
Pengembang terus-menerus mencari alat canggih untuk membangun aplikasi cerdas. OpenAI menjawab kebutuhan ini dengan merilis GPT-OSS, serangkaian model bahasa berbobot terbuka yang menyediakan kemampuan penalaran tingkat lanjut. Model-model ini, termasuk gpt-oss-120b dan gpt-oss-20b, memungkinkan penyesuaian dan penerapan di berbagai lingkungan. Pengguna mengaksesnya melalui API yang disediakan oleh platform hosting, memungkinkan integrasi yang mulus ke dalam proyek.
Untuk mulai bekerja dengan API GPT-OSS, pengembang mendapatkan akses melalui penyedia seperti OpenRouter atau Together AI. Platform ini meng-host model dan mengekspos endpoint standar yang kompatibel dengan format API OpenAI. Kompatibilitas ini menyederhanakan migrasi dari model berpemilik.
Apa Itu GPT-OSS? Fitur dan Kemampuan Utama
OpenAI merancang GPT-OSS sebagai keluarga model Mixture-of-Experts (MoE). Arsitektur ini hanya mengaktifkan sebagian kecil parameter per token, meningkatkan efisiensi. Misalnya, gpt-oss-120b memiliki total 117 miliar parameter tetapi hanya mengaktifkan 5,1 miliar per token. Demikian pula, gpt-oss-20b menggunakan 21 miliar parameter dengan 3,6 miliar aktif.
Model-model ini menggunakan struktur berbasis Transformer dengan lapisan perhatian padat dan jarang yang bergantian. Mereka menggabungkan Rotary Positional Embeddings (RoPE) untuk menangani konteks panjang hingga 128.000 token. Pengembang mendapatkan manfaat dari ini dalam aplikasi yang membutuhkan input ekstensif, seperti ringkasan dokumen.
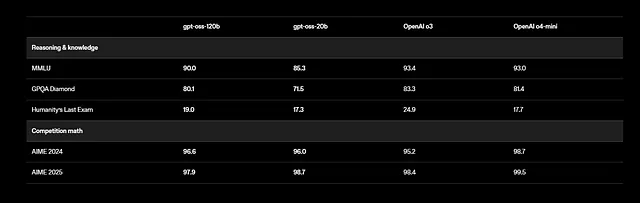
Selain itu, GPT-OSS mendukung tugas multibahasa, meskipun pelatihan berfokus pada bahasa Inggris dengan penekanan pada data STEM dan pengkodean. Tolok ukur menunjukkan hasil yang mengesankan: gpt-oss-120b mencetak 94,2% pada MMLU (Massive Multitask Language Understanding) dan 96,6% pada AIME (American Invitational Mathematics Examination). Ini mengungguli model seperti o4-mini dalam kueri terkait kesehatan dan matematika kompetisi.
Pengembang memanfaatkan fitur pemanggilan alat (tool calling), di mana model memanggil fungsi eksternal seperti pencarian web atau eksekusi kode. Kemampuan agen ini memungkinkan pembangunan sistem otonom. Misalnya, model merangkai beberapa panggilan alat dalam satu respons untuk memecahkan masalah langkah demi langkah.
Selain itu, model-model ini mematuhi lisensi Apache 2.0, memungkinkan modifikasi dan penerapan gratis. OpenAI menyediakan bobot di Hugging Face, dikuantisasi dalam format MXFP4 untuk mengurangi penggunaan memori. Pengguna menjalankannya secara lokal atau melalui penyedia cloud.
Namun, pertimbangan keamanan berlaku. OpenAI melakukan evaluasi di bawah Kerangka Kesiapan (Preparedness Framework) mereka, menguji risiko seperti misinformasi. Pengembang menerapkan perlindungan, seperti memfilter output, untuk mengurangi masalah.
Intinya, GPT-OSS menggabungkan kekuatan dengan aksesibilitas. Sifatnya yang terbuka mendorong kontribusi komunitas, yang mengarah pada peningkatan yang cepat. Selanjutnya, identifikasi penyedia yang menawarkan akses API ke model-model ini.
Memilih Penyedia untuk Akses API GPT-OSS
Beberapa platform meng-host model GPT-OSS dan menyediakan endpoint API. Pengembang memilih berdasarkan kebutuhan seperti kecepatan, biaya, dan skalabilitas. OpenRouter, misalnya, menawarkan gpt-oss-120b dengan harga yang kompetitif dan integrasi yang mudah.
Together AI menyediakan opsi lain, menekankan penerapan siap-perusahaan. Ini mendukung model melalui endpoint /v1/chat/completions, yang kompatibel dengan klien OpenAI. Pengembang mengirimkan payload JSON yang menentukan pesan, max_tokens, dan temperature.
Selain itu, Fireworks AI dan Cerebras memberikan inferensi berkecepatan tinggi. Cerebras mencapai hingga 3.000 token per detik, ideal untuk aplikasi waktu nyata. Harga bervariasi: OpenRouter mengenakan biaya sekitar $0,15 per juta token input, sementara Together AI menawarkan tarif serupa dengan diskon volume.
Pengembang juga mempertimbangkan self-hosting untuk privasi. Alat seperti vLLM atau Ollama memungkinkan menjalankan GPT-OSS di server lokal, mengekspos API. Misalnya, vLLM melayani model dengan rute yang kompatibel dengan OpenAI, hanya membutuhkan satu perintah untuk memulai.
Namun, penyedia cloud menyederhanakan penskalaan. AWS, Azure, dan Vercel mengintegrasikan GPT-OSS melalui kemitraan dengan OpenAI. Opsi-opsi ini menangani load balancing dan auto-scaling secara otomatis.
Selain itu, evaluasi latensi. gpt-oss-20b cocok untuk perangkat edge dengan persyaratan yang lebih rendah, sementara gpt-oss-120b membutuhkan GPU seperti NVIDIA H100. Penyedia mengoptimalkan perangkat keras, memastikan kinerja yang konsisten.
Singkatnya, penyedia yang tepat selaras dengan tujuan proyek. Setelah dipilih, lanjutkan untuk mendapatkan kredensial API.
Mendapatkan Akses API dan Menyiapkan Lingkungan Anda
Pengembang memulai dengan mendaftar di situs penyedia. Untuk OpenRouter, kunjungi openrouter.ai, buat akun, dan navigasikan ke bagian Keys. Hasilkan kunci API baru, beri nama untuk referensi, dan salin dengan aman.
Selanjutnya, instal pustaka klien. Di Python, gunakan pip untuk menambahkan openai: pip install openai. Konfigurasi klien dengan URL dasar dan kunci. Contoh:
from openai import OpenAI
client = OpenAI(
base_url="https://openrouter.ai/api/v1",
api_key="your_api_key_here"
)
Pengaturan ini memungkinkan pengiriman permintaan ke model gpt-oss.
Selain itu, untuk Together AI, gunakan SDK mereka: pip install together. Inisialisasi dengan:
import together
together.api_key = "your_together_api_key"
Uji koneksi dengan mencantumkan model atau mengirim kueri sederhana.
Namun, verifikasi perangkat keras jika melakukan self-hosting. Unduh bobot dari Hugging Face: huggingface-cli download openai/gpt-oss-120b. Kemudian, gunakan vLLM untuk melayani: vllm serve openai/gpt-oss-120b.
Selain itu, atur variabel lingkungan untuk keamanan. Simpan kunci dalam file .env dan muat dengan pustaka dotenv.
Jika ada masalah, periksa dokumen penyedia untuk batas laju atau kesalahan otentikasi. Persiapan ini memastikan interaksi API yang lancar.
Melakukan Panggilan API Pertama Anda ke GPT-OSS
Pengembang membuat permintaan menggunakan endpoint chat completions. Tentukan model, seperti "openai/gpt-oss-120b", dalam payload.
Untuk panggilan dasar, siapkan pesan sebagai daftar kamus. Setiap kamus menyertakan peran (system, user, assistant) dan konten.
Berikut adalah contoh dalam Python:
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[
{"role": "system", "content": "You are a helpful assistant."},
{"role": "user", "content": "Explain quantum superposition."}
],
max_tokens=200,
temperature=0.7
)
print(completion.choices[0].message.content)
Ini menghasilkan respons yang menjelaskan konsep secara teknis.
Selain itu, sesuaikan parameter untuk kontrol. Temperature memengaruhi kreativitas – nilai yang lebih rendah menghasilkan output yang deterministik. Top_p membatasi pengambilan sampel token, sementara presence_penalty mencegah pengulangan.
Selanjutnya, gabungkan pemanggilan alat (tool calling). Definisikan alat dalam permintaan:
tools = [
{
"type": "function",
"function": {
"name": "get_current_weather",
"description": "Get the current weather in a given location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string", "description": "The city and state, e.g. San Francisco, CA"},
"unit": {"type": "string", "enum": ["celsius", "fahrenheit"]}
},
"required": ["location"]
}
}
}
]
completion = client.chat.completions.create(
model="openai/gpt-oss-120b",
messages=[{"role": "user", "content": "What's the weather like in Boston?"}],
tools=tools,
tool_choice="auto"
)
Model merespons dengan panggilan alat, yang kemudian dieksekusi oleh pengembang dan diumpankan kembali.
Namun, tangani respons dengan hati-hati. Uraikan JSON untuk konten, finish_reason, dan statistik penggunaan seperti jumlah token.
Selain itu, untuk chain-of-thought, berikan prompt dengan "Think step by step." Atur upaya penalaran dalam pesan sistem: "reasoning_effort: medium".
Bereksperimenlah dengan gpt-oss-20b untuk pengujian yang lebih cepat: Ganti nama model dalam panggilan.
Dalam skenario lanjutan, streaming respons menggunakan stream=True untuk output waktu nyata.
Langkah-langkah ini membangun keterampilan dasar. Sekarang, integrasikan alat pengujian seperti Apidog.
Mengintegrasikan Apidog untuk Pengujian API GPT-OSS yang Efisien
Pengembang mengandalkan Apidog untuk menguji dan men-debug interaksi API. Alat ini menyediakan antarmuka yang ramah pengguna untuk mengirim permintaan ke endpoint gpt-oss.
Pertama, instal Apidog dari situs web mereka. Buat proyek baru dan tambahkan endpoint API, seperti https://openrouter.ai/api/v1/chat/completions.
Selanjutnya, konfigurasikan header: Tambahkan Authorization dengan token Bearer dan Content-Type sebagai application/json.
Selain itu, bangun badan permintaan. Gunakan editor JSON Apidog untuk memasukkan model, pesan, dan parameter. Misalnya, uji panggilan gpt-oss untuk pembuatan kode.
Apidog memvisualisasikan respons, menyoroti kesalahan atau keberhasilan. Ini mendukung variabel lingkungan untuk beralih kunci API antar penyedia.
Namun, manfaatkan koleksi untuk mengatur pengujian. Kelompokkan kueri GPT-OSS berdasarkan tugas, seperti penalaran atau penggunaan alat, dan jalankan dalam batch.
Selain itu, Apidog menghasilkan cuplikan kode dalam bahasa seperti Python atau cURL dari permintaan Anda, mempercepat pengembangan.
Untuk kolaborasi, bagikan proyek dengan tim. Ini memastikan pengujian integrasi gpt-oss yang konsisten.
Dalam praktiknya, gunakan Apidog untuk memantau penggunaan token dan mengoptimalkan prompt, mengurangi biaya.
Secara keseluruhan, Apidog meningkatkan produktivitas saat bekerja dengan API GPT-OSS.
Penggunaan Tingkat Lanjut: Penyesuaian dan Penerapan
Pengembang menyempurnakan GPT-OSS untuk domain tertentu. Gunakan pustaka transformers Hugging Face untuk memuat bobot dan melatih pada kumpulan data kustom.
Misalnya, siapkan data dalam format JSONL dengan pasangan prompt-completion. Jalankan skrip penyempurnaan dari repo GitHub.
Selain itu, terapkan model yang disetel melalui vLLM untuk penyajian API. Ini mendukung beban produksi dengan fitur seperti dynamic batching.
Selanjutnya, jelajahi ekstensi multi-modal. Meskipun berfokus pada teks, integrasikan dengan model visi untuk aplikasi hibrida.
Namun, pantau overfitting selama penyempurnaan. Gunakan set validasi dan penghentian awal.
Selain itu, skalakan dengan inferensi terdistribusi pada kluster. Penyedia seperti AWS menawarkan opsi terkelola.
Dalam pengaturan agen, rantai GPT-OSS dengan API eksternal untuk alur kerja seperti penelitian otomatis.
Teknik-teknik ini memperluas kemampuan di luar panggilan dasar.
Praktik Terbaik, Batasan, dan Pemecahan Masalah
Pengembang mengikuti praktik terbaik untuk hasil optimal. Buat prompt yang jelas, gunakan contoh few-shot, dan iterasi berdasarkan output.
Selain itu, hormati batas laju – periksa dasbor penyedia untuk menghindari pembatasan.
Namun, akui batasan: GPT-OSS mungkin berhalusinasi, jadi validasi respons penting. Ini tidak memiliki pembaruan pengetahuan waktu nyata.
Selain itu, amankan kunci API dan log penggunaan untuk kontrol biaya.
Pecahkan masalah dengan meninjau kode kesalahan; 401 menunjukkan otentikasi tidak valid, 429 berarti batas laju tercapai.
Singkatnya, patuhi panduan ini untuk kinerja yang andal.
Kesimpulan: Berdayakan Proyek Anda dengan API GPT-OSS
Pengembang kini memiliki alat untuk mengintegrasikan GPT-OSS secara efektif. Dari pengaturan hingga fitur lanjutan, panduan ini membekali Anda untuk sukses. Bereksperimenlah, sempurnakan, dan berinovasi dengan gpt-oss dan Apidog untuk menciptakan solusi AI yang berdampak.