
DeepSeek terus memajukan model bahasa besar dengan rilis yang memprioritaskan penalaran dan efisiensi. Para insinyur dan peneliti kini memiliki akses ke DeepSeek-V3.2 dan DeepSeek-V3.2-Speciale, model yang unggul dalam pemecahan masalah kompleks dan alur kerja agen. Alat-alat ini terintegrasi dengan mulus ke dalam aplikasi, namun pengembang sering menghadapi tantangan dalam penyiapan, otentikasi, dan optimasi. Artikel ini menyediakan panduan teknis langkah demi langkah untuk memanfaatkan model-model ini secara efektif.
Memahami DeepSeek-V3.2: Fondasi Sumber Terbuka untuk Penalaran Tingkat Lanjut
Pengembang membangun sistem AI yang tangguh pada model sumber terbuka karena menawarkan transparansi, kustomisasi, dan peningkatan yang digerakkan oleh komunitas. DeepSeek-V3.2 berdiri sebagai penerus resmi varian eksperimental V3.2-Exp, yang dirilis DeepSeek sebelumnya untuk menguji mekanisme sparse attention. Model ini mengaktifkan 37 miliar parameter dari total 671 miliar dalam arsitektur Mixture-of-Experts (MoE) miliknya, yang dilatih pada 14,8 triliun token berkualitas tinggi. Skala sebesar itu memungkinkan DeepSeek-V3.2 menangani berbagai tugas, mulai dari pembuatan bahasa alami hingga pembuktian matematis yang rumit.
Inovasi inti model ini terletak pada DeepSeek Sparse Attention (DSA), mekanisme granular yang mengurangi overhead komputasi selama inferensi, terutama untuk konteks panjang hingga 128.000 token. Para insinyur menghargai ini karena menjaga kualitas output sambil mengurangi latensi—kritis untuk aplikasi real-time seperti chatbot atau asisten kode. Selain itu, DeepSeek-V3.2 mengintegrasikan mode "berpikir", di mana model menghasilkan langkah-langkah penalaran menengah sebelum output akhir, meningkatkan akurasi pada benchmark seperti AIME 2025 dan HMMT 2025.
Akses versi sumber terbuka di Hugging Face di deepseek-ai/DeepSeek-V3.2. Pengembang mengunduh bobot dan konfigurasi secara langsung, memungkinkan penyebaran lokal pada kluster GPU. Sebagai contoh, gunakan pustaka Transformers untuk memuat model:
from transformers import AutoTokenizer, AutoModelForCausalLM
import torch
model_name = "deepseek-ai/DeepSeek-V3.2"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
device_map="auto"
)
prompt = "Solve this equation: x^2 + 3x - 4 = 0"
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=200, do_sample=False)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Cuplikan kode ini menginisialisasi model dengan presisi bfloat16 untuk efisiensi pada GPU NVIDIA modern. Namun, eksekusi lokal membutuhkan perangkat keras yang substansial—direkomendasikan setidaknya 8x GPU A100 untuk presisi penuh. Akibatnya, banyak tim memilih versi terkuantisasi melalui pustaka seperti bitsandbytes agar sesuai dengan perangkat keras konsumen.
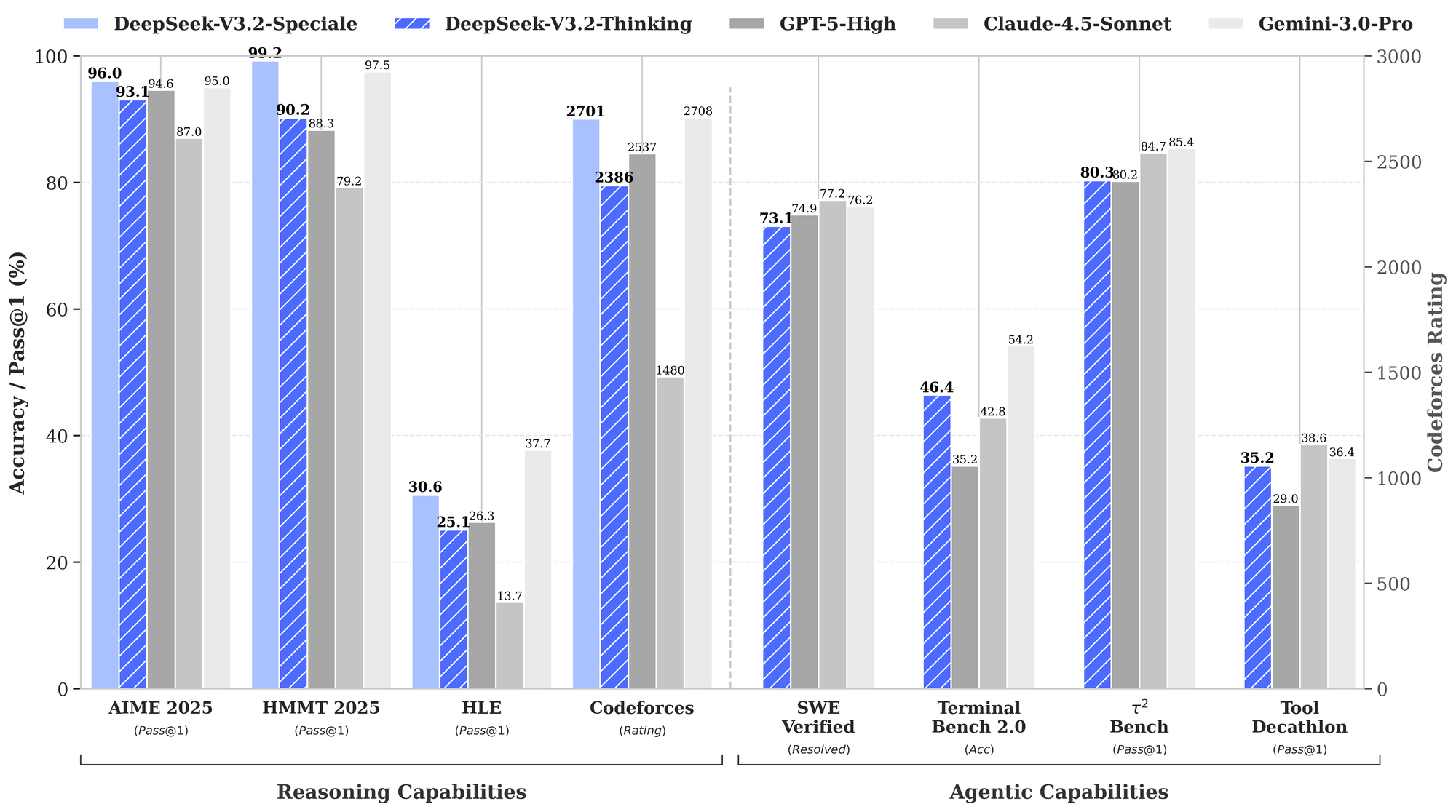
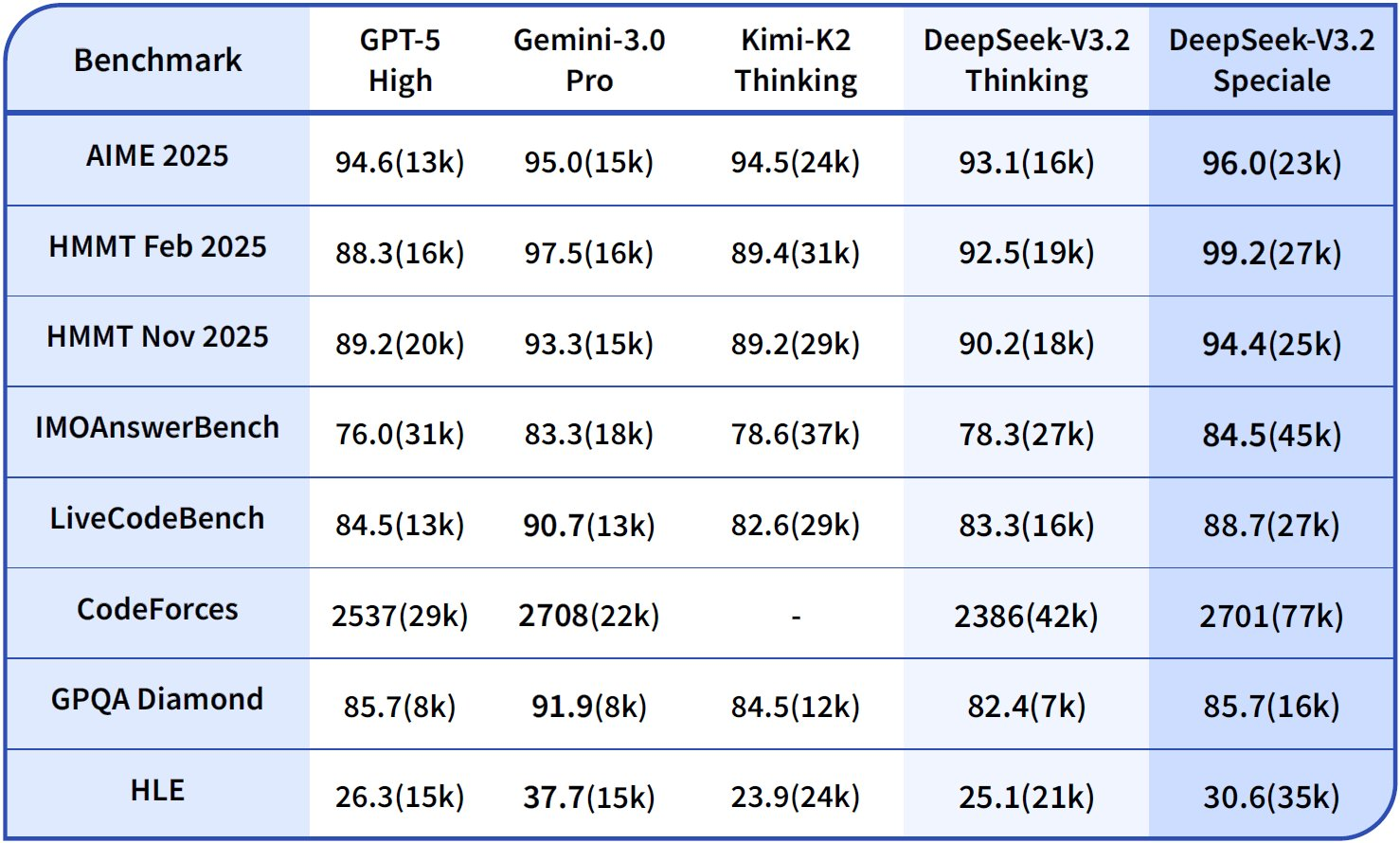
Benchmark menggarisbawahi kekuatan DeepSeek-V3.2. Dalam tugas penalaran, ia mencapai 93,1% pada AIME 2025 (pass@1), melampaui GPT-5-High sebesar 90,2%. Untuk kemampuan agen, ia memecahkan 2.537 masalah pada SWE-Bench Verified, mengungguli Claude-4.5-Sonnet sebesar 2.536. Metrik ini menempatkan DeepSeek-V3.2 sebagai "driver harian" yang seimbang untuk lingkungan produksi, di mana kecepatan inferensi sama pentingnya dengan kecerdasan mentah.
Selain itu, model ini mendukung ekstensi multimodal dalam pembaruan mendatang, namun rilis saat ini berfokus pada penalaran berbasis teks. Para insinyur menyempurnakannya pada dataset spesifik domain menggunakan adaptor LoRA, mempertahankan kemampuan dasar sambil beradaptasi dengan ceruk pasar seperti analisis hukum atau simulasi ilmiah. Akibatnya, akses sumber terbuka memberdayakan prototyping cepat tanpa ketergantungan vendor.
Menjelajahi DeepSeek-V3.2-Speciale: Dioptimalkan untuk Kinerja Penalaran Puncak
Meskipun DeepSeek-V3.2 menyediakan utilitas yang luas, DeepSeek-V3.2-Speciale menargetkan skenario yang menuntut kedalaman kognitif maksimum. Varian ini mendorong batas penalaran, menyaingi Gemini-3.0-Pro dalam kompetisi elit. Ia meraih medali emas di IMO 2025, CMO, ICPC World Finals, dan IOI 2025—prestasi yang membutuhkan rangkaian logika bernuansa dan pemecahan masalah kreatif.
DeepSeek-V3.2-Speciale dibangun di atas fondasi MoE yang sama tetapi menggabungkan tahap reinforcement learning dari umpan balik manusia (RLHF) yang ditingkatkan, menekankan perilaku agen. Tidak seperti model dasar, ia menghasilkan proses pemikiran internal yang lebih panjang, yang mengonsumsi lebih banyak token tetapi menghasilkan akurasi yang unggul pada tugas-tugas seperti penggunaan alat di lingkungan multi-langkah. Misalnya, ia mensintesis data pelatihan di lebih dari 1.800 dunia simulasi dan lebih dari 85.000 instruksi, memungkinkan penanganan skenario yang tidak terlihat secara robust.
Lihat kartu model di Hugging Face di deepseek-ai/DeepSeek-V3.2-Speciale. Pengunduhan mengikuti proses serupa:
model_name = "deepseek-ai/DeepSeek-V3.2-Speciale"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(
model_name,
torch_dtype=torch.bfloat16,
trust_remote_code=True,
device_map="auto"
)
prompt = "Prove that the sum of angles in a triangle is 180 degrees."
inputs = tokenizer(prompt, return_tensors="pt").to(model.device)
outputs = model.generate(**inputs, max_new_tokens=500, temperature=0.1)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Perhatikan tanda trust_remote_code=True, karena Speciale menggunakan implementasi perhatian khusus. Penyiapan ini menuntut VRAM yang lebih banyak—hingga 1TB untuk inferensi yang tidak terkuantisasi—sehingga ideal untuk laboratorium penelitian daripada perangkat edge.
Data kinerja menyoroti keunggulannya. Bagan benchmark yang disediakan menggambarkan DeepSeek-V3.2-Speciale (batang biru) memimpin dalam penalaran: 99,0% pada HMMT 2025 (pass@1) berbanding GPT-5-High 97,5%, dan akurasi 84,8% pada Codeforces (peringkat) berbanding Claude-4.5-Sonnet 84,7%. Dalam domain agen, ia unggul di Terminal-Bench v0.2 (akurasi 84,3%) dan Tool-Use (pass@1), seringkali dengan margin tipis yang menjadi semakin penting dalam operasi berantai. Namun, penggunaan token yang lebih tinggi—hingga 50% lebih banyak dari V3.2—memerlukan rekayasa prompt yang cermat untuk mengendalikan biaya.
Karena Speciale tidak memiliki fitur penggunaan alat bawaan dalam rilis awalnya, pengembang mengaitkannya dengan API eksternal untuk agen hibrida. Pendekatan ini unggul dalam evaluasi, di mana ia mengungguli rekan-rekannya pada benchmark instruksi 85k+. Secara keseluruhan, DeepSeek-V3.2-Speciale cocok untuk aplikasi berisiko tinggi, seperti pembuktian teorema otomatis atau simulasi perencanaan strategis.
Transisi dari Sumber Terbuka ke API: Mengapa Akses Terkelola Penting
Penyebaran lokal menawarkan kontrol, namun penskalaan menimbulkan kompleksitas seperti penyediaan dan pemeliharaan perangkat keras. Pengembang beralih ke API untuk akses instan, ekonomi bayar per penggunaan, dan infrastruktur terkelola. DeepSeek menyediakan endpoint terkelola untuk V3.2 dan V3.2-Speciale, memastikan kompatibilitas dengan antarmuka bergaya OpenAI. Pergeseran ini mempercepat prototyping, karena tim melewati hambatan penyiapan dan berfokus pada integrasi.
Selain itu, akses API membuka fitur perusahaan, seperti pembatasan tarif dan caching, yang mengoptimalkan beban produksi. Misalnya, hit cache secara dramatis mengurangi biaya input, membuat kueri berulang menjadi ekonomis. Akibatnya, startup dan perusahaan mengadopsi endpoint ini untuk penyebaran yang sensitif terhadap biaya.
Mengakses DeepSeek API: Penyiapan Langkah demi Langkah
Insinyur mengakses DeepSeek API melalui platform resmi. Pertama, buat akun dan hasilkan kunci API di bagian "Kunci API". Kunci ini mengautentikasi permintaan melalui header Otorisasi: Bearer YOUR_API_KEY.
URL dasar adalah https://api.deepseek.com/v1. Untuk DeepSeek-V3.2, gunakan pengenal model deepseek-v3.2. DeepSeek-V3.2-Speciale beroperasi pada endpoint sementara: https://api.deepseek.com/v3.2_speciale_expires_on_20251215, tersedia hingga 15 Desember 2025, pukul 15:59 UTC. Setelah tanggal ini, ia akan bergabung ke dalam penawaran standar.
Instal OpenAI SDK untuk kesederhanaan:
pip install openai
Kemudian, konfigurasikan klien:
from openai import OpenAI
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v1"
)
Kirim permintaan penyelesaian untuk DeepSeek-V3.2:
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[
{"role": "system", "content": "You are a helpful assistant focused on reasoning."},
{"role": "user", "content": "Explain quantum entanglement in simple terms."}
],
max_tokens=300,
temperature=0.7
)
print(response.choices[0].message.content)
Untuk DeepSeek-V3.2-Speciale, sesuaikan base_url dan model:
client = OpenAI(
api_key="YOUR_API_KEY",
base_url="https://api.deepseek.com/v3.2_speciale_expires_on_20251215"
)
response = client.chat.completions.create(
model="deepseek-v3.2-speciale",
messages=[{"role": "user", "content": "Solve: Integrate e^x sin(x) dx."}],
max_tokens=500
)
Panggilan-panggilan ini mengembalikan respons JSON dengan statistik penggunaan, termasuk token prompt dan penyelesaian. Tangani kesalahan melalui blok try-except, periksa batas kecepatan (misalnya, 10.000 RPM untuk V3.2).
Selain itu, aktifkan mode berpikir dengan menambahkan /thinking ke nama model, mis., deepseek-v3.2/thinking. Ini memicu penalaran langkah demi langkah, ideal untuk men-debug kueri kompleks.
Harga API: Penskalaan Hemat Biaya untuk DeepSeek-V3.2 dan Speciale
Harga menjadi landasan adopsi API, dan DeepSeek menyusunnya secara transparan per juta token. Kedua model mengikuti tarif yang sama, ditagih berdasarkan input (cache hit/miss) dan output. Cache hit berlaku untuk prefiks berulang dalam sesi, mengurangi biaya untuk alur kerja iteratif.
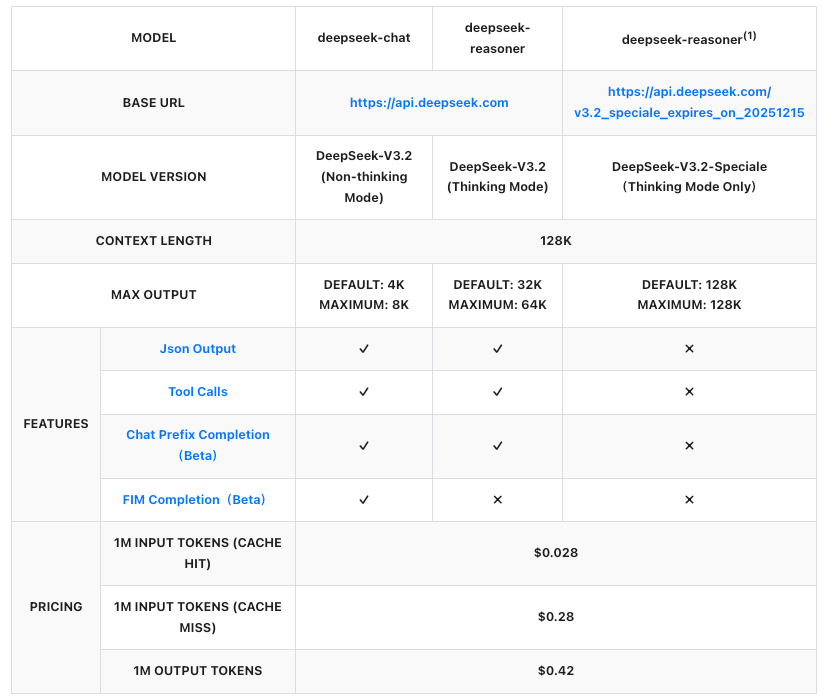
Angka-angka ini mewakili pengurangan lebih dari 50% dari versi sebelumnya, menjadikan DeepSeek kompetitif dengan API berpemilik. Misalnya, menghasilkan respons 1.000 token pada prompt 500 token (cache miss) berharga sekitar $0,00035—tidak signifikan untuk sebagian besar kasus penggunaan. Perusahaan menegosiasikan rencana khusus untuk volume yang lebih tinggi, tetapi model bayar sesuai penggunaan cocok untuk pengembang.
Akibatnya, tim memperkirakan pengeluaran menggunakan estimasi token di dasbor DeepSeek. Pertimbangkan konsumsi token Speciale yang lebih tinggi; kueri yang banyak penalaran mungkin menggandakan biaya tetapi melipatgandakan akurasi pada benchmark seperti Tau² (29,0% pass@1 untuk Speciale vs. 25,1% untuk V3.2).
Mengintegrasikan dengan Apidog: Pengujian dan Dokumentasi API yang Efisien
Pengembang menyederhanakan alur kerja dengan alat seperti Apidog, yang merancang, menguji, dan mendokumentasikan API tanpa kode. Impor kunci API DeepSeek Anda ke variabel lingkungan Apidog, lalu buat koleksi permintaan baru untuk endpoint V3.2 dan Speciale.
Bangun permintaan POST ke /chat/completions:
- Header:
Authorization: Bearer {{api_key}},Content-Type: application/json - Body: Payload JSON dengan model, pesan, dan parameter.
Jalankan pengujian di antarmuka Apidog, yang secara otomatis menghasilkan respons dan pernyataan. Misalnya, validasi bahwa output Speciale melebihi 200 token pada prompt matematika. Selain itu, Apidog mengekspor spesifikasi OpenAPI, memfasilitasi serah terima tim.
Integrasi ini memangkas waktu debugging hingga 40%, karena perbedaan visual menyoroti ketidaksesuaian. Tim juga membuat respons tiruan untuk pengembangan offline, memastikan ketangguhan sebelum penerapan langsung.
Teknik Lanjutan: Penggunaan Alat dan Alur Kerja Agen
DeepSeek-V3.2 memperkenalkan pemikiran dalam penggunaan alat, memadukan penalaran internal dengan panggilan eksternal. Tentukan alat dalam payload API:
tools = [
{
"type": "function",
"function": {
"name": "calculator",
"description": "Perform basic math",
"parameters": {
"type": "object",
"properties": {"expression": {"type": "string"}}
}
}
}
]
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "user", "content": "What is 15% of 250?"}],
tools=tools,
tool_choice="auto"
)
Model melakukan penalaran langkah demi langkah, kemudian memanggil alat jika diperlukan. Speciale, yang saat ini tanpa alat, sangat cocok sebagai oracle penalaran dalam rantai multi-model.
Untuk agen, orkestrasikan melalui LangChain: bungkus panggilan DeepSeek dalam agen yang merutekan tugas secara dinamis. Penyiapan ini menyelesaikan 73,1% masalah SWE-Bench Verified, sesuai benchmark.
Praktik Terbaik untuk Penyebaran Produksi
Optimalkan prompt dengan template chain-of-thought untuk memanfaatkan mode berpikir. Pantau penggunaan token melalui metadata API, menerapkan fallback untuk batasan anggaran. Skalakan dengan klien asinkron di Python untuk aplikasi berkapasitas tinggi.
Keamanan menuntut rotasi kunci dan daftar putih IP. Terakhir, evaluasi secara iteratif terhadap benchmark seperti yang ada di laporan teknis, menyesuaikan hyperparameter agar sesuai dengan domain.
Kesimpulan: Manfaatkan Kekuatan DeepSeek Hari Ini
DeepSeek-V3.2 dan DeepSeek-V3.2-Speciale mendefinisikan ulang penalaran AI yang mudah diakses. Dari fleksibilitas sumber terbuka hingga efisiensi API, model-model ini memberdayakan pengembang untuk membangun agen yang lebih cerdas. Mulailah dengan eksperimen lokal, migrasikan ke endpoint terkelola, dan integrasikan Apidog untuk pengujian yang mulus. Seiring berkembangnya benchmark, lintasan DeepSeek menjanjikan kemampuan yang lebih besar—posisikan proyek Anda di garis depan.