
Ingin meningkatkan alur kerja coding Anda dengan **GPT-OSS**, model *open-weight* dari Open AI, langsung di dalam **Claude Code**? Anda akan sangat senang! Dirilis pada Agustus 2025, **GPT-OSS** (varian 20B atau 120B) adalah kekuatan besar untuk coding dan penalaran, dan Anda dapat memasangkannya dengan antarmuka CLI Claude Code yang ramping untuk pengaturan gratis atau berbiaya rendah. Dalam panduan percakapan ini, kami akan memandu Anda melalui tiga cara untuk mengintegrasikan **GPT-OSS** dengan Claude Code menggunakan Hugging Face, OpenRouter, atau LiteLLM. Mari kita mulai dan siapkan asisten coding AI Anda!
Ingin platform All-in-One yang terintegrasi untuk Tim Pengembang Anda agar dapat bekerja sama dengan produktivitas maksimum?
Apidog memenuhi semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!
Apa Itu GPT-OSS dan Mengapa Menggunakannya dengan Claude Code?
**GPT-OSS** adalah keluarga model *open-weight* Open AI, dengan varian 20B dan 120B menawarkan kinerja luar biasa untuk tugas coding, penalaran, dan keagenan. Dengan jendela konteks 128K token dan lisensi Apache 2.0, ini sangat cocok untuk pengembang yang menginginkan fleksibilitas dan kontrol. **Claude Code**, alat CLI Anthropic (versi 0.5.3+), adalah favorit pengembang karena kemampuan coding percakapannya. Dengan mengarahkan Claude Code ke **GPT-OSS** melalui API yang kompatibel dengan OpenAI, Anda dapat menikmati antarmuka Claude yang familiar sambil memanfaatkan kekuatan *open-source* **GPT-OSS**—tanpa biaya langganan Anthropic. Siap mewujudkannya? Mari jelajahi opsi pengaturannya!

Prasyarat untuk Menggunakan GPT-OSS dengan Claude Code
Sebelum kita mulai, pastikan Anda memiliki:
- **Claude Code ≥ 0.5.3**: Periksa dengan
claude --version. Instal melaluipip install claude-codeatau perbarui denganpip install --upgrade claude-code. - **Akun Hugging Face**: Daftar di huggingface.co dan buat token baca/tulis (Pengaturan > Token Akses).
- **Kunci API OpenRouter**: Opsional, untuk Jalur B. Dapatkan di openrouter.ai.
- **Python 3.10+ dan Docker**: Untuk pengaturan lokal atau LiteLLM (Jalur C).
- **Pengetahuan CLI Dasar**: Keakraban dengan variabel lingkungan dan perintah terminal akan membantu.
Jalur A: Hosting Mandiri GPT-OSS di Hugging Face
Ingin kontrol penuh? Hosting **GPT-OSS** di Inference Endpoints Hugging Face untuk pengaturan pribadi yang skalabel. Berikut caranya:
Langkah 1: Dapatkan Modelnya
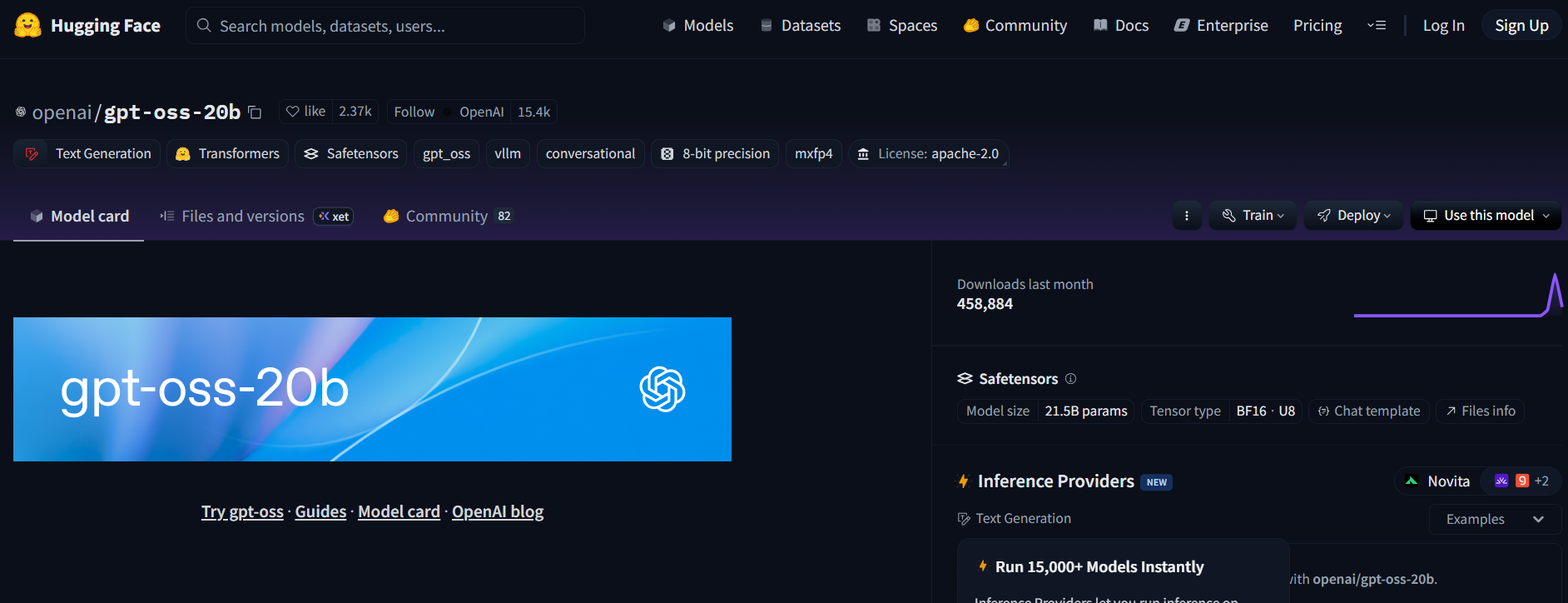
- Kunjungi repo **GPT-OSS** di Hugging Face (openai/gpt-oss-20b atau openai/gpt-oss-120b).
- Setujui lisensi Apache 2.0 untuk mengakses model.
- Sebagai alternatif, coba **Qwen3-Coder-480B-A35B-Instruct** (Qwen/Qwen3-Coder-480B-A35B-Instruct) untuk model yang berfokus pada coding (gunakan versi GGUF untuk perangkat keras yang lebih ringan).
Langkah 2: Terapkan Titik Akhir Inferensi Generasi Teks
- Pada halaman model, klik **Deploy** > **Inference Endpoint**.
- Pilih templat **Text Generation Inference (TGI)** (≥ v1.4.0).
- Aktifkan kompatibilitas OpenAI dengan mencentang **Enable OpenAI compatibility** atau menambahkan
--enable-openaidi pengaturan lanjutan. - Pilih perangkat keras: A10G atau CPU untuk 20B, A100 untuk 120B. Buat titik akhir.
Langkah 3: Kumpulkan Kredensial
- Setelah status titik akhir adalah **Running**, salin:
- **ENDPOINT_URL**: Terlihat seperti
https://<titik-akhir-anda>.us-east-1.aws.endpoints.huggingface.cloud. - **HF_API_TOKEN**: Token Hugging Face Anda dari Pengaturan > Token Akses.
2. Catat ID model (misalnya, gpt-oss-20b atau gpt-oss-120b).
Langkah 4: Konfigurasi Claude Code
- Atur variabel lingkungan di terminal Anda:
export ANTHROPIC_BASE_URL="https://<titik-akhir-anda>.us-east-1.aws.endpoints.huggingface.cloud"
export ANTHROPIC_AUTH_TOKEN="hf_xxxxxxxxxxxxxxxxx"
export ANTHROPIC_MODEL="gpt-oss-20b" # atau gpt-oss-120b
Ganti <titik-akhir-anda> dan hf_xxxxxxxxxxxxxxxxx dengan nilai Anda.
2. Uji pengaturannya:
claude --model gpt-oss-20b
Claude Code mengarahkan ke titik akhir **GPT-OSS** Anda, mengalirkan respons melalui API /v1/chat/completions TGI, meniru skema OpenAI.
Langkah 5: Catatan Biaya dan Skala
- **Biaya Hugging Face**: Inference Endpoints secara otomatis berskala, jadi pantau penggunaan untuk menghindari pembakaran kredit. A10G berharga sekitar $0.60/jam, A100 sekitar $3/jam.
- **Opsi Lokal**: Untuk biaya cloud nol, jalankan TGI secara lokal dengan Docker:
docker run --name tgi -p 8080:80 -e HF_TOKEN=hf_xxxxxxxxxxxxxxxxx ghcr.io/huggingface/text-generation-inference:latest --model-id openai/gpt-oss-20b --enable-openai
Kemudian atur ANTHROPIC_BASE_URL="http://localhost:8080".
Jalur B: Proxy GPT-OSS Melalui OpenRouter
Tidak ada DevOps? Tidak masalah! Gunakan **OpenRouter** untuk mengakses **GPT-OSS** dengan pengaturan minimal. Ini cepat dan menangani penagihan untuk Anda.
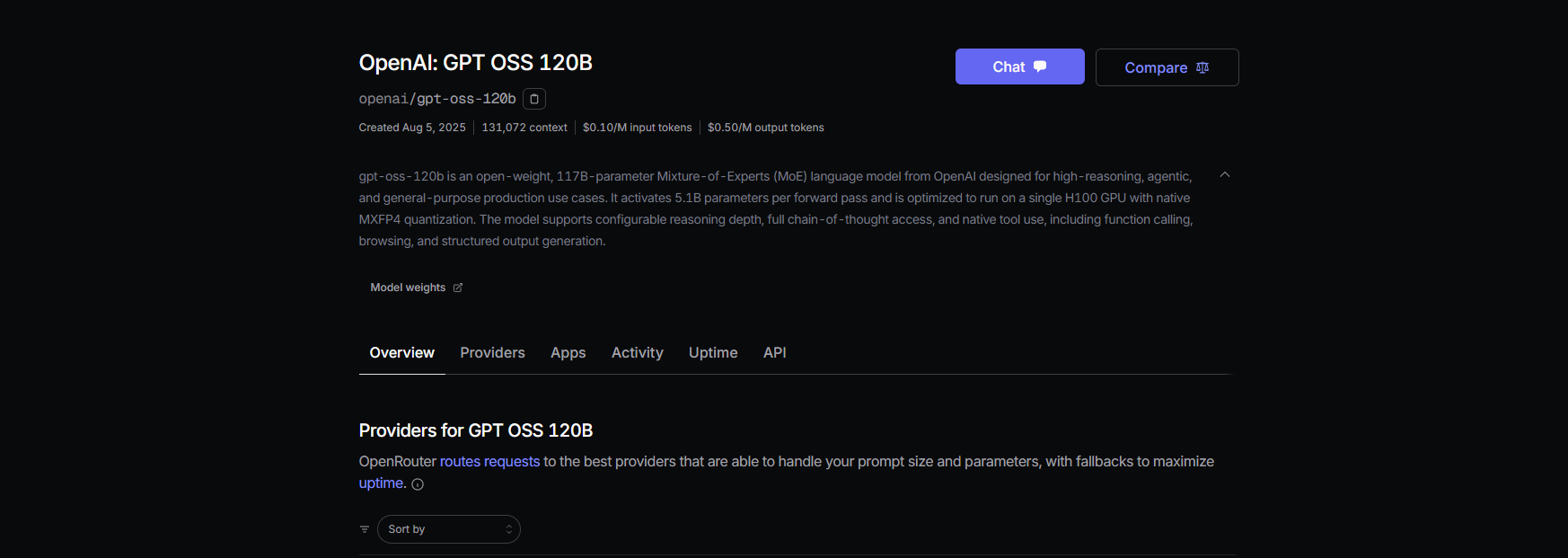
Langkah 1: Daftar dan Pilih Model
- Daftar di openrouter.ai dan salin kunci API Anda dari bagian **Keys**.
- Pilih slug model:
openai/gpt-oss-20bopenai/gpt-oss-120bqwen/qwen3-coder-480b(untuk model coder Qwen)
Langkah 2: Konfigurasi Claude Code
- Atur variabel lingkungan:
export ANTHROPIC_BASE_URL="https://openrouter.ai/api/v1"
export ANTHROPIC_AUTH_TOKEN="or_xxxxxxxxx"
export ANTHROPIC_MODEL="openai/gpt-oss-20b"
Ganti or_xxxxxxxxx dengan kunci API OpenRouter Anda.
2. Uji coba:
claude --model openai/gpt-oss-20b
Claude Code terhubung ke **GPT-OSS** melalui API terpadu OpenRouter, dengan dukungan streaming dan fallback.
Langkah 3: Catatan Biaya
- **Harga OpenRouter**: Sekitar $0.50/M token input, ~$2.00/M token output untuk **GPT-OSS-120B**, jauh lebih murah daripada model proprietary seperti GPT-4 (~$20.00/M).
- **Penagihan**: OpenRouter mengelola penggunaan, jadi Anda hanya membayar sesuai penggunaan.
Jalur C: Gunakan LiteLLM untuk Armada Model Campuran
Ingin mengelola model **GPT-OSS**, Qwen, dan Anthropic dalam satu alur kerja? **LiteLLM** bertindak sebagai proxy untuk menukar model dengan mulus.
Langkah 1: Instal dan Konfigurasi LiteLLM
- Instal LiteLLM:
pip install litellm
2. Buat file konfigurasi (litellm.yaml):
model_list:
- model_name: gpt-oss-20b
litellm_params:
model: openai/gpt-oss-20b
api_key: or_xxxxxxxxx # Kunci OpenRouter
api_base: https://openrouter.ai/api/v1
- model_name: qwen3-coder
litellm_params:
model: openrouter/qwen/qwen3-coder
api_key: or_xxxxxxxxx
api_base: https://openrouter.ai/api/v1
Ganti or_xxxxxxxxx dengan kunci OpenRouter Anda.
3. Mulai proxy:
litellm --config litellm.yaml
Langkah 2: Arahkan Claude Code ke LiteLLM
- Atur variabel lingkungan:
export ANTHROPIC_BASE_URL="http://localhost:4000"
export ANTHROPIC_AUTH_TOKEN="litellm_master"
export ANTHROPIC_MODEL="gpt-oss-20b"
2. Uji coba:
claude --model gpt-oss-20b
LiteLLM mengarahkan permintaan ke **GPT-OSS** melalui OpenRouter, dengan pencatatan biaya dan routing *simple-shuffle* untuk keandalan.
Langkah 3: Catatan
- **Hindari Routing Latensi**: Gunakan mode *simple-shuffle* di LiteLLM untuk mencegah masalah dengan model Anthropic.
- **Pelacakan Biaya**: LiteLLM mencatat penggunaan untuk transparansi.
Menguji GPT-OSS dengan Claude Code
Mari pastikan **GPT-OSS** berfungsi! Buka Claude Code dan coba perintah berikut:
**Generasi Kode**:
claude --model gpt-oss-20b "Tulis REST API Python dengan Flask"
Harapkan respons seperti:
from flask import Flask, jsonify
app = Flask(__name__)
@app.route('/api', methods=['GET'])
def get_data():
return jsonify({"message": "Halo dari GPT-OSS!"})
if __name__ == '__main__':
app.run(debug=True)
**Analisis Kodebasis**:
claude --model gpt-oss-20b "Ringkas src/server.js"
**GPT-OSS** memanfaatkan jendela konteks 128K-nya untuk menganalisis file JavaScript Anda dan mengembalikan ringkasan.
**Debugging**:
claude --model gpt-oss-20b "Debug kode Python yang *buggy* ini: [tempel kode]"
Dengan tingkat kelulusan HumanEval 87.3%, **GPT-OSS** seharusnya dapat menemukan dan memperbaiki masalah secara akurat.
Tips Pemecahan Masalah
- **404 pada /v1/chat/completions?** Pastikan
--enable-openaiaktif di TGI (Jalur A) atau periksa ketersediaan model OpenRouter (Jalur B). - **Respons Kosong?** Verifikasi
ANTHROPIC_MODELcocok dengan slug (misalnya,gpt-oss-20b). - **Error 400 Setelah Tukar Model?** Gunakan routing *simple-shuffle* di LiteLLM (Jalur C).
- **Token Pertama Lambat?** Panaskan titik akhir Hugging Face dengan prompt kecil setelah penskalaan ke nol.
- **Claude Code Crash?** Perbarui ke ≥ 0.5.3 dan pastikan variabel lingkungan diatur dengan benar.
Mengapa Menggunakan GPT-OSS dengan Claude Code?
Memasangkan **GPT-OSS** dengan Claude Code adalah impian para pengembang. Anda mendapatkan:
- **Penghematan Biaya**: $0.50/M token input OpenRouter mengalahkan model proprietary, dan pengaturan TGI lokal gratis setelah biaya perangkat keras.
- **Kekuatan Open-Source**: Lisensi Apache 2.0 **GPT-OSS** memungkinkan Anda menyesuaikan atau menerapkan secara pribadi.
- **Alur Kerja yang Mulus**: CLI Claude Code terasa seperti mengobrol dengan teman coding, sementara **GPT-OSS** menangani pekerjaan berat dengan skor MMLU 94.2% dan AIME 96.6%.
- **Fleksibilitas**: Tukar antara model **GPT-OSS**, Qwen, atau Anthropic dengan LiteLLM atau OpenRouter.
Pengguna memuji kehebatan coding **GPT-OSS**, menyebutnya "binatang buas yang hemat anggaran untuk proyek multi-file." Baik Anda menghosting sendiri atau melalui proxy OpenRouter, pengaturan ini menjaga biaya tetap rendah dan produktivitas tetap tinggi.
Kesimpulan
Anda sekarang siap untuk menggunakan **GPT-OSS** dengan **Claude Code**! Baik Anda menghosting sendiri di Hugging Face, menggunakan proxy melalui OpenRouter, atau menggunakan LiteLLM untuk mengelola model, Anda memiliki pengaturan coding yang kuat dan hemat biaya. Dari menghasilkan REST API hingga men-debug kode, **GPT-OSS** memberikan hasil, dan Claude Code membuatnya terasa mudah. Cobalah, bagikan prompt favorit Anda di komentar, dan mari kita nikmati coding AI!
Ingin platform All-in-One yang terintegrasi untuk Tim Pengembang Anda agar dapat bekerja sama dengan produktivitas maksimum?
Apidog memenuhi semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!