
Ranah kecerdasan buatan terus mengalami ekspansi pesat, dengan Large Language Models (LLMs) semakin menunjukkan kemampuan kognitif yang canggih. Di antara model-model ini, FractalAIResearch/Fathom-R1-14B muncul sebagai model yang patut diperhatikan, menampung sekitar 14,8 miliar parameter. Model ini secara khusus direkayasa oleh Fractal AI Research untuk unggul dalam tugas penalaran matematis dan umum yang kompleks. Yang membedakan Fathom-R1-14B adalah kemampuannya untuk mencapai tingkat kinerja yang tinggi ini dengan efisiensi biaya yang luar biasa dan dalam jendela konteks token 16.384 (16K) yang praktis. Artikel ini menawarkan tinjauan teknis Fathom-R1-14B, merinci pengembangannya, arsitektur, proses pelatihan, kinerja yang diukur dengan benchmark, dan memberikan panduan terfokus untuk implementasi praktisnya berdasarkan metode yang sudah mapan.
Fractal AI: Inovator di Balik Model

Fathom-R1-14B adalah produk dari Fractal AI Research, divisi penelitian dari Fractal, sebuah perusahaan AI dan analitik terkemuka yang berkantor pusat di Mumbai, India. Fractal telah mendapatkan reputasi global dalam memberikan solusi kecerdasan buatan dan analitik canggih kepada perusahaan-perusahaan Fortune 500. Penciptaan Fathom-R1-14B sangat selaras dengan ambisi India yang berkembang di sektor kecerdasan buatan.
Aspirasi AI India
Pengembangan model ini sangat signifikan dalam konteks IndiaAI Mission. Srikanth Velamakanni, Co-founder, Group Chief Executive & Vice-Chairman Fractal, menyatakan bahwa Fathom-R1-14B adalah demonstrasi awal dari inisiatif yang lebih besar. Dia menyebutkan, "Kami mengusulkan pembangunan model penalaran besar (LRM) pertama India sebagai bagian dari misi IndiaAI... Ini [Fathom-R1-14B] hanyalah bukti kecil dari apa yang mungkin," mengisyaratkan rencana untuk serangkaian model, termasuk versi 70 miliar parameter yang jauh lebih besar. Arah strategis ini menyoroti komitmen nasional terhadap kemandirian AI dan penciptaan model dasar pribumi. Kontribusi Fractal yang lebih luas terhadap AI mencakup proyek-proyek berdampak lainnya, seperti Vaidya.ai, platform AI multi-modal untuk bantuan kesehatan. Oleh karena itu, perilisan Fathom-R1-14B sebagai alat sumber terbuka tidak hanya bermanfaat bagi komunitas AI global tetapi juga menandakan pencapaian penting dalam lanskap AI India yang berkembang.
Desain Dasar dan Cetak Biru Arsitektur Fathom-R1-14B
Kemampuan mengesankan Fathom-R1-14B dibangun di atas fondasi yang dipilih dengan cermat dan desain arsitektur yang kuat, dioptimalkan untuk tugas-tugas penalaran.
Perjalanan Fathom-R1-14B dimulai dengan pemilihan Deepseek-R1-Distilled-Qwen-14B sebagai model dasarnya. Sifat "distilled" dari model ini menandakan bahwa ia adalah turunan yang lebih ringkas dan efisien secara komputasi dari model induk yang lebih besar, yang secara khusus dirancang untuk mempertahankan sebagian besar kemampuan aslinya, terutama yang berasal dari keluarga Qwen yang sangat dihargai. Ini memberikan titik awal yang kuat, yang kemudian ditingkatkan dengan cermat oleh Fractal AI Research melalui teknik pasca-pelatihan khusus. Untuk operasinya, model ini biasanya menggunakan presisi bfloat16 (Brain Floating Point Format), yang mencapai keseimbangan efektif antara kecepatan komputasi dan akurasi numerik yang diperlukan untuk perhitungan kompleks.
Fathom-R1-14B dibangun di atas arsitektur Qwen2, sebuah iterasi yang kuat dalam keluarga model Transformer. Model Transformer adalah standar saat ini untuk LLMs berkinerja tinggi, sebagian besar karena mekanisme self-attention yang inovatif. Mekanisme ini memungkinkan model untuk secara dinamis menimbang signifikansi token yang berbeda—baik itu kata, sub-kata, atau simbol matematis—dalam urutan input saat menghasilkan outputnya. Kemampuan ini sangat penting untuk memahami ketergantungan rumit yang ada dalam masalah matematika kompleks dan argumen logis yang bernuansa.
Skala model, yang dicirikan oleh sekitar 14,8 miliar parameter, adalah faktor kunci dalam kinerjanya. Parameter ini, yang pada dasarnya adalah nilai numerik yang dipelajari di dalam lapisan jaringan saraf, mengkodekan pengetahuan dan kemampuan penalaran model. Model sebesar ini menawarkan kapasitas substansial untuk menangkap dan merepresentasikan pola kompleks dari data pelatihannya.
Signifikansi Jendela Konteks 16K
Spesifikasi arsitektur yang penting adalah jendela konteks token 16.384. Ini menentukan panjang maksimum gabungan prompt input dan output yang dihasilkan model yang dapat diproses dalam satu operasi. Meskipun beberapa model memiliki jendela konteks yang jauh lebih besar, kapasitas 16K Fathom-R1-14B adalah pilihan desain yang disengaja dan pragmatis. Ukurannya cukup besar untuk menampung pernyataan masalah yang rinci, rantai penalaran langkah demi langkah yang ekstensif (seperti yang sering diperlukan dalam matematika tingkat Olimpiade), dan jawaban yang komprehensif. Yang penting, ini dicapai tanpa menimbulkan peningkatan biaya komputasi secara kuadratik yang dapat dikaitkan dengan mekanisme perhatian dalam urutan yang sangat panjang, membuat Fathom-R1-14B lebih gesit dan kurang memakan sumber daya selama inferensi.
Fathom-R1-14B Benar-Benar Sangat Efektif Biaya
Salah satu aspek paling mencolok dari Fathom-R1-14B adalah efisiensi proses pasca-pelatihannya. Versi utama model ini di-fine-tune dengan biaya yang dilaporkan sekitar $499 USD. Kelayakan ekonomi yang luar biasa ini dicapai melalui strategi pelatihan yang canggih dan multifaset yang berfokus pada memaksimalkan keterampilan penalaran tanpa pengeluaran komputasi yang berlebihan.
Teknik inti yang mendasari spesialisasi yang efisien ini meliputi:
- Supervised Fine-Tuning (SFT): Fase dasar ini melibatkan pelatihan model dasar pada kumpulan data pasangan soal-solusi berkualitas tinggi dan dikurasi yang secara khusus disesuaikan untuk penalaran matematika tingkat lanjut. Melalui SFT, model belajar meniru jalur penyelesaian masalah yang benar dan deduksi logis.
- Iterative Curriculum Learning: Daripada mengekspos model pada seluruh spektrum kesulitan masalah sekaligus, strategi ini memperkenalkan tantangan secara bertahap. Model dimulai dengan masalah matematika yang lebih sederhana dan secara progresif beralih ke yang lebih kompleks, seperti yang berasal dari AIME dan HMMT. Pendekatan terstruktur ini memfasilitasi pembelajaran yang lebih stabil dan efektif, memungkinkan model untuk membangun fondasi yang kuat sebelum menangani tugas-tugas yang sangat menantang. Teknik ini menjadi pusat pengembangan model pendahulu utama,
Fathom-R1-14B-V0.6. - Penggabungan Model (Model Merging): Model Fathom-R1-14B akhir adalah gabungan dari dua model pendahulu yang di-fine-tune secara khusus:
Fathom-R1-14B-V0.6(yang menjalani Iterative Curriculum SFT) danFathom-R1-14B-V0.4(yang berfokus pada SFT dengan "Shortest-Chains," kemungkinan menekankan keringkasan dalam solusi). Dengan menggabungkan model yang dilatih dengan fokus yang sedikit berbeda, model yang dihasilkan mewarisi serangkaian kekuatan yang lebih luas.
Tujuan utama dari proses pelatihan yang cermat ini adalah untuk menanamkan "penalaran matematis yang ringkas namun akurat."
Fractal AI Research juga mengeksplorasi jalur pelatihan alternatif dengan varian bernama Fathom-R1-14B-RS. Versi ini menggabungkan Reinforcement Learning (RL), khususnya menggunakan algoritma yang disebut GRPO (Generalized Reward Pushing Optimization), bersama dengan SFT. Meskipun pendekatan ini menghasilkan kinerja tinggi yang sebanding, biaya pasca-pelatihannya sedikit lebih tinggi, yaitu $967 USD. Pengembangan kedua versi ini menggarisbawahi komitmen untuk mengeksplorasi beragam metodologi guna mencapai kinerja penalaran yang optimal secara efisien. Sebagai bagian dari komitmen mereka terhadap transparansi, Fractal AI Research telah membuka sumber resep pelatihan dan kumpulan datanya.
Benchmark Kinerja: Mengukur Keunggulan Penalaran
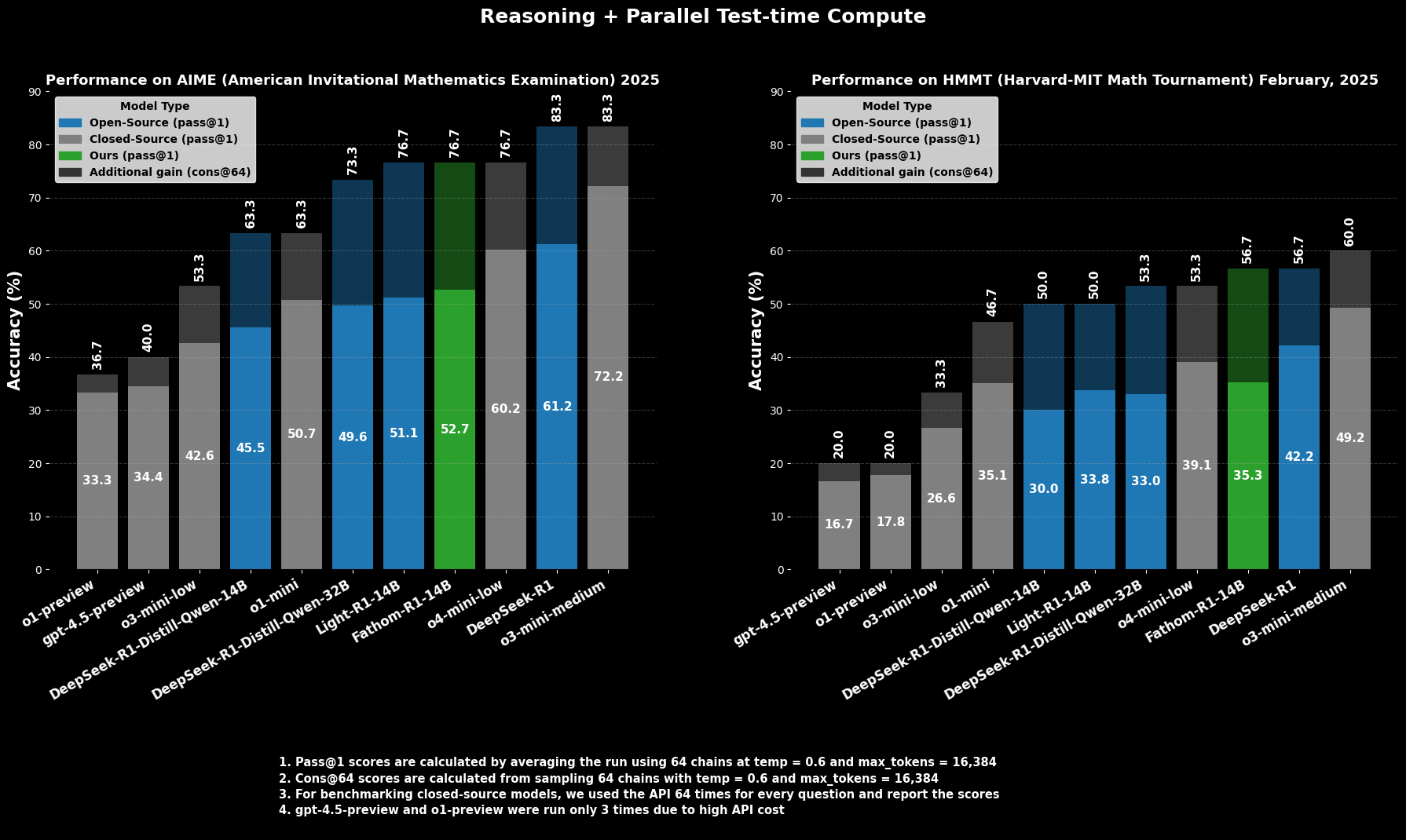
Kemahiran Fathom-R1-14B bukan hanya teoretis; ini dibuktikan dengan kinerja yang mengesankan pada benchmark penalaran matematika yang ketat dan diakui secara internasional.
Keberhasilan di AIME dan HMMT
Pada AIME2025 (American Invitational Mathematics Examination), kompetisi matematika pra-perguruan tinggi yang menantang, Fathom-R1-14B mencapai akurasi Pass@1 sebesar 52,71%. Metrik `Pass@1` menunjukkan persentase masalah di mana model menghasilkan solusi yang benar dalam satu percobaan. Ketika diizinkan anggaran komputasi yang lebih besar saat pengujian, dievaluasi menggunakan cons@64 (konsistensi di antara 64 solusi yang diambil sampelnya), akurasinya pada AIME2025 naik menjadi 76,7% yang mengesankan.
Demikian pula, pada HMMT25 (Harvard-MIT Mathematics Tournament), kompetisi tingkat tinggi lainnya, model mencetak 35,26% `Pass@1`, yang meningkat menjadi 56,7% `cons@64`. Skor ini sangat patut diperhatikan karena dicapai dalam anggaran output token 16K model, mencerminkan pertimbangan penerapan praktis.
Kinerja Komparatif
Dalam evaluasi komparatif, Fathom-R1-14B secara signifikan mengungguli model sumber terbuka lainnya dengan ukuran yang serupa atau bahkan lebih besar pada benchmark matematika spesifik ini pada `Pass@1`. Yang lebih mencolok, kinerjanya, terutama ketika mempertimbangkan metrik `cons@64`, menempatkannya bersaing dengan beberapa model sumber tertutup yang mumpuni, yang sering diasumsikan memiliki akses ke sumber daya yang jauh lebih besar. Ini menyoroti efisiensi Fathom-R1-14B dalam menerjemahkan parameter dan pelatihannya menjadi penalaran dengan fidelitas tinggi.
Mari Kita Coba Jalankan Fathom-R1-14B
https://nodeshift.com/blog/how-to-install-fathom-r1-14b-the-most-efficient-sota-math-reasoning-llm
Bagian ini memberikan panduan terfokus tentang cara menjalankan Fathom-R1-14B menggunakan pustaka transformers dari Hugging Face dalam lingkungan Python. Pendekatan ini sangat cocok untuk pengguna yang memiliki akses ke perangkat keras GPU yang mumpuni, baik secara lokal maupun melalui penyedia cloud. Langkah-langkah yang diuraikan di sini sangat mengikuti praktik yang sudah mapan untuk menerapkan model semacam itu.
Konfigurasi Lingkungan
Menyiapkan lingkungan Python yang sesuai sangat penting. Langkah-langkah berikut merinci penyiapan umum menggunakan Conda pada sistem berbasis Linux (atau Windows Subsystem for Linux):
Akses Mesin Anda: Jika menggunakan instance GPU cloud jarak jauh, sambungkan ke sana melalui SSH.Bash
# Example: ssh your_user@your_gpu_instance_ip -p YOUR_PORT -i /path/to/your/ssh_key
Verifikasi Pengenalan GPU: Pastikan sistem mengenali GPU NVIDIA dan driver terpasang dengan benar.Bash
nvidia-smi
Buat dan Aktifkan Lingkungan Conda: Merupakan praktik yang baik untuk mengisolasi dependensi proyek.Bash
conda create -n fathom python=3.11 -y
conda activate fathom
Instal Pustaka yang Diperlukan: Instal PyTorch (kompatibel dengan versi CUDA Anda), Hugging Face transformers, accelerate (untuk pemuatan dan distribusi model yang efisien), notebook (untuk Jupyter), dan ipywidgets (untuk interaktivitas notebook).Bash
# Ensure you install a PyTorch version compatible with your GPU's CUDA toolkit
# Example for CUDA 11.8:
# pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu118
# Or for CUDA 12.1:
pip install torch torchvision torchaudio --index-url https://download.pytorch.org/whl/cu121
conda install -c conda-forge --override-channels notebook -y
pip install ipywidgets transformers accelerate
Inferensi Berbasis Python dalam Jupyter Notebook
Dengan lingkungan yang sudah disiapkan, Anda dapat menggunakan Jupyter Notebook untuk memuat dan berinteraksi dengan Fathom-R1-14B.
Mulai Server Jupyter Notebook: Jika berada di server jarak jauh, mulai Jupyter Notebook dengan mengizinkan akses jarak jauh dan tentukan port.Bash
jupyter notebook --no-browser --port=8888 --allow-root
Jika berjalan dari jarak jauh, Anda mungkin perlu menyiapkan penerusan port SSH dari mesin lokal Anda untuk mengakses antarmuka Jupyter:Bash
# Example: ssh -N -L localhost:8889:localhost:8888 your_user@your_gpu_instance_ip
Kemudian, buka http://localhost:8889 (atau port lokal pilihan Anda) di browser web Anda.
Kode Python untuk Interaksi Model: Buat Jupyter Notebook baru dan gunakan kode Python berikut:Python
import torch
from transformers import AutoModelForCausalLM, AutoTokenizer
# Define the model ID from Hugging Face
model_id = "FractalAIResearch/Fathom-R1-14B"
print(f"Loading tokenizer for {model_id}...")
tokenizer = AutoTokenizer.from_pretrained(model_id)
print(f"Loading model {model_id} (this may take a while)...")
# Load the model with bfloat16 precision for efficiency and device_map for auto distribution
model = AutoModelForCausalLM.from_pretrained(
model_id,
torch_dtype=torch.bfloat16, # Use bfloat16 if your GPU supports it
device_map="auto", # Automatically distributes model layers across available hardware
trust_remote_code=True # Some models may require this
)
print("Model and tokenizer loaded successfully.")
# Define a sample mathematical prompt
prompt = """Question: Natalia sold clips to 48 of her friends in April, and then she sold half as many clips in May. In June, she sold 4 more clips than in May. How many clips did Natalia sell altogether in April, May, and June? Provide a step-by-step solution.
Solution:"""
print(f"\nPrompt:\n{prompt}")
# Tokenize the input prompt
inputs = tokenizer(prompt, return_tensors="pt").to(model.device) # Ensure inputs are on the model's device
print("\nGenerating solution...")
# Generate the output from the model
# Adjust generation parameters as needed for different types of problems
outputs = model.generate(
**inputs,
max_new_tokens=768, # Maximum number of new tokens to generate for the solution
num_return_sequences=1, # Number of independent sequences to generate
temperature=0.1, # Lower temperature for more deterministic, factual outputs
top_p=0.7, # Use nucleus sampling with top_p
do_sample=True # Enable sampling for temperature and top_p to have an effect
)
# Decode the generated tokens into a string
solution_text = tokenizer.decode(outputs[0], skip_special_tokens=True)
print("\nGenerated Solution:\n")
print(solution_text)
Kesimpulan: Dampak Fathom-R1-14B pada AI yang Dapat Diakses
FractalAIResearch/Fathom-R1-14B berdiri sebagai demonstrasi yang meyakinkan tentang kecerdikan teknis di arena AI kontemporer. Desain spesifiknya, menampilkan sekitar 14,8 miliar parameter, arsitektur Qwen2, dan jendela konteks token 16K, ketika digabungkan dengan pelatihan yang inovatif dan efektif biaya (sekitar $499 untuk versi utama), telah menghasilkan LLM yang memberikan kinerja terdepan. Ini dibuktikan dengan skornya pada benchmark penalaran matematika yang berat seperti AIME dan HMMT.
Fathom-R1-14B secara meyakinkan menggambarkan bahwa batas-batas penalaran AI dapat dimajukan melalui desain cerdas dan metodologi yang efisien, mendorong masa depan di mana AI berkinerja tinggi lebih demokratis dan bermanfaat luas.
Ingin platform Terintegrasi, All-in-One untuk Tim Developer Anda bekerja sama dengan produktivitas maksimum?
Apidog memenuhi semua permintaan Anda, dan menggantikan Postman dengan harga yang jauh lebih terjangkau!