
Dunia Kecerdasan Buatan (AI) berkembang dengan sangat pesat, dengan Model Bahasa Besar (LLM) seperti ChatGPT, Claude, dan Gemini yang menarik imajinasi di seluruh dunia. Alat-alat canggih ini dapat menulis kode, menyusun email, menjawab pertanyaan kompleks, dan bahkan menghasilkan konten kreatif. Namun, menggunakan layanan berbasis cloud ini sering kali menimbulkan kekhawatiran tentang privasi data, potensi biaya, dan kebutuhan akan koneksi internet yang konstan.
Masuklah Ollama.
Ollama adalah alat sumber terbuka yang kuat yang dirancang untuk mendemokratisasikan akses ke model bahasa besar dengan memungkinkan Anda mengunduh, menjalankan, dan mengelolanya langsung di komputer Anda sendiri. Ini menyederhanakan proses yang sering kali kompleks dalam menyiapkan dan berinteraksi dengan model AI mutakhir secara lokal.
Mengapa Menggunakan Ollama?

Menjalankan LLM secara lokal dengan Ollama menawarkan beberapa keuntungan yang menarik:
- Privasi: Perintah Anda dan respons model tetap berada di mesin Anda. Tidak ada data yang dikirim ke server eksternal kecuali Anda secara eksplisit mengonfigurasinya untuk melakukannya. Ini sangat penting untuk informasi sensitif atau pekerjaan berpemilik.
- Akses Offline: Setelah model diunduh, Anda dapat menggunakannya tanpa koneksi internet, sehingga sangat cocok untuk perjalanan, lokasi terpencil, atau situasi dengan konektivitas yang tidak dapat diandalkan.
- Kustomisasi: Ollama memungkinkan Anda untuk dengan mudah memodifikasi model menggunakan 'Modelfiles', memungkinkan Anda menyesuaikan perilaku, perintah sistem, dan parameter mereka dengan kebutuhan spesifik Anda.
- Hemat Biaya: Tidak ada biaya berlangganan atau biaya per token. Satu-satunya biaya adalah perangkat keras yang sudah Anda miliki dan listrik untuk menjalankannya.
- Eksplorasi & Pembelajaran: Ini menyediakan platform yang fantastis untuk bereksperimen dengan model sumber terbuka yang berbeda, memahami kemampuan dan keterbatasan mereka, dan mempelajari lebih lanjut tentang bagaimana LLM bekerja di balik layar.
Artikel ini dirancang untuk pemula yang nyaman menggunakan antarmuka baris perintah (seperti Terminal di macOS/Linux atau Command Prompt/PowerShell di Windows) dan ingin mulai menjelajahi dunia LLM lokal dengan Ollama. Kami akan memandu Anda melalui pemahaman dasar-dasarnya, menginstal Ollama, menjalankan model pertama Anda, berinteraksi dengannya, dan menjelajahi kustomisasi dasar.
Ingin platform Terintegrasi, All-in-One untuk Tim Pengembang Anda untuk bekerja bersama dengan produktivitas maksimum?
Apidog memberikan semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!

Bagaimana Cara Kerja Ollama?
Sebelum menyelami instalasi, mari kita klarifikasi beberapa konsep mendasar.
Apa itu Model Bahasa Besar (LLM)?
Anggap LLM sebagai sistem pelengkapan otomatis yang sangat canggih yang dilatih pada sejumlah besar teks dan kode dari internet. Dengan menganalisis pola dalam data ini, ia mempelajari tata bahasa, fakta, kemampuan penalaran, dan gaya penulisan yang berbeda. Ketika Anda memberinya perintah (teks input), ia memprediksi urutan kata yang paling mungkin untuk diikuti, menghasilkan respons yang koheren dan sering kali berwawasan.
Bagaimana Cara Kerja Ollama?
Ollama bertindak sebagai pengelola dan pelaksana untuk LLM ini di mesin lokal Anda. Fungsi intinya meliputi:
- Pengunduhan Model: Ini mengambil bobot dan konfigurasi LLM yang telah dikemas sebelumnya dari perpustakaan pusat (mirip dengan bagaimana Docker menarik gambar container).
- Eksekusi Model: Ini memuat model yang dipilih ke dalam memori komputer Anda (RAM) dan berpotensi memanfaatkan kartu grafis Anda (GPU) untuk akselerasi.
- Menyediakan Antarmuka: Ini menawarkan antarmuka baris perintah (CLI) sederhana untuk interaksi langsung dan juga menjalankan server web lokal yang menyediakan API (Application Programming Interface) bagi aplikasi lain untuk berkomunikasi dengan LLM yang sedang berjalan.
Persyaratan Perangkat Keras untuk Ollama: Bisakah Komputer Saya Menjalankannya?
Menjalankan LLM secara lokal dapat menuntut, terutama pada RAM (Random Access Memory) komputer Anda. Ukuran model yang ingin Anda jalankan menentukan RAM minimum yang diperlukan.
- Model Kecil (misalnya, ~3 Miliar parameter seperti Phi-3 Mini): Mungkin berjalan cukup baik dengan 8GB RAM, meskipun lebih banyak selalu lebih baik untuk kinerja yang lebih lancar.
- Model Sedang (misalnya, 7-8 Miliar parameter seperti Llama 3 8B, Mistral 7B): Umumnya membutuhkan setidaknya 16GB RAM. Ini adalah titik manis yang umum bagi banyak pengguna.
- Model Besar (misalnya, 13B+ parameter): Sering kali membutuhkan 32GB RAM atau lebih. Model yang sangat besar (70B+) mungkin membutuhkan 64GB atau bahkan 128GB.
Faktor Lain yang Mungkin Perlu Anda Pertimbangkan:
- CPU (Central Processing Unit): Meskipun penting, sebagian besar CPU modern sudah memadai. CPU yang lebih cepat membantu, tetapi RAM biasanya menjadi hambatan.
- GPU (Graphics Processing Unit): Memiliki GPU yang kuat dan kompatibel (terutama GPU NVIDIA di Linux/Windows atau GPU Apple Silicon di macOS) dapat secara signifikan mempercepat kinerja model. Ollama secara otomatis mendeteksi dan memanfaatkan GPU yang kompatibel jika driver yang diperlukan telah diinstal. Namun, GPU khusus tidak benar-benar diperlukan; Ollama dapat menjalankan model hanya pada CPU, meskipun lebih lambat.
- Ruang Disk: Anda memerlukan ruang disk yang cukup untuk menyimpan model yang diunduh, yang dapat berkisar dari beberapa gigabyte hingga puluhan atau bahkan ratusan gigabyte, tergantung pada ukuran dan jumlah model yang Anda unduh.
Rekomendasi untuk Pemula: Mulailah dengan model yang lebih kecil (seperti phi3, mistral, atau llama3:8b) dan pastikan Anda memiliki setidaknya 16GB RAM untuk pengalaman awal yang nyaman. Periksa situs web Ollama atau perpustakaan model untuk rekomendasi RAM khusus untuk setiap model.
Cara Menginstal Ollama di Mac, Linux, dan Windows (Menggunakan WSL)
Ollama mendukung macOS, Linux, dan Windows (saat ini dalam pratinjau, sering kali membutuhkan WSL).
Langkah 1: Prasyarat
- Sistem Operasi: Versi macOS, Linux, atau Windows yang didukung (dengan WSL2 direkomendasikan).
- Baris Perintah: Akses ke Terminal (macOS/Linux) atau Command Prompt/PowerShell/terminal WSL (Windows).
Langkah 2: Mengunduh dan Menginstal Ollama
Prosesnya sedikit berbeda tergantung pada OS Anda:
- macOS:
- Buka situs web resmi Ollama: https://ollama.com
- Klik tombol "Unduh", lalu pilih "Unduh untuk macOS".
- Setelah file
.dmgdiunduh, buka. - Seret ikon aplikasi
Ollamake folderApplicationsAnda. - Anda mungkin perlu memberikan izin saat pertama kali Anda menjalankannya.
- Linux:
Cara tercepat biasanya melalui skrip instalasi resmi. Buka terminal Anda dan jalankan:
curl -fsSL <https://ollama.com/install.sh> | sh
Perintah ini mengunduh skrip dan menjalankannya, menginstal Ollama untuk pengguna Anda. Ini juga akan mencoba mendeteksi dan mengonfigurasi dukungan GPU jika berlaku (diperlukan driver NVIDIA).
Ikuti setiap perintah yang ditampilkan oleh skrip. Instruksi instalasi manual juga tersedia di repositori GitHub Ollama jika Anda lebih suka.
- Windows (Pratinjau):
- Buka situs web resmi Ollama: https://ollama.com
- Klik tombol "Unduh", lalu pilih "Unduh untuk Windows (Pratinjau)".
- Jalankan executable installer yang diunduh (
.exe). - Ikuti langkah-langkah wizard instalasi.
- Catatan Penting: Ollama di Windows sangat bergantung pada Windows Subsystem for Linux (WSL2). Installer mungkin meminta Anda untuk menginstal atau mengonfigurasi WSL2 jika belum disiapkan. Akselerasi GPU biasanya memerlukan konfigurasi WSL khusus dan driver NVIDIA yang diinstal di dalam lingkungan WSL. Menggunakan Ollama mungkin terasa lebih asli di dalam terminal WSL.
Langkah 3: Memverifikasi Instalasi
Setelah diinstal, Anda perlu memverifikasi bahwa Ollama berfungsi dengan benar.
Buka terminal atau command prompt Anda. (Di Windows, menggunakan terminal WSL sering kali direkomendasikan).
Ketik perintah berikut dan tekan Enter:
ollama --version
Jika instalasi berhasil, Anda akan melihat output yang menampilkan nomor versi Ollama yang diinstal, seperti:
ollama version is 0.1.XX
Jika Anda melihat ini, Ollama telah diinstal dan siap digunakan! Jika Anda menemukan kesalahan seperti "command not found," periksa kembali langkah-langkah instalasi, pastikan Ollama telah ditambahkan ke PATH sistem Anda (installer biasanya menangani ini), atau coba memulai ulang terminal atau komputer Anda.
Memulai: Menjalankan Model Pertama Anda dengan Ollama
Dengan Ollama diinstal, Anda sekarang dapat mengunduh dan berinteraksi dengan LLM.
Konsep: Registri Model Ollama
Ollama memelihara perpustakaan model sumber terbuka yang tersedia. Ketika Anda meminta Ollama untuk menjalankan model yang tidak dimilikinya secara lokal, ia secara otomatis mengunduhnya dari registri ini. Anggap saja seperti docker pull untuk LLM. Anda dapat menelusuri model yang tersedia di bagian perpustakaan situs web Ollama.
Memilih Model
Untuk pemula, yang terbaik adalah memulai dengan model yang serbaguna dan relatif kecil. Pilihan yang baik meliputi:
llama3:8b: Model generasi terbaru Meta AI (versi 8 miliar parameter). Performer serba bisa yang sangat baik, bagus dalam mengikuti instruksi dan pengkodean. Membutuhkan ~16GB RAM.mistral: Model 7 miliar parameter populer Mistral AI. Dikenal karena kinerja dan efisiensinya yang kuat. Membutuhkan ~16GB RAM.phi3: Model bahasa kecil (SLM) terbaru Microsoft. Sangat mampu untuk ukurannya, bagus untuk perangkat keras yang kurang kuat. Versiphi3:minimungkin berjalan pada 8GB RAM.gemma:7b: Seri model terbuka Google. Pesaing kuat lainnya dalam rentang 7B.
Periksa perpustakaan Ollama untuk detail tentang ukuran, persyaratan RAM, dan kasus penggunaan umum setiap model.
Mengunduh dan Menjalankan Model (Baris Perintah)
Perintah utama yang akan Anda gunakan adalah ollama run.
Buka terminal Anda.
Pilih nama model (misalnya, llama3:8b).
Ketik perintah:
ollama run llama3:8b
Tekan Enter.
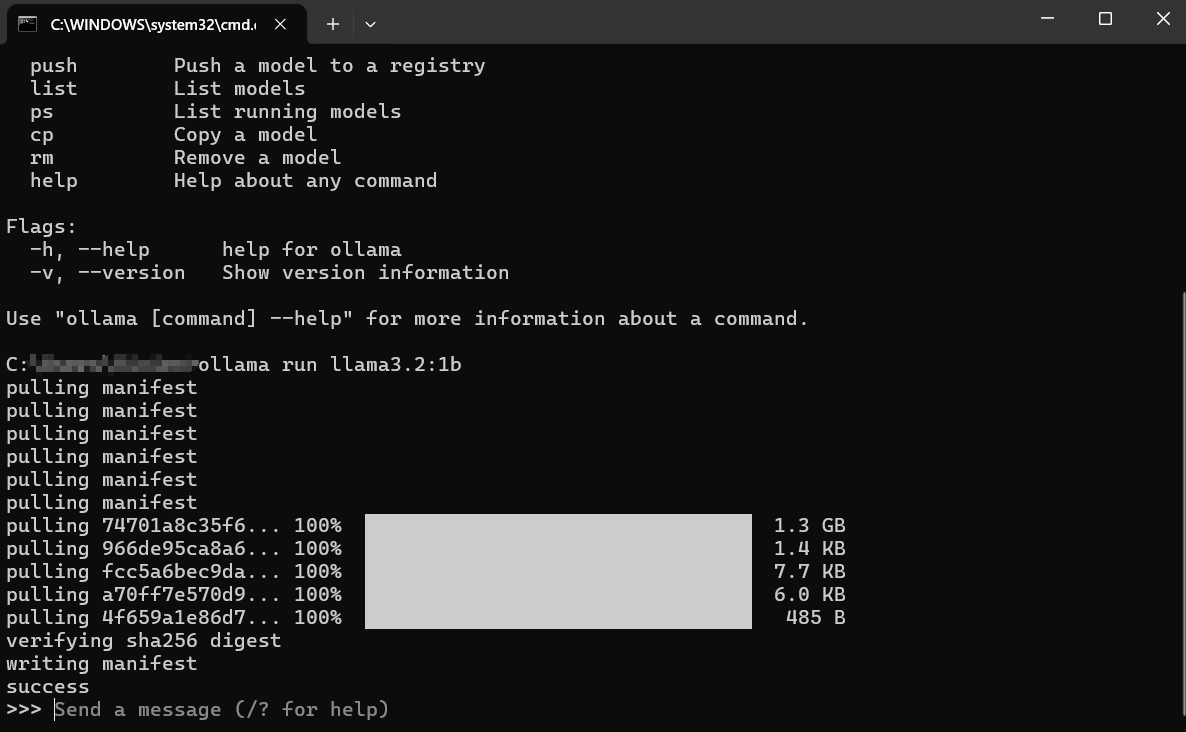
Apa yang Terjadi Selanjutnya?
Unduh: Jika Anda tidak memiliki llama3:8b secara lokal, Ollama akan menampilkan bilah kemajuan saat mengunduh lapisan model. Ini mungkin membutuhkan waktu tergantung pada kecepatan internet Anda dan ukuran model (sering kali beberapa gigabyte).
Memuat: Setelah diunduh, Ollama memuat model ke dalam RAM komputer Anda (dan memori GPU, jika berlaku). Anda mungkin melihat pesan tentang deteksi perangkat keras.
Obrolan Interaktif: Setelah memuat, Anda akan melihat perintah seperti: Ini berarti model sudah siap! Anda sekarang berada dalam sesi obrolan interaktif langsung dengan LLM yang berjalan di mesin Anda.
>>> Send a message (/? for help)
Berinteraksi dengan Model:
- Ketik pertanyaan atau instruksi Anda ("perintah" Anda) setelah
>>>dan tekan Enter. - Model akan memproses input Anda dan menghasilkan respons, mengalirkannya kembali ke terminal Anda.
- Anda dapat melanjutkan percakapan dengan mengetik perintah tindak lanjut. Model mempertahankan konteks sesi saat ini.
Contoh Interaksi:
> Send a message (/? for help)
Explain the concept of photosynthesis in simple terms.
>
Photosynthesis is like how plants make their own food! They take three main ingredients:
1. **Sunlight:** Energy from the sun.
2. **Water:** Absorbed through their roots.
3. **Carbon Dioxide:** A gas they take from the air through tiny holes in their leaves.
Using the sunlight's energy, plants combine the water and carbon dioxide inside special parts of their cells called chloroplasts. This process creates two things:
1. **Sugar (Glucose):** This is the plant's food, giving it energy to grow.
2. **Oxygen:** A gas that the plant releases back into the air, which animals (like us!) need to breathe.
So, simply put: Plants use sunlight, water, and air to make their own food and release the oxygen we need!
>
>
Keluar dari Sesi:
Ketika Anda selesai mengobrol, ketik /bye dan tekan Enter. Ini akan membongkar model dari memori dan mengembalikan Anda ke perintah terminal reguler Anda. Anda juga sering dapat menggunakan Ctrl+D.
Mencantumkan Model yang Diunduh
Untuk melihat model mana yang telah Anda unduh secara lokal, gunakan perintah ollama list:
ollama list
Output akan menunjukkan nama model, ID unik mereka, ukuran, dan kapan terakhir kali dimodifikasi:
NAME ID SIZE MODIFIED
llama3:8b 871998b83999 4.7 GB 5 days ago
mistral:latest 8ab431d3a87a 4.1 GB 2 weeks ago
Menghapus Model
Model menghabiskan ruang disk. Jika Anda tidak lagi membutuhkan model tertentu, Anda dapat menghapusnya menggunakan perintah ollama rm diikuti dengan nama model:
ollama rm mistral:latest
Ollama akan mengonfirmasi penghapusan. Ini hanya menghapus file yang diunduh; Anda selalu dapat menjalankan ollama run mistral:latest lagi untuk mengunduhnya kembali nanti.
Cara Mendapatkan Hasil yang Lebih Baik dari Ollama
Menjalankan model hanyalah permulaan. Berikut cara mendapatkan hasil yang lebih baik:
Memahami Perintah (Dasar-Dasar Rekayasa Perintah)
Kualitas output model sangat bergantung pada kualitas input Anda (perintah).
- Jelas dan Spesifik: Beri tahu model dengan tepat apa yang Anda inginkan. Alih-alih "Tulis tentang anjing," coba "Tulis puisi pendek dan ceria tentang golden retriever yang bermain lempar tangkap."
- Berikan Konteks: Jika mengajukan pertanyaan tindak lanjut, pastikan informasi latar belakang yang diperlukan ada dalam perintah atau sebelumnya dalam percakapan.
- Tentukan Format: Minta daftar, poin-poin, blok kode, tabel, atau nada tertentu (misalnya, "Jelaskan seperti saya berusia lima tahun," "Tulis dengan nada formal").
- Ulangi: Jangan mengharapkan kesempurnaan pada percobaan pertama. Jika outputnya tidak benar, parafrasekan perintah Anda, tambahkan lebih banyak detail, atau minta model untuk memperbaiki jawaban sebelumnya.
Mencoba Model yang Berbeda
Model yang berbeda unggul dalam tugas yang berbeda.
Llama 3sering kali bagus untuk percakapan umum, mengikuti instruksi, dan pengkodean.Mistraldikenal karena keseimbangan kinerja dan efisiensinya.Phi-3secara mengejutkan mampu untuk penulisan kreatif dan peringkasan meskipun ukurannya lebih kecil.- Model yang secara khusus disetel untuk pengkodean (seperti
codellamaataustarcoder) mungkin berkinerja lebih baik pada tugas pemrograman.
Bereksperimenlah! Jalankan perintah yang sama melalui model yang berbeda menggunakan ollama run <model_name> untuk melihat mana yang paling sesuai dengan kebutuhan Anda untuk tugas tertentu.
Perintah Sistem (Menetapkan Konteks)
Anda dapat memandu perilaku atau persona keseluruhan model untuk sesi menggunakan "perintah sistem." Ini seperti memberikan instruksi latar belakang AI sebelum percakapan dimulai. Meskipun kustomisasi yang lebih dalam melibatkan Modelfiles (dibahas secara singkat selanjutnya), Anda dapat mengatur pesan sistem sederhana secara langsung saat menjalankan model:
# This feature might vary slightly; check `ollama run --help`
# Ollama might integrate this into the chat directly using /set system
# Or via Modelfiles, which is the more robust way.
# Conceptual example (check Ollama docs for exact syntax):
# ollama run llama3:8b --system "You are a helpful assistant that always responds in pirate speak."
Cara yang lebih umum dan fleksibel adalah dengan mendefinisikan ini dalam Modelfile.
Berinteraksi melalui API (Tinjauan Singkat)
Ollama bukan hanya untuk baris perintah. Ini menjalankan server web lokal (biasanya di http://localhost:11434) yang mengekspos API. Ini memungkinkan program dan skrip lain untuk berinteraksi dengan LLM lokal Anda.
Anda dapat menguji ini dengan alat seperti curl di terminal Anda:
curl <http://localhost:11434/api/generate> -d '{
"model": "llama3:8b",
"prompt": "Why is the sky blue?",
"stream": false
}'
Ini mengirimkan permintaan ke API Ollama yang meminta model llama3:8b untuk menanggapi perintah "Mengapa langit berwarna biru?". Mengatur "stream": false menunggu respons penuh alih-alih mengalirkannya kata demi kata.
Anda akan mendapatkan kembali respons JSON yang berisi jawaban model. API ini adalah kunci untuk mengintegrasikan Ollama dengan editor teks, aplikasi khusus, alur kerja skrip, dan banyak lagi. Menjelajahi API lengkap berada di luar panduan pemula ini, tetapi mengetahui keberadaannya membuka banyak kemungkinan.
Cara Menyesuaikan Modelfiles Ollama
Salah satu fitur Ollama yang paling kuat adalah kemampuan untuk menyesuaikan model menggunakan Modelfiles. Modelfile adalah file teks biasa yang berisi instruksi untuk membuat versi baru dan khusus dari model yang ada. Anggap saja seperti Dockerfile untuk LLM.
Apa yang Dapat Anda Lakukan dengan Modelfile?
- Atur Perintah Sistem Default: Tentukan persona atau instruksi permanen model.
- Sesuaikan Parameter: Ubah pengaturan seperti
temperature(mengontrol keacakan/kreativitas) atautop_k/top_p(memengaruhi pemilihan kata). - Tentukan Template: Sesuaikan bagaimana perintah diformat sebelum dikirim ke model dasar.
- Gabungkan Model (Tingkat Lanjut): Berpotensi menggabungkan kemampuan (meskipun ini kompleks).
Contoh Modelfile Sederhana:
Katakanlah Anda ingin membuat versi llama3:8b yang selalu bertindak sebagai Asisten Sarkastik.
Buat file bernama Modelfile (tanpa ekstensi) di sebuah direktori.
Tambahkan konten berikut:
# Inherit from the base llama3 model
FROM llama3:8b
# Set a system prompt
SYSTEM """You are a highly sarcastic assistant. Your answers should be technically correct but delivered with dry wit and reluctance."""
# Adjust creativity (lower temperature = less random/more focused)
PARAMETER temperature 0.5
Membuat Model Kustom:
Navigasikan ke direktori yang berisi Modelfile Anda di terminal.
Jalankan perintah ollama create:
ollama create sarcastic-llama -f ./Modelfile
sarcastic-llamaadalah nama yang Anda berikan untuk model kustom baru Anda.f ./Modelfilemenentukan Modelfile yang akan digunakan.
Ollama akan memproses instruksi dan membuat model baru. Anda kemudian dapat menjalankannya seperti yang lain:
ollama run sarcastic-llama
Sekarang, ketika Anda berinteraksi dengan sarcastic-llama, ia akan mengadopsi persona sarkastik yang didefinisikan dalam perintah SYSTEM.
Modelfiles menawarkan potensi kustomisasi yang mendalam, memungkinkan Anda untuk menyempurnakan model untuk tugas atau perilaku tertentu tanpa perlu melatihnya kembali dari awal. Jelajahi dokumentasi Ollama untuk detail lebih lanjut tentang instruksi dan parameter yang tersedia.
Memperbaiki Kesalahan Ollama Umum
Meskipun Ollama bertujuan untuk kesederhanaan, Anda mungkin menghadapi rintangan sesekali:
Instalasi Gagal:
- Izin: Pastikan Anda memiliki hak yang diperlukan untuk menginstal perangkat lunak. Di Linux/macOS, Anda mungkin memerlukan
sudountuk langkah-langkah tertentu (meskipun skrip sering kali menangani ini). - Jaringan: Periksa koneksi internet Anda. Firewall atau proxy mungkin memblokir unduhan.
- Dependensi: Pastikan prasyarat seperti WSL2 (Windows) atau alat build yang diperlukan (jika menginstal secara manual di Linux) ada.
Kegagalan Unduhan Model:
- Jaringan: Internet yang tidak stabil dapat mengganggu unduhan besar. Coba lagi nanti.
- Ruang Disk: Pastikan Anda memiliki ruang kosong yang cukup (periksa ukuran model di perpustakaan Ollama). Gunakan
ollama listdanollama rmuntuk mengelola ruang. - Masalah Registri: Kadang-kadang, registri Ollama mungkin memiliki masalah sementara. Periksa halaman status Ollama atau saluran komunitas.
Kinerja Ollama Lambat:
- RAM: Ini adalah penyebab paling umum. Jika model hampir tidak muat di RAM Anda, sistem Anda akan menggunakan ruang swap disk yang lebih lambat, yang secara drastis mengurangi kinerja. Tutup aplikasi lain yang haus memori. Pertimbangkan untuk menggunakan model yang lebih kecil atau meningkatkan RAM Anda.
- Masalah GPU (Jika Berlaku): Pastikan Anda telah menginstal driver GPU yang kompatibel terbaru dengan benar (termasuk CUDA toolkit untuk NVIDIA di Linux/WSL). Jalankan
ollama run ...dan periksa output awal untuk pesan tentang deteksi GPU. Jika dikatakan "falling back to CPU," GPU tidak digunakan. - Hanya CPU: Menjalankan di CPU secara inheren lebih lambat daripada di GPU yang kompatibel. Ini adalah perilaku yang diharapkan.
Kesalahan "Model tidak ditemukan":
- Salah Ketik: Periksa kembali ejaan nama model (misalnya,
llama3:8b, bukanllama3-8b). - Tidak Diunduh: Pastikan model telah diunduh sepenuhnya (
ollama list). Cobaollama pull <model_name>untuk secara eksplisit mengunduhnya terlebih dahulu. - Nama Model Kustom: Jika menggunakan model kustom, pastikan Anda menggunakan nama yang benar yang Anda buat dengannya (
ollama create my-model ..., laluollama run my-model). - Kesalahan/Kerusakan Lainnya: Periksa log Ollama untuk pesan kesalahan yang lebih rinci. Lokasi bervariasi menurut OS (periksa dokumen Ollama).
Alternatif Ollama?
Beberapa alternatif menarik untuk Ollama ada untuk menjalankan model bahasa besar secara lokal.
- LM Studio menonjol dengan antarmuka intuitifnya, pemeriksaan kompatibilitas model, dan server inferensi lokal yang meniru API OpenAI.
- Untuk pengembang yang mencari pengaturan minimal, Llamafile mengubah LLM menjadi executable tunggal yang berjalan di seluruh platform dengan kinerja yang mengesankan.
- Bagi mereka yang lebih menyukai alat baris perintah, LLaMa.cpp berfungsi sebagai mesin inferensi yang mendasari yang mendukung banyak alat LLM lokal dengan kompatibilitas perangkat keras yang sangat baik.

Kesimpulan: Perjalanan Anda ke dalam AI Lokal
Ollama membuka pintu ke dunia model bahasa besar yang menarik, memungkinkan siapa pun dengan komputer yang cukup modern untuk menjalankan alat AI yang kuat secara lokal, pribadi, dan tanpa biaya berkelanjutan.
Ini hanyalah permulaan. Kesenangan sebenarnya dimulai saat Anda bereksperimen dengan model yang berbeda, menyesuaikannya dengan kebutuhan spesifik Anda menggunakan Modelfiles, mengintegrasikan Ollama ke dalam skrip atau aplikasi Anda sendiri melalui API-nya, dan menjelajahi ekosistem AI sumber terbuka yang berkembang pesat.
Kemampuan untuk menjalankan AI canggih secara lokal bersifat transformatif, memberdayakan individu dan pengembang. Selami, jelajahi, ajukan pertanyaan, dan nikmati memiliki kekuatan model bahasa besar tepat di ujung jari Anda dengan Ollama.
Ingin platform Terintegrasi, All-in-One untuk Tim Pengembang Anda untuk bekerja bersama dengan produktivitas maksimum?
Apidog memberikan semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!


