
Para pengembang dan peneliti mencari model yang memprioritaskan penalaran untuk menggerakkan agen otonom. DeepSeek-V3.2 dan varian khususnya, DeepSeek-V3.2-Speciale, secara tepat memenuhi kebutuhan ini. Model-model ini dibangun di atas iterasi sebelumnya, seperti DeepSeek-V3.2-Exp, untuk memberikan kapabilitas yang ditingkatkan dalam inferensi logis, pemecahan masalah matematika, dan alur kerja agen. Para insinyur kini memiliki akses ke alat yang memproses kueri kompleks dengan efisiensi, melampaui tolok ukur yang ditetapkan oleh sistem sumber tertutup terkemuka.
Saat kami mengkaji model-model ini, fokus tetap pada keunggulan teknisnya. Pertama, fondasi sumber terbuka memungkinkan eksperimen luas. Kemudian, akses API menyediakan opsi penerapan yang skalabel. Sepanjang postingan ini, data dari sumber resmi dan tolok ukur mengilustrasikan potensinya.
Membuka Sumber DeepSeek-V3.2: Fondasi untuk Pengembangan AI Kolaboratif
DeepSeek merilis DeepSeek-V3.2 di bawah Lisensi MIT yang permisif, mendorong adopsi luas di kalangan komunitas AI. Keputusan ini memberdayakan pengembang untuk memeriksa, memodifikasi, dan menerapkan model tanpa hambatan restriktif. Akibatnya, tim mempercepat inovasi dalam aplikasi agen, mulai dari pembuatan kode otomatis hingga alur kerja penalaran multi-langkah.
Arsitektur model berpusat pada DeepSeek Sparse Attention (DSA), mekanisme yang mengoptimalkan tuntutan komputasi untuk pemrosesan konteks panjang. DSA menggunakan sparsity berbutir halus, mengurangi kompleksitas perhatian dari skala kuadratik menjadi hampir linear sambil mempertahankan kualitas keluaran. Misalnya, dalam urutan yang melebihi 128.000 token—setara dengan ratusan halaman teks—model mempertahankan kecepatan inferensi yang kompetitif dengan rekan-rekan yang lebih kecil.
DeepSeek-V3.2 memiliki 685 miliar parameter, didistribusikan di berbagai jenis tensor seperti BF16, F8_E4M3, dan F32 untuk kuantisasi fleksibel. Pelatihan menggabungkan kerangka kerja pembelajaran penguatan (RL) yang skalabel, di mana agen belajar melalui umpan balik iteratif pada tugas-tugas sintetis. Pendekatan ini menyempurnakan jalur penalaran, memungkinkan model untuk merangkai langkah-langkah logis secara efektif. Selain itu, pipeline sintesis tugas agen berskala besar menghasilkan skenario beragam, memadukan penalaran dengan pemanggilan alat. Pengembang mengakses ini melalui repositori Hugging Face, tempat bobot pra-terlatih dan model dasar berada.
Penggunaan dimulai dengan pengkodean input dalam format yang kompatibel dengan OpenAI, difasilitasi oleh skrip Python di direktori pengkodean model. Template obrolan memperkenalkan mode "berpikir dengan alat", di mana model mempertimbangkan sebelum bertindak. Parameter sampling—temperature pada 1.0 dan top_p pada 0.95—menghasilkan keluaran yang konsisten namun kreatif. Untuk penerapan lokal, repositori GitHub untuk DeepSeek-V3.2-Exp menawarkan operator yang dioptimalkan CUDA, termasuk varian TileLang untuk beragam ekosistem GPU.
Selain itu, Lisensi MIT memastikan kelangsungan perusahaan. Organisasi menyesuaikan model untuk agen berpemilik tanpa hambatan hukum. Tolok ukur memvalidasi keterbukaan ini: DeepSeek-V3.2 mencapai kesetaraan dengan GPT-5 dalam skor penalaran agregat, sebagaimana dirinci dalam laporan teknis. Dengan demikian, open-sourcing tidak hanya mendemokratisasikan akses tetapi juga menjadi tolok ukur terhadap raksasa berpemilik.
DeepSeek-V3.2-Speciale: Peningkatan yang Disesuaikan untuk Tuntutan Penalaran Tingkat Lanjut
Sementara DeepSeek-V3.2 melayani tujuan umum, DeepSeek-V3.2-Speciale secara eksklusif menargetkan penalaran mendalam. Varian ini menerapkan pelatihan pasca-komputasi tinggi pada basis parameter 685B yang sama, meningkatkan kemahiran dalam pemecahan masalah abstrak. Sebagai hasilnya, ia meraih setara medali emas di Olimpiade Matematika Internasional (IMO) dan Olimpiade Informatika Internasional (IOI) tahun 2025, mengungguli garis dasar manusia dalam solusi yang diserahkan.
Secara arsitektur, DeepSeek-V3.2-Speciale mencerminkan saudaranya dengan DSA untuk penanganan konteks panjang yang efisien. Namun, pelatihan pasca-pelatihan menekankan RL pada kumpulan data pilihan, termasuk masalah olimpiade dan rantai agen sintetis. Proses ini mengasah penalaran rantai pemikiran (CoT), di mana model menguraikan kueri menjadi langkah-langkah yang dapat diverifikasi. Yang menarik, ia menghilangkan dukungan pemanggilan alat untuk memusatkan sumber daya pada inferensi murni, menjadikannya ideal untuk tugas-tugas intensif komputasi seperti pembuktian teorema.
Kartu model Hugging Face menyoroti perbedaan: DeepSeek-V3.2-Speciale memproses input tanpa dependensi eksternal, mengandalkan pertimbangan internal. Pengembang mengkodekan pesan serupa, tetapi keluaran menuntut parsing kustom karena tidak adanya template Jinja. Penanganan kesalahan dalam kode produksi menjadi krusial, karena respons yang salah bentuk memerlukan lapisan validasi.
Dalam perbandingan, DeepSeek-V3.2-Speciale melampaui GPT-5-High dalam agregat penalaran dan selaras dengan Gemini-3.0-Pro. Misalnya, pada AIME 2025 (Pass@1), ia mencetak 93.1%, mengungguli Claude-4.5-Sonnet yang 90.2%. Keuntungan ini berasal dari RL yang ditargetkan, yang mensimulasikan skenario adversarial untuk memperkuat rantai logis. Akibatnya, para peneliti menerapkannya untuk tugas-tugas perbatasan, seperti memverifikasi kode ICPC World Finals atau bukti CMO 2025, dengan aset yang tersedia di repositori.
Secara keseluruhan, DeepSeek-V3.2-Speciale memperluas jangkauan ekosistem. Ini melengkapi model dasar dengan menangani kasus-kasus batas di mana kedalaman mengalahkan keluasan, memastikan cakupan komprehensif untuk pembangun agen.
Membandingkan Kapabilitas Penalaran dan Agen: Wawasan Berbasis Data
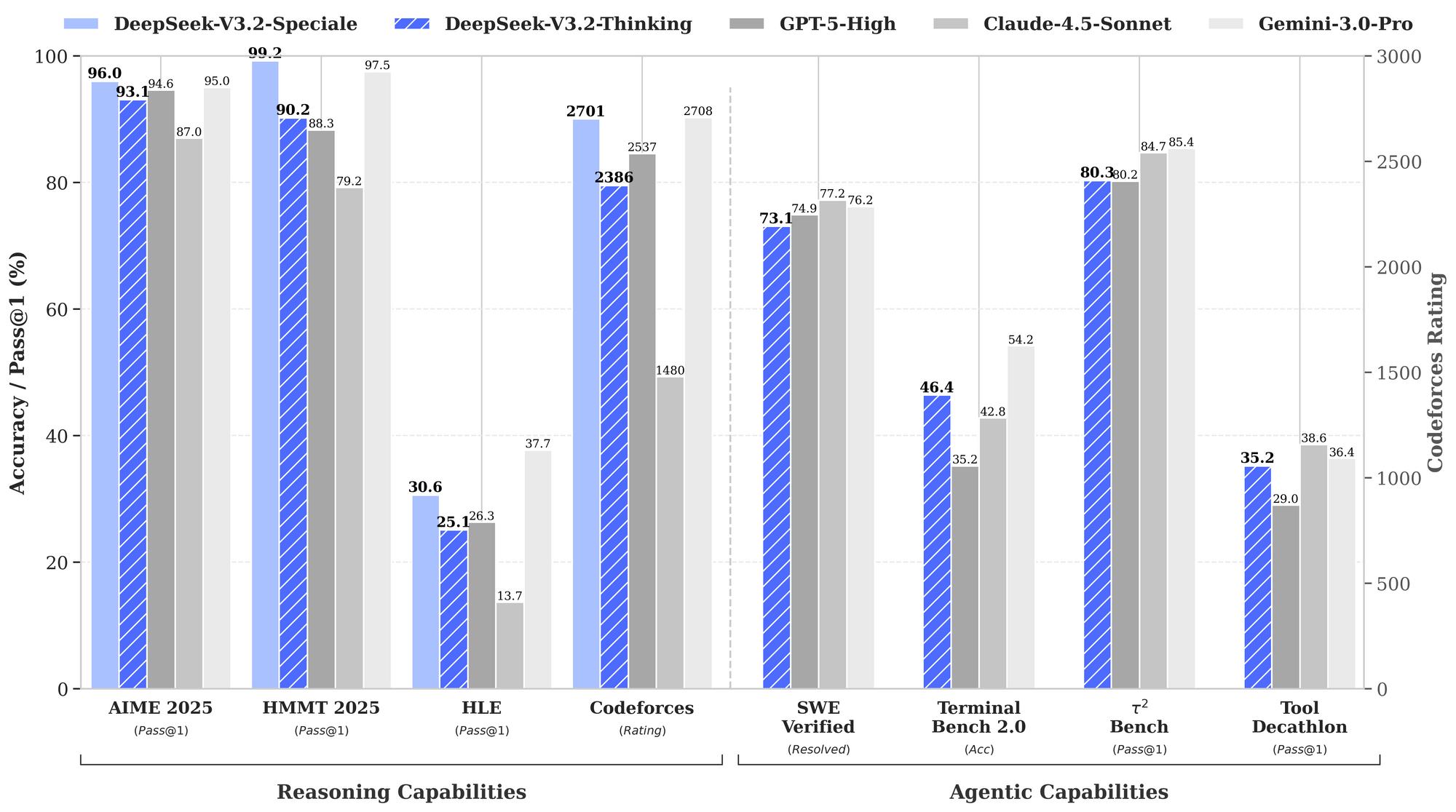
Tolok ukur mengukur kekuatan DeepSeek-V3.2, khususnya dalam domain penalaran dan agen. Grafik kinerja yang disediakan mengilustrasikan tingkat kelulusan dan akurasi di seluruh evaluasi utama, menempatkan model-model ini dibandingkan dengan GPT-5-High, Claude-4.5-Sonnet, dan Gemini-3.0-Pro.
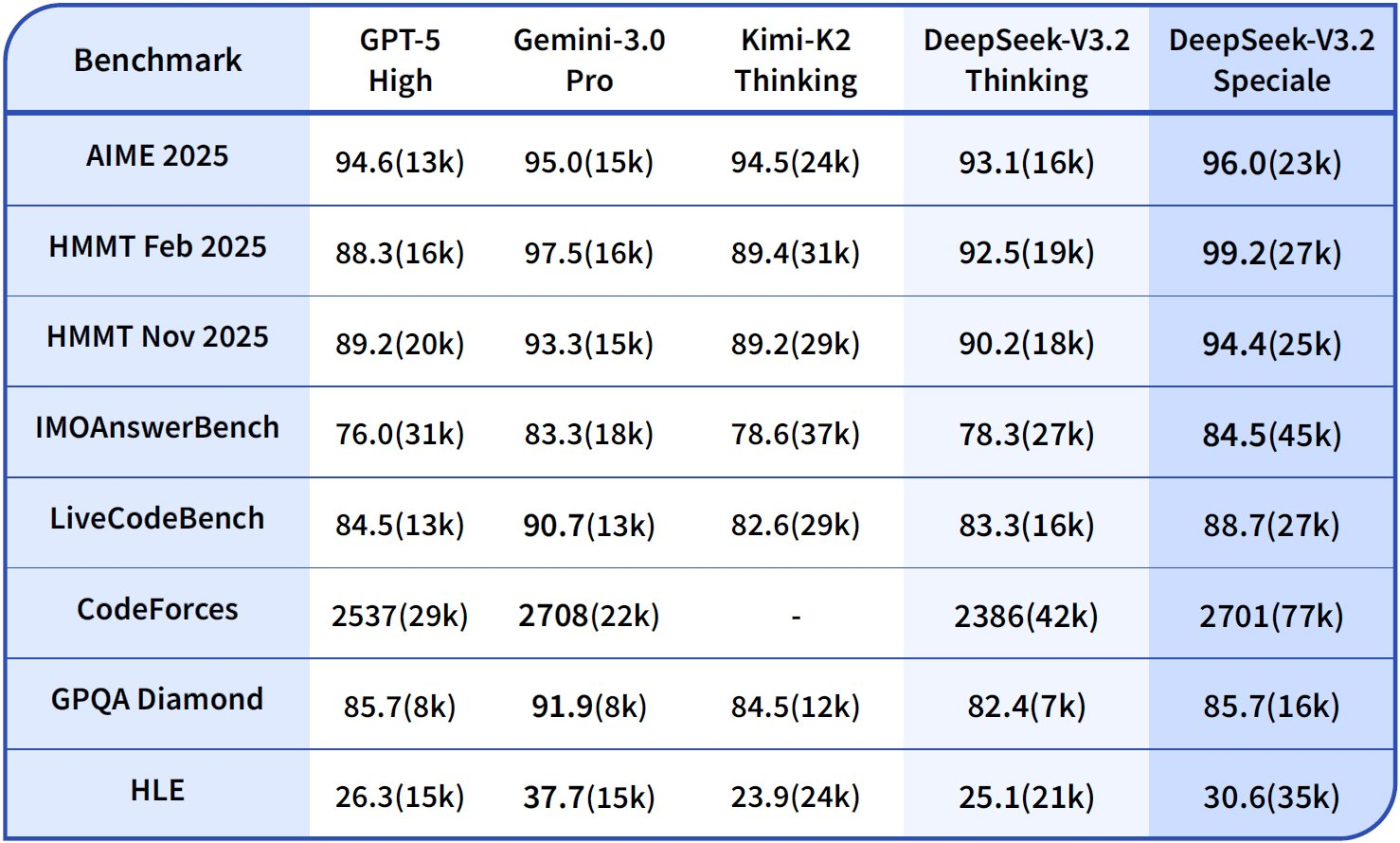
Dalam kapabilitas penalaran, DeepSeek-V3.2-Thinking (konfigurasi komputasi tinggi yang mirip dengan Speciale) memimpin dengan 93.1% pada AIME 2025 (Pass@1), melampaui GPT-5-High sebesar 90.8% dan Claude-4.5-Sonnet sebesar 87.0%. Demikian pula, pada HMMT 2025, ia mencapai 94.6%, mencerminkan dekomposisi matematika yang superior. Evaluasi HLE menunjukkan 95.0% pass@1, di mana model memecahkan teka-teki logika bahasa Inggris tingkat tinggi dengan sedikit percobaan ulang.
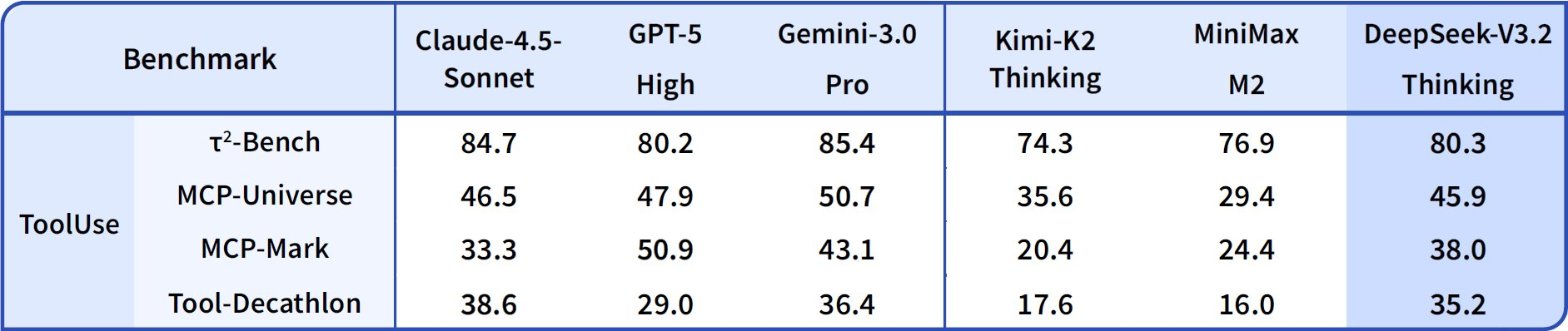
Beralih ke kapabilitas agen, DeepSeek-V3.2 unggul dalam pengkodean dan penggunaan alat. Peringkat Codeforces mencapai 2708 untuk mode Thinking, mengungguli Gemini-3.0-Pro yang 2537. Metrik ini mengagregasikan masalah yang dipecahkan di bawah batasan waktu, menekankan efisiensi algoritmik. Pada SWE-Verified (diselesaikan), ia mencapai 73.1%, menunjukkan deteksi bug yang andal dan pembuatan perbaikan di basis kode yang terverifikasi.
Akurasi Terminal Bench 2.0 mencapai 80.3%, di mana model menavigasi lingkungan shell melalui perintah bahasa alami. T² (Pass@1) mencetak 84.8%, mengevaluasi tugas yang ditingkatkan alat seperti pengambilan dan sintesis data. Evaluasi Alat mencapai 84.7%, dengan model memanggil API dan mengurai respons secara akurat.
DeepSeek-V3.2-Speciale memperkuat ini dalam subset penalaran murni. Misalnya, ia meningkatkan AIME menjadi 99.2% dan HMMT menjadi 99.0%, mendekati kesempurnaan dalam matematika gaya olimpiade. Namun, skor agennya menurun tanpa dukungan alat—misalnya, Alat pada 73.1% versus 84.7% pada model dasar—memprioritaskan kedalaman daripada integrasi.
Hasil ini berasal dari protokol standar: Pass@1 mengukur keberhasilan satu kali percobaan, sementara peringkat menggabungkan penskalaan mirip Elo. Dibandingkan dengan garis dasar, model DeepSeek menutup kesenjangan sumber terbuka, dengan DSA memungkinkan penghematan komputasi 50% pada konteks panjang. Dengan demikian, tolok ukur tidak hanya memvalidasi klaim tetapi juga memandu pemilihan: gunakan V3.2 untuk agen yang seimbang, Speciale untuk logika intensif.
| Tolok Ukur | Metrik | DeepSeek-V3.2 | DeepSeek-V3.2-Speciale | GPT-5-High | Claude-4.5-Sonnet | Gemini-3.0-Pro |
|---|---|---|---|---|---|---|
| AIME 2025 | Lulus@1 (%) | 93.1 | 99.2 | 90.8 | 87.0 | 90.2 |
| HMMT 2025 | Lulus@1 (%) | 94.6 | 99.0 | 91.4 | 83.3 | 95.0 |
| HLE | Lulus@1 (%) | 95.0 | 97.5 | 92.8 | 79.2 | 98.3 |
| Codeforces | Peringkat | 2701 | 2708 | 2537 | 2386 | 2537 |
| SWE-Verified | Diselesaikan (%) | 73.1 | 77.2 | 71.9 | 73.1 | 64.4 |
| Terminal Bench 2.0 | Akurasi (%) | 80.3 | 80.6 | 84.7 | 85.4 | 80.3 |
| T² | Lulus@1 (%) | 84.8 | 83.2 | 82.0 | 82.9 | 78.5 |
| Alat | Lulus@1 (%) | 84.7 | 73.1 | 74.9 | 77.2 | 76.2 |
Tabel ini mengagregasikan data grafik, menyoroti kepemimpinan yang konsisten dalam penalaran sambil mempertahankan daya saing dalam keagenan.
Mengakses DeepSeek API: Integrasi Tanpa Hambatan untuk Penerapan Skalabel
Bobot sumber terbuka mengundang pengujian lokal, tetapi akses API menskalakan agen produksi dengan mudah. DeepSeek-V3.2 diterapkan melalui API resmi, bersama dengan antarmuka aplikasi dan web. Pengembang mengautentikasi dengan kunci API dari dasbor platform, lalu membuat kueri titik akhir dalam JSON yang kompatibel dengan OpenAI.
Untuk DeepSeek-V3.2-Speciale, akses terbatas pada API-only, sesuai dengan kebutuhan komputasi tinggi tanpa overhead lokal. Titik akhir mendukung parameter seperti alat untuk pemanggilan, meskipun Speciale memproses penalaran tanpa alat. Jendela konteks meluas hingga 128.000 token, dengan cache hits mengoptimalkan kueri berulang.
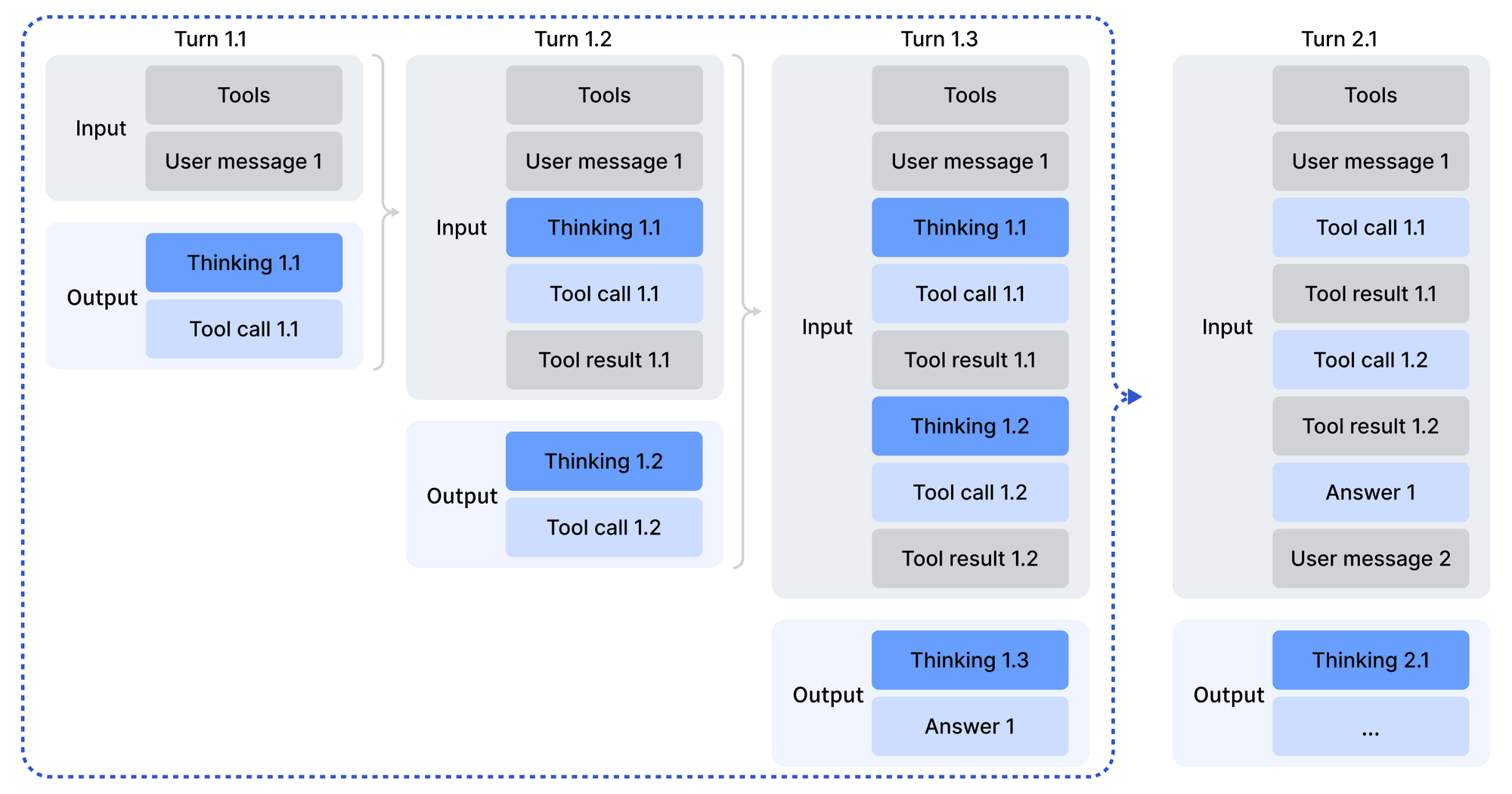
Integrasi memanfaatkan SDK dalam Python, Node.js, dan cURL. Contoh panggilan mengkodekan prompt dengan peran pengembang untuk skenario agen:
import openai
client = openai.OpenAI(
api_key="kunci_deepseek_anda",
base_url="https://api.deepseek.com"
)
response = client.chat.completions.create(
model="deepseek-v3.2",
messages=[{"role": "developer", "content": "Selesaikan masalah IMO ini: ..."}],
temperature=1.0,
top_p=0.95
)
Struktur ini mengurai keluaran melalui skrip yang disediakan, menangani pemanggilan alat jika berlaku. Akibatnya, agen merangkai respons, memanggil layanan eksternal di tengah penalaran.
Untuk meningkatkan alur kerja ini, Apidog terbukti sangat berharga. Ia membuat mock respons API, mendokumentasikan skema, dan menguji kasus-kasus batas—secara langsung berlaku untuk titik akhir DeepSeek. Unduh Apidog secara gratis untuk memvisualisasikan alur permintaan dan memastikan logika agen yang kuat sebelum penerapan.
Harga API: Efisiensi Biaya Bertemu Kinerja Tinggi
Harga API DeepSeek menekankan keterjangkauan, dengan peluncuran V3.2-Exp mengurangi biaya setengah dari V3.1-Terminus. Pengembang membayar per juta token: $0.028 untuk input cache hits, $0.28 untuk misses, dan $0.42 untuk output. Struktur ini memberi penghargaan pada konteks yang berulang, vital untuk loop agen.
Dibandingkan dengan pesaing, tarif ini memangkas harga GPT-5 yang $15–$75 per juta output. Mekanisme cache—yang mencapai 10% dari biaya miss—memungkinkan sesi panjang yang ekonomis. Untuk interaksi agen 10.000 token (80% cache hit), biaya turun di bawah $0.01, berskala linier.
Tingkat gratis menawarkan akses awal, beralih ke pembayaran sesuai penggunaan untuk pengembang. Paket perusahaan menyesuaikan volume, tetapi tarif dasar cukup untuk sebagian besar. Dengan demikian, penetapan harga selaras dengan etos sumber terbuka, mendemokratisasikan penalaran tingkat lanjut.
Sebuah kalkulator memperkirakan: Untuk 1 juta token input (50% hit) dan 200.000 output, total mendekati $0.20—sebagian kecil dibandingkan alternatif. Efisiensi ini memberdayakan tugas-tugas massal, mulai dari tinjauan kode hingga sintesis data.
Penjelasan Teknis Mendalam: Arsitektur dan Inovasi Pelatihan
DSA membentuk inti, melakukan sparsifikasi matriks perhatian secara dinamis. Untuk posisi i, ia memperhatikan jendela lokal dan kunci global, mengurangi FLOPs sebesar 40% pada 100 ribu konteks. Kuantisasi ke F8_E4M3 mengurangi memori setengah tanpa kehilangan akurasi, memungkinkan penerapan 8x A100.

Pelatihan mencakup pra-pelatihan pada 10T token, fine-tuning tersupervisi, dan RLHF dengan reward agen. Pipeline sintesis menghasilkan lebih dari 1 juta tugas, mensimulasikan keagenan dunia nyata. Pasca-pelatihan untuk Speciale mengalokasikan 10x komputasi, menyaring penalaran dari lintasan.
Inovasi-inovasi ini menghasilkan perilaku yang muncul: koreksi diri dalam 85% kegagalan HLE dan keberhasilan alat 92% pada T². Iterasi mendatang mungkin akan mengintegrasikan multimodality, sesuai peta jalan.
Kesimpulan: Memposisikan DeepSeek untuk Masa Depan Agen
DeepSeek-V3.2 dan DeepSeek-V3.2-Speciale mendefinisikan ulang penalaran sumber terbuka. Tolok ukur mengkonfirmasi keunggulan mereka, akses terbuka mengundang kolaborasi, dan API yang terjangkau memungkinkan skala. Pengembang membangun agen yang superior, mulai dari pemecah olimpiade hingga otomatisator perusahaan.
Seiring evolusi AI, model-model ini menetapkan preseden. Bereksperimenlah hari ini—unduh bobot dari Hugging Face, integrasikan melalui API, dan uji dengan Apidog. Jalur menuju sistem cerdas dimulai di sini.