ollama/llama3",
messages=messages,
max_tokens=50,
api_base="http://localhost:11434"
)
print("Llama 3 Response:", ollama_response.choices[0].message.content)
# Stream Ollama Llama 3 response
print("\nStreaming Ollama Llama 3...")
stream_response = completion(
model="ollama/llama3",
messages=messages,
stream=True,
api_base="http://localhost:11434"
)
print("Streamed Llama 3 Response:")
for chunk in stream_response:
if chunk.choices[0].delta.content:
print(chunk.choices[0].delta.content, end="", flush=True)
print() # Newline after streaming
Skrip ini:
- Menyiapkan kunci API dan endpoint Ollama.
- Mendefinisikan prompt ("Tulis puisi pendek tentang bulan").
- Memanggil GPT-4o dan Llama 3 dengan fungsi
completiondari LiteLLM. - Melakukan streaming respons Llama 3 untuk output real-time.
2. Ganti Kunci API: Perbarui os.environ["OPENAI_API_KEY"] dengan kunci OpenAI Anda yang sebenarnya. Jika Anda tidak memilikinya, lewati panggilan GPT-4o dan fokus pada Ollama.
3. Pastikan Ollama Berjalan: Mulai Ollama di terminal terpisah:
ollama serve
Ini menjalankan Ollama di http://localhost:11434. Biarkan terbuka untuk panggilan Llama 3.
4. Jalankan Skrip: Di lingkungan virtual Anda, jalankan:
python test_llm.py
- Ketika saya menjalankan ini, GPT-4o mengembalikan puisi yang rapi seperti:
>> The moon’s soft glow, a silver dream, lights paths where quiet shadows gleam.
- Llama 3 memberikan versi yang lebih sederhana namun menawan, seperti:
>> Moon so bright in the night sky, glowing soft as clouds float by.
Respons yang di-stream dicetak kata demi kata, terasa seperti LLM sedang mengetik secara langsung. Jika gagal, periksa apakah Ollama berjalan, kunci OpenAI Anda valid, atau port 11434 terbuka. Log debug ada di ~/.litellm/logs.
Menambahkan Observabilitas dengan LiteLLM Callbacks
Ingin melacak panggilan LLM Anda seperti seorang profesional? LiteLLM mendukung callback untuk mencatat input, output, dan biaya ke alat seperti Langfuse atau MLflow. Mari kita tambahkan callback sederhana untuk mencatat biaya.
Perbarui Skrip: Modifikasi test_llm.py untuk menyertakan callback pelacakan biaya:
from litellm import completion
import os
# Callback function to track cost
def track_cost_callback(kwargs, completion_response, start_time, end_time):
cost = kwargs.get("response_cost", 0)
print(f"Response cost: ${cost:.4f}")
# Set callback
import litellm
litellm.success_callback = [track_cost_callback]
# Rest of the script (same as above)
os.environ["OPENAI_API_KEY"] = "your-openai-api-key"
os.environ["OLLAMA_API_BASE"] = "http://localhost:11434"
messages = [{"role": "user", "content": "Write a short poem about the moon"}]
print("Calling GPT-4o...")
gpt_response = completion(model="openai/gpt-4o", messages=messages, max_tokens=50)
print("GPT-4o Response:", gpt_response.choices[0].message.content)
# ... (Ollama and streaming calls unchanged)
Ini mencatat biaya setiap panggilan (misalnya, "Response cost: $0.0025" untuk GPT-4o). Panggilan Ollama gratis, jadi biayanya $0.
Jalankan Lagi: Jalankan python test_llm.py. Anda akan melihat log biaya di samping respons, membantu Anda memantau pengeluaran untuk LLM berbasis cloud.
Mendokumentasikan API Anda dengan APIdog
Karena Anda bekerja dengan API LLM, Anda mungkin ingin mendokumentasikannya dengan jelas untuk tim atau pengguna Anda. Saya sangat menyarankan Anda memeriksa APIdog. Dokumentasi APIdog adalah alat yang fantastis untuk ini! Ini menawarkan platform yang ramping dan interaktif untuk merancang, menguji, dan mendokumentasikan API, dengan fitur-fitur seperti API playground dan opsi self-hosting. Memasangkan panggilan API LiteLLM dengan dokumen APIdog yang rapi dapat membawa proyek Anda ke tingkat berikutnya—cobalah!
Pandangan Saya tentang LiteLLM
Setelah bermain dengan LiteLLM, inilah yang saya sukai:
- Format Terpadu: Satu struktur kode untuk OpenAI, Ollama, dan lainnya—tidak ada lagi sakit kepala khusus API.
- Kekuatan Lokal: Integrasi Ollama memungkinkan Anda menjalankan model secara offline, sempurna untuk privasi atau proyek beranggaran rendah.
- Keseruan Streaming: Respons real-time membuat aplikasi terasa hidup, seperti mengobrol dengan teman.
- Komunitas yang Aktif: Dengan lebih dari 18 ribu bintang GitHub, LiteLLM adalah favorit pengembang.
Tantangan? Pengaturan bisa jadi rumit jika Ollama atau kunci API tidak dikonfigurasi dengan benar, tetapi dokumennya solid.
Tips Pro untuk Sukses dengan LiteLLM
- Debugging: Aktifkan logging verbose dengan
litellm.set_verbose = Trueuntuk melihat permintaan dan respons mentah. - Model Lain: Coba Claude dari Anthropic atau Azure OpenAI dengan menambahkan kunci API dan model mereka (misalnya,
anthropic/claude-3-sonnet-20240229). - Panggilan Asinkron: Gunakan
litellm.acompletionuntuk panggilan non-blocking di aplikasi FastAPI. - Server Proxy: Jalankan LiteLLM sebagai proxy (
litellm --model gpt-3.5-turbo) agar beberapa aplikasi dapat berbagi satu endpoint. - Komunitas: Bergabunglah dengan Discord atau GitHub Discussions LiteLLM untuk tips dan pembaruan.
Penutup: Perjalanan LiteLLM Anda Dimulai Di Sini
Anda baru saja membuka kekuatan LiteLLM untuk memanggil LLM seperti seorang profesional, dari GPT-4o OpenAI hingga Llama 3 lokal, semuanya dalam satu format yang bersih! Baik Anda sedang membangun aplikasi AI atau bereksperimen seperti coder yang penasaran, LiteLLM memudahkan untuk mengganti model, melakukan streaming respons, dan melacak biaya. Coba prompt baru, tambahkan lebih banyak penyedia, atau siapkan server proxy untuk proyek yang lebih besar. Bagikan kemenangan LiteLLM Anda di GitHub LiteLLM—saya sangat antusias melihat apa yang Anda buat! Dan jangan lupa untuk memeriksa APIdog untuk mendokumentasikan API Anda. Selamat coding!