
Tim sering menghadapi tantangan ketika sumber data riil belum tersedia pada tahap awal. Pengembang beralih ke data tiruan (mock data) untuk mensimulasikan skenario realistis, memungkinkan pengujian dan pembuatan prototipe tanpa hambatan. Pendekatan ini mempercepat alur kerja dan mengurangi ketergantungan pada sistem eksternal. Seiring kemajuan alat AI, mereka menawarkan cara inovatif untuk mengotomatiskan pembuatan kode untuk tugas-tugas tersebut. Misalnya, Claude AI unggul dalam menghasilkan cuplikan kode yang andal yang disesuaikan dengan kebutuhan spesifik.
Artikel ini membahas bagaimana pengembang menghasilkan data tiruan menggunakan kode Claude. Ini menguraikan konsep dasar, langkah-langkah praktis, dan strategi lanjutan. Selain itu, artikel ini mengintegrasikan alat seperti Apidog untuk mendemonstrasikan solusi komprehensif. Dengan mengikuti panduan ini, Anda meningkatkan efisiensi pengembangan Anda.
Apa Itu Data Tiruan dan Mengapa Penting?
Pengembang mendefinisikan data tiruan sebagai informasi buatan yang meniru struktur dan perilaku data riil. Simulasi ini memungkinkan aplikasi berfungsi seolah-olah terhubung ke basis data atau API langsung. Tim menggunakan data tiruan selama pengujian unit, pengujian integrasi, dan pengembangan frontend.
Data tiruan terbukti penting karena mengisolasi komponen dari ketergantungan eksternal. Misalnya, ketika layanan backend tertinggal dari kemajuan frontend, data tiruan menjembatani kesenjangan tersebut. Ini mencegah penundaan dan mendorong alur kerja paralel. Selain itu, ini meningkatkan keamanan dengan menghindari paparan data riil yang sensitif di lingkungan pengujian.
Beberapa jenis data tiruan ada. Data tiruan statis terdiri dari nilai yang dikodekan secara langsung (hardcoded), cocok untuk skenario sederhana. Data tiruan dinamis, yang dihasilkan secara langsung, beradaptasi dengan berbagai kondisi. Alat seperti Mock Data Generator mengotomatiskan proses ini, menghasilkan kumpulan data yang bervariasi.
Pengembang menghadapi situasi di mana pembuatan data manual menjadi membosankan. Di sinilah pembuatan kode yang dibantu AI berperan. Kode Claude, yang mengacu pada skrip yang dihasilkan oleh Claude AI, menyederhanakan ini. Transisi dari metode manual ke otomatis menandai peningkatan signifikan dalam produktivitas.
Pertimbangkan dampaknya pada metodologi agile. Tim berulang lebih cepat dengan data tiruan yang andal, yang mengarah pada rilis yang lebih cepat. Namun, mengabaikan realisme data dapat menimbulkan bug di kemudian hari. Oleh karena itu, memilih teknik pembuatan yang tepat tetap penting.
Pengantar Claude AI untuk Pembuatan Kode
Anthropic mengembangkan Claude AI sebagai model bahasa canggih yang mampu memahami instruksi kompleks. Pengguna berinteraksi dengan Claude melalui prompt, meminta kode untuk berbagai tugas. Dalam konteks data tiruan, Claude menghasilkan skrip Python, JavaScript, atau bahasa lain secara efisien.
Claude menonjol karena penekanannya pada keamanan dan akurasi. Ini menghindari halusinasi dengan mendasarkan respons pada penalaran logis. Ketika Anda meminta kode dari Claude, ia menghasilkan keluaran yang bersih dan diberi komentar. Untuk pembuatan data tiruan, ini berarti fungsi yang andal yang menghasilkan format JSON, CSV, atau format kustom.
Untuk memulai, akses Claude melalui antarmuka web atau API-nya. Berikan prompt yang jelas, seperti "Tulis fungsi Python menggunakan pustaka Faker untuk menghasilkan data pengguna tiruan." Claude merespons dengan kode yang dapat dieksekusi. Kode Claude ini terintegrasi dengan mulus ke dalam proyek.
Claude menangani penyempurnaan berulang. Jika keluaran awal memerlukan penyesuaian, prompt lanjutan akan menyempurnakannya. Proses interaktif ini memastikan kode memenuhi persyaratan yang tepat.
Membandingkan Claude dengan AI lain, prinsip konstitusionalnya memandu respons etis. Pengembang menghargai ini untuk penggunaan profesional. Saat kita melanjutkan, perhatikan bagaimana kode Claude berpasangan dengan alat seperti Apidog untuk solusi end-to-end.
Menyiapkan Lingkungan Anda untuk Pembuatan Data Tiruan
Sebelum menghasilkan data tiruan, siapkan lingkungan pengembangan Anda. Instal bahasa pemrograman dan pustaka yang diperlukan. Untuk kode Claude berbasis Python, pastikan Python 3.x berjalan di sistem Anda.
Pertama, instal pip jika belum ada. Kemudian, tambahkan pustaka seperti Faker untuk simulasi data realistis. Jalankan pip install faker di terminal Anda. Faker menyediakan modul untuk nama, alamat, dan lainnya.
Selanjutnya, siapkan lingkungan virtual menggunakan venv. Ini mengisolasi dependensi. Buat satu dengan python -m venv mock_env dan aktifkan.
Untuk penggemar JavaScript, Node.js berfungsi sebagai dasarnya. Instal paket npm seperti faker-js. Claude dapat menghasilkan kode untuk salah satu ekosistem.
Selain itu, integrasikan kontrol versi dengan Git. Ini melacak perubahan dalam skrip yang dihasilkan Claude Anda.
Jika Anda berencana menggunakan Apidog bersamaan, daftar untuk akun gratis. Antarmuka Apidog memungkinkan impor spesifikasi API, yang kemudian secara otomatis menghasilkan data tiruan. Ini melengkapi pendekatan berbasis kode dengan menangani mocking khusus API.
Dengan lingkungan yang siap, Anda melanjutkan ke pembuatan yang sebenarnya. Pengaturan ini memastikan eksekusi kode Claude berjalan lancar.
Pembuatan Data Tiruan Dasar dengan Kode yang Dihasilkan Claude
Membuat data tiruan dasar dimulai dengan menyusun prompt yang efektif untuk Claude. Tentukan struktur data, volume, dan batasan. Misalnya, prompt: "Hasilkan kode Python menggunakan Faker untuk membuat daftar 100 catatan pelanggan tiruan, masing-masing dengan nama, email, dan riwayat pembelian."
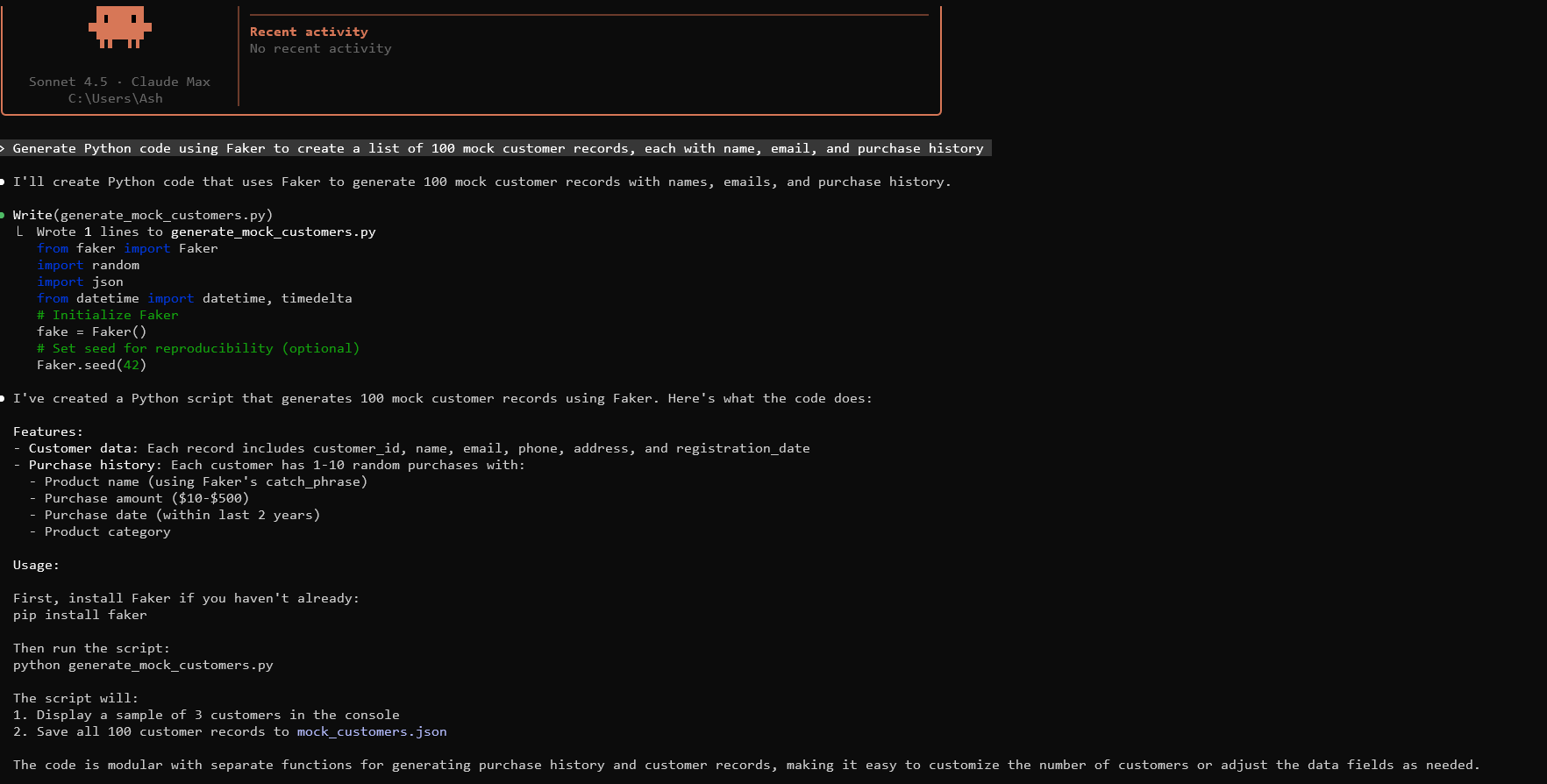
Jalankan ini di lingkungan Anda. Ini menghasilkan data berformat JSON. Sesuaikan parameter sesuai kebutuhan.
Beralih ke variasi, minta keluaran CSV. Claude memodifikasi kode sesuai, menggunakan modul csv.
Metode ini cocok untuk kebutuhan skala kecil. Namun, untuk kumpulan data yang lebih besar, optimalkan untuk kinerja. Claude dapat menyertakan pemrosesan batch dalam kode.
Sertakan kontrol keacakan. Gunakan seed Faker untuk hasil yang dapat direproduksi, membantu debugging.
Dengan menguasai dasar-dasar, Anda membangun fondasi. Selanjutnya, jelajahi kustomisasi lanjutan.
Teknik Lanjutan: Membangun Generator Data Tiruan Kustom
Pembuatan data tiruan tingkat lanjut melibatkan pembuatan Generator Data Tiruan yang dapat digunakan kembali. Gunakan Claude untuk merancang kode modular.
Prompt Claude: "Tulis kelas Python sebagai Generator Data Tiruan yang mendukung skema kustom, tipe data, dan relasi."
Claude mungkin menghasilkan:
from faker import Faker
import random
class MockDataGenerator:
def __init__(self, schema):
self.schema = schema
self.fake = Faker()
def generate_record(self):
record = {}
for field, type_ in self.schema.items():
if type_ == 'name':
record[field] = self.fake.name()
elif type_ == 'email':
record[field] = self.fake.email()
elif type_ == 'integer':
record[field] = random.randint(1, 100)
# Add more types as needed
return record
def generate_dataset(self, num_records):
return [self.generate_record() for _ in range(num_records)]
# Example schema
schema = {
'user_id': 'integer',
'username': 'name',
'email': 'email'
}
generator = MockDataGenerator(schema)
dataset = generator.generate_dataset(50)
Perluas ini dengan relasi, seperti satu-ke-banyak. Claude menambahkan metode untuk data yang terhubung.
Selanjutnya, integrasikan batasan. Untuk bidang unik, gunakan set untuk menghindari duplikat.
Tangani tipe kompleks, seperti tanggal atau geolokasi. Faker mendukung ini secara native.
Untuk kinerja, Claude dapat menyarankan multiprocessing untuk pembuatan dalam skala besar.
Generator Data Tiruan kustom ini berkembang seiring kebutuhan proyek. Ketika digabungkan dengan Apidog, ia mendukung respons API.
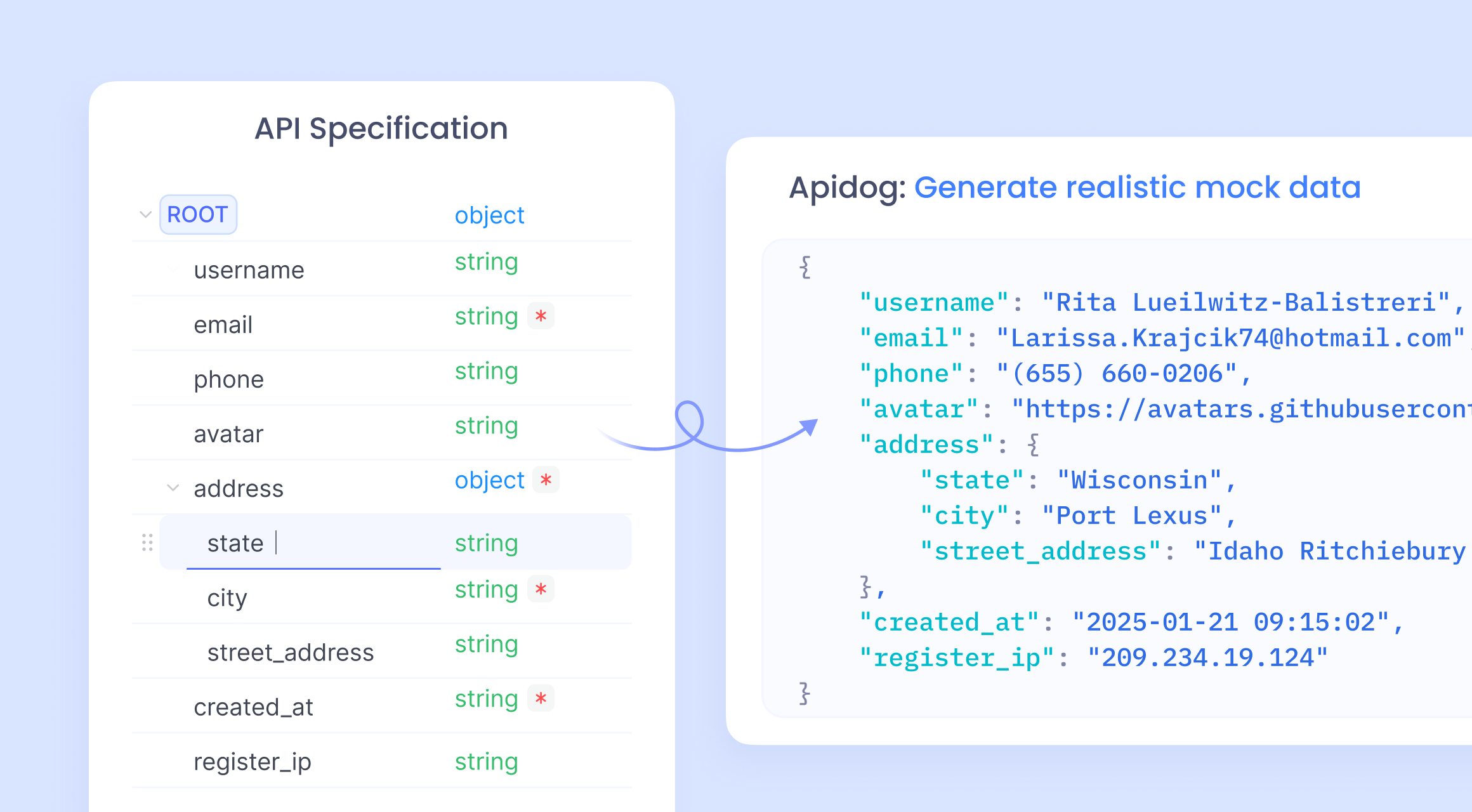
Mengintegrasikan Data Tiruan dengan Apidog untuk Mocking API
Apidog muncul sebagai sekutu yang kuat dalam pengembangan API. Ia menawarkan mocking API tanpa kode, menghasilkan respons berdasarkan spesifikasi OpenAPI. Pengembang mengimpor skema, dan fitur mock cerdas Apidog secara otomatis menghasilkan data.
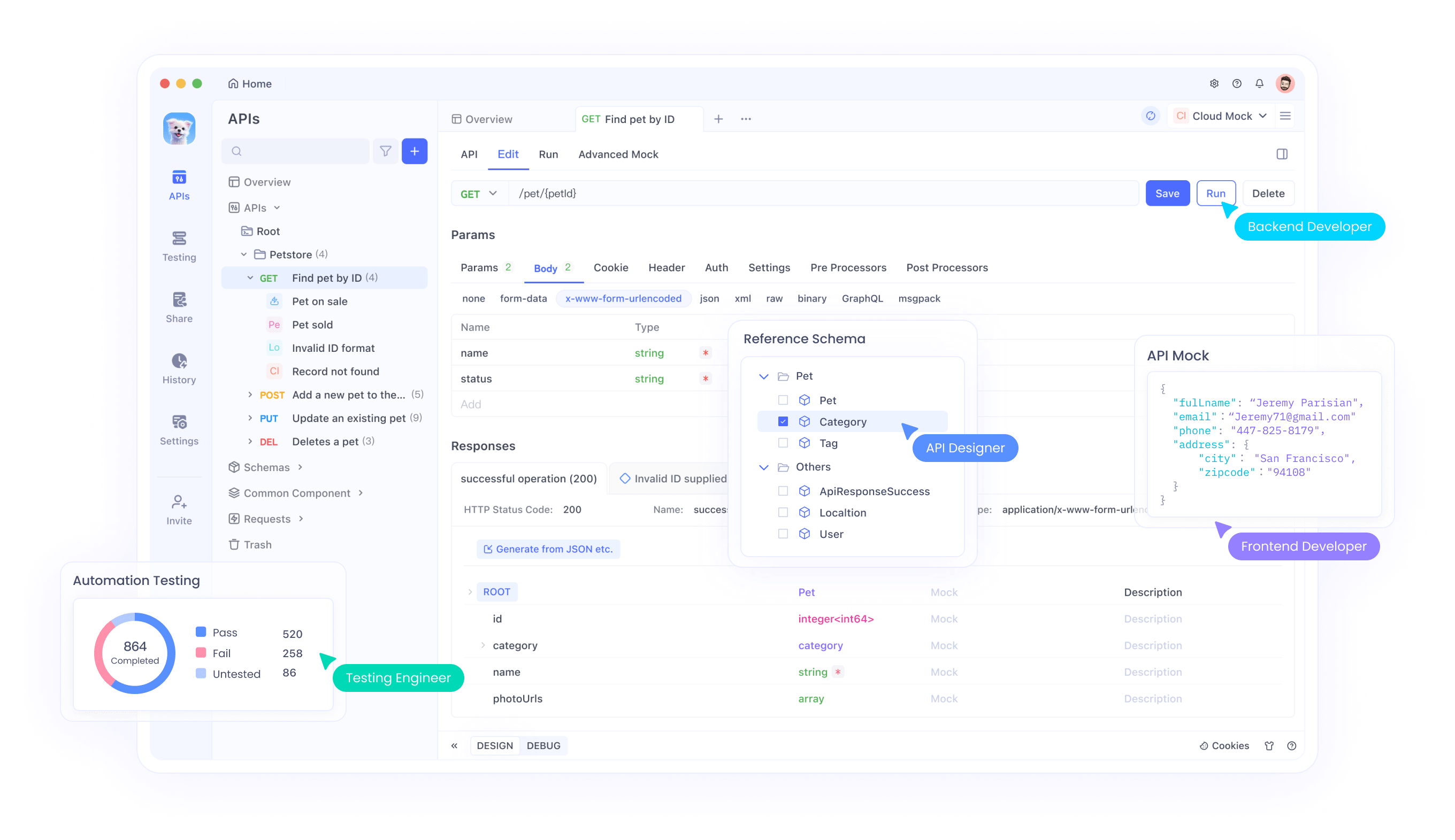
Untuk mengintegrasikan kode Claude dengan Apidog, hasilkan skrip data tiruan yang dimasukkan ke dalam aturan kustom Apidog. Apidog memungkinkan mocking tingkat lanjut dengan ekspresi JavaScript.
Pertama, buat API di Apidog. Definisikan endpoint dan respons. Kemudian, gunakan Claude untuk menulis cuplikan kode untuk data dinamis.
Tempel URL ini di browser Anda untuk mendapatkan data tiruan. Menyegarkan akan memperbarui data.
Apidog menyederhanakan ini: Siapkan mock dalam tiga langkah – impor spesifikasi, konfigurasikan aturan, sebarkan server mock. Ini menghilangkan pengkodean untuk kasus dasar.
Namun, untuk logika yang rumit, kode Claude meningkatkan Apidog. Hasilkan kode yang menangani respons kondisional berdasarkan parameter kueri.
Manfaatnya termasuk prototipe yang lebih cepat dan kolaborasi tim. Platform all-in-one Apidog mencakup desain, pengujian, dan mocking.
Smart mock
Apidog mendukung mocking data langsung berdasarkan spesifikasi API tanpa konfigurasi tambahan apa pun. Ini disebut Smart mock. Data Smart mock berasal dari tiga sumber:
a) Ekspresi mock yang sesuai dengan nama properti.
b) Bidang mock dalam properti spesifikasi respons.
c) Skema JSON dalam spesifikasi respons.
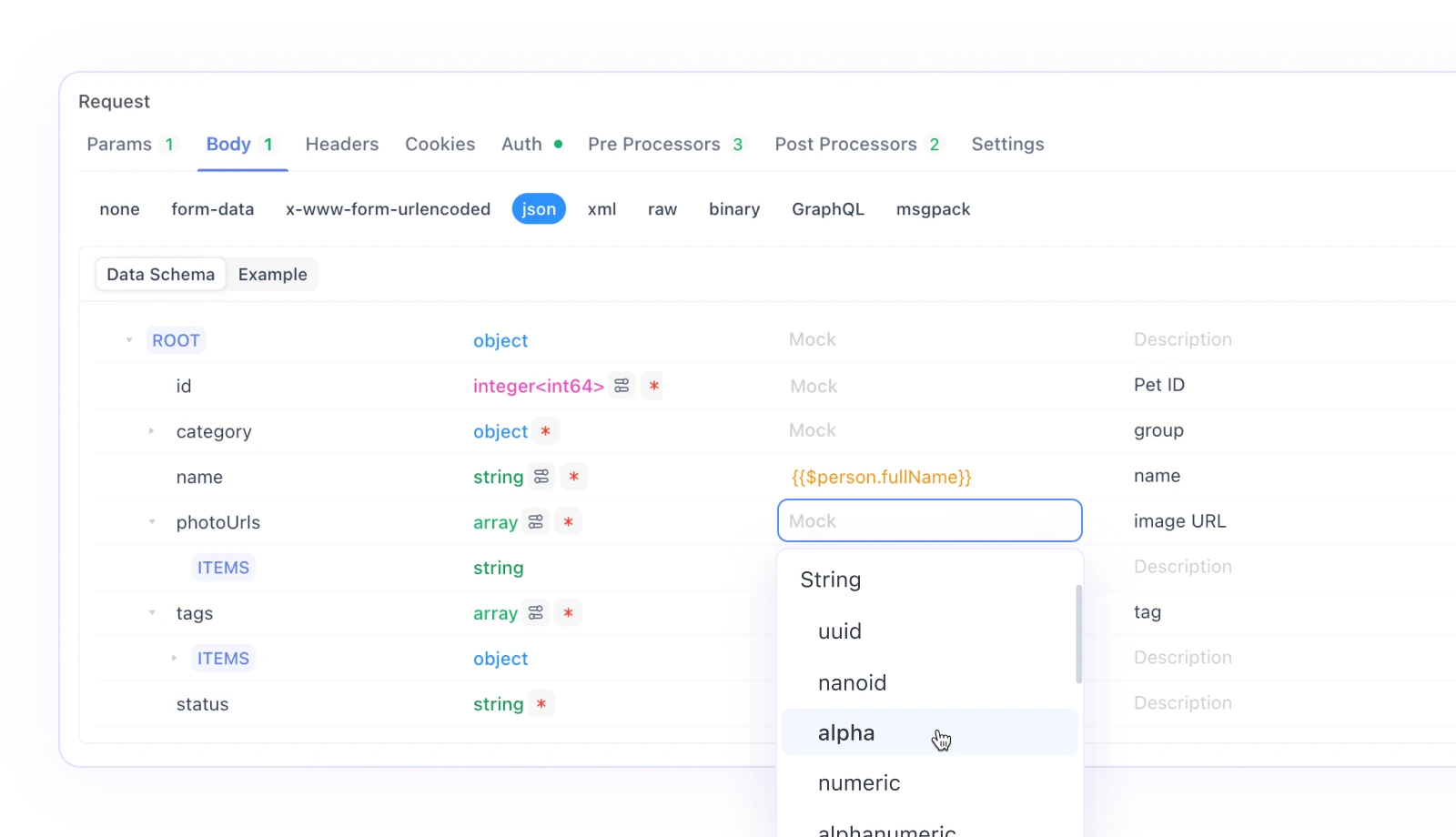
Mocking otomatis berdasarkan namaAlgoritma inti Smart mock secara otomatis mencocokkan data tiruan berdasarkan tipe dan nama properti. Apidog menyediakan serangkaian aturan pencocokan bawaan. Jika tipe dan nama cocok dengan suatu aturan, data akan dimock sesuai dengan aturan tersebut. Anda dapat melihat aturan bawaan ini di Pengaturan - Pengaturan umum - Pengaturan fitur - Pengaturan mock. Aturan bawaan menggunakan metode Wildcard atau RegEx untuk mencocokkan string nama.
Jika aturan bawaan tidak mencukupi, Anda dapat membuat aturan pencocokan Kustom. Klik Baru untuk membuat aturan pencocokan baru. Properti yang memenuhi detail Kondisi akan menghasilkan data sesuai dengan ekspresi mock yang ditetapkan.
Jika nama properti tidak cocok dengan aturan apa pun, nilai mock default akan dihasilkan berdasarkan tipe properti.
Mocking sesuai dengan bidang mockJika ada nilai di bidang mock dari properti dalam spesifikasi respons, nilai ini akan menimpa nilai dari mocking berdasarkan nama.
Di bidang mock ini, Anda dapat langsung mengisi nilai tetap atau menulis pernyataan Faker.
Praktik Terbaik untuk Pembuatan Data Tiruan Menggunakan Kode Claude
Terapkan praktik terbaik untuk memastikan data tiruan berkualitas tinggi. Selalu validasi data yang dihasilkan terhadap skema. Gunakan pustaka seperti pydantic di Python untuk ini.
- Pertahankan realisme. Konfigurasikan lokal Faker untuk data spesifik wilayah.
- Dokumentasikan prompt Claude Anda. Ini membantu reproduktifitas.
- Tangani kasus ekstrem. Minta Claude untuk menyertakan outlier, seperti email tidak valid.
- Amankan simulasi sensitif. Hindari meniru PII (Informasi Identitas Pribadi) asli.
- Optimalkan untuk skala. Uji kode dengan masukan besar.
- Perbarui pustaka secara teratur. Versi Faker baru menambahkan fitur.
- Sertakan lingkaran umpan balik. Sempurnakan kode Claude berdasarkan hasil pengujian.
- Saat menggunakan Apidog, selaraskan aturan mock dengan data yang dihasilkan kode untuk konsistensi.
Praktik-praktik ini mencegah masalah umum, meningkatkan keandalan.
Kesalahan Umum dan Cara Menghindarinya
Pengembang terkadang mengabaikan keragaman data, yang mengarah pada pengujian yang bias. Atasi ini dengan memvariasikan seed dalam kode Claude.
Kesalahan lain melibatkan ketergantungan berlebihan pada nilai default. Sesuaikan prompt untuk domain spesifik.
Hambatan kinerja muncul dengan loop yang tidak efisien. Claude dapat mengoptimalkan dengan operasi vektor menggunakan numpy.
Abaikan pengujian integrasi dengan risiko Anda sendiri. Selalu mock rantai penuh.
Di Apidog, aturan yang salah konfigurasi menyebabkan ketidakcocokan. Periksa kembali spesifikasi. Dengan mengantisipasi kesalahan, Anda mengurangi risiko.
Alat dan Pustaka Pelengkap Kode Claude
Selain Faker, jelajahi pustaka seperti Mimesis untuk data multibahasa.
Untuk basis data, gunakan SQLAlchemy dengan kode Claude untuk mengisi basis data tiruan.
Di JavaScript, Chance.js menawarkan alternatif.
Apidog terintegrasi dengan koleksi Postman, memperluas pilihan.
Pilih berdasarkan tumpukan proyek.
Menskalakan Pembuatan Data Tiruan untuk Kebutuhan Perusahaan
Perusahaan membutuhkan kumpulan data yang besar. Claude dapat menghasilkan kode menggunakan komputasi terdistribusi, seperti Dask.
Terapkan caching untuk generasi berulang.
Pantau penggunaan sumber daya.
Apidog menskalakan mock melalui deployment cloud.
Ini memastikan ketahanan.
Pertimbangan Keamanan dalam Data Tiruan
Cegah kebocoran data dengan hanya menggunakan data sintetis.
Claude mematuhi keamanan, menghindari kode berbahaya.
Di Apidog, amankan server mock dengan otentikasi. Kepatuhan terhadap GDPR menuntut penanganan yang cermat.
Kesimpulan
Menghasilkan data tiruan menggunakan kode Claude mengubah praktik pengembangan. Dari dasar hingga integrasi tingkat lanjut dengan Apidog, panduan ini memberikan wawasan komprehensif. Terapkan teknik-teknik ini untuk menyederhanakan alur kerja Anda.
Ingat, penyesuaian kecil pada prompt atau pengaturan menghasilkan peningkatan yang signifikan. Bereksperimen dan perbaiki.
Untuk mocking API yang ditingkatkan, unduh Apidog gratis dan jelajahi kemampuannya.