
Hai, para penggemar AI! Bersiaplah karena Open AI baru saja meluncurkan kejutan besar dengan model berbobot terbuka (open-weight) terbaru mereka, **GPT-OSS-120B**, dan ini menarik perhatian di komunitas AI. Dirilis di bawah lisensi Apache 2.0, model canggih ini dirancang untuk tugas penalaran, pengkodean, dan agen, semuanya berjalan pada satu GPU. Dalam panduan ini, kita akan menyelami apa yang membuat **GPT-OSS-120B** istimewa, tolok ukur luar biasa, harga terjangkau, dan bagaimana Anda dapat menggunakannya melalui API OpenRouter. Mari jelajahi permata sumber terbuka ini dan buat Anda dapat mengkode dengannya dalam waktu singkat!
Ingin platform All-in-One terintegrasi untuk Tim Pengembang Anda agar dapat bekerja sama dengan produktivitas maksimal?
Apidog memenuhi semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!
Apa Itu GPT-OSS-120B?
**GPT-OSS-120B** dari Open AI adalah model bahasa dengan 117 miliar parameter (dengan 5,1 miliar aktif per token) yang merupakan bagian dari seri GPT-OSS berbobot terbuka baru mereka, di samping GPT-OSS-20B yang lebih kecil. Dirilis pada 5 Agustus 2025, ini adalah model Mixture-of-Experts (MoE) yang dioptimalkan untuk efisiensi, berjalan pada satu GPU NVIDIA H100 atau bahkan perangkat keras konsumen dengan kuantisasi MXFP4. Ini dibangun untuk tugas-tugas seperti penalaran kompleks, pembuatan kode, dan penggunaan alat, dengan jendela konteks 128K token yang besar—bayangkan 300–400 halaman teks! Di bawah lisensi Apache 2.0, Anda dapat menyesuaikan, menyebarkan, atau bahkan mengomersialkannya, menjadikannya impian bagi pengembang dan bisnis yang mendambakan kontrol dan privasi.

Tolok Ukur: Bagaimana Performa GPT-OSS-120B?
**GPT-OSS-120B** tidak kalah dalam hal kinerja. Tolok ukur Open AI menunjukkan bahwa ini adalah pesaing serius terhadap model-model berpemilik seperti o4-mini mereka sendiri dan bahkan Claude 3.5 Sonnet. Berikut rinciannya:
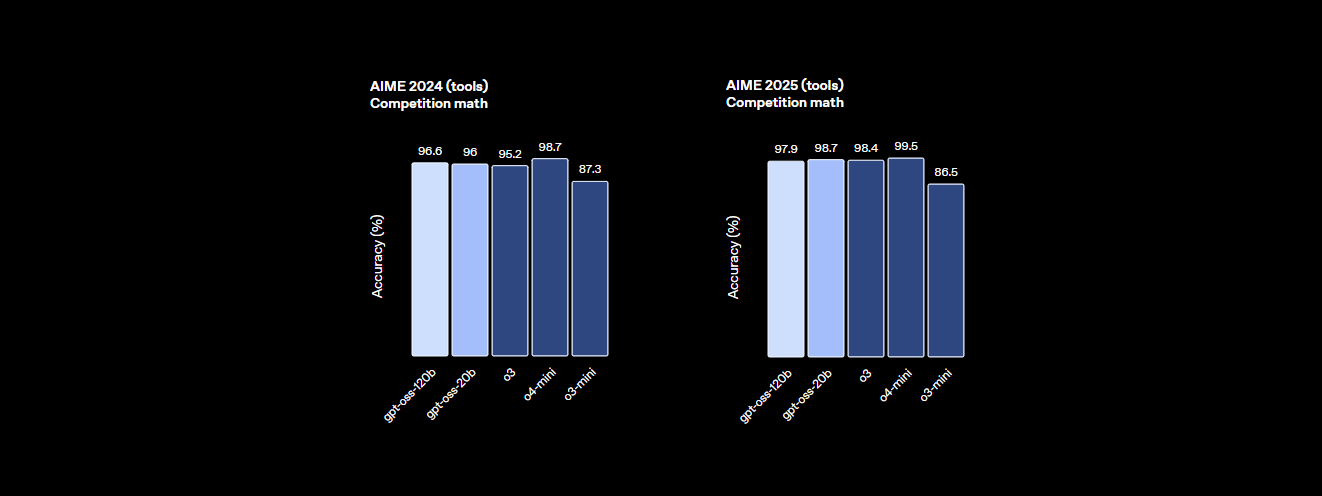
- Kekuatan Penalaran: Ia mencetak 94,2% pada MMLU (Massive Multitask Language Understanding), sedikit di bawah 95,1% GPT-4, dan mencapai 96,6% pada kompetisi matematika AIME, mengungguli banyak model tertutup.
- Kecakapan Pengkodean: Pada Codeforces, ia memiliki peringkat Elo 2622, dan mencapai tingkat kelulusan 87,3% pada HumanEval untuk pembuatan kode, menjadikannya teman terbaik bagi pembuat kode.
- Kesehatan dan Penggunaan Alat: Ini melampaui o4-mini pada HealthBench untuk kueri terkait kesehatan dan unggul dalam tugas-tugas agen seperti TauBench, berkat penalaran chain-of-thought (CoT) dan kemampuan pemanggilan alatnya.
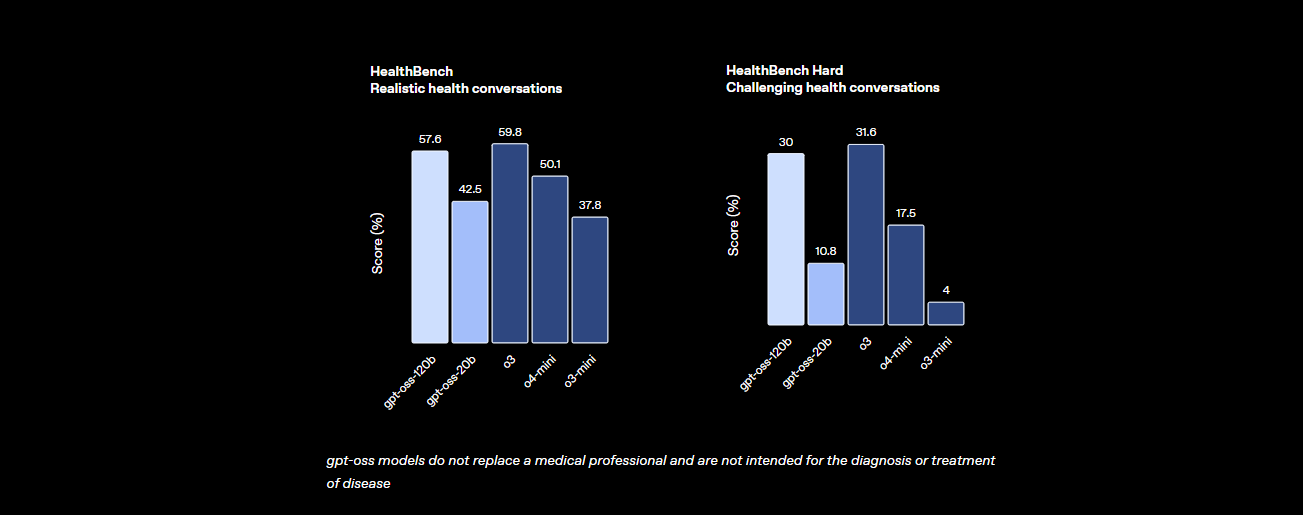
- Kecepatan: Pada GPU H100, ia memproses 45 token per detik, dengan penyedia seperti Cerebras mencapai hingga 3.000 token/detik untuk kebutuhan volume tinggi. OpenRouter menghasilkan ~500 token/detik, mengungguli banyak model tertutup.
Statistik ini menunjukkan bahwa **GPT-OSS-120B** hampir setara dengan model berpemilik tingkat atas, sekaligus bersifat terbuka dan dapat disesuaikan. Ini adalah raksasa untuk matematika, pengkodean, dan pemecahan masalah umum, dengan keamanan yang terintegrasi melalui penyetelan halus adversarial untuk menjaga risiko tetap rendah.
Harga: Terjangkau dan Transparan
Salah satu bagian terbaik dari **GPT-OSS-120B**? Ini hemat biaya, terutama dibandingkan dengan model berpemilik. Berikut rinciannya di seluruh penyedia utama, berdasarkan data terbaru untuk jendela konteks 131K:
- Penyebaran Lokal: Jalankan di perangkat keras Anda sendiri (misalnya, GPU H100 atau pengaturan VRAM 80GB) tanpa biaya API. Pengaturan GMKTEC EVO-X2 berharga ~€2000 dan menggunakan kurang dari 200W, sempurna untuk perusahaan kecil yang memprioritaskan privasi.
- Baseten: $0,10/M token input, $0,50/M token output. Latensi: 0,20 detik, Throughput: 491,1 token/detik. Output maks: 131K token.
- Fireworks: $0,15/M input, $0,60/M output. Latensi: 0,56 detik, Throughput: 258,9 token/detik. Output maks: 33K token.
- Together: $0,15/M input, $0,60/M output. Latensi: 0,28 detik, Throughput: 131,1 token/detik. Output maks: 131K token.
- Parasail: $0,15/M input, $0,60/M output (kuantisasi FP4). Latensi: 0,40 detik, Throughput: 94,3 token/detik. Output maks: 131K token.
- Groq: $0,15/M input, $0,75/M output. Latensi: 0,24 detik, Throughput: 1.065 token/detik. Output maks: 33K token.
- Cerebras: $0,25/M input, $0,69/M output. Latensi: 0,42 detik, Throughput: 1.515 token/detik. Output maks: 33K token. Ideal untuk kebutuhan kecepatan tinggi, mencapai hingga 3.000 token/detik dalam beberapa pengaturan.
Dengan **GPT-OSS-120B**, Anda mendapatkan kinerja tinggi dengan sebagian kecil dari biaya GPT-4 (~$20,00/M token), dengan penyedia seperti Groq dan Cerebras menawarkan throughput yang sangat cepat untuk aplikasi real-time.
Cara Menggunakan GPT-OSS-120B dengan Cline melalui OpenRouter
Ingin memanfaatkan kekuatan **GPT-OSS-120B** untuk proyek pengkodean Anda? Meskipun **Claude Desktop** dan **Claude Code** tidak mendukung integrasi langsung dengan model OpenAI seperti **GPT-OSS-120B** karena ketergantungan mereka pada ekosistem Anthropic, Anda dapat dengan mudah menggunakan model ini dengan **Cline**, ekstensi VS Code sumber terbuka gratis, melalui API **OpenRouter**. Selain itu, **Cursor** baru-baru ini membatasi opsi **Bring Your Own Key (BYOK)** untuk pengguna non-Pro, mengunci fitur seperti mode Agen dan Edit di balik langganan $20/bulan, menjadikan **Cline** alternatif yang lebih fleksibel untuk pengguna BYOK. Berikut cara menyiapkan **GPT-OSS-120B** dengan **Cline** dan **OpenRouter**, langkah demi langkah.
Langkah 1: Dapatkan Kunci API OpenRouter
- Daftar dengan OpenRouter:
- Kunjungi openrouter.ai dan buat akun gratis menggunakan Google atau GitHub.
2. Temukan GPT-OSS-120B:
- Di tab Models, cari “gpt-oss-120b” dan pilih.
3. Buat Kunci API:
- Buka bagian Keys, klik Create API Key, beri nama (misalnya, “GPT-OSS-Cursor”), dan salin. Simpan dengan aman.
Langkah 2: Gunakan Cline di VS Code dengan BYOK
Untuk akses BYOK tanpa batasan, **Cline** (ekstensi VS Code sumber terbuka) adalah alternatif Cursor yang fantastis. Ini mendukung **GPT-OSS-120B** melalui OpenRouter tanpa penguncian fitur. Berikut cara mengaturnya:
- Instal Cline:
- Buka VS Code (code.visualstudio.com).
- Buka panel Ekstensi (
Ctrl+Shift+XatauCmd+Shift+X). - Cari “Cline” dan instal (oleh nickbaumann98, github.com/cline/cline).
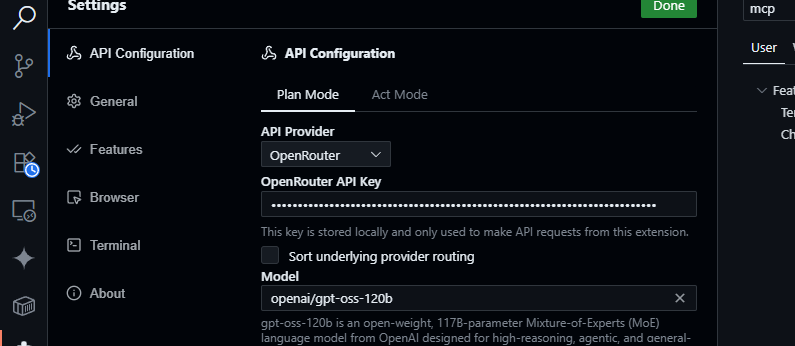
2. Konfigurasi OpenRouter:
- Buka panel Cline (klik ikon Cline di Activity Bar).
- Klik ikon roda gigi di panel Cline.
- Pilih OpenRouter sebagai penyedia.
- Tempelkan kunci API OpenRouter Anda.
- Pilih
openai/gpt-oss-120bsebagai model.
3. Simpan dan Uji:
- Simpan pengaturan. Di panel obrolan Cline, coba:
Buat fungsi JavaScript untuk mengurai data JSON.
- Harapkan respons seperti:
function parseJSON(data) {
try {
return JSON.parse(data);
} catch (e) {
console.error("Invalid JSON:", e.message);
return null;
}
}
- Uji kueri basis kode:
Ringkas src/api/server.js
- Cline akan menganalisis proyek Anda dan mengembalikan ringkasan, memanfaatkan jendela konteks 128K **GPT-OSS-120B**.
Mengapa Cline Lebih Baik dari Cursor atau Claude?
- Tidak Ada Integrasi Claude: **Claude Desktop** dan **Claude Code** terkunci pada model Anthropic (misalnya, Claude 3.5 Sonnet) dan tidak mendukung model OpenAI seperti **GPT-OSS-120B** karena batasan ekosistem.
- Batasan BYOK Cursor: Larangan BYOK terbaru Cursor untuk pengguna non-Pro berarti Anda tidak dapat mengakses mode Agen atau Edit tanpa langganan $20/bulan, bahkan dengan kunci API OpenRouter yang valid. **Cline** tidak memiliki batasan seperti itu, menawarkan akses fitur penuh secara gratis dengan kunci API Anda.
- Privasi dan Kontrol: Cline mengirimkan permintaan langsung ke OpenRouter, melewati server pihak ketiga (tidak seperti perutean AWS Cursor), meningkatkan privasi.
Tips Pemecahan Masalah
- Kunci API Tidak Valid? Verifikasi kunci Anda di dasbor OpenRouter dan pastikan aktif.
- Model Tidak Tersedia? Periksa daftar model OpenRouter untuk openai/gpt-oss-120b. Jika hilang, coba penyedia seperti Fireworks AI atau hubungi dukungan OpenRouter.
- Respons Lambat? Pastikan internet Anda stabil. Untuk kinerja lebih cepat, pertimbangkan model yang lebih ringan seperti GPT-OSS-20B.
- Kesalahan Cline? Perbarui Cline melalui panel Ekstensi dan periksa log di panel Output VS Code.
Mengapa Menggunakan GPT-OSS-120B?
Model **GPT-OSS-120B** adalah pengubah permainan bagi pengembang dan bisnis, menawarkan kombinasi kinerja, fleksibilitas, dan efisiensi biaya yang menarik. Berikut adalah mengapa ia menonjol:
- Kebebasan Sumber Terbuka: Berlisensi di bawah Apache 2.0, Anda dapat menyempurnakan, menyebarkan, atau mengomersialkan **GPT-OSS-120B** tanpa batasan, memberi Anda kendali penuh atas alur kerja AI Anda.
- Penghematan Biaya: Jalankan secara lokal pada satu GPU H100 atau perangkat keras konsumen (VRAM 80GB) tanpa biaya API. Melalui OpenRouter, harga sangat kompetitif yaitu ~$0,50/M token input dan ~$2,00/M token output, sebagian kecil dari $20,00/M token GPT-4, menawarkan penghematan hingga 90% untuk pengguna berat. Penyedia lain seperti Groq ($0,15/M input, $0,75/M output) dan Cerebras ($0,25/M input, $0,69/M output) juga menjaga biaya tetap rendah.
- Kinerja: Ini mencapai hampir setara dengan o4-mini OpenAI, mencetak 94,2% pada MMLU, 96,6% pada matematika AIME, dan 87,3% pada HumanEval untuk pengkodean. Jendela konteks 128K tokennya (300–400 halaman) menangani basis kode atau dokumen besar dengan mudah.
- Penalaran Chain-of-Thought (CoT): Transparansi CoT penuh model memungkinkan Anda melihat penalaran langkah demi langkahnya, membuatnya lebih mudah untuk men-debug output dan mendeteksi bias atau kesalahan. Anda dapat menyesuaikan upaya penalaran (rendah, sedang, tinggi) melalui prompt sistem (misalnya, “Reasoning: high”) untuk tugas-tugas seperti matematika kompleks atau pengkodean, menyeimbangkan kecepatan dan kedalaman. Desain CoT tanpa pengawasan ini membantu peneliti dalam memantau perilaku model tanpa pengawasan langsung, meningkatkan kepercayaan dan keamanan.
- Kemampuan Agen: Dukungan asli untuk penggunaan alat, seperti penjelajahan web dan eksekusi kode Python, membuatnya ideal untuk alur kerja agen. Ini dapat merangkai beberapa panggilan alat (misalnya, 28 pencarian web berturut-turut dalam demo) untuk tugas-tugas kompleks seperti agregasi data atau otomatisasi.
- Privasi: Hosting di tempat (misalnya, melalui Dell Enterprise Hub) untuk kontrol data lengkap, sempurna untuk perusahaan atau pengguna yang sadar privasi.
- Fleksibilitas: Kompatibel dengan OpenRouter, Fireworks AI, Cerebras, dan pengaturan lokal seperti Ollama atau LM Studio, ia berjalan pada berbagai perangkat keras, dari GPU RTX hingga Apple Silicon.
Perbincangan komunitas di X menyoroti kecepatannya (hingga 1.515 token/detik pada Cerebras) dan kecakapan pengkodeannya, dengan pengembang menyukai kemampuannya menangani proyek multi-file dan sifat bobot terbukanya untuk penyesuaian. Baik Anda membangun agen AI atau menyempurnakan untuk tugas-tugas khusus, **GPT-OSS-120B** memberikan nilai yang tak tertandingi.
Kesimpulan
**GPT-OSS-120B** dari Open AI adalah model bobot terbuka revolusioner, memadukan kinerja tingkat atas dengan penyebaran yang hemat biaya. Tolok ukurnya menyaingi model berpemilik, harganya ramah di kantong, dan mudah diintegrasikan dengan Cursor atau Cline melalui API OpenRouter. Baik Anda mengkode, men-debug, atau bernalar melalui masalah kompleks, model ini memberikan hasil. Cobalah, bereksperimenlah dengan jendela konteks 128K-nya, dan beri tahu kami kasus penggunaan keren Anda di komentar—saya sangat ingin tahu!
Untuk detail lebih lanjut, lihat repositori di github.com/openai/gpt-oss atau pengumuman Open AI di openai.com.
Ingin platform All-in-One terintegrasi untuk Tim Pengembang Anda agar dapat bekerja sama dengan produktivitas maksimal?
Apidog memenuhi semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!