Et si vous pouviez changer de fournisseur d'IA sans réécrire une seule ligne de code ? L'API Venice offre exactement cela : des points d'accès compatibles OpenAI avec une rétention de données nulle, des options de modèles non censurés et une architecture axée sur la confidentialité que vous contrôlez.
La plupart des API d'IA vous obligent à utiliser des SDK spécifiques au fournisseur, conservent vos données pour l'entraînement des modèles et facturent des tarifs premium pour des fonctionnalités de base. Vous réécrivez votre application lorsque vous changez de fournisseur. Vos requêtes entraînent les modèles de vos concurrents. Vos coûts augmentent de manière imprévisible.
L'API Venice élimine ces points de friction. Elle reproduit exactement la structure de l'API d'OpenAI : changez l'URL de base et votre code existant fonctionne immédiatement. Vos données restent privées. Vous choisissez parmi plusieurs modèles de paiement, y compris le staking de crypto et des crédits USD prépayés (pay-as-you-go).
Vous voulez une plateforme intégrée tout-en-un pour que votre équipe de développeurs travaille avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix bien plus abordable !
Générer votre clé API Venice
1. Naviguez vers venice.ai/settings/api.
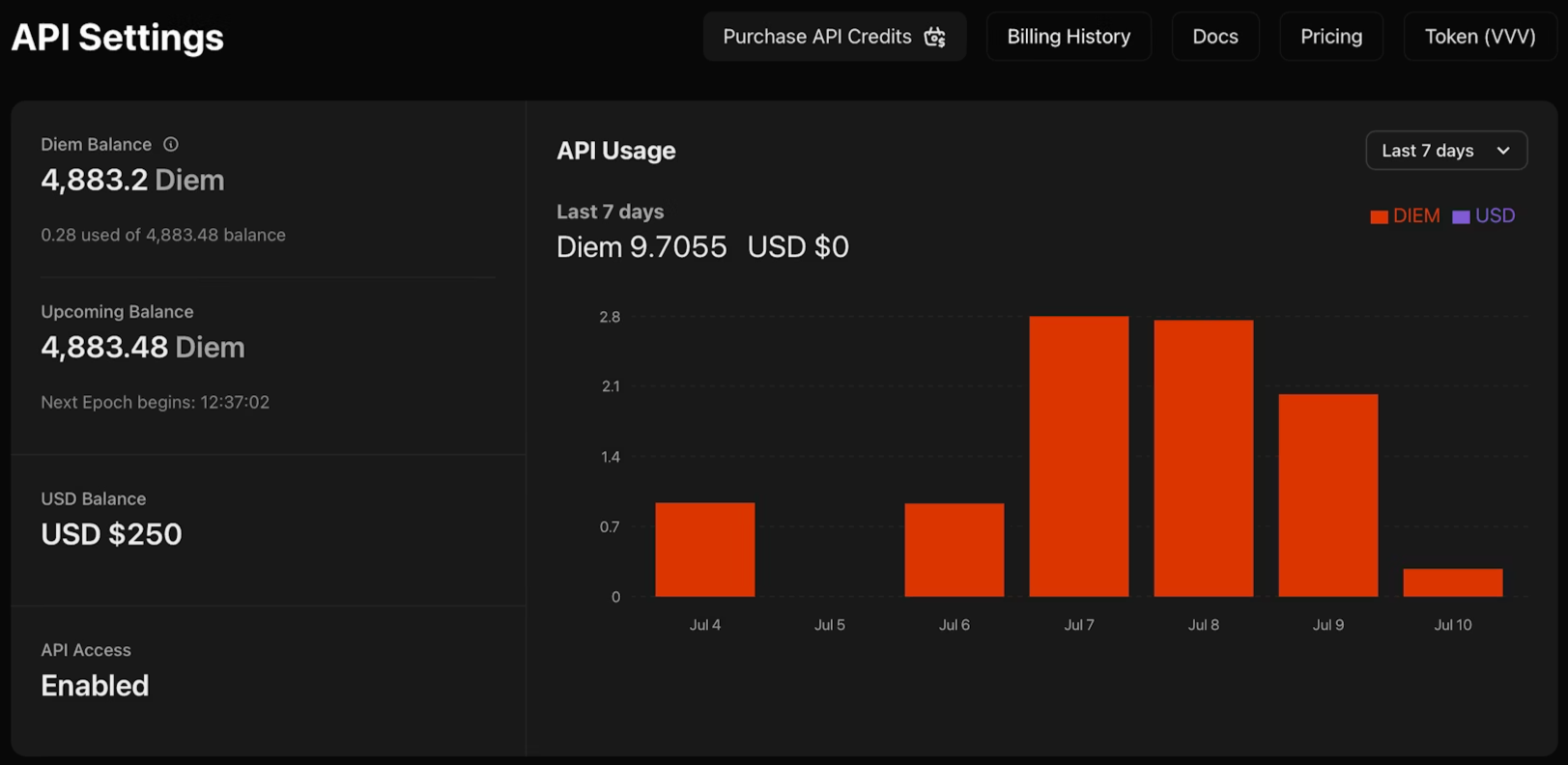
2. Cliquez sur "Generate New API Key" (Générer une nouvelle clé API) et configurez vos identifiants :
- Description : Nommez votre clé pour l'organisation
- Type : Les clés Admin gèrent d'autres clés par programmation ; les clés d'inférence uniquement exécutent exclusivement les modèles
- Expiration : Date facultative à laquelle la clé se désactive automatiquement
- Limites de consommation : Plafonds quotidiens en Diem ou USD pour contrôler les dépenses
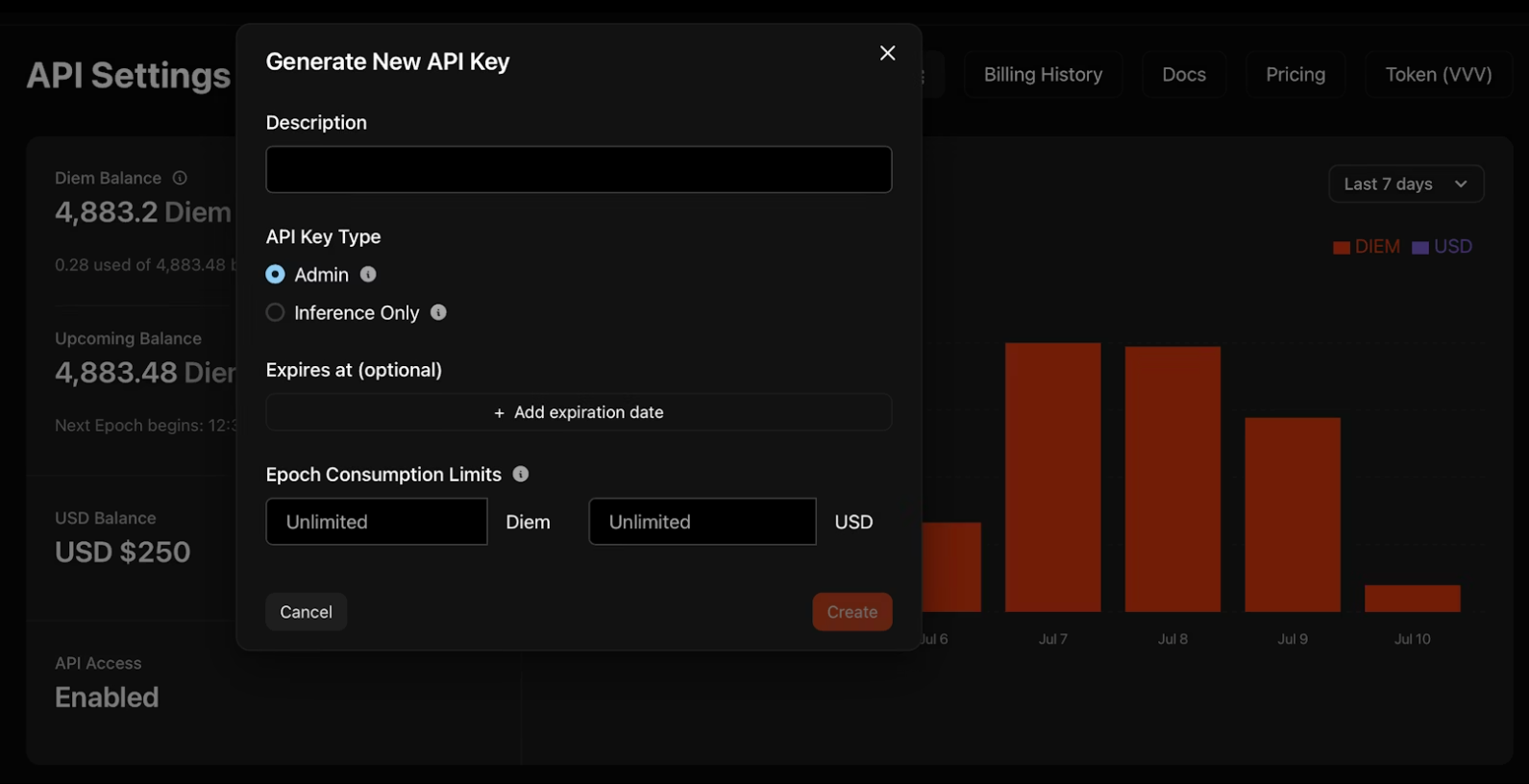
3. Copiez votre clé immédiatement. Venice l'affiche une seule fois ! Stockez-la dans des variables d'environnement, jamais dans des dépôts de code.
export VENICE_API_KEY="your-key-here"
Considérations de sécurité des clés
Les clés Admin offrent un accès étendu à votre compte Venice. Traitez-les comme des identifiants root – utilisez-les pour les scripts de rotation de clés et la gestion d'équipe, jamais dans le code de l'application. Les clés d'inférence uniquement limitent les opérations à l'exécution de modèles, réduisant ainsi l'exposition en cas de fuite. Faites pivoter les clés trimestriellement en utilisant les journaux d'activité du tableau de bord pour identifier les identifiants obsolètes.
Authentification et configuration de base de l'API Venice
Venice utilise l'authentification standard par jeton Bearer. Chaque requête nécessite deux en-têtes :
Authorization: Bearer $VENICE_API_KEY
Content-Type: application/json
L'URL de base suit exactement le modèle d'OpenAI :
import openai
import os
client = openai.OpenAI(
api_key=os.getenv("VENICE_API_KEY"),
base_url="https://api.venice.ai/api/v1"
)
Ce simple changement de configuration achemine tous vos appels SDK OpenAI existants via l'infrastructure de Venice. Aucun changement de méthode. Aucune réécriture de paramètre. Votre code fonctionne immédiatement.
Compatibilité SDK
Venice maintient sa compatibilité avec les SDK officiels d'OpenAI pour Python, TypeScript, Go, PHP, C#, Java et Swift. Les bibliothèques tierces construites sur la spécification d'OpenAI fonctionnent également sans modification. Testez votre base de code existante avec Venice en changeant uniquement l'URL de base et la clé API — si vous utilisez des complétions de chat standard, le streaming ou l'appel de fonctions, la migration prend quelques minutes.
Migration depuis OpenAI
La migration nécessite trois changements : l'URL de base, la clé API et le nom du modèle. Remplacez https://api.openai.com/v1 par https://api.venice.ai/api/v1. Échangez votre clé API OpenAI contre votre clé Venice. Modifiez les identifiants de modèle de gpt-4 ou gpt-3.5-turbo par des équivalents Venice tels que qwen3-4b. Testez minutieusement avant le déploiement en production. Vérifiez que les réponses en streaming sont correctement traitées. Confirmez que les schémas d'appel de fonctions sont valides. Vérifiez que les paramètres de génération d'images correspondent à vos exigences. La couche de compatibilité de Venice gère la plupart des cas limites, mais il existe des différences subtiles dans le formatage des messages d'erreur et les en-têtes de limite de débit.
Conseil de pro : Testez minutieusement tous vos points d'accès API avec Apidog.
Points d'accès et capacités de base de l'API Venice
Venice fournit neuf points d'accès distincts couvrant la génération de texte, d'images, d'audio et de vidéo :
Génération de texte
/api/v1/chat/completions- IA conversationnelle avec support du streaming/api/v1/embeddings/generate- Embeddings vectoriels pour les applications RAG
Traitement d'images
/api/v1/image/generate- Génération de texte en image/api/v1/image/upscale- Amélioration de la résolution/api/v1/image/edit- Inpainting et modification assistés par l'IA
Audio
/api/v1/audio/speech- Synthèse vocale (texte-parole)/api/v1/audio/transcriptions- Transcription vocale (parole-texte)
Vidéo et personnages
/api/v1/video/queue- Génération de texte/vidéo en vidéo/api/v1/characters/list- Gestion des personas IA
Chaque point d'accès maintient des formats de requête/réponse compatibles OpenAI là où cela est applicable. Vous réutilisez la logique d'analyse existante.
Stratégie de sélection des points d'accès
Adaptez les points d'accès à la complexité de votre cas d'utilisation. Les complétions de chat gèrent la plupart des besoins de génération de texte. Ajoutez des embeddings pour la recherche sémantique ou les pipelines RAG. Utilisez les points d'accès image pour les flux de travail créatifs ou la modération de contenu. Les points d'accès audio activent les fonctionnalités d'accessibilité ou les interfaces vocales. Commencez par un point d'accès, validez votre intégration, puis étendez-vous aux flux de travail multimodaux.
Travailler avec les réponses en streaming
Le streaming réduit la latence perçue pour les applications de chat. Venice utilise des Server-Sent Events (SSE) identiques à l'implémentation d'OpenAI. Traitez le contenu partiel au fur et à mesure qu'il arrive plutôt que d'attendre des réponses complètes. Gérez la terminaison du flux en vérifiant les messages [DONE]. Implémentez une logique de reconnexion pour les flux interrompus — stockez l'historique de conversation côté client et réessayez les requêtes échouées. Surveillez l'utilisation des jetons dans les fragments de flux pour suivre les coûts en temps réel.
Paramètres spécifiques à l'API Venice
Au-delà des paramètres standard d'OpenAI, Venice ajoute des contrôles de capacité via l'objet venice_parameters :
{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Latest AI developments?"}],
"venice_parameters": {
"enable_web_search": "on",
"enable_web_citations": true,
"strip_thinking_response": false
}
}
Intégration de la recherche web
Définissez enable_web_search sur auto, on ou off. Auto permet au modèle de décider quand les informations actuelles améliorent les réponses. Forcez-le sur on pour les requêtes en temps réel concernant des événements récents ou des technologies en évolution rapide. Associez-le à enable_web_citations pour renvoyer les URL sources — essentiel pour les outils de recherche et la vérification des faits.
Contrôle du raisonnement
Les modèles de raisonnement comme DeepSeek R1 affichent par défaut une réflexion étape par étape. Définissez strip_thinking_response sur true pour ne renvoyer que les réponses finales, réduisant ainsi la consommation de jetons. Utilisez disable_thinking pour contourner entièrement le raisonnement pour les requêtes simples.
Syntaxe alternative
Passez les paramètres via le suffixe du modèle pour des requêtes concises :
model="qwen3-4b:enable_web_search=on&enable_web_citations=true"
Hiérarchie des paramètres
Les paramètres spécifiques à Venice remplacent les valeurs par défaut mais respectent les paramètres explicites. Si vous spécifiez temperature: 0.5 dans l'objet racine et enable_web_search: on dans venice_parameters, les deux s'appliquent simultanément. Testez les combinaisons de paramètres isolément avant de les déployer en production — certains paramètres interagissent de manière imprévisible avec certains modèles.
Exemples d'implémentation pratique lors de l'utilisation de l'API Venice
Complétion de chat de base
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Explain zero-knowledge proofs"}],
"stream": true
}'
Le streaming fonctionne de manière identique à OpenAI — traitez les fragments SSE au fur et à mesure qu'ils arrivent.
Appel de fonctions
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-4b",
"messages": [{"role": "user", "content": "Weather in Tokyo?"}],
"tools": [{
"type": "function",
"function": {
"name": "get_weather",
"description": "Get weather for location",
"parameters": {
"type": "object",
"properties": {
"location": {"type": "string"}
},
"required": ["location"]
}
}
}]
}'
Les modèles Venice prennent en charge l'appel de fonctions parallèle et l'application de schémas comme l'implémentation d'OpenAI.
Génération d'images
curl --request POST \
--url https://api.venice.ai/api/v1/image/generate \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "venice-sd35",
"prompt": "Cyberpunk cityscape at night, neon reflections",
"aspect_ratio": "16:9",
"resolution": "2K",
"hide_watermark": true
}'
Les rapports d'aspect disponibles incluent 1:1, 4:3, 16:9 et 21:9. Les options de résolution sont 1K et 2K.
Mise à l'échelle d'image
curl --request POST \
--url https://api.venice.ai/api/v1/image/upscale \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "upscale-sd35",
"image": "base64encodedimage..."
}'
Analyse de vision
curl --request POST \
--url https://api.venice.ai/api/v1/chat/completions \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "qwen3-vl-235b-a22b",
"messages": [{
"role": "user",
"content": [
{"type": "text", "text": "What architecture style is this?"},
{"type": "image_url", "image_url": {"url": "data:image/jpeg;base64,..."}}
]
}]
}'
Passez les images sous forme d'URI de données base64 ou d'URL HTTPS. Les modèles de vision acceptent plusieurs images par message pour les tâches de comparaison.
Synthèse audio
curl --request POST \
--url https://api.venice.ai/api/v1/audio/speech \
--header "Authorization: Bearer $VENICE_API_KEY" \
--header "Content-Type: application/json" \
--data '{
"model": "tts-kokoro",
"input": "Welcome to Venice API",
"voice": "af_sky",
"response_format": "mp3"
}'
Les options de voix utilisent des préfixes : af_ (femme américaine), am_ (homme américain) et des schémas similaires pour d'autres accents.
Modèles de gestion d'erreurs
Venice renvoie des codes d'état HTTP standard. 401 indique des échecs d'authentification — vérifiez votre clé API et vos en-têtes. 429 signale une limitation de débit ; implémentez une reprise exponentielle à partir de 1 seconde. Les erreurs 500 suggèrent des problèmes d'infrastructure temporaires ; réessayez après 5 secondes. Analysez les réponses d'erreur pour des messages spécifiques — Venice inclut des raisons détaillées d'échec dans le corps de la réponse.
Confidentialité et architecture des données de l'API Venice
La politique de rétention de données nulle de Venice fonctionne grâce à une architecture technique, et pas seulement à des promesses légales. Votre navigateur stocke l'historique des conversations localement en utilisant IndexedDB. Les serveurs Venice traitent les requêtes sur des GPU qui ne voient que la requête actuelle — pas d'historique de conversation, pas de métadonnées d'identité utilisateur, pas d'informations de clé API.
Après avoir généré une réponse, les serveurs suppriment immédiatement la requête et la sortie. Rien n'est conservé sur le disque ou dans les journaux. Vos données n'entraînent jamais les modèles. Cela diffère fondamentalement des services centralisés qui conservent les données pour la détection des abus et l'amélioration des modèles.
Pour une confidentialité accrue, Venice héberge la plupart des modèles sur une infrastructure privée plutôt que de s'appuyer sur des fournisseurs tiers. Les options non censurées s'exécutent sur du matériel contrôlé par Venice, garantissant l'absence de filtrage ou de journalisation externe.
Vérification du flux de données
Vérifiez les affirmations de Venice en matière de confidentialité en surveillant le trafic réseau. Les requêtes API vont directement à api.venice.ai avec chiffrement TLS. Aucun script d'analyse tiers ne se charge dans la documentation. Les en-têtes de réponse ne montrent aucune directive de mise en cache — confirmant la non-rétention côté serveur. Pour les applications sensibles, implémentez le chiffrement côté client avant d'envoyer les requêtes, bien que cela empêche le modèle de comprendre le contenu.
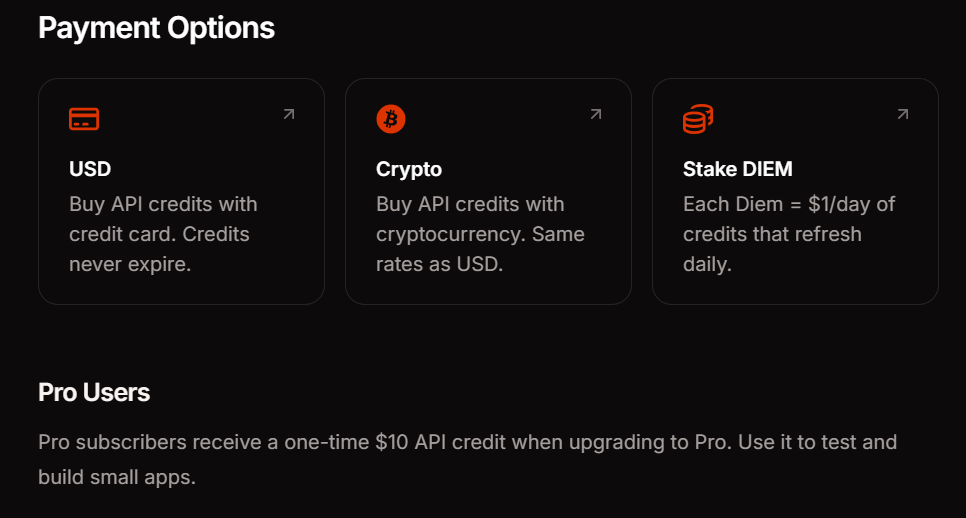
Options de tarification et de paiement de l'API Venice
Venice propose trois méthodes de paiement pour correspondre à vos habitudes d'utilisation. L'abonnement Pro coûte 18 $ par mois et comprend 10 $ en crédits API ainsi que des requêtes illimitées sur les fonctionnalités grand public. Le staking DIEM nécessite l'achat de jetons VVV qui fournissent des allocations de calcul quotidiennes permanentes — idéal pour les applications à fort volume avec un trafic prévisible. Le paiement à l'usage en USD (pay-as-you-go) vous permet d'approvisionner votre compte en dollars et de consommer des crédits selon vos besoins, parfait pour l'expérimentation et les charges de travail variables.
L'accès à l'API reste actuellement gratuit pendant la phase bêta. Cela vous permet de valider les modèles d'intégration et d'estimer les coûts avant de vous engager sur une méthode de paiement. Surveillez votre tableau de bord d'utilisation pour suivre la consommation de jetons sur les points d'accès et les modèles.
Directives de sélection des modèles
Choisissez les modèles en fonction des exigences de capacité et des contraintes de latence. Commencez avec qwen3-4b pour le prototypage et les requêtes simples — il répond rapidement et gère adéquatement la plupart des tâches de génération de texte. Passez à des modèles plus grands comme llama-3.3-70b ou deepseek-ai-DeepSeek-R1 lorsque vous avez besoin de raisonnement avancé, de génération de code ou de suivi d'instructions complexes. Les tâches de vision nécessitent des modèles multimodaux comme qwen3-vl-235b-a22b. La génération audio utilise des modèles de parole spécialisés. Interrogez le point d'accès /api/v1/models par programmation pour vérifier la disponibilité en temps réel — Venice fait pivoter les modèles en fonction de la demande et de la capacité de l'infrastructure.
Conclusion
L'API Venice élimine les frictions de l'intégration de l'IA. Vous bénéficiez de la compatibilité OpenAI sans le verrouillage, de la confidentialité sans la complexité de configuration et d'une tarification flexible sans factures surprises. L'approche de remplacement direct signifie que vous pouvez évaluer Venice aux côtés de votre fournisseur actuel sans réécrire le code de l'application.
Lors de la création d'intégrations API — que ce soit pour tester les points d'accès Venice, déboguer les flux d'authentification ou gérer plusieurs configurations de fournisseurs — utilisez Apidog pour rationaliser votre flux de travail. Il gère les tests visuels d'API, la génération de documentation et la collaboration d'équipe afin que vous puissiez vous concentrer sur la livraison de fonctionnalités.