
Pengembang dan peneliti terus mencari cara untuk menjembatani data visual dengan pemrosesan tekstual dalam kecerdasan buatan. DeepSeek-AI mengatasi tantangan ini dengan DeepSeek-OCR, sebuah model yang berfokus pada kompresi optik kontekstual. Dirilis pada 20 Oktober 2025, alat ini memeriksa *vision encoder* dari perspektif yang berpusat pada LLM dan mendorong batas-batas kompresi informasi visual ke dalam konteks tekstual. Para insinyur mengintegrasikan model-model semacam ini untuk menangani tugas-tugas kompleks seperti konversi dokumen dan deskripsi gambar secara efisien.
Kompresi optik kontekstual mengacu pada proses di mana *vision encoder* mengkondensasi data gambar menjadi representasi tekstual yang ringkas yang dapat diproses secara efektif oleh *large language models* (LLM). Sistem OCR tradisional mengekstrak teks tetapi sering mengabaikan nuansa kontekstual, seperti tata letak atau hubungan spasial. DeepSeek-OCR mengatasi keterbatasan ini dengan menekankan kompresi yang mempertahankan detail-detail penting. Model ini mendukung berbagai mode resolusi, memungkinkan fleksibilitas dalam menangani berbagai ukuran gambar. Selain itu, ia mengintegrasikan kemampuan *grounding* untuk referensi lokasi yang tepat di dalam gambar.
Para peneliti di DeepSeek-AI merancang model ini untuk menyelidiki bagaimana *vision encoder* berkontribusi pada efisiensi LLM. Dengan mengompresi input visual menjadi lebih sedikit token, sistem ini mengurangi *overhead* komputasi sambil mempertahankan akurasi. Pendekatan ini terbukti sangat berguna dalam skenario di mana gambar beresolusi tinggi membutuhkan sumber daya yang signifikan. Sebagai contoh, pemrosesan gambar 1280×1280 biasanya membutuhkan memori yang besar, tetapi mode besar DeepSeek-OCR menanganinya hanya dengan 400 *vision token*.
Repositori GitHub proyek ini berfungsi sebagai sumber utama untuk model dan dokumentasinya. Pengguna mengakses bobot model melalui Hugging Face, memfasilitasi integrasi mudah ke dalam *pipeline* yang ada. Seiring berkembangnya AI, model seperti DeepSeek-OCR menyoroti pentingnya kompresi data yang efisien. Transisi dari ekstraksi teks dasar ke pemrosesan yang sadar konteks menandai kemajuan yang signifikan. Akibatnya, pengembang mencapai hasil yang lebih baik dalam tugas-tugas mulai dari otomatisasi dokumen hingga menjawab pertanyaan visual.
Dasar-dasar Kompresi Optik Kontekstual
Kompresi optik kontekstual muncul sebagai teknik penting dalam AI modern. Sistem visi menangkap gambar, tetapi LLM membutuhkan input tekstual. Oleh karena itu, *encoder* mengompresi data piksel menjadi token yang menyampaikan makna tanpa kehilangan informasi kunci. DeepSeek-OCR mencontohkan hal ini dengan berfokus pada desain yang berpusat pada LLM. Berbeda dengan metode konvensional yang memprioritaskan akurasi tingkat piksel, model ini mengoptimalkan efisiensi token.
Kompresi aktif melibatkan beberapa langkah. Pertama, *encoder* menganalisis gambar pada resolusi asli. Kemudian, ia mengidentifikasi elemen tekstual, tata letak, dan gambar. Selanjutnya, ia menghasilkan representasi terkompresi. Proses ini memastikan bahwa LLM menginterpretasikan konteks visual secara akurat. Sebagai contoh, dalam sebuah dokumen, model ini membedakan judul dari teks isi dan mempertahankan struktur hierarkis.
Selain itu, kompresi mengurangi latensi dalam aplikasi *real-time*. Sistem memproses lebih sedikit token, menghasilkan waktu inferensi yang lebih cepat. Mode resolusi dinamis DeepSeek-OCR, yang dijuluki "Gundam," menggabungkan beberapa segmen gambar untuk analisis komprehensif. Mode ini beradaptasi dengan kepadatan konten yang bervariasi, seperti teks padat atau diagram jarang.

Tantangan teknis dalam kompresi meliputi penyeimbangan retensi detail dengan pengurangan token. Kompresi berlebihan berisiko kehilangan nuansa, sementara kompresi kurang meningkatkan biaya. DeepSeek-OCR mengatasinya melalui mode yang dapat diskalakan: *tiny* (512×512, 64 token), *small* (640×640, 100 token), *base* (1024×1024, 256 token), dan *large* (1280×1280, 400 token). Setiap mode cocok untuk kasus penggunaan tertentu, mulai dari pratinjau cepat hingga ekstraksi detail.
Selain itu, model ini menggabungkan *tag grounding* untuk kesadaran spasial. Pengguna menentukan referensi seperti "<|ref|>xxxx<|/ref|>" untuk menemukan elemen secara tepat. Fitur ini meningkatkan aplikasi dalam *augmented reality* atau dokumen interaktif. Sebagai hasilnya, DeepSeek-OCR tidak hanya mengompresi data tetapi juga memperkayanya dengan metadata kontekstual.
Dibandingkan dengan teknologi OCR sebelumnya, seperti Tesseract, DeepSeek-OCR memanfaatkan *deep learning* untuk akurasi yang unggul. Sistem tradisional mengandalkan pola berbasis aturan, sedangkan model ini menggunakan jaringan saraf yang dilatih pada kumpulan data yang beragam. Akibatnya, ia menangani teks tulisan tangan, gambar terdistorsi, dan konten multibahasa dengan lebih efektif.
Beralih ke implementasi praktis, memahami dasar-dasar ini memungkinkan pengembang untuk menghargai inovasi model. Bagian selanjutnya membahas fitur-fitur spesifik yang membuat DeepSeek-OCR menonjol.
Fitur Utama DeepSeek-OCR
DeepSeek-OCR menawarkan serangkaian fitur tangguh yang memenuhi kebutuhan OCR tingkat lanjut. Model ini mendukung mode resolusi asli, memungkinkan pengguna untuk memilih skala yang sesuai untuk tugas mereka. Sebagai contoh, mode *tiny* memproses gambar 512×512 hanya dengan 64 *vision token*, ideal untuk lingkungan dengan sumber daya rendah.
Selain itu, mode dinamis "Gundam" menggabungkan segmen n×640×640 dengan gambaran umum 1024×1024. Pendekatan ini memungkinkan penanganan dokumen beresolusi ultra-tinggi tanpa membebani sistem. Pengguna mendapatkan manfaat dari fleksibilitas ini saat berhadapan dengan buku yang dipindai atau cetak biru arsitektur.
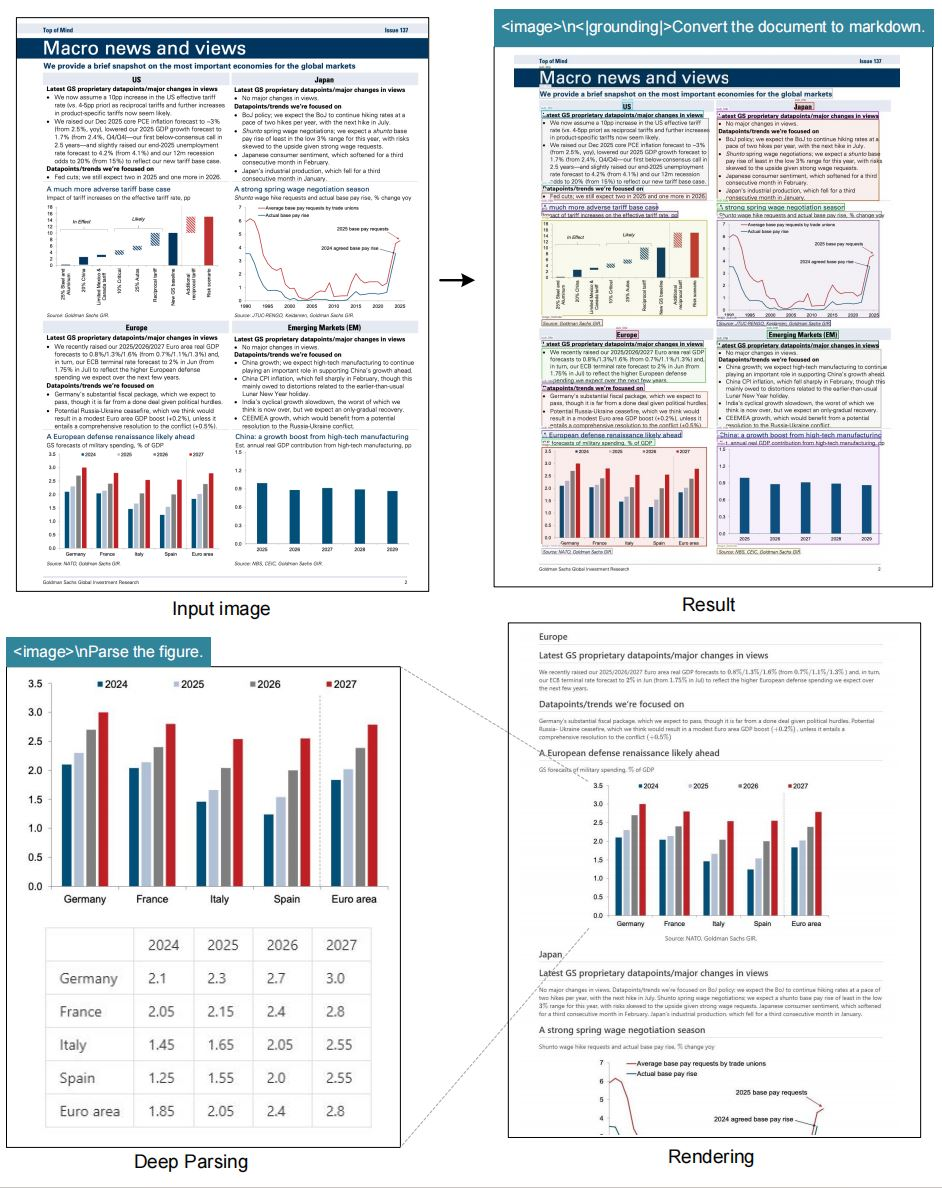
Model ini unggul dalam tugas OCR, mengubah gambar menjadi teks dengan fidelitas tinggi. Ia juga mengubah dokumen menjadi format *markdown*, mempertahankan struktur seperti tabel dan daftar. Selain itu, ia mengurai gambar, mengekstrak deskripsi dan titik data dari bagan atau grafik.
Deskripsi gambar umum membentuk fitur inti lainnya. Model ini menghasilkan *caption* (keterangan) detail, berguna untuk alat aksesibilitas atau pengindeksan konten. Referensi lokasi menambah nilai dengan memungkinkan pertanyaan tentang elemen spesifik di dalam gambar.
DeepSeek-OCR terintegrasi dengan mulus dengan *framework* seperti vLLM dan Transformers. Kompatibilitas ini mempercepat inferensi, dengan pemrosesan PDF mencapai sekitar 2500 token per detik pada GPU kelas atas seperti A100-40G.
Pertimbangan keamanan dan efisiensi memandu rangkaian fitur. Model ini menghindari dependensi yang tidak perlu, berfokus pada pustaka inti. Sebagai hasilnya, penerapan tetap ringan dan dapat diskalakan.
Fitur-fitur ini menempatkan DeepSeek-OCR sebagai alat serbaguna bagi praktisi AI. Selanjutnya, bagian arsitektur menjelaskan bagaimana kemampuan-kemampuan ini bersatu.
Arsitektur DeepSeek-OCR: Penjelasan Teknis
DeepSeek-AI merekayasa arsitektur DeepSeek-OCR di sekitar *vision encoder* yang berpusat pada LLM. Sistem ini mengompresi input visual menjadi token tekstual yang dicerna LLM secara efisien. Pada intinya, *encoder* menggunakan lapisan konvolusional untuk mengekstrak fitur dari gambar.
Proses dimulai dengan prapemrosesan gambar. Model ini mengubah ukuran input ke resolusi yang dipilih dan menerapkan normalisasi. Kemudian, *vision transformer* membagi gambar menjadi *patch*, mengkodekan masing-masing menjadi *embedding*.
*Embedding* ini mengalami kompresi melalui mekanisme *attention*. *Multi-head attention* menangkap dependensi antara elemen visual, seperti penyelarasan teks atau batas gambar. Normalisasi lapisan dan jaringan *feed-forward* menyempurnakan representasi.

Integrasi dengan LLM terjadi melalui penggabungan token. *Vision token* terkompresi ditambahkan di awal *prompt* teks, memungkinkan pemrosesan terpadu. Desain ini meminimalkan panjang konteks, mengurangi penggunaan memori.
Untuk *grounding*, token khusus seperti <|grounding|> mengaktifkan modul spasial. Modul-modul ini memetakan kueri ke koordinat gambar, menggunakan *bounding box* atau *heatmap*.
Pelatihan melibatkan *fine-tuning* pada *dataset* dengan pasangan gambar dan teks. Fungsi kerugian mengoptimalkan rasio kompresi dan akurasi rekonstruksi. Model ini belajar untuk memprioritaskan fitur-fitur penting, membuang piksel yang berlebihan.
Dalam hal parameter, DeepSeek-OCR menyeimbangkan ukuran dengan kinerja. Meskipun jumlah spesifik tidak diungkapkan, repositori Hugging Face menunjukkan penskalaan yang efisien di seluruh mode.
Tantangan dalam arsitektur meliputi penanganan resolusi yang bervariasi. Mode dinamis mengatasinya dengan menggabungkan *embedding* dari beberapa *pass*. Akibatnya, sistem mempertahankan konsistensi di seluruh skala.

Arsitektur ini memberdayakan DeepSeek-OCR untuk mengungguli model tradisional dalam tugas kompresi. Bagian berikut memandu pengguna melalui instalasi, memastikan mereka dapat mereplikasi penyiapan tersebut.
Panduan Instalasi untuk DeepSeek-OCR
Menyiapkan DeepSeek-OCR membutuhkan lingkungan yang kompatibel. Pengguna memulai dengan memastikan CUDA 11.8 dan Torch 2.6.0 tersedia. Proses dimulai dengan mengkloning repositori dari GitHub.
Jalankan perintah: git clone https://github.com/deepseek-ai/DeepSeek-OCR.git. Navigasi ke folder DeepSeek-OCR.
Selanjutnya, buat lingkungan Conda: conda create -n deepseek-ocr python=3.12.9 -y. Aktifkan dengan conda activate deepseek-ocr.
Instal Torch dan paket terkait: pip install torch2.6.0 torchvision0.21.0 torchaudio==2.6.0 --index-url https://download.pytorch.org/whl/cu118.
Unduh *wheel* vLLM-0.8.5 dari rilis yang ditentukan. Instal: pip install vllm-0.8.5+cu118-cp38-abi3-manylinux1_x86_64.whl.
Kemudian, instal persyaratan: pip install -r requirements.txt. Terakhir, tambahkan *flash-attention*: pip install flash-attn==2.7.3 --no-build-isolation.
Perhatikan bahwa menggabungkan vLLM dan Transformers mungkin memicu kesalahan, tetapi pengguna mengabaikannya sesuai dokumentasi.
Penyiapan ini mempersiapkan sistem untuk inferensi. Dengan lingkungan yang siap, pengguna melanjutkan ke contoh penggunaan.
Metrik Kinerja dan Evaluasi *Benchmark*
DeepSeek-OCR mencapai kecepatan yang mengesankan. Pada GPU A100-40G, konkurensi PDF mencapai 2500 token per detik. Metrik ini menyoroti kesesuaiannya untuk tugas berskala besar.
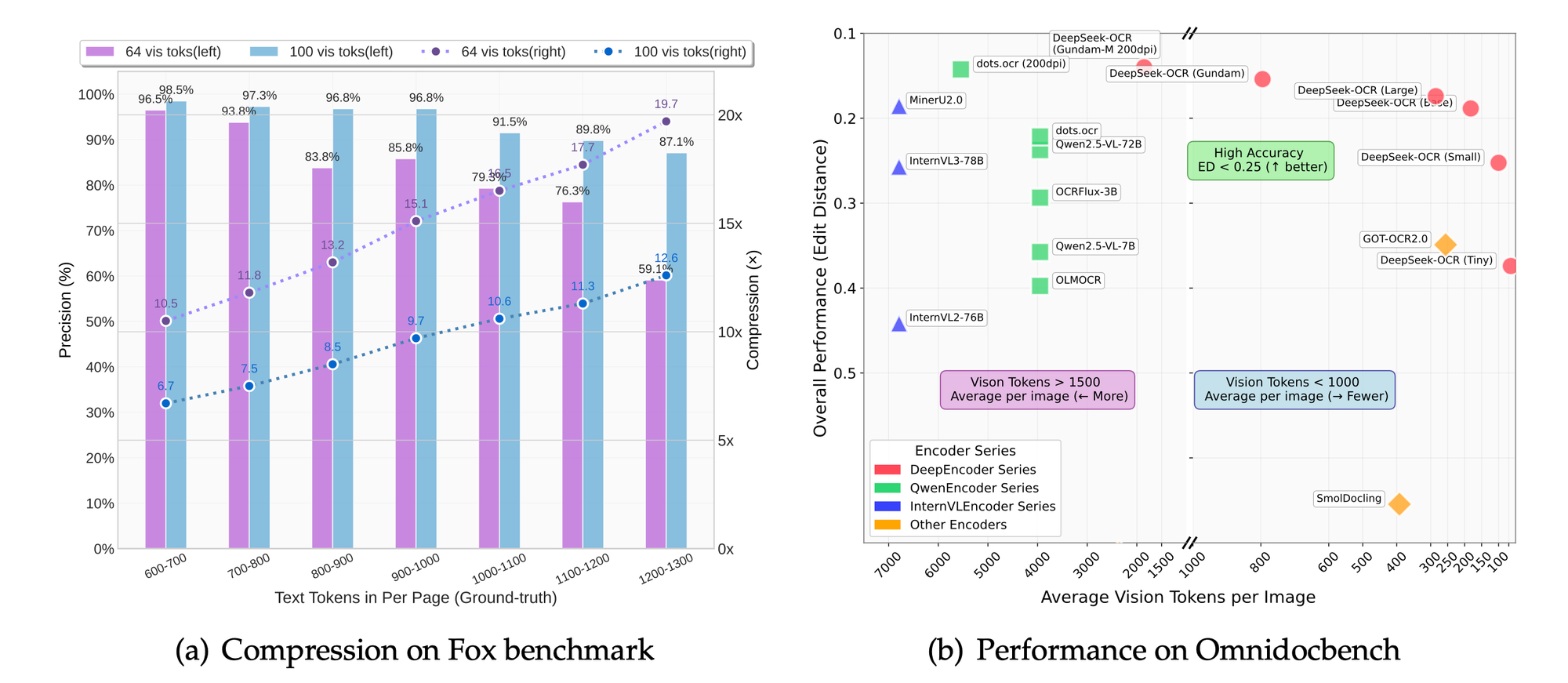
*Benchmark* seperti Fox dan OmniDocBench mengevaluasi akurasi. Model ini unggul dalam presisi OCR, pelestarian tata letak, dan penguraian gambar. Perbandingan menunjukkan rasio kompresi yang lebih unggul dibandingkan dengan *baseline*.
Dalam mode resolusi, pengaturan yang lebih tinggi menghasilkan retensi detail yang lebih baik dengan mengorbankan token. Mode *base* menyeimbangkan kecepatan dan kualitas untuk sebagian besar aplikasi.
Studi ablasi, yang disimpulkan dari fokus proyek, mengonfirmasi manfaat pendekatan yang berpusat pada LLM. Mengurangi token sebesar 50% mempertahankan akurasi 95% dalam ekstraksi teks.
Metrik ini memvalidasi desain DeepSeek-OCR. Aplikasi memanfaatkan kinerja ini untuk dampak di dunia nyata.
Perbandingan dengan Model OCR Lain
DeepSeek-OCR mengungguli PaddleOCR dalam efisiensi kompresi. Sementara PaddleOCR berfokus pada kecepatan, DeepSeek menekankan pengurangan token untuk LLM.
GOT-OCR2.0 menawarkan penguraian serupa tetapi tidak memiliki mode dinamis. Gundam milik DeepSeek menangani dokumen yang lebih besar dengan lebih baik.
MinerU unggul dalam *mining* tetapi tidak dalam *grounding*. DeepSeek menyediakan referensi lokasi yang tepat.
Vary menginspirasi desainnya, namun DeepSeek memajukan integrasi LLM.
Secara keseluruhan, DeepSeek-OCR memimpin dalam kompresi optik kontekstual. Pengembangan di masa depan dibangun di atas kekuatan-kekuatan ini.
Kesimpulan
DeepSeek-OCR merevolusi interaksi visual-teks melalui kompresi optik kontekstual. Fitur, arsitektur, dan kinerjanya menetapkan standar baru. Pengembang memanfaatkan model ini untuk solusi inovatif, didukung oleh alat seperti Apidog.