
Pengembang yang membangun aplikasi cerdas semakin menuntut model yang menangani beragam jenis data tanpa mengorbankan kecepatan atau akurasi. GLM-4.6V memenuhi kebutuhan ini secara langsung. Z.ai merilis seri ini sebagai model bahasa besar multimodal sumber terbuka, memadukan teks, gambar, video, dan file menjadi interaksi yang mulus. API memberdayakan Anda untuk mengintegrasikan kemampuan ini langsung ke dalam proyek Anda, baik untuk analisis dokumen maupun agen pencarian visual.
Saat kita memeriksa arsitektur, metode akses, dan harga GLM-4.6V, Anda akan melihat bagaimana ia mengungguli rekan-rekannya dalam tolok ukur. Selain itu, kiat integrasi dengan alat seperti Apidog akan membantu Anda menerapkan lebih cepat. Mari kita mulai dengan desain inti model.
Memahami GLM-4.6V: Arsitektur dan Kemampuan Inti
Insinyur Z.ai GLM-4.6V untuk memproses input multimodal secara native, menghasilkan respons teks terstruktur. Seri model ini mencakup dua varian: GLM-4.6V unggulan (106B parameter) untuk tugas berkinerja tinggi dan GLM-4.6V-Flash (9B parameter) untuk penerapan lokal yang efisien. Keduanya mendukung jendela konteks 128K token, memungkinkan analisis dokumen ekstensif—hingga 150 halaman—atau video berdurasi satu jam dalam satu kali jalan.

Inti dari GLM-4.6V menggabungkan encoder visual yang selaras dengan protokol konteks panjang. Penyelarasan ini memastikan model mempertahankan detail halus di seluruh input. Misalnya, ia menangani urutan teks-gambar yang saling terkait, mendasarkan respons pada elemen visual tertentu seperti koordinat objek dalam foto. Panggilan fungsi native membedakannya; pengembang memanggil alat secara langsung dengan parameter gambar, dan model menginterpretasikan umpan balik visual.
Selain itu, pembelajaran penguatan menyempurnakan pemanggilan alat. Model belajar untuk merangkai tindakan, seperti menanyakan alat pencarian dengan tangkapan layar dan menalar hasilnya. Ini menghasilkan alur kerja ujung ke ujung, dari persepsi hingga pengambilan keputusan. Akibatnya, aplikasi memperoleh otonomi tanpa pemrosesan pasca yang rapuh.

Dalam praktiknya, fitur-fitur ini diterjemahkan ke dalam penanganan data dunia nyata yang kuat. Model ini unggul dalam pembuatan teks kaya, menghasilkan keluaran gambar-teks yang saling terkait untuk laporan atau infografis. Ia juga mendukung Extended Model Context Protocol (MCP), memungkinkan input multimodal berbasis URL untuk pemrosesan yang terukur.
Tolok Ukur dan Kinerja: Mengukur GLM-4.6V Terhadap Rekan-rekan
Data kuantitatif memvalidasi keunggulan GLM-4.6V. Pada MMBench, ia mencetak 82,5% dalam QA multimodal, mengungguli LLaVA-1.6 sebesar 4 poin. MathVista mengungkapkan akurasi 68% dalam persamaan visual, berkat encoder yang selaras.
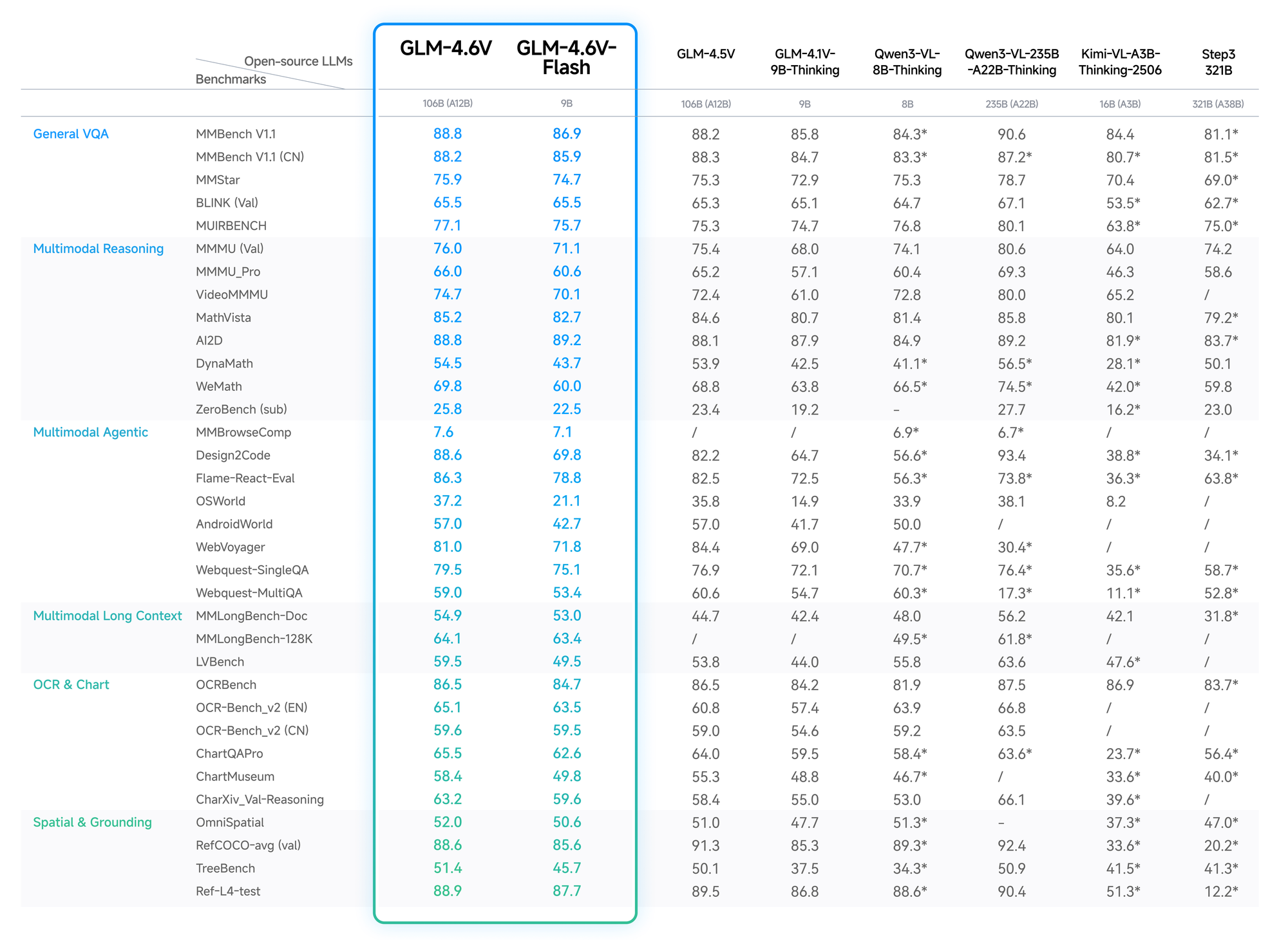
Tes OCRBench menghasilkan 91% untuk ekstraksi teks dari gambar yang terdistorsi, melampaui GPT-4V dalam peringkat sumber terbuka. Evaluasi konteks panjang, seperti Video-MME, mencapai 75% untuk klip berdurasi satu jam, mempertahankan detail di seluruh bingkai.
Varian Flash mengorbankan sedikit akurasi (penurunan 2-3%) untuk percepatan 5x, ideal untuk aplikasi real-time. Blog Z.ai merinci hal ini, dengan pengaturan yang dapat direproduksi di Hugging Face.
Dengan demikian, pengembang memilih GLM-4.6V untuk kinerja yang andal dan hemat biaya.
Fitur Utama Seri Model GLM-4.6V
GLM-4.6V mengemas fitur-fitur canggih yang meningkatkan AI multimodal. Pertama, modalitas inputnya mencakup teks, gambar, video, dan file, dengan output yang berfokus pada pembuatan teks yang tepat. Pengembang menghargai fleksibilitas: unggah PDF keuangan, dan model mengekstrak tabel, menalar tren, dan menyarankan visualisasi.
Penggunaan alat native merupakan terobosan. Tidak seperti model tradisional yang memerlukan orkestrasi eksternal, GLM-4.6V menyematkan panggilan fungsi. Anda mendefinisikan alat dalam permintaan—misalnya, pemotong untuk gambar—dan model meneruskan data visual sebagai parameter. Kemudian memahami hasilnya, mengulang jika diperlukan. Ini menutup lingkaran untuk tugas-tugas seperti pencarian web visual: mengenali maksud dari gambar kueri, merencanakan pengambilan, menggabungkan hasil, dan mengeluarkan wawasan yang beralasan.
Selain itu, konteks 128K memberdayakan analisis bentuk panjang. Proses 200 slide dari presentasi; model merangkum tema-tema utama sambil memberi stempel waktu pada peristiwa video, seperti gol dalam pertandingan sepak bola. Untuk pengembangan frontend, ia mereplikasi UI dari tangkapan layar, menghasilkan kode HTML/CSS/JS yang akurat piksel. Editan bahasa alami menyusul, menyempurnakan prototipe secara interaktif.
Varian Flash mengoptimalkan latensi. Dengan 9B parameter, ia berjalan pada perangkat keras konsumen melalui mesin inferensi vLLM atau SGLang. Bobot yang tersedia di Hugging Face memungkinkan penyetelan halus, meskipun koleksi tersebut berfokus pada model dasar tanpa statistik ekstensif. Secara keseluruhan, fitur-fitur ini menempatkan GLM-4.6V sebagai tulang punggung serbaguna untuk agen dalam intelijen bisnis atau alat kreatif.
Cara Mengakses API GLM-4.6V: Pengaturan Langkah demi Langkah
Mengakses API GLM-4.6V terbukti mudah, berkat antarmuka yang kompatibel dengan OpenAI. Mulailah dengan mendaftar di portal pengembang Z.ai (z.ai). Buat kunci API di bawah dasbor akun Anda—token Bearer ini mengautentikasi semua permintaan.
Endpoint dasar berada di https://api.z.ai/api/paas/v4/chat/completions. Gunakan metode POST dengan payload JSON. Header autentikasi meliputi Authorization: Bearer <kunci-api-Anda> dan Content-Type: application/json. Struktur array pesan percakapan, mendukung konten multimodal.
Misalnya, kirim URL gambar bersama dengan prompt teks. Payload menentukan "model": "glm-4.6v" atau "glm-4.6v-flash". Aktifkan langkah-langkah berpikir dengan "thinking": {"type": "enabled"} untuk jejak penalaran yang transparan. Mode streaming menambahkan "stream": true untuk respons real-time melalui server-sent events.
Berikut adalah integrasi Python dasar menggunakan pustaka requests:
import requests
import json
url = "https://api.z.ai/api/paas/v4/chat/completions"
headers = {
"Authorization": "Bearer KUNCI_API_ANDA",
"Content-Type": "application/json"
}
payload = {
"model": "glm-4.6v",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {"url": "https://example.com/image.jpg"}
},
{"type": "text", "text": "Jelaskan elemen kunci dalam gambar ini dan sarankan perbaikannya."}
]
}
],
"thinking": {"type": "enabled"}
}
response = requests.post(url, headers=headers, data=json.dumps(payload))
print(response.json())
Kode ini mengambil deskripsi dengan alasan. Untuk video atau file, perluas array konten serupa—URL atau pengodean base64 berfungsi. Batas tarif berlaku berdasarkan paket Anda; pantau melalui dasbor.
Apidog meningkatkan proses ini. Impor spesifikasi OpenAPI dari dokumen Z.ai ke Apidog, lalu buat permintaan secara visual. Uji panggilan fungsi tanpa kode, memvalidasi payload sebelum produksi. Akibatnya, Anda berulang lebih cepat, menangkap kesalahan lebih awal.
Akses lokal melengkapi penggunaan cloud. Unduh bobot dari koleksi GLM-4.6V Hugging Face dan layani melalui kerangka kerja yang kompatibel. Penyiapan ini cocok untuk aplikasi yang sensitif privasi, meskipun membutuhkan sumber daya GPU untuk model 106B.
Rincian Harga: Skala Hemat Biaya dengan GLM-4.6V
Z.ai menyusun harga GLM-4.6V untuk menyeimbangkan aksesibilitas dan kinerja. Model unggulan membebankan biaya $0,6 per juta token input dan $0,9 per juta token output. Model berjenjang ini memperhitungkan kompleksitas multimodal—gambar dan video mengonsumsi token berdasarkan resolusi dan panjang.
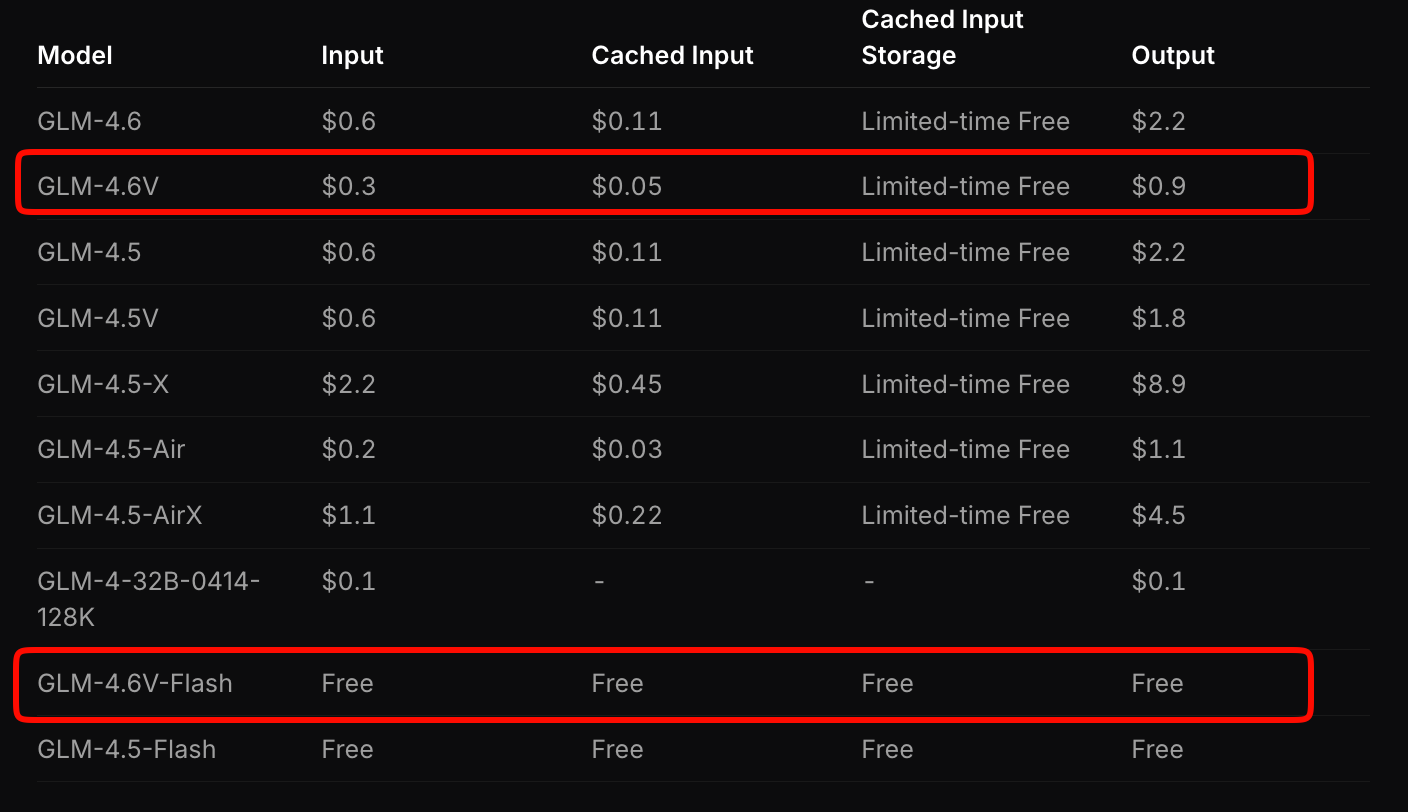
Sebaliknya, GLM-4.6V-Flash menawarkan akses gratis, ideal untuk prototipe atau penerapan di edge. Tidak ada biaya token yang berlaku, meskipun biaya inferensi terkait dengan perangkat keras Anda. Promosi waktu terbatas melipatgandakan kuota penggunaan dengan sepertujuh biaya untuk tingkat berbayar, membuat eksperimen menjadi terjangkau.
Bandingkan ini dengan pesaing: GLM-4.6V mengalahkan API multimodal serupa sebesar 20-30% sambil memberikan tolok ukur yang lebih unggul. Untuk aplikasi bervolume tinggi, hitung biaya melalui alat estimasi Z.ai. Masukkan beban kerja sampel—misalnya, 100 analisis dokumen harian—dan ia memproyeksikan pengeluaran bulanan.
Selain itu, bobot sumber terbuka mengurangi biaya jangka panjang. Setel halus pada data Anda untuk mengurangi ketergantungan pada panggilan cloud. Secara keseluruhan, harga ini memungkinkan startup untuk menskalakan tanpa kendala anggaran.
Mengintegrasikan API GLM-4.6V dengan Apidog: Optimalisasi Alur Kerja Praktis
Apidog mengubah integrasi GLM-4.6V dari pekerjaan manual yang membosankan menjadi kolaborasi yang efisien. Sebagai klien API dan alat desain, ia mengimpor spesifikasi Z.ai, secara otomatis menghasilkan template permintaan. Anda menarik dan melepaskan payload multimodal, mempratinjau respons, dan mengekspor ke cuplikan kode dalam Python, Node.js, atau cURL.
Mulailah dengan membuat proyek baru di Apidog. Tempel URL endpoint dan autentikasi dengan kunci Anda. Untuk tugas grounding visual, buat permintaan: tambahkan jenis image_url, masukkan prompt koordinat, dan tekan kirim. Apidog memvisualisasikan output, menyoroti langkah-langkah berpikir.
Kolaborasi bersinar di sini. Bagikan koleksi dengan tim; kendalikan versi endpoint saat Anda menambahkan alat. Variabel lingkungan mengamankan kunci di seluruh dev, staging, dan prod. Akibatnya, siklus deployment menjadi lebih pendek—uji rantai agen penuh dalam hitungan menit.
Perluas ke pemantauan: Apidog mencatat latensi dan kesalahan, menunjukkan hambatan dalam aliran multimodal. Pasangkan dengan GLM-4.6V-Flash untuk tes lokal gratis, lalu skalakan ke cloud. Pengembang melaporkan prototipe 40% lebih cepat dengan alat semacam itu.
Studi Kasus Dunia Nyata: Menerapkan GLM-4.6V dalam Produksi
GLM-4.6V bersinar di industri yang banyak menggunakan dokumen. Analis keuangan mengunggah laporan; model menguraikan grafik, menghitung rasio, dan menghasilkan ringkasan eksekutif dengan visual yang disematkan. Satu perusahaan mengurangi waktu analisis dari jam menjadi menit, memanfaatkan konteks 128K untuk pengajuan tahunan.
Dalam e-commerce, agen pencarian visual aktif. Pelanggan mengunggah foto produk; GLM-4.6V merencanakan kueri, mengambil kecocokan, dan menalar atribut seperti varian warna. Ini meningkatkan konversi sebesar 15%, menurut pengadopsi awal.

Tim frontend mempercepat prototipe. Masukkan tangkapan layar; terima kode yang dapat diedit. Berulang dengan prompt seperti "Tambahkan navbar responsif." Fidelitas tingkat piksel model meminimalkan revisi, memangkas desain-ke-deploy menjadi dua.

Platform video mendapat manfaat dari penalaran temporal. Ringkas kuliah dengan stempel waktu atau deteksi peristiwa dalam feed pengawasan. Penggunaan alat native terintegrasi dengan basis data, secara otomatis menandai anomali.
Kasus-kasus ini menunjukkan keserbagunaan GLM-4.6V. Namun, keberhasilan bergantung pada rekayasa prompt—buat instruksi yang jelas untuk memaksimalkan akurasi.
Tantangan dan Praktik Terbaik untuk Penggunaan API GLM-4.6V
Meskipun memiliki kekuatan, model multimodal menghadapi hambatan. Input resolusi tinggi meningkatkan jumlah token, menaikkan biaya—kompres gambar ke 512x512 piksel terlebih dahulu. Overflow konteks berisiko menimbulkan halusinasi; bagi video panjang menjadi segmen-segmen.
Praktik terbaik meredakan hal ini. Gunakan mode berpikir untuk debugging; ini mengekspos langkah-langkah perantara. Validasi output alat dengan pernyataan dalam kode Anda. Untuk pengguna Apidog, siapkan tes otomatis pada endpoint untuk menegakkan skema.
Pantau kuota dengan cermat—Flash gratis menghindari kejutan, tetapi tingkat berbayar membutuhkan anggaran. Terakhir, setel halus pada data domain melalui bobot terbuka untuk meningkatkan kekhususan.
Kesimpulan: Tingkatkan Proyek Anda dengan GLM-4.6V Hari Ini
GLM-4.6V mendefinisikan ulang AI multimodal melalui alat native, konteks luas, dan aksesibilitas terbuka. API-nya, dengan harga kompetitif $0,6/M input untuk model penuh dan gratis untuk Flash, terintegrasi dengan lancar dengan platform seperti Apidog. Dari agen dokumen hingga generator UI, ia mendorong inovasi.
Terapkan wawasan ini sekarang: dapatkan kunci API Anda, uji di Apidog, dan bangun. Masa depan AI mendukung mereka yang memanfaatkan kemampuan seperti itu lebih awal. Aplikasi apa yang akan Anda transformasikan selanjutnya?