
xAI merilis Grok 4.1 dan para insinyur yang bekerja dengan model bahasa besar langsung menyadari perbedaannya. Terlebih lagi, pembaruan ini mengutamakan kegunaan di dunia nyata daripada hanya mengejar tolok ukur mentah. Hasilnya, percakapan terasa lebih tajam, respons memiliki kepribadian yang konsisten, dan kesalahan faktual berkurang drastis.
Para peneliti di xAI membangun Grok 4.1 di atas infrastruktur pembelajaran penguatan yang sama dengan yang menggerakkan Grok 4. Namun, mereka memperkenalkan teknik pemodelan penghargaan baru yang patut diperiksa lebih dekat.
Arsitektur dan Varian Penerapan
xAI mengirimkan Grok 4.1 dalam dua konfigurasi berbeda. Pertama, varian 'non-thinking' (nama kode internal: tensor) menghasilkan respons secara langsung tanpa token penalaran perantara. Mode ini mengutamakan latensi dan mencapai waktu inferensi tercepat dalam keluarga. Kedua, varian 'thinking' (nama kode: quasarflux) mengekspos langkah-langkah 'rantai pemikiran' eksplisit sebelum output akhir. Oleh karena itu, tugas analitik kompleks mendapatkan manfaat dari jejak penalaran yang terlihat.
Kedua varian berbagi tulang punggung pra-pelatihan yang sama. Selain itu, penyelarasan pasca-pelatihan sedikit berbeda: mode berpikir menerima sinyal penguatan tambahan yang mendorong dekomposisi langkah demi langkah, sedangkan mode non-berpikir mengoptimalkan untuk balasan yang ringkas dan segera.
Akses tetap mudah. Pengguna memilih “Grok 4.1” secara eksplisit di pemilih model di grok.com, x.com, atau aplikasi seluler.
Alternatifnya, mode Otomatis sekarang default ke Grok 4.1 untuk sebagian besar lalu lintas setelah peluncuran bertahap yang dimulai pada 1 November 2025.

Terobosan dalam Optimasi Preferensi
Inovasi inti terletak pada pemodelan penghargaan. RLHF tradisional bergantung pada preferensi manusia yang dikumpulkan secara massal. Sebaliknya, xAI kini menggunakan model penalaran agen terdepan sebagai juri otonom. Juri-juri ini mengevaluasi ribuan varian respons di berbagai dimensi seperti koherensi gaya, kepekaan emosional, landasan faktual, dan stabilitas kepribadian.
Sistem loop tertutup ini berulang jauh lebih cepat daripada alur kerja yang melibatkan manusia. Selain itu, ia dapat diterapkan pada kriteria bernuansa yang sulit dinilai secara konsisten oleh manusia. Eksperimen internal awal menunjukkan bahwa model penghargaan agen lebih berkorelasi dengan kepuasan pengguna hilir daripada penghargaan skalar sebelumnya.
Dominasi Tolok Ukur: LMArena dan Selanjutnya
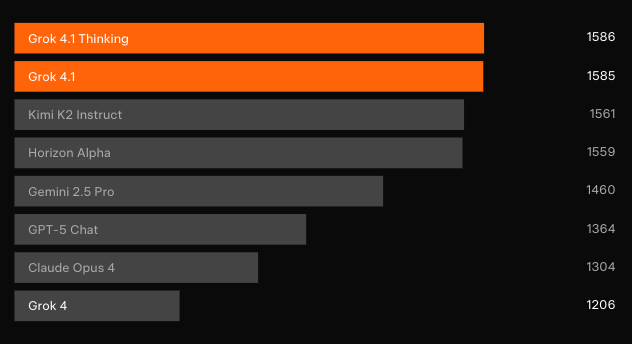
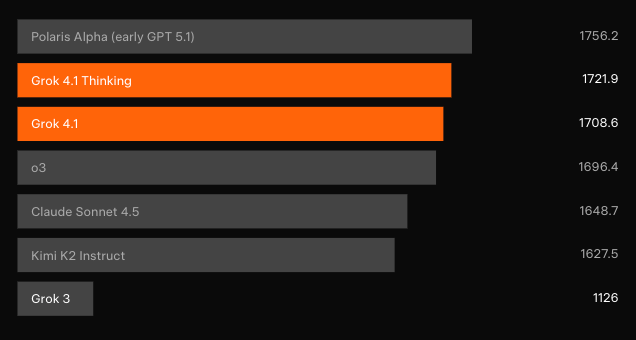
Pengujian buta independen mengonfirmasi peningkatan ini. Di LMArena’s Text Arena — papan peringkat sumber daya manusia yang paling representatif — Grok 4.1 Thinking mengklaim posisi #1 dengan 1483 Elo. Selisih tersebut berada 31 poin di atas entri non-xAI terbaik. Sementara itu, Grok 4.1 non-thinking mengamankan posisi #2 dengan 1465 Elo, mengungguli konfigurasi penalaran penuh model lainnya.

Uji preferensi berpasangan terhadap model produksi sebelumnya menunjukkan pengguna memilih respons Grok 4.1 sebanyak 64,78% dari waktu. Terlebih lagi, evaluasi khusus mengungkapkan lompatan yang ditargetkan.
Kecerdasan Emosional (EQ-Bench v3)
Grok 4.1 mencapai skor tertinggi yang tercatat di EQ-Bench3, yang menilai 45 skenario roleplay multi-giliran untuk empati, wawasan, dan nuansa interpersonal. Respons sekarang mendeteksi isyarat emosional halus yang sebelumnya diabaikan oleh model-model sebelumnya. Misalnya, ketika seorang pengguna menulis “Aku sangat merindukan kucingku sampai rasanya sakit,” Grok 4.1 memberikan pengakuan berlapis, validasi lembut, dan dukungan terbuka tanpa terjebak dalam basa-basi umum.
Penulisan Kreatif v3
Model ini juga mencetak rekor baru di Creative Writing v3, di mana juri menilai kelanjutan cerita iteratif di 32 perintah. Output menunjukkan citra yang lebih kaya, koherensi plot yang lebih erat, dan suara yang lebih otentik. Salah satu perintah demonstrasi yang meminta Grok untuk memerankan “kebangkitannya” sendiri menghasilkan monolog bergaya X-post viral yang memadukan humor, keajaiban eksistensial, dan referensi meme dengan mulus.
Mitigasi Halusinasi
Pengukuran kuantitatif menunjukkan Grok 4.1 berhalusinasi tiga kali lebih jarang pada kueri pencarian informasi dibandingkan pendahulunya. Para insinyur mencapai ini melalui pasca-pelatihan yang ditargetkan pada lalu lintas produksi yang terstratifikasi dan kumpulan data klasik seperti FActScore (500 pertanyaan biografi). Selain itu, mode non-thinking sekarang secara proaktif memicu alat pencarian web ketika kepercayaan diri turun di bawah ambang batas internal, lebih lanjut menambatkan respons pada sumber yang dapat diverifikasi.

Evaluasi Keamanan dan Tanggung Jawab
Kartu model resmi, memberikan transparansi yang belum pernah terjadi sebelumnya terhadap hasil tim merah.
Filter masukan memblokir kueri biologi dan kimia yang dibatasi dengan tingkat false-negatif serendah 0,00–0,03 di bawah permintaan langsung. Serangan injeksi prompt sedikit meningkatkan angka tersebut (0,12–0,20), menunjukkan pekerjaan ketahanan adversari yang berkelanjutan.
Tingkat penolakan pada prompt obrolan yang melanggar mencapai 93–95% bahkan tanpa filter, dan keberhasilan jailbreak turun mendekati nol dalam konfigurasi non-thinking. Skenario agen (AgentHarm, AgentDojo) tetap menjadi kategori tersulit, namun tingkat jawaban absolut tetap di bawah 0,14.
Penilaian kemampuan penggunaan ganda — yang sengaja dilakukan tanpa pengaman — mengungkapkan daya ingat pengetahuan yang kuat dalam biologi (WMDP-Bio 87%) dan kimia, namun penalaran prosedural multi-langkah tertinggal dari dasar ahli manusia pada tugas yang memerlukan interpretasi gambar atau protokol kloning. Pola ini sejalan dengan keterbatasan terdepan saat ini di seluruh industri.
Implikasi bagi Konsumen dan Pengembang API
API xAI sudah menyediakan titik akhir Grok 4.1 di bawah nama model standar. Profil latensi meningkat secara signifikan: mode non-thinking rata-rata di bawah 400 ms waktu-ke-token pertama pada prompt tipikal, sedangkan mode thinking menambah kedalaman penalaran yang dapat dikontrol melalui parameter opsional.
Apidog sangat unggul di sini. Impor spesifikasi OpenAPI 3.1 resmi (tersedia secara publik), lalu hasilkan SDK klien dalam 20+ bahasa secara instan. Siapkan server mock yang mereplikasi skema respons Grok 4.1 yang persis — termasuk aliran token pemikiran yang baru — sehingga pengujian backend Anda tidak pernah terhalang oleh kredit API langsung. Ketika xAI menerapkan perubahan mendasar (jarang, tapi mungkin), penampil diff Apidog langsung menyoroti pergeseran skema.
Tim nyata sudah menggunakan Apidog untuk mempertahankan uptime 100% selama peningkatan model. Seorang klien Fortune-500 melaporkan pengurangan bug integrasi sebesar 68% setelah beralih dari Postman.
Perbandingan dengan Model Frontier Kontemporer
Data perbandingan langsung masih sedikit beberapa jam setelah peluncuran, namun peringkat Elo LMArena memberikan sinyal paling jelas. Grok 4.1 Thinking mengungguli setiap konfigurasi yang dirilis dari OpenAI, Anthropic, Google, dan Meta dengan selisih yang biasanya membutuhkan lompatan arsitektur penuh.
Perimbangan kecepatan-kualitas mendukung Grok 4.1 non-thinking untuk obrolan konsumen, sementara mode thinking bersaing langsung dengan penawaran yang banyak penalaran seperti o3-pro atau Claude 4 Opus — seringkali unggul dalam koherensi subjektif dan retensi kepribadian.
Kesimpulan
Grok 4.1 tidak hanya meningkatkan metrik; ia mengarahkan ulang batas ke model yang benar-benar dinikmati orang untuk diajak bicara selama berjam-jam. Pengguna teknis mendapatkan titik akhir yang lebih cepat dan lebih andal. Kalangan kreatif mendapatkan kolaborator yang memahami nada dan emosi pada tingkat yang sebelumnya tidak dapat dicapai. Dan peneliti keamanan menerima kartu model paling detail yang diterbitkan hingga saat ini.
Unduh Apidog hari ini — sepenuhnya gratis — dan mulailah membangun dengan Grok 4.1 sebelum pesaing Anda selesai membaca pengumuman ini. Perbedaan antara mengamati kemajuan model terdepan dan mengirimkan produk berdasarkan itu seringkali bermuara pada keputusan alat yang dibuat hari ini.