
Keluarga Qwen 3 mendominasi lanskap LLM sumber terbuka pada tahun 2025. Para insinyur menyebarkan model-model ini di mana-mana—mulai dari agen perusahaan yang sangat penting hingga asisten seluler. Sebelum Anda mulai mengirim permintaan ke Alibaba Cloud atau melakukan *self-hosting*, sederhanakan alur kerja Anda dengan Apidog.
Ikhtisar Qwen 3: Inovasi Arsitektur yang Mendorong Kinerja Tahun 2025
Tim Qwen Alibaba merilis seri Qwen 3 pada 29 April 2025, menandai kemajuan penting dalam model bahasa besar (LLM) sumber terbuka. Pengembang memuji lisensi Apache 2.0-nya, yang memungkinkan penyetelan halus (*fine-tuning*) dan penerapan komersial tanpa batasan. Pada intinya, Qwen 3 menggunakan arsitektur berbasis Transformer dengan peningkatan dalam *positional embeddings* dan mekanisme perhatian, mendukung panjang konteks hingga 128K token secara native—dan dapat diperluas hingga 131K melalui YaRN.

Selain itu, seri ini menggabungkan desain Mixture-of-Experts (MoE) dalam varian-varian tertentu, hanya mengaktifkan sebagian kecil parameter selama inferensi. Pendekatan ini mengurangi *overhead* komputasi sambil mempertahankan fidelitas tinggi dalam keluaran. Misalnya, para insinyur melaporkan *throughput* hingga 10x lebih cepat pada tugas-tugas konteks panjang dibandingkan dengan pendahulu padat seperti Qwen2.5-72B. Akibatnya, varian Qwen 3 berskala efisien di berbagai perangkat keras, dari perangkat *edge* hingga kluster *cloud*.
Qwen 3 juga unggul dalam dukungan multibahasa, menangani lebih dari 119 bahasa dengan *instruction-following* yang bernuansa. Tolok ukur mengonfirmasi keunggulannya dalam domain STEM, di mana ia memproses data matematika dan kode sintetis yang disempurnakan dari 36 triliun token. Oleh karena itu, aplikasi di perusahaan global mendapat manfaat dari berkurangnya kesalahan terjemahan dan peningkatan penalaran lintas bahasa. Beralih ke hal-hal spesifik, mode penalaran hibrida—yang diaktifkan melalui *tokenizer flags*—memungkinkan model untuk menggunakan logika langkah demi langkah untuk matematika atau pengkodean, atau beralih ke mode non-berpikir untuk dialog. Dualitas ini memberdayakan pengembang untuk mengoptimalkan setiap kasus penggunaan.
Fitur Utama yang Menyatukan Varian Qwen 3
Semua model Qwen 3 memiliki karakteristik dasar yang meningkatkan kegunaannya pada tahun 2025. Pertama, model-model ini mendukung operasi dual-mode: mode berpikir mengaktifkan proses *chain-of-thought* untuk tolok ukur seperti AIME25, sementara mode non-berpikir memprioritaskan kecepatan untuk aplikasi obrolan. Para insinyur mengaktifkan ini dengan parameter sederhana, mencapai akurasi hingga 92,3% pada matematika kompleks tanpa mengorbankan latensi.
Kedua, fitur agensi memungkinkan panggilan alat (*tool-calling*) yang mulus, mengungguli rekan-rekan sumber terbuka dalam tugas-tugas seperti navigasi peramban atau eksekusi kode. Misalnya, varian Qwen 3 mencetak 69,6 pada Tau2-Bench Verified, menyaingi model proprietary. Selain itu, kehebatan multibahasanya mencakup dialek dari Mandarin hingga Swahili, dengan 73,0 pada tolok ukur MultiIF.
Ketiga, efisiensi berasal dari varian terkuantisasi (misalnya, Q4_K_M) dan kerangka kerja seperti vLLM atau SGLang, yang menghasilkan 25 token/detik pada GPU konsumen. Namun, model yang lebih besar membutuhkan VRAM 16GB+, mendorong penerapan *cloud*. Penetapan harga tetap kompetitif, dengan token input seharga $0,20–$1,20 per juta melalui Alibaba Cloud.
Selain itu, Qwen 3 menekankan keamanan melalui moderasi bawaan, mengurangi halusinasi sebesar 15% dibandingkan Qwen2.5. Pengembang memanfaatkan ini untuk aplikasi kelas produksi, mulai dari rekomendasi e-commerce hingga penganalisis hukum. Saat kita beralih ke varian individual, kekuatan bersama ini menyediakan dasar yang konsisten untuk perbandingan.
5 Varian Model Qwen 3 Terbaik Tahun 2025
Berdasarkan tolok ukur tahun 2025 dari LMSYS Arena, LiveCodeBench, dan SWE-Bench, kami menyusun peringkat lima varian Qwen 3 teratas. Kriteria pemilihan meliputi skor penalaran, kecepatan inferensi, efisiensi parameter, dan aksesibilitas API. Masing-masing unggul dalam skenario yang berbeda, tetapi semuanya memajukan batas-batas sumber terbuka.
1. Qwen3-235B-A22B – Monster MoE Unggulan Mutlak
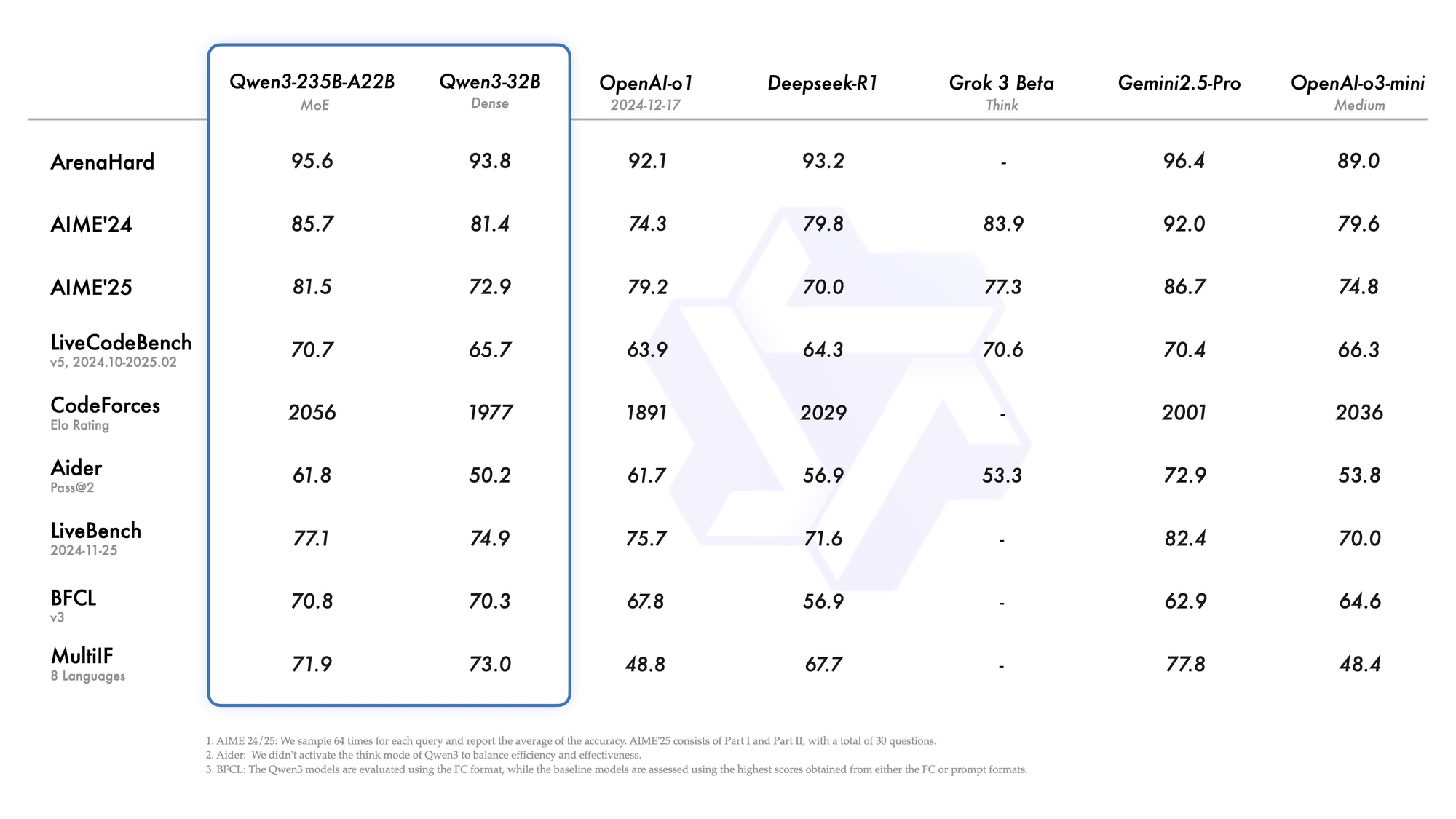
Qwen3-235B-A22B menarik perhatian sebagai varian MoE terkemuka, dengan total 235 miliar parameter dan 22 miliar parameter aktif per token. Dirilis pada Juli 2025 sebagai Qwen3-235B-A22B-Instruct-2507, model ini mengaktifkan delapan *expert* melalui *top-k routing*, mengurangi komputasi sebesar 90% dibandingkan dengan model padat yang setara. Tolok ukur menempatkannya setara dengan Gemini 2.5 Pro: 95,6 pada ArenaHard, 77,1 pada LiveBench, dan kepemimpinan dalam CodeForces Elo (memimpin sebesar 5%).
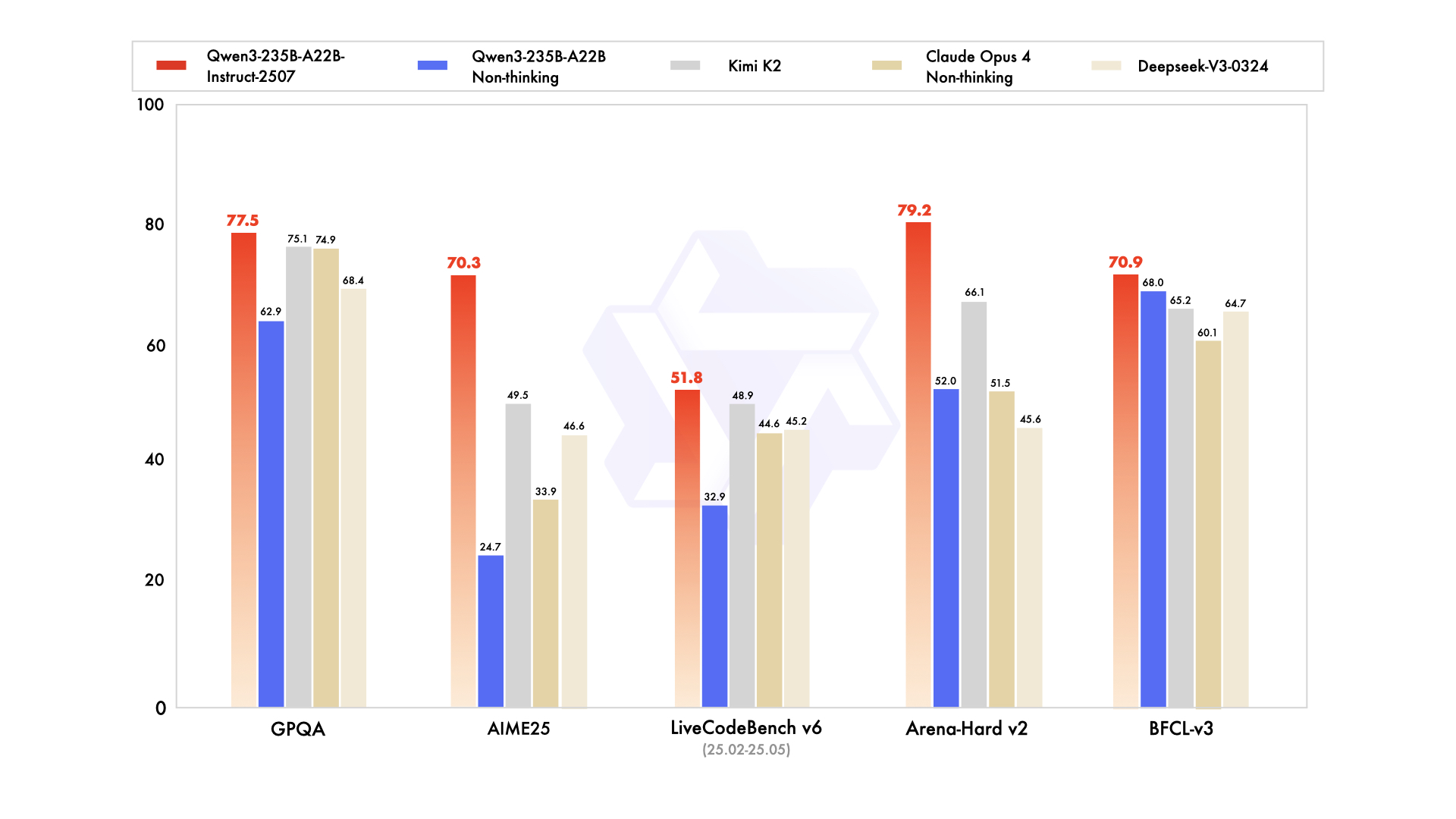
Dalam pengkodean, ia mencapai 74,8 pada LiveCodeBench v6, menghasilkan TypeScript fungsional dengan iterasi minimal. Untuk matematika, mode berpikir menghasilkan 92,3 pada AIME25, menyelesaikan integral multi-langkah melalui deduksi eksplisit. Tugas multibahasa mencetak 73,0 pada MultiIF, memproses pertanyaan berbahasa Arab dengan sempurna.
Penerapan mendukung API *cloud*, di mana ia menangani 256K konteks. Namun, eksekusi lokal memerlukan 8x GPU H100. Para insinyur mengintegrasikannya untuk alur kerja agensi, seperti *debugging* skala repositori. Secara keseluruhan, varian ini menetapkan standar tahun 2025 untuk kedalaman, meskipun skalanya cocok untuk tim dengan anggaran tinggi.
Keunggulan
- Menyamai atau mengalahkan Gemini 2.5 Pro dan Claude 3.7 Sonnet di hampir setiap papan peringkat tahun 2025 (95,6 ArenaHard, 92,3 mode berpikir AIME25, 74,8 LiveCodeBench v6).
- Unggul dalam alur kerja agensi multi-giliran, panggilan alat kompleks, dan pemahaman kode tingkat repositori.
- Menangani konteks 256K–1M dengan YaRN tanpa penurunan kualitas.
- Mode berpikir memberikan penalaran *chain-of-thought* yang dapat diverifikasi yang menyaingi model *frontier* sumber tertutup.
Kelemahan
- Sangat mahal dan lambat secara lokal—membutuhkan 8×H100 atau yang setara untuk latensi yang wajar.
- Harga API adalah yang tertinggi dalam keluarga ($1,20–$6,00/juta token keluaran pada konteks puncak).
- Terlalu berlebihan untuk 95% beban kerja produksi; sebagian besar tim tidak pernah memenuhi kapasitasnya.
Kapan menggunakannya
- Agen otonom kelas perusahaan yang harus menyelesaikan matematika tingkat PhD, men-debug seluruh basis kode, atau melakukan analisis kontrak hukum dengan hampir nol halusinasi.
- Laboratorium penelitian beranggaran tinggi yang mendorong *state-of-the-art* pada tolok ukur baru.
- Backend penalaran internal di mana biaya per token menjadi sekunder dibandingkan dengan kecerdasan maksimum.
2. Qwen3-30B-A3B – Juara MoE Titik Manis (*Sweet Spot*)
Qwen3-30B-A3B muncul sebagai pilihan utama untuk pengaturan yang terbatas sumber daya, menampilkan total 30,5 miliar parameter dan 3,3 miliar parameter aktif. Struktur MoE-nya—48 lapisan, 128 *expert* (delapan di-routing)—mencerminkan model unggulan tetapi dengan jejak sebesar 10%. Diperbarui pada Juli 2025, model ini mengungguli QwQ-32B sebanyak 10x dalam efisiensi aktif, mencetak 91,0 pada ArenaHard dan 69,6 pada SWE-Bench Verified.
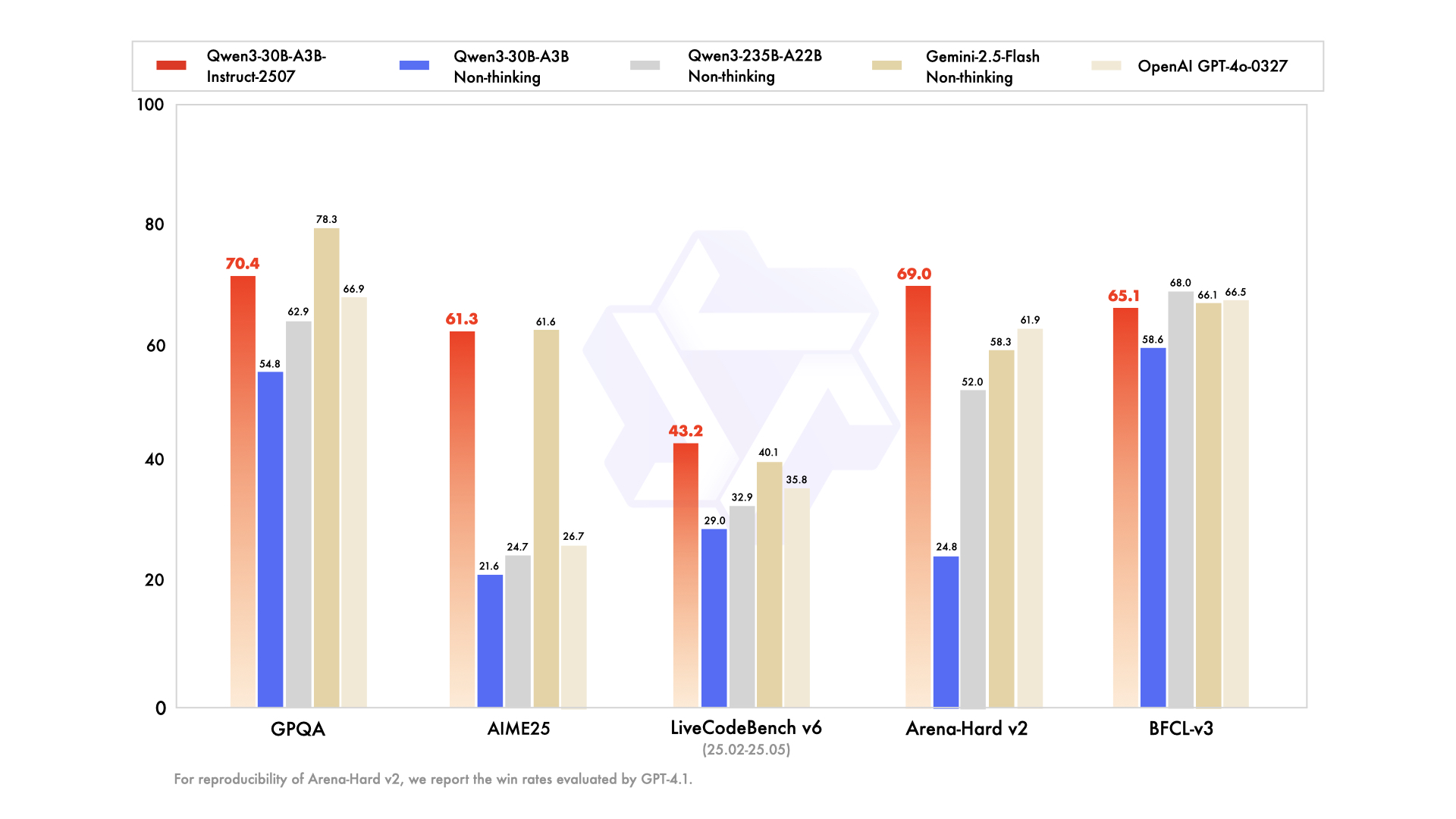
Evaluasi pengkodean menyoroti kehebatannya: 32,4% *pass@5* pada *fresh GitHub PRs*, setara dengan GPT-5-High. Tolok ukur matematika menunjukkan 81,6 pada AIME25 dalam mode berpikir, menyaingi model-model yang lebih besar. Dengan konteks 131K melalui YaRN, ia memproses dokumen panjang tanpa terpotong.
Keunggulan
- Parameter aktif 10× lebih murah daripada 235B sambil mempertahankan ~90–95% kualitas penalaran model unggulan (91.0 ArenaHard, 81.6 AIME25).
- Berjalan dengan nyaman pada satu A100 80GB atau dua kartu 40GB dengan vLLM + FlashAttention.
- Rasio harga-kinerja terbaik di antara semua model MoE terbuka tahun 2025.
- Mengungguli setiap model padat 72B–110B dalam pengkodean dan matematika.
Kelemahan
- Masih membutuhkan ~24–30GB VRAM dalam FP8/INT4; tidak ramah laptop.
- Kelancaran penulisan kreatif sedikit lebih rendah daripada model padat murni dengan ukuran yang sama.
- Latensi mode berpikir melonjak 2–3× dibandingkan mode non-berpikir.
Kapan menggunakannya
- Agen pengkodean produksi, ulasan PR otomatis, atau *copilot* DevOps internal.
- Pipeline penelitian *throughput* tinggi yang membutuhkan penalaran matematika atau sains tingkat *frontier* dengan anggaran yang wajar.
- Tim mana pun yang sebelumnya menggunakan Llama-405B atau Mixtral-123B tetapi menginginkan penalaran yang lebih baik dengan biaya lebih rendah.
3. Qwen3-32B – Raja Serbabisa Padat (*Dense All-Rounder*)
Qwen3-32B padat menghasilkan 32 miliar parameter yang sepenuhnya aktif, menekankan *throughput* mentah daripada sparsity. Dilatih dengan 36T token, model ini menyamai Qwen2.5-72B dalam kinerja dasar tetapi unggul dalam *post-training alignment*. Tolok ukur menunjukkan 89,5 pada ArenaHard dan 73,0 pada MultiIF, dengan penulisan kreatif yang kuat (misalnya, narasi *role-playing* mencetak 85% preferensi manusia).
Dalam pengkodean, ia memimpin BFCL dengan 68,2, menghasilkan UI *drag-and-drop* dari *prompt*. Matematika menghasilkan 70,3 pada AIME25, meskipun ia tertinggal dari rekan-rekan MoE dalam *chain-of-thought*. Konteks 128K-nya cocok untuk basis pengetahuan, dan mode non-berpikir meningkatkan kecepatan dialog hingga 20 token/detik.
Keunggulan
- *Instruction-following* dan keluaran kreatif yang luar biasa—seringkali lebih disukai daripada model MoE yang lebih besar dalam evaluasi manusia buta untuk penulisan dan *role-play*.
- Mudah untuk di-*fine-tune* dengan LoRA/QLoRA pada perangkat keras konsumen (VRAM 16–24GB).
- Inferensi tercepat di antara model yang masih mengalahkan GPT-4o pada banyak tugas (89.5 ArenaHard).
- Kinerja multibahasa yang sangat kuat di 119+ bahasa.
Kelemahan
- Tertinggal ~8–12 poin dari model MoE lainnya pada tolok ukur matematika dan pengkodean tersulit ketika mode berpikir diaktifkan.
- Tidak ada trik efisiensi parameter—setiap token membutuhkan komputasi penuh 32B.
Kapan menggunakannya
- Platform pembuatan konten, asisten penulisan novel, alat salinan pemasaran.
- Proyek yang membutuhkan *fine-tuning* berat (chatbot khusus domain, transfer gaya).
- Tim yang menginginkan kualitas mendekati unggulan tetapi harus tetap di bawah 24GB VRAM.
4. Qwen3-14B – Kekuatan *Edge* & Seluler
Qwen3-14B memprioritaskan portabilitas dengan 14,8 miliar parameter, mendukung 128K konteks pada perangkat keras kelas menengah. Ia menyaingi Qwen2.5-32B dalam efisiensi, mencetak 85,5 pada ArenaHard dan bersaing ketat dengan Qwen3-30B-A3B dalam matematika/pengkodean (dalam margin 5%). Dikuantisasi ke Q4_0, ia berjalan pada 24,5 token/detik pada perangkat seluler seperti RedMagic 8S Pro.
Tugas agensi mencetak 65,1 pada Tau2-Bench, memungkinkan penggunaan alat dalam aplikasi latensi rendah. Dukungan multibahasa bersinar, dengan akurasi 70% pada inferensi dialek. Untuk perangkat *edge*, ia memproses 32K konteks secara *offline*, ideal untuk analitik IoT.
Para insinyur menghargai jejaknya untuk pembelajaran terfederasi, di mana privasi mengalahkan skala. Oleh karena itu, ia cocok untuk asisten AI seluler atau sistem tertanam.
Keunggulan
- Berjalan pada 24–30 token/detik bahkan pada ponsel modern (Snapdragon 8 Gen 4, Dimensity 9400) ketika dikuantisasi ke Q4_K_M.
- Masih mengalahkan Qwen2.5-32B dan Llama-3.1-70B pada sebagian besar tolok ukur penalaran.
- Sangat baik untuk RAG *on-device* dengan konteks 32K–128K.
- Biaya API terendah di braket kinerja kelas atas.
Kelemahan
- Mulai kesulitan dengan tugas agensi multi-langkah yang membutuhkan >5 panggilan alat.
- Kualitas penulisan kreatif terasa di bawah model 32B+.
- Kurang *future-proof* karena tolok ukur terus meningkat.
Kapan menggunakannya
- Asisten *on-device* (aplikasi Android/iOS, perangkat *wearable*).
- Penerapan yang sensitif privasi (kesehatan, keuangan) di mana data tidak dapat meninggalkan perangkat.
- Sistem tertanam *real-time* (robot, mobil, *gateway* IoT).
5. Qwen3-8B – Pekerja Keras Ringan & Prototyping Terbaik
Melengkapi lima besar, Qwen3-8B menawarkan 8 miliar parameter untuk iterasi cepat, mengungguli Qwen2.5-14B pada 15 tolok ukur. Ia mencapai 81,5 pada AIME25 (non-berpikir) dan 60,2 pada LiveCodeBench, cukup untuk tinjauan kode dasar. Dengan konteks native 32K, ia diterapkan pada laptop melalui Ollama, mencapai 25 token/detik.
Varian ini cocok untuk pemula yang menguji obrolan multibahasa atau agen sederhana. Mode berpikirnya meningkatkan teka-teki logika, mencetak 75% pada tugas deduksi. Hasilnya, ia mempercepat *proof-of-concept* sebelum ditingkatkan ke model-model yang lebih besar.
Keunggulan
- Berjalan pada >25 token/detik bahkan pada laptop dengan VRAM 8–12GB (MacBook M3 Pro, RTX 4070 mobile).
- *Instruction-following* yang sangat kompeten—mengalahkan Gemma-2-27B dan Phi-4-14B pada sebagian besar papan peringkat tahun 2025.
- Sempurna untuk eksperimen Ollama lokal atau LM Studio.
- Harga API termurah dalam keluarga.
Kelemahan
- Batas penalaran yang jelas pada matematika tingkat pascasarjana dan masalah pengkodean tingkat lanjut.
- Lebih rentan terhadap halusinasi dalam tugas-tugas intensif pengetahuan.
- Konteks terbatas (32K native, 128K dengan YaRN tetapi lebih lambat).
Kapan menggunakannya
- Prototyping cepat dan pembuatan MVP.
- Alat pendidikan, asisten pribadi, atau proyek hobi.
- Lapisan *routing frontend* dalam sistem hibrida (gunakan 8B untuk menyortir, eskalasi ke 30B/235B saat dibutuhkan).
Pertimbangan Harga API dan Penerapan untuk Model Qwen 3
Mengakses Qwen 3 melalui API mendemokratisasi AI canggih, dengan Alibaba Cloud memimpin pada harga yang kompetitif. Tingkat harga berdasarkan token: untuk Qwen3-235B-A22B, input berbiaya $0,20–$1,20/juta (rentang 0–252K), output $1,00–$6,00/juta. Qwen3-30B-A3B mencerminkan ini pada tarif 80%, sementara model padat seperti Qwen3-32B turun menjadi $0,15 input/$0,75 output.
Penyedia pihak ketiga seperti Together AI menawarkan Qwen3-32B seharga $0,80/1 juta total token, dengan diskon volume. *Cache hits* mengurangi tagihan: implisit sebesar 20%, eksplisit sebesar 10%. Dibandingkan dengan GPT-5 ($3–15/1 juta), Qwen 3 memangkas biaya hingga 70%, memungkinkan penskalaan yang hemat biaya.
Tips penerapan: Gunakan vLLM untuk *batching*, SGLang untuk kompatibilitas OpenAI. Apidog meningkatkan ini dengan membuat *mock* *endpoint* Qwen, menguji *payload*, dan menghasilkan *docs*—penting untuk *pipeline* CI/CD. Eksekusi lokal melalui Ollama cocok untuk *prototyping*, tetapi API unggul untuk produksi.
Fitur keamanan seperti pembatasan tarif (*rate limiting*) dan moderasi menambah nilai, tanpa biaya tambahan. Oleh karena itu, tim yang sadar anggaran memilih berdasarkan volume token: varian kecil untuk pengembangan, varian unggulan untuk inferensi.
Tabel Keputusan – Pilih Model Qwen 3 Anda pada Tahun 2025
| Peringkat | Model | Parameter (Total/Aktif) | Ringkasan Keunggulan | Kelemahan Utama | Terbaik Untuk | Estimasi Biaya API (Input/Output per 1 Juta token) | VRAM Minimum (terkuantisasi) |
|---|---|---|---|---|---|---|---|
| 1 | Qwen3-235B-A22B | 235B / 22B MoE | Penalaran maksimum, agensi, matematika, kode | Sangat mahal & berat | Penelitian *frontier*, agen perusahaan, akurasi tanpa toleransi | $0.20–$1.20 / $1.00–$6.00 | 64GB+ (cloud) |
| 2 | Qwen3-30B-A3B | 30.5B / 3.3B MoE | Harga-kinerja terbaik, penalaran kuat | Masih membutuhkan GPU server | Agen pengkodean produksi, *backend* matematika/sains, inferensi volume tinggi | $0.16–$0.96 / $0.80–$4.80 | 24–30GB |
| 3 | Qwen3-32B | 32B Dense | Penulisan kreatif, *fine-tuning* mudah, kecepatan | Tertinggal dari MoE pada tugas tersulit | Platform konten, *fine-tuning* domain, chatbot multibahasa | $0.15 / $0.75 | 16–20GB |
| 4 | Qwen3-14B | 14.8B Dense | Mampu di *edge*/seluler, RAG *on-device* yang hebat | Kemampuan agen multi-langkah terbatas | AI *on-device*, aplikasi kritis privasi, sistem tertanam | $0.12 / $0.60 | 8–12GB |
| 5 | Qwen3-8B | 8B Dense | Kecepatan laptop/ponsel, termurah | Batas yang jelas pada tugas kompleks | Prototyping, asisten pribadi, lapisan *routing* dalam sistem hibrida | $0.10 / $0.50 | 4–8GB |
Rekomendasi Akhir untuk Tahun 2025
Sebagian besar tim pada tahun 2025 sebaiknya menggunakan Qwen3-30B-A3B—model ini memberikan 90%+ kekuatan model unggulan dengan sebagian kecil dari biaya dan persyaratan perangkat keras. Hanya beralih ke 235B-A22B jika Anda benar-benar membutuhkan 5–10% kualitas penalaran terakhir dan memiliki anggaran. Turun ke 32B padat untuk beban kerja kreatif atau *fine-tuning* yang berat, dan gunakan 14B/8B ketika latensi, privasi, atau batasan perangkat mendominasi.
Varian mana pun yang Anda pilih, Apidog akan menghemat waktu Anda dalam men-debug API. Unduh gratis hari ini dan mulailah membangun dengan Qwen 3 dengan percaya diri.