
Apakah Anda ingin menerapkan Deepseek R1 —salah satu model bahasa besar yang paling kuat—di platform cloud? Baik Anda bekerja di AWS, Azure, atau Digital Ocean, panduan ini akan membantu Anda. Pada akhir postingan ini, Anda akan memiliki peta jalan yang jelas untuk membuat model Deepseek R1 Anda berjalan dengan mudah. Selain itu, kami akan menunjukkan kepada Anda bagaimana alat seperti Apidog dapat membantu menyederhanakan pengujian API selama penerapan.
Mengapa Menerapkan Deepseek R1 di Cloud?
Menerapkan Deepseek R1 di cloud bukan hanya tentang skalabilitas; ini tentang memanfaatkan kekuatan GPU dan infrastruktur tanpa server untuk menangani beban kerja besar secara efisien. Dengan 671B parameternya, Deepseek R1 membutuhkan perangkat keras yang kuat dan konfigurasi yang dioptimalkan. Cloud menyediakan fleksibilitas, efektivitas biaya, dan sumber daya berkinerja tinggi yang membuat penerapan model semacam itu layak bahkan untuk tim yang lebih kecil.
Dalam panduan ini, kami akan memandu Anda dalam menerapkan Deepseek R1 di tiga platform populer: AWS, Azure, dan Digital Ocean. Kami juga akan berbagi tips untuk mengoptimalkan kinerja dan mengintegrasikan alat seperti Apidog untuk manajemen API.
Mempersiapkan Lingkungan Anda
Sebelum melompat ke penerapan, mari siapkan lingkungan kita. Ini melibatkan pengaturan token otentikasi, memastikan ketersediaan GPU, dan mengatur file Anda.
Token Otentikasi
Setiap penyedia cloud memerlukan beberapa bentuk otentikasi. Contohnya:
- Di AWS , Anda memerlukan peran IAM dengan izin untuk mengakses bucket S3 dan instance EC2.
- Di Azure , Anda dapat menggunakan pengalaman otentikasi yang disederhanakan yang disediakan oleh Azure Machine Learning SDK.
- Di Digital Ocean , buat token API dari dasbor akun Anda.
Token ini sangat penting karena memungkinkan komunikasi yang aman antara mesin lokal Anda dan platform cloud.
Organisasi File
Atur file Anda secara sistematis. Jika Anda menggunakan Docker (yang sangat direkomendasikan), buat Dockerfile yang berisi semua dependensi. Alat seperti Tensorfuse menyediakan templat bawaan untuk menerapkan Deepseek R1. Demikian pula, pengguna IBM Cloud harus mengunggah file model mereka ke Object Storage sebelum melanjutkan.
Opsi 1: Menerapkan Deepseek R1 di AWS Menggunakan Tensorfuse
Mari kita mulai dengan Amazon Web Services (AWS), salah satu platform cloud yang paling banyak digunakan. AWS seperti pisau Swiss Army—ia memiliki alat untuk setiap tugas, dari penyimpanan hingga daya komputasi. Di bagian ini, kita akan fokus pada penerapan Deepseek R1 menggunakan Tensorfuse, yang menyederhanakan proses secara signifikan.
Mengapa Membangun dengan Deepseek-R1?
Sebelum menyelami detail teknis, mari kita pahami mengapa Deepseek R1 menonjol:
- Kinerja Tinggi pada Evaluasi: Mencapai hasil yang kuat pada tolok ukur standar industri, mencetak 90,8% pada MMLU dan 79,8% pada AIME 2024.
- Penalaran Tingkat Lanjut: Menangani tugas penalaran logis multi-langkah dengan konteks minimal, unggul dalam tolok ukur seperti LiveCodeBench (Pass@1-COT) dengan skor 65,9%.
- Dukungan Multibahasa: Dilatih sebelumnya pada data linguistik yang beragam, membuatnya mahir dalam pemahaman multibahasa.
- Model Distilasi yang Dapat Diskalakan: Varian distilasi yang lebih kecil (2B, 7B, dan 70B) menawarkan opsi yang lebih murah tanpa mengorbankan biaya.
Kekuatan ini menjadikan Deepseek R1 pilihan yang sangat baik untuk aplikasi siap produksi, dari chatbot hingga analitik data tingkat perusahaan.
Prasyarat
Sebelum Anda mulai, pastikan Anda telah mengonfigurasi Tensorfuse di akun AWS Anda. Jika Anda belum melakukannya, ikuti panduan Memulai. Pengaturan ini seperti menyiapkan ruang kerja Anda sebelum memulai proyek—ini memastikan semuanya ada di tempatnya untuk proses yang lancar.
Langkah 1: Atur Token Otentikasi API Anda
Hasilkan string acak yang akan digunakan sebagai token otentikasi API Anda. Simpan sebagai rahasia di Tensorfuse menggunakan perintah berikut:
tensorkube secret create vllm-token VLLM_API_KEY=vllm-key --env default
Pastikan bahwa dalam produksi, Anda menggunakan token yang dihasilkan secara acak. Anda dapat dengan cepat menghasilkan satu menggunakan openssl rand -base64 32 dan ingat untuk menjaganya tetap aman karena rahasia Tensorfuse bersifat buram.
Langkah 2: Siapkan Dockerfile
Kami akan menggunakan gambar OpenAI vLLM resmi sebagai gambar dasar kami. Gambar ini dilengkapi dengan semua dependensi yang diperlukan untuk menjalankan vLLM.
Berikut adalah konfigurasi Dockerfile:
# Dockerfile untuk Deepseek-R1-671B
FROM vllm/vllm-openai:latest
# Aktifkan Transfer HF Hub
ENV HF_HUB_ENABLE_HF_TRANSFER 1
# Ekspos port 80
EXPOSE 80
# Titik masuk dengan kunci API
ENTRYPOINT ["python3", "-m", "vllm.entrypoints.openai.api_server", \
"--model", "deepseek-ai/DeepSeek-R1", \
"--dtype", "bfloat16", \
"--trust-remote-code", \
"--tensor-parallel-size","8", \
"--max-model-len", "4096", \
"--port", "80", \
"--cpu-offload-gb", "80", \
"--gpu-memory-utilization", "0.95", \
"--api-key", "${VLLM_API_KEY}"]
Konfigurasi ini memastikan bahwa server vLLM dioptimalkan untuk persyaratan khusus Deepseek R1, termasuk pemanfaatan memori GPU dan paralelisme tensor .
Langkah 3: Konfigurasi Penerapan
Buat file deployment.yaml untuk menentukan pengaturan penerapan Anda:
# deployment.yaml untuk Deepseek-R1-671B
gpus: 8
gpu_type: h100
secret:
- vllm-token
min-scale: 1
readiness:
httpGet:
path: /health
port: 80
Terapkan layanan Anda menggunakan perintah berikut:
tensorkube deploy --config-file ./deployment.yaml
Perintah ini menyiapkan layanan LLM produksi penskalaan otomatis yang siap untuk melayani permintaan yang diautentikasi.
Langkah 4: Mengakses Aplikasi yang Diterapkan
Setelah penerapan berhasil, Anda dapat menguji titik akhir Anda menggunakan curl atau pustaka klien OpenAI Python. Berikut adalah contoh menggunakan curl:
curl --request POST \
--url YOUR_APP_URL/v1/completions \
--header 'Content-Type: application/json' \
--header 'Authorization: Bearer vllm-key' \
--data '{
"model": "deepseek-ai/DeepSeek-R1",
"prompt": "Earth to Robotland. What's up?",
"max_tokens": 200
}'
Untuk pengguna Python, berikut adalah cuplikan contoh:
import openai
# Ganti dengan URL dan token Anda yang sebenarnya
base_url = "YOUR_APP_URL/v1"
api_key = "vllm-key"
openai.api_base = base_url
openai.api_key = api_key
response = openai.Completion.create(
model="deepseek-ai/DeepSeek-R1",
prompt="Hello, Deepseek R1! How are you today?",
max_tokens=200
)
print(response)
Opsi 2: Menerapkan Deepseek R1 di Azure
Menerapkan Deepseek R1 di Azure Machine Learning (Azure ML) adalah proses yang disederhanakan yang memanfaatkan infrastruktur platform yang kuat dan alat canggih untuk inferensi waktu nyata. Di bagian ini, kami akan memandu Anda dalam menerapkan Deepseek R1 menggunakan Managed Online Endpoints Azure ML. Pendekatan ini memastikan skalabilitas, efisiensi, dan kemudahan pengelolaan.
Langkah 1: Buat Lingkungan Kustom untuk vLLM di Azure ML
Untuk memulai, kita perlu membuat lingkungan kustom yang disesuaikan untuk vLLM, yang akan berfungsi sebagai tulang punggung untuk menerapkan Deepseek R1. Kerangka kerja vLLM dioptimalkan untuk inferensi throughput tinggi, menjadikannya ideal untuk menangani model bahasa besar seperti Deepseek R1.
1.1: Tentukan Dockerfile :Kita mulai dengan membuat Dockerfile yang menentukan lingkungan untuk model kita. Kontainer dasar vLLM mencakup semua dependensi dan driver yang diperlukan, memastikan pengaturan yang lancar:
FROM vllm/vllm-openai:latest
ENV MODEL_NAME deepseek-ai/DeepSeek-R1-Distill-Llama-8B
ENTRYPOINT python3 -m vllm.entrypoints.openai.api_server --model $MODEL_NAME $VLLM_ARGS
Dockerfile ini memungkinkan kita untuk meneruskan nama model melalui variabel lingkungan (MODEL_NAME), memungkinkan fleksibilitas dalam memilih model yang diinginkan selama penerapan . Misalnya, Anda dapat dengan mudah beralih di antara berbagai versi Deepseek R1 tanpa memodifikasi kode yang mendasarinya.
1.2: Masuk ke Ruang Kerja Azure ML: Selanjutnya, masuk ke ruang kerja Azure ML Anda menggunakan Azure CLI. Ganti <subscription ID>, <Azure Machine Learning workspace name>, dan <resource group> dengan detail spesifik Anda:
az account set --subscription <subscription ID>
az configure --defaults workspace=<Azure Machine Learning workspace name> group=<resource group>
Langkah ini memastikan bahwa semua perintah berikutnya dieksekusi dalam konteks ruang kerja Anda.
1.3: Buat File Konfigurasi Lingkungan: Sekarang, buat file environment.yml untuk menentukan pengaturan lingkungan. File ini mereferensikan Dockerfile yang kita buat sebelumnya:
$schema: https://azuremlschemas.azureedge.net/latest/environment.schema.json
name: r1
build:
path: .
dockerfile_path: Dockerfile
1.4: Bangun Lingkungan: Dengan file konfigurasi yang siap, bangun lingkungan menggunakan perintah berikut:
az ml environment create -f environment.yml
Langkah ini mengkompilasi lingkungan, membuatnya tersedia untuk digunakan dalam penerapan Anda.
Langkah 2: Terapkan Azure ML Managed Online Endpoint
Setelah lingkungan disiapkan, kita beralih ke penerapan model Deepseek R1 menggunakan Azure ML’s Managed Online Endpoints. Titik akhir ini menyediakan kemampuan inferensi waktu nyata yang dapat diskalakan, menjadikannya sempurna untuk aplikasi tingkat produksi.
2.1: Buat File Konfigurasi Titik Akhir: Mulailah dengan membuat file endpoint.yml untuk menentukan Managed Online Endpoint:
$schema: https://azuremlsdk2.blob.core.windows.net/latest/managedOnlineEndpoint.schema.json
name: r1-prod
auth_mode: key
Konfigurasi ini menentukan nama titik akhir (r1-prod) dan mode otentikasi (key). Anda dapat mengambil URI penilaian dan kunci API titik akhir nanti untuk tujuan pengujian.
2.2: Buat Titik Akhir: Gunakan perintah berikut untuk membuat titik akhir:
az ml online-endpoint create -f endpoint.yml
2.3: Ambil Alamat Gambar Docker: Sebelum melanjutkan, ambil alamat gambar Docker yang dibuat pada Langkah 1. Navigasikan ke Azure ML Studio > Environments > r1 untuk menemukan alamat gambar. Akan terlihat seperti ini:
xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx
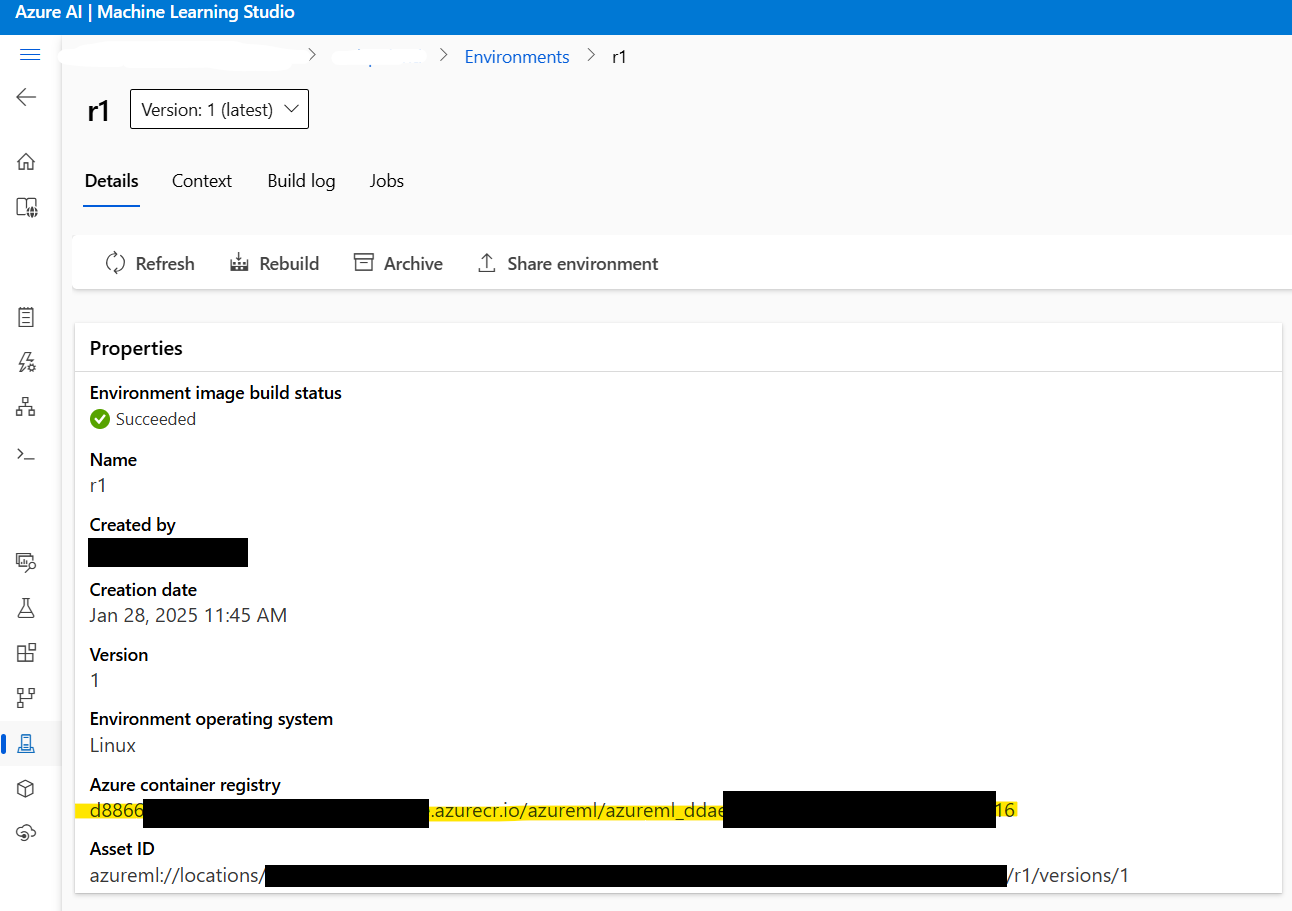
2.4: Buat File Konfigurasi Penerapan: Selanjutnya, buat file deployment.yml untuk mengonfigurasi pengaturan penerapan. File ini menentukan model, jenis instance, dan parameter lainnya:
$schema: https://azuremlschemas.azureedge.net/latest/managedOnlineDeployment.schema.json
name: current
endpoint_name: r1-prod
environment_variables:
MODEL_NAME: deepseek-ai/DeepSeek-R1-Distill-Llama-8B
VLLM_ARGS: "" # Argumen opsional untuk runtime vLLM
environment:
image: xxxxxx.azurecr.io/azureml/azureml_xxxxxxxx # Tempel alamat gambar Docker di sini
inference_config:
liveness_route:
port: 8000
path: /ping
readiness_route:
port: 8000
path: /health
scoring_route:
port: 8000
path: /
instance_type: Standard_NC24ads_A100_v4
instance_count: 1
request_settings: # Opsional tetapi penting untuk mengoptimalkan throughput
max_concurrent_requests_per_instance: 32
request_timeout_ms: 60000
liveness_probe:
initial_delay: 10
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
readiness_probe:
initial_delay: 120 # Tunggu selama 120 detik sebelum melakukan probing, memungkinkan model untuk memuat dengan tenang
period: 10
timeout: 2
success_threshold: 1
failure_threshold: 30
Parameter utama yang perlu dipertimbangkan:
instance_count: Menentukan berapa banyak nodeStandard_NC24ads_A100_v4yang akan diputar. Meningkatkan nilai ini menskalakan throughput secara linier tetapi juga meningkatkan biaya.max_concurrent_requests_per_instance: Mengontrol jumlah permintaan bersamaan yang diizinkan per instance. Nilai yang lebih tinggi meningkatkan throughput tetapi dapat meningkatkan latensi.request_timeout_ms: Menentukan waktu maksimum (dalam milidetik) titik akhir menunggu respons sebelum waktu habis. Sesuaikan ini berdasarkan persyaratan beban kerja Anda.
2.5: Terapkan Model: Terakhir, terapkan model Deepseek R1 menggunakan perintah berikut:
az ml online-deployment create -f deployment.yml --all-traffic
Langkah ini menyelesaikan penerapan, membuat model dapat diakses melalui titik akhir yang ditentukan .
Langkah 3: Menguji Penerapan
Setelah penerapan selesai, saatnya untuk menguji titik akhir untuk memastikan semuanya berfungsi seperti yang diharapkan.
3.1: Ambil Detail Titik Akhir: Gunakan perintah berikut untuk mengambil URI penilaian dan kunci API titik akhir:
az ml online-endpoint show -n r1-prod
az ml online-endpoint get-credentials -n r1-prod
3.2: Alirkan Respons Menggunakan OpenAI SDK: Untuk mengalirkan respons, Anda dapat menggunakan OpenAI SDK:
from openai import OpenAI
url = "https://r1-prod.polandcentral.inference.ml.azure.com/v1"
client = OpenAI(base_url=url, api_key="xxxxxxxx")
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-R1-Distill-Llama-8B",
messages=[
{"role": "user", "content": "What is better, summer or winter?"},
],
stream=True
)
for chunk in response:
delta = chunk.choices[0].delta
if hasattr(delta, "content"):
print(delta.content, end="", flush=True)
Langkah 4: Pemantauan dan Penskalaan Otomatis
Azure Monitor memberikan wawasan komprehensif tentang pemanfaatan sumber daya, termasuk metrik GPU. Saat berada di bawah beban konstan, Anda akan melihat bahwa vLLM mengonsumsi sekitar 90% memori GPU, dengan pemanfaatan GPU mendekati 100%. Metrik ini membantu Anda menyempurnakan kinerja dan mengoptimalkan biaya.
Untuk mengaktifkan penskalaan otomatis, konfigurasikan kebijakan penskalaan berdasarkan pola lalu lintas. Misalnya, Anda dapat meningkatkan instance_count selama jam sibuk dan menguranginya selama jam tidak sibuk untuk menyeimbangkan kinerja dan biaya.
Opsi 3: Menerapkan Deepseek R1 di Digital Ocean
Terakhir, mari kita bahas penerapan Deepseek R1 di Digital Ocean , yang dikenal karena kesederhanaan dan keterjangkauannya.
Prasyarat
Sebelum menyelami proses penerapan, mari pastikan Anda memiliki semua yang Anda butuhkan:
- Akun DigitalOcean: Jika Anda belum memilikinya, daftar untuk akun DigitalOcean. Pengguna baru menerima kredit $100 untuk 60 hari pertama, yang sempurna untuk bereksperimen dengan droplet bertenaga GPU.
- Keakraban dengan Bash Shell: Anda akan menggunakan terminal untuk berinteraksi dengan droplet Anda, mengunduh dependensi, dan menjalankan perintah. Jangan khawatir jika Anda bukan seorang ahli—setiap perintah akan diberikan langkah demi langkah.
- GPU Droplet: DigitalOcean sekarang menawarkan GPU droplet yang dirancang khusus untuk beban kerja AI/ML. Droplet ini dilengkapi dengan GPU NVIDIA H100, menjadikannya ideal untuk menerapkan model besar seperti Deepseek R1.
Dengan prasyarat ini, Anda siap untuk bergerak maju.
Menyiapkan GPU Droplet
Langkah pertama adalah menyiapkan mesin Anda. Anggap ini sebagai persiapan kanvas sebelum melukis—Anda ingin semuanya siap sebelum menyelami detailnya.
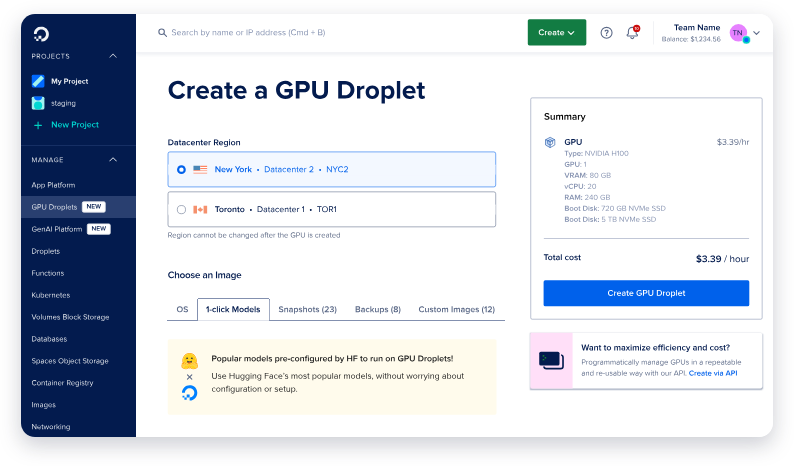
Langkah 1: Buat GPU Droplet Baru
- Masuk ke akun DigitalOcean Anda dan navigasikan ke bagian Droplets.
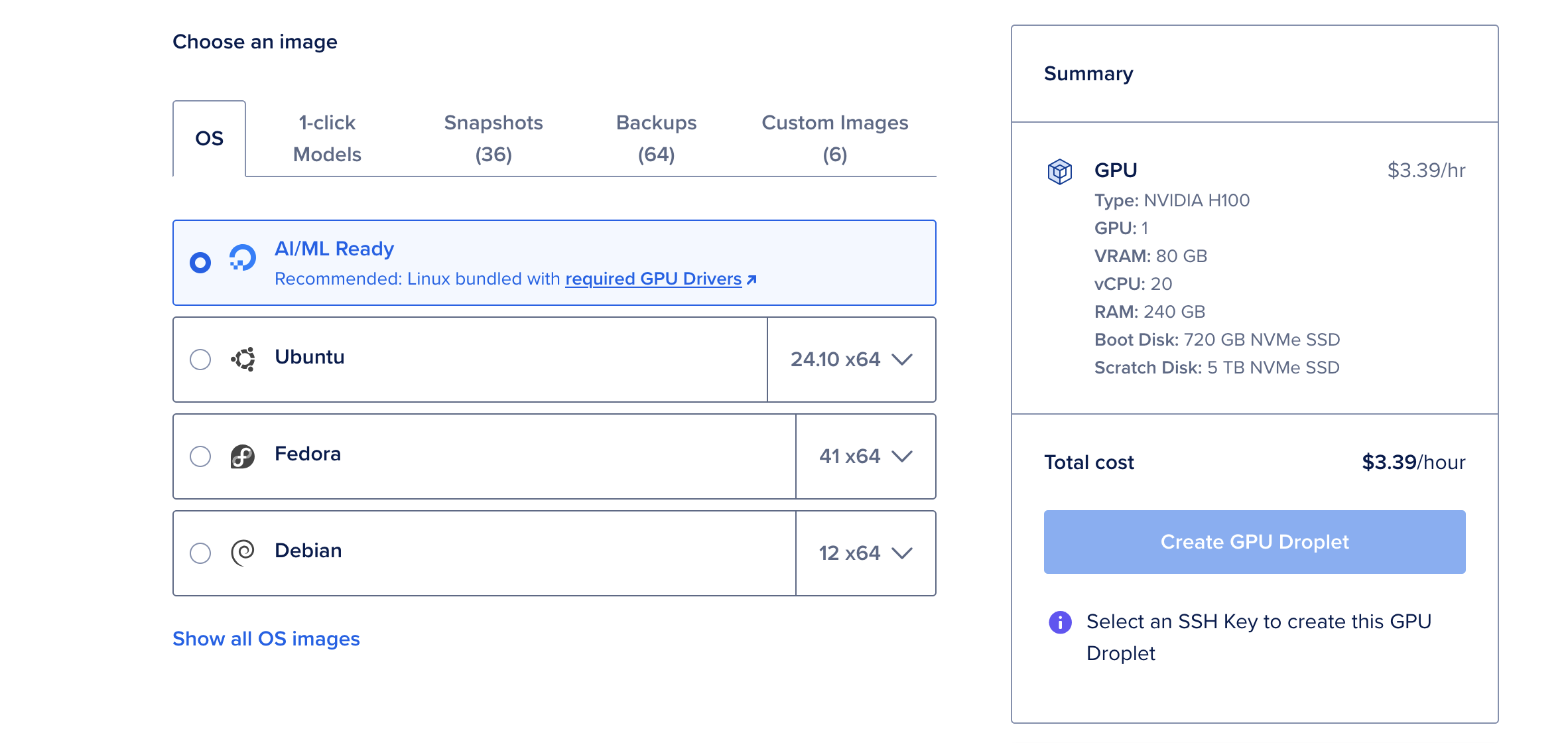
- Klik Create Droplet dan pilih sistem operasi AI/ML Ready. OS ini sudah dikonfigurasi sebelumnya dengan driver CUDA dan dependensi lain yang diperlukan untuk akselerasi GPU.
- Pilih GPU NVIDIA H100 tunggal kecuali Anda berencana untuk menerapkan versi parameter 671B terbesar dari Deepseek R1, yang mungkin memerlukan beberapa GPU.
- Setelah droplet Anda dibuat, tunggu hingga berputar. Proses ini biasanya hanya membutuhkan beberapa menit.
Mengapa Memilih GPU H100?
GPU NVIDIA H100 adalah pembangkit tenaga listrik, menawarkan vRAM 80GB, RAM 240GB, dan penyimpanan 720GB. Dengan $6,47 per jam, ini adalah opsi hemat biaya untuk menerapkan model bahasa besar seperti Deepseek R1. Untuk model yang lebih kecil, seperti versi parameter 70B, GPU H100 tunggal lebih dari cukup.
Memasang Ollama & Deepseek R1
Sekarang setelah GPU droplet Anda aktif dan berjalan, saatnya untuk memasang alat yang diperlukan untuk menjalankan Deepseek R1. Kita akan menggunakan Ollama, kerangka kerja ringan yang dirancang untuk menyederhanakan penerapan model bahasa besar.
Langkah 1: Buka Konsol Web
Dari halaman detail droplet Anda, klik tombol Web Console yang terletak di sudut kanan atas. Ini membuka jendela terminal langsung di browser Anda, menghilangkan kebutuhan akan konfigurasi SSH.
Langkah 2: Pasang Ollama
Di terminal, tempel perintah berikut untuk memasang Ollama:
curl -fsSL https://ollama.com/install.sh | sh
Skrip ini mengotomatiskan proses pemasangan, mengunduh dan mengonfigurasi semua dependensi yang diperlukan. Pemasangan mungkin memakan waktu beberapa menit, tetapi setelah selesai, mesin Anda akan siap untuk menjalankan Deepseek R1.
Langkah 3: Jalankan Deepseek R1
Dengan Ollama terpasang, menjalankan Deepseek R1 semudah menjalankan satu perintah. Untuk demonstrasi ini, kita akan menggunakan versi parameter 70B, yang mencapai keseimbangan antara kinerja dan penggunaan sumber daya:
ollama run deepseek-r1:70b
Saat pertama kali Anda menjalankan perintah ini, ia akan mengunduh model (sekitar 40GB) dan memuatnya ke dalam memori. Proses ini dapat memakan waktu beberapa menit, tetapi menjalankan berikutnya akan jauh lebih cepat karena model di-cache secara lokal.
Setelah model dimuat, Anda akan melihat prompt interaktif tempat Anda dapat mulai berinteraksi dengan Deepseek R1. Ini seperti melakukan percakapan dengan asisten yang sangat cerdas!
Pengujian dan Pemantauan dengan Apidog
Setelah model Deepseek R1 Anda diterapkan, saatnya untuk menguji dan memantau kinerjanya. Di sinilah Apidog bersinar. Uji DeepSeek API di sini.
Apa Itu Apidog?
Apidog adalah alat pengujian API yang kuat yang dirancang untuk menyederhanakan debugging dan validasi. Dengan antarmuka intuitifnya, Anda dapat dengan cepat membuat kasus pengujian, respons tiruan, dan memantau kesehatan API.
Mengapa Menggunakan Apidog?
- Kemudahan Penggunaan : Tidak diperlukan pengkodean! Fungsionalitas seret dan lepas memungkinkan Anda membuat pengujian secara visual.
- Kemampuan Integrasi : Terintegrasi dengan mulus dengan pipeline CI/CD, menjadikannya ideal untuk alur kerja DevOps.
- Wawasan Waktu Nyata : Pantau latensi, tingkat kesalahan, dan throughput secara waktu nyata.
Dengan mengintegrasikan Apidog ke dalam alur kerja Anda, Anda dapat memastikan bahwa penerapan Deepseek R1 Anda tetap andal dan berkinerja optimal di bawah berbagai beban.
Kesimpulan
Menerapkan Deepseek R1 di cloud tidak harus menakutkan. Dengan mengikuti langkah-langkah yang diuraikan di atas, Anda dapat berhasil menyiapkan model mutakhir ini di AWS, Azure, atau Digital Ocean. Ingatlah untuk memanfaatkan alat seperti Apidog untuk menyederhanakan proses pengujian dan pemantauan.


