
Le traitement de documents a longtemps été l'une des applications les plus pratiques de l'IA – pourtant, la plupart des solutions d'OCR imposent un compromis inconfortable entre précision et efficacité. Les systèmes traditionnels comme Tesseract exigent un prétraitement extensif. Les API cloud facturent par page et ajoutent de la latence. Même les modèles modernes de vision-langage peinent avec l'explosion de jetons qui résulte des images de documents haute résolution.
DeepSeek-OCR 2 change complètement cette équation. S'appuyant sur l'approche de "Compression Optique Contextuelle" de la version 1, la nouvelle version introduit le "Flux Causal Visuel" – une architecture qui traite les documents comme les humains les lisent réellement, comprenant les relations visuelles et le contexte plutôt que de simplement reconnaître les caractères. Le résultat est un modèle qui atteint 97% de précision tout en compressant les images jusqu'à seulement 64 jetons, permettant un débit de plus de 200 000 pages par jour sur un seul GPU.
Ce guide couvre tout, de l'installation de base au déploiement en production, avec du code fonctionnel que vous pouvez copier-coller et exécuter immédiatement.
Qu'est-ce que DeepSeek-OCR 2 ?
DeepSeek-OCR 2 est un modèle open-source de vision-langage spécifiquement conçu pour la compréhension de documents et l'extraction de texte. Publié par DeepSeek AI en janvier 2026, il s'appuie sur le DeepSeek-OCR original avec une nouvelle architecture "Visual Causal Flow" qui modélise comment les éléments visuels dans les documents sont liés causalement entre eux – comprenant qu'un en-tête de tableau détermine comment les cellules en dessous doivent être interprétées, ou qu'une légende de figure explique le graphique au-dessus.
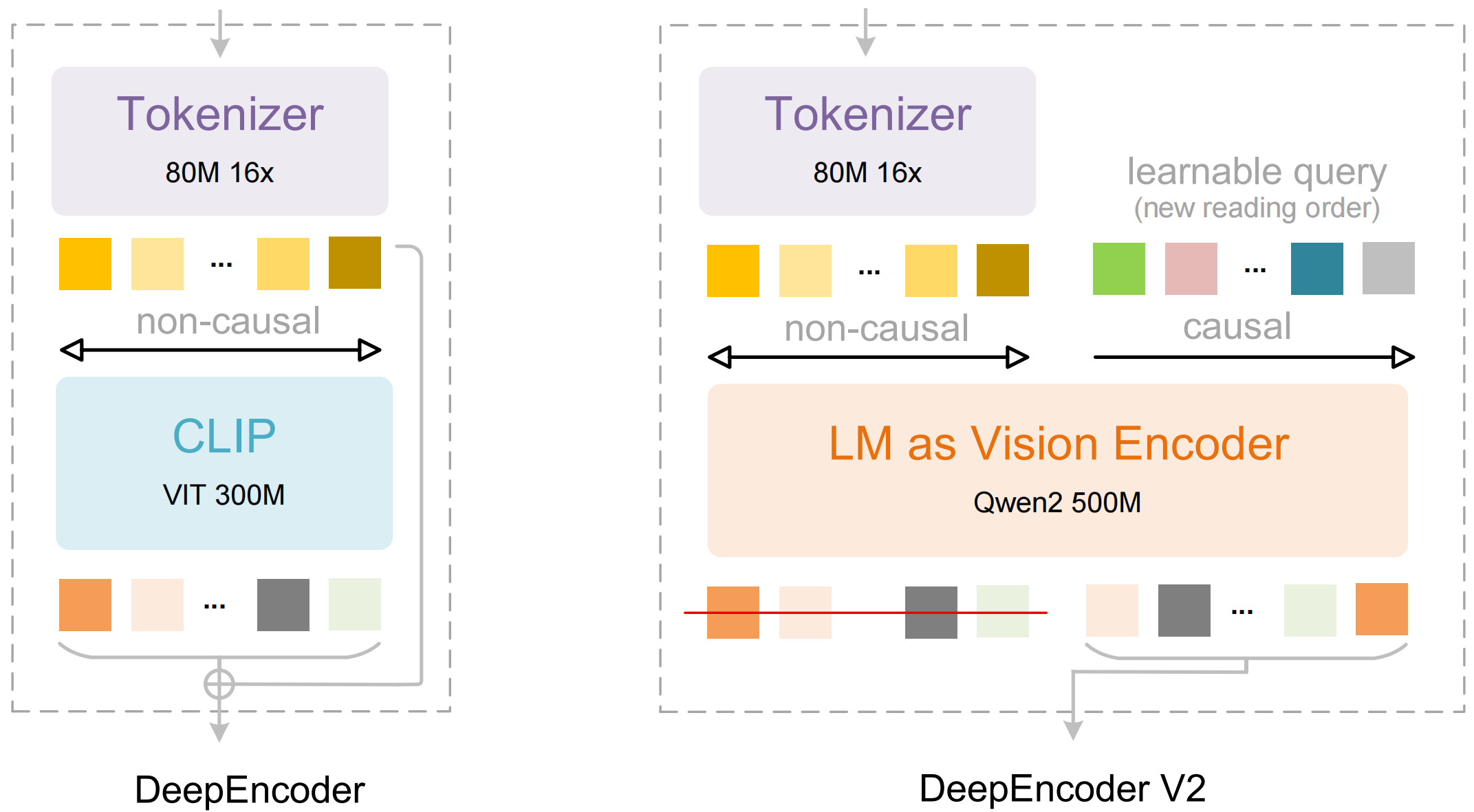
Le modèle se compose de deux composants principaux :
- DeepEncoder : Un transformeur de vision double qui combine l'extraction de détails locaux (basée sur SAM, 80M de paramètres) avec la compréhension de la mise en page globale (basée sur CLIP, 300M de paramètres)
- Décodeur DeepSeek3B-MoE : Un modèle de langage à mélange d'experts qui génère une sortie structurée (Markdown, LaTeX, JSON) à partir de la représentation visuelle compressée
Ce qui rend DeepSeek-OCR 2 différent :
- Compression extrême : Réduit une image de 1024 × 1024 de 4 096 patchs à seulement 256 jetons – une réduction de 16 ×
- Sortie structurée : Génère du Markdown propre avec des tableaux, des en-têtes et une mise en forme corrects
- Prise en charge multi-format : Gère les PDF, les documents numérisés, les captures d'écran, les notes manuscrites, et plus encore
- Plus de 100 langues : Entraîné sur 30 millions de pages couvrant environ 100 langues
- Poids ouverts : Sous licence MIT, disponible sur Hugging Face
Fonctionnalités Clés et Architecture
Flux Causal Visuel
La principale fonctionnalité de la version 2 est le "Flux Causal Visuel" – une nouvelle approche de la compréhension des documents qui va au-delà du simple OCR. Au lieu de traiter une page comme une grille plate de caractères, le modèle apprend les relations causales entre les éléments visuels :
- Inférence de l'ordre de lecture : Détermine automatiquement la séquence correcte pour les mises en page multi-colonnes
- Compréhension de la structure des tableaux : Reconnaît les en-têtes, les cellules fusionnées et les tableaux imbriqués
- Liaison figure-légende : Associe les images à leurs descriptions
- Analyse des expressions mathématiques : Gère avec précision les expressions LaTeX en ligne et en bloc
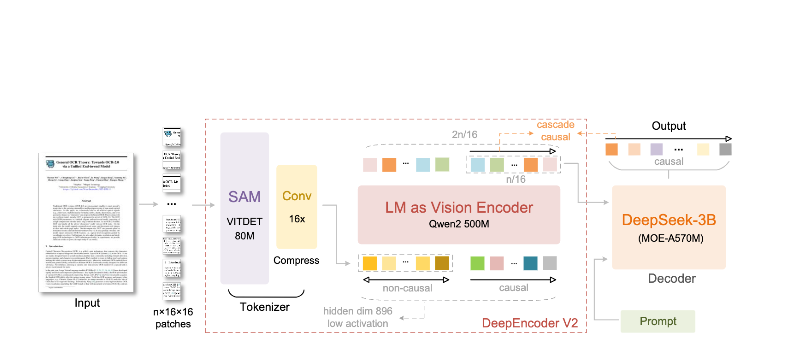
Architecture du DeepEncoder
Le DeepEncoder est là où la magie opère. Il traite les images haute résolution tout en maintenant un nombre de jetons gérable :
Image d'entrée (1024×1024)
↓
Bloc SAM-base (80M paramètres)
- Attention fenêtrée pour les détails locaux
- Extrait les caractéristiques fines
↓
Bloc CLIP-large (300M paramètres)
- Attention globale pour la mise en page
- Comprend la structure du document
↓
Bloc de Convolution
- Réduction de 16× des jetons
- 4 096 patchs → 256 jetons
↓
Sortie : Jetons de Vision Compressés
Compromis Compression vs Précision
| Taux de Compression | Jetons Visuels | Précision |
|---|---|---|
| 4× | 1,024 | 99%+ |
| 10× | 256 | 97% |
| 16× | 160 | 92% |
| 20× | 128 | ~60% |
Le point idéal pour la plupart des applications est le taux de compression de 10×, qui maintient une précision de 97% tout en permettant le débit élevé qui rend le déploiement en production pratique.
Installation et Configuration
Prérequis
- Python 3.10+ (3.12.9 recommandé)
- CUDA 11.8+ avec GPU NVIDIA compatible
- Au moins 16 Go de mémoire GPU (A100-40G recommandé pour la production)
Méthode 1 : Installation de vLLM (Recommandée)
vLLM offre les meilleures performances pour les déploiements en production :
# Créer un environnement virtuel
python -m venv deepseek-ocr-env
source deepseek-ocr-env/bin/activate
# Installer vLLM avec le support CUDA
pip install vllm>=0.8.5
# Installer Flash Attention pour des performances optimales
pip install flash-attn==2.7.3 --no-build-isolation
Méthode 2 : Installation de Transformers
Pour le développement et l'expérimentation :
pip install transformers>=4.40.0
pip install torch>=2.6.0 torchvision>=0.21.0
pip install accelerate
pip install flash-attn==2.7.3 --no-build-isolation
Méthode 3 : Docker (Production)
FROM nvidia/cuda:11.8-devel-ubuntu22.04
RUN pip install vllm>=0.8.5 flash-attn==2.7.3
# Pré-télécharger le modèle
RUN python -c "from vllm import LLM; LLM(model='deepseek-ai/DeepSeek-OCR-2')"
EXPOSE 8000
CMD ["vllm", "serve", "deepseek-ai/DeepSeek-OCR-2", "--port", "8000"]
Vérifier l'Installation
import torch
print(f"Version de PyTorch : {torch.__version__}")
print(f"CUDA disponible : {torch.cuda.is_available()}")
print(f"GPU : {torch.cuda.get_device_name(0)}")
import vllm
print(f"Version de vLLM : {vllm.__version__}")
Exemples de Code Python
OCR de Base avec vLLM
Voici la manière la plus simple d'extraire du texte d'une image de document :
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
# Initialiser le modèle
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
trust_remote_code=True,
)
# Charger votre image de document
image = Image.open("document.png").convert("RGB")
# Préparer le prompt - "Free OCR." déclenche l'extraction standard
prompt = "<image>\nOCR gratuit."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": image}
}]
# Configurer les paramètres d'échantillonnage
sampling_params = SamplingParams(
temperature=0.0, # Déterministe pour l'OCR
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822}, # <td>, </td> pour les tableaux
},
skip_special_tokens=False,
)
# Générer la sortie
outputs = llm.generate(model_input, sampling_params)
# Extraire le texte markdown
markdown_text = outputs[0].outputs[0].text
print(markdown_text)
Traitement par Lots de Plusieurs Documents
Traitez plusieurs documents efficacement en un seul lot :
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
from pathlib import Path
def batch_ocr(image_paths: list[str], llm: LLM) -> list[str]:
"""Traiter plusieurs images en un seul lot."""
# Charger toutes les images
images = [Image.open(p).convert("RGB") for p in image_paths]
# Préparer l'entrée du lot
prompt = "<image>\nOCR gratuit."
model_inputs = [
{"prompt": prompt, "multi_modal_data": {"image": img}}
for img in images
]
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
# Générer toutes les sorties en un seul appel
outputs = llm.generate(model_inputs, sampling_params)
return [out.outputs[0].text for out in outputs]
# Utilisation
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
image_files = list(Path("documents/").glob("*.png"))
results = batch_ocr([str(f) for f in image_files], llm)
for path, text in zip(image_files, results):
print(f"--- {path.name} ---")
print(text[:500]) # Premiers 500 caractères
print()
Utilisation Directe de Transformers
Pour plus de contrôle sur le processus d'inférence :
import torch
from transformers import AutoModel, AutoTokenizer
from PIL import Image
# Définir le GPU
device = "cuda:0"
# Charger le modèle et le tokenizer
model_name = "deepseek-ai/DeepSeek-OCR-2"
tokenizer = AutoTokenizer.from_pretrained(model_name, trust_remote_code=True)
model = AutoModel.from_pretrained(
model_name,
_attn_implementation="flash_attention_2",
trust_remote_code=True,
use_safetensors=True,
)
model = model.eval().to(device).to(torch.bfloat16)
# Charger et prétraiter l'image
image = Image.open("document.png").convert("RGB")
# Différents prompts pour différentes tâches
prompts = {
"ocr": "<image>\nOCR gratuit.",
"markdown": "<image>\n<|grounding|>Convertir le document en markdown.",
"table": "<image>\nExtraire tous les tableaux au format markdown.",
"math": "<image>\nExtraire les expressions mathématiques en LaTeX.",
}
# Traiter avec le prompt choisi
prompt = prompts["markdown"]
inputs = tokenizer(prompt, return_tensors="pt").to(device)
# Ajouter l'image aux entrées (prétraitement spécifique au modèle)
with torch.no_grad():
outputs = model.generate(
**inputs,
images=[image],
max_new_tokens=4096,
do_sample=False,
)
result = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(result)
Traitement Asynchrone pour un Débit Élevé
import asyncio
from vllm import AsyncLLMEngine, AsyncEngineArgs, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from PIL import Image
async def process_document(engine, image_path: str, request_id: str):
"""Traiter un document unique de manière asynchrone."""
image = Image.open(image_path).convert("RGB")
prompt = "<image>\nOCR gratuit."
sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
)
results = []
async for output in engine.generate(prompt, sampling_params, request_id):
results.append(output)
return results[-1].outputs[0].text
async def main():
# Initialiser le moteur asynchrone
engine_args = AsyncEngineArgs(
model="deepseek-ai/DeepSeek-OCR-2",
enable_prefix_caching=False,
mm_processor_cache_gb=0,
)
engine = AsyncLLMEngine.from_engine_args(engine_args)
# Traiter plusieurs documents simultanément
image_paths = ["doc1.png", "doc2.png", "doc3.png"]
tasks = [
process_document(engine, path, f"req_{i}")
for i, path in enumerate(image_paths)
]
results = await asyncio.gather(*tasks)
for path, text in zip(image_paths, results):
print(f"{path}: {len(text)} caractères extraits")
asyncio.run(main())
Utilisation de vLLM pour la Production
Démarrage du Serveur Compatible OpenAI
Déployer DeepSeek-OCR 2 comme serveur API :
vllm serve deepseek-ai/DeepSeek-OCR-2 \
--host 0.0.0.0 \
--port 8000 \
--logits_processors vllm.model_executor.models.deepseek_ocr:NGramPerReqLogitsProcessor \
--no-enable-prefix-caching \
--mm-processor-cache-gb 0 \
--max-model-len 16384 \
--gpu-memory-utilization 0.9
Appel du Serveur avec le SDK OpenAI
from openai import OpenAI
import base64
# Initialiser le client pointant vers le serveur local
client = OpenAI(
api_key="EMPTY", # Non requis pour le serveur local
base_url="http://localhost:8000/v1",
timeout=3600,
)
def encode_image(image_path: str) -> str:
"""Encoder l'image en base64."""
with open(image_path, "rb") as f:
return base64.b64encode(f.read()).decode("utf-8")
def ocr_document(image_path: str) -> str:
"""Extraire le texte du document en utilisant l'API OCR."""
base64_image = encode_image(image_path)
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": f"data:image/png;base64,{base64_image}"
}
},
{
"type": "text",
"text": "OCR gratuit."
}
]
}
],
max_tokens=8192,
temperature=0.0,
extra_body={
"skip_special_tokens": False,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822],
},
},
)
return response.choices[0].message.content
# Utilisation
result = ocr_document("invoice.png")
print(result)
Utilisation avec des URLs
response = client.chat.completions.create(
model="deepseek-ai/DeepSeek-OCR-2",
messages=[
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "https://example.com/document.png"
}
},
{
"type": "text",
"text": "OCR gratuit."
}
]
}
],
max_tokens=8192,
temperature=0.0,
)
Test avec Apidog
Tester efficacement les API OCR nécessite de visualiser à la fois les documents d'entrée et la sortie extraite. Apidog fournit une interface intuitive pour expérimenter DeepSeek-OCR 2.
Configuration du Point de Terminaison OCR
Étape 1 : Créer une Nouvelle Requête
- Ouvrez Apidog et créez un nouveau projet
- Ajoutez une requête POST à
http://localhost:8000/v1/chat/completions
Étape 2 : Configurer les En-têtes
Content-Type: application/json
Étape 3 : Configurer le Corps de la Requête
{
"model": "deepseek-ai/DeepSeek-OCR-2",
"messages": [
{
"role": "user",
"content": [
{
"type": "image_url",
"image_url": {
"url": "data:image/png;base64,{{base64_image}}"
}
},
{
"type": "text",
"text": "OCR gratuit."
}
]
}
],
"max_tokens": 8192,
"temperature": 0,
"extra_body": {
"skip_special_tokens": false,
"vllm_xargs": {
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": [128821, 128822]
}
}
}
Test de Différents Types de Documents
Créez des requêtes sauvegardées pour les types de documents courants :
- Extraction de facture - Testez l'extraction de données structurées
- Article académique - Testez la gestion des maths LaTeX
- Notes manuscrites - Testez la reconnaissance d'écriture manuscrite
- Mise en page multi-colonnes - Testez l'inférence de l'ordre de lecture
Comparaison des Modes de Résolution
Configurez des variables d'environnement pour tester rapidement différents modes :
| Mode | Résolution | Jetons | Cas d'Utilisation |
|---|---|---|---|
tiny | 512×512 | 64 | Aperçus rapides |
small | 640×640 | 100 | Documents simples |
base | 1024×1024 | 256 | Documents standards |
large | 1280×1280 | 400 | Texte dense |
gundam | Dynamique | Variable | Mises en page complexes |

Modes de Résolution et Compression
DeepSeek-OCR 2 prend en charge cinq modes de résolution, chacun optimisé pour différents cas d'utilisation :
Mode Tiny (64 jetons)
Idéal pour : Détection rapide de texte, formulaires simples, entrées basse résolution
# Configurer pour le mode tiny
os.environ["DEEPSEEK_OCR_MODE"] = "tiny" # 512×512
Mode Small (100 jetons)
Idéal pour : Documents numériques propres, texte à colonne unique
Mode Base (256 jetons) - Par Défaut
Idéal pour : La plupart des documents standards, factures, lettres
Mode Large (400 jetons)
Idéal pour : Articles académiques denses, documents juridiques
Mode Gundam (Dynamique)
Idéal pour : Documents multipages complexes avec des mises en page variées
# Le mode Gundam combine plusieurs vues
# - n × 640×640 tuiles locales pour les détails
# - 1 × 1024×1024 vue globale pour la structure
Choisir le Bon Mode
def select_mode(document_type: str, page_count: int) -> str:
"""Sélectionne le mode de résolution optimal en fonction des caractéristiques du document."""
if document_type == "simple_form":
return "tiny"
elif document_type == "digital_document" and page_count == 1:
return "small"
elif document_type == "academic_paper":
return "large"
elif document_type == "mixed_layout" or page_count > 1:
return "gundam"
else:
return "base" # Par défaut
Traitement des PDFs et des Documents
Conversion de PDFs en Images
import fitz # PyMuPDF
from PIL import Image
import io
def pdf_to_images(pdf_path: str, dpi: int = 150) -> list[Image.Image]:
"""Convertit les pages PDF en images PIL."""
doc = fitz.open(pdf_path)
images = []
for page_num in range(len(doc)):
page = doc[page_num]
# Rendu à la résolution DPI spécifiée
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
# Convertir en image PIL
img_data = pix.tobytes("png")
img = Image.open(io.BytesIO(img_data))
images.append(img)
doc.close()
return images
# Utilisation
images = pdf_to_images("report.pdf", dpi=200)
print(f"Extrait {len(images)} pages")
Pipeline Complet de Traitement PDF
from vllm import LLM, SamplingParams
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
from pathlib import Path
import fitz
from PIL import Image
import io
class PDFProcessor:
def __init__(self, model_name: str = "deepseek-ai/DeepSeek-OCR-2"):
self.llm = LLM(
model=model_name,
enable_prefix_caching=False,
mm_processor_cache_gb=0,
logits_processors=[NGramPerReqLogitsProcessor],
)
self.sampling_params = SamplingParams(
temperature=0.0,
max_tokens=8192,
extra_args={
"ngram_size": 30,
"window_size": 90,
"whitelist_token_ids": {128821, 128822},
},
skip_special_tokens=False,
)
def process_pdf(self, pdf_path: str, dpi: int = 150) -> str:
"""Traite l'intégralité du PDF et renvoie le markdown combiné."""
doc = fitz.open(pdf_path)
all_text = []
for page_num in range(len(doc)):
# Convertir la page en image
page = doc[page_num]
mat = fitz.Matrix(dpi / 72, dpi / 72)
pix = page.get_pixmap(matrix=mat)
img = Image.open(io.BytesIO(pix.tobytes("png")))
# OCR de la page
prompt = "<image>\nOCR gratuit."
model_input = [{
"prompt": prompt,
"multi_modal_data": {"image": img}
}]
output = self.llm.generate(model_input, self.sampling_params)
page_text = output[0].outputs[0].text
all_text.append(f"## Page {page_num + 1}\n\n{page_text}")
doc.close()
return "\n\n---\n\n".join(all_text)
# Utilisation
processor = PDFProcessor()
markdown = processor.process_pdf("annual_report.pdf")
# Enregistrer dans un fichier
Path("output.md").write_text(markdown)
Performances de Référence
Références de Précision
| Référence | DeepSeek-OCR 2 | GOT-OCR2.0 | MinerU2.0 |
|---|---|---|---|
| OmniDocBench | 94.2% | 91.8% | 89.5% |
| Jetons/page | 100-256 | 256 | 6 000+ |
| Fox (compression 10×) | 97% | - | - |
| Fox (compression 20×) | 60% | - | - |
Performances de Débit
| Matériel | Pages/Jour | Pages/Heure |
|---|---|---|
| A100-40G (simple) | 200 000+ | ~8 300 |
| A100-40G × 20 | 33M+ | ~1.4M |
| RTX 4090 | ~80 000 | ~3 300 |
| RTX 3090 | ~50 000 | ~2 100 |
Précision en Conditions Réelles par Type de Document
| Type de Document | Précision | Notes |
|---|---|---|
| PDFs numériques | 98%+ | Meilleures performances |
| Documents numérisés | 95%+ | Numérisations de bonne qualité |
| Rapports financiers | 92% | Tableaux complexes |
| Notes manuscrites | 85% | Dépend de la lisibilité |
| Documents historiques | 80% | Qualité dégradée |
Bonnes Pratiques et Optimisation
Prétraitement des Images
from PIL import Image, ImageEnhance, ImageFilter
def preprocess_document(image: Image.Image) -> Image.Image:
"""Prétraite l'image du document pour un OCR optimal."""
# Convertir en RGB si nécessaire
if image.mode != "RGB":
image = image.convert("RGB")
# Redimensionner si trop petit (minimum 512px sur le côté le plus court)
min_dim = min(image.size)
if min_dim < 512:
scale = 512 / min_dim
new_size = (int(image.width * scale), int(image.height * scale))
image = image.resize(new_size, Image.Resampling.LANCZOS)
# Améliorer le contraste pour les documents numérisés
enhancer = ImageEnhance.Contrast(image)
image = enhancer.enhance(1.2)
# Affûter légèrement
image = image.filter(ImageFilter.SHARPEN)
return image
Ingénierie des Prompts
# Différents prompts pour différentes tâches
PROMPTS = {
# OCR standard - le plus rapide, bon pour la plupart des cas
"ocr": "<image>\nOCR gratuit.",
# Conversion Markdown - meilleure préservation de la structure
"markdown": "<image>\n<|grounding|>Convertir le document en markdown.",
# Extraction de tableau - optimisée pour les données tabulaires
"table": "<image>\nExtraire tous les tableaux au format markdown.",
# Extraction mathématique - pour les documents académiques/scientifiques
"math": "<image>\nExtraire tout le texte et les expressions mathématiques. Utiliser LaTeX pour les maths.",
# Champs spécifiques - pour l'extraction de formulaires
"fields": "<image>\nExtraire les champs suivants : nom, date, montant, signature.",
}
Optimisation de la Mémoire
# Pour une mémoire GPU limitée
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
gpu_memory_utilization=0.8, # Laisser une marge
max_model_len=8192, # Réduire le contexte maximal
enable_chunked_prefill=True, # Meilleure efficacité mémoire
)
Stratégie de Traitement par Lots
def optimal_batch_size(gpu_memory_gb: int, avg_image_size: tuple) -> int:
"""Calcule la taille de lot optimale en fonction de la mémoire GPU."""
# Mémoire approximative par image (en Go)
pixels = avg_image_size[0] * avg_image_size[1]
mem_per_image = (pixels * 4) / (1024**3) # 4 octets par pixel
# Réserver 60% de la mémoire GPU pour le modèle
available = gpu_memory_gb * 0.4
return max(1, int(available / mem_per_image))
# Exemple : A100-40G avec des images 1024x1024
batch_size = optimal_batch_size(40, (1024, 1024))
print(f"Taille de lot recommandée : {batch_size}") # ~10
Dépannage des Problèmes Courants
Erreurs de Mémoire Insuffisante
Problème : CUDA out of memory
Solutions :
# 1. Réduire la taille du lot
sampling_params = SamplingParams(max_tokens=4096) # Réduire de 8192
# 2. Utiliser un mode de résolution plus petit
os.environ["DEEPSEEK_OCR_MODE"] = "small"
# 3. Activer l'optimisation de la mémoire
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
gpu_memory_utilization=0.7,
enforce_eager=True, # Désactiver les graphes CUDA
)
Mauvaise Extraction de Tableau
Problème : Les tableaux sont désalignés ou il manque des cellules
Solutions :
# S'assurer que les jetons de liste blanche sont définis
sampling_params = SamplingParams(
extra_args={
"whitelist_token_ids": {128821, 128822}, # Critique pour les tableaux
},
)
# Utiliser une résolution plus élevée
os.environ["DEEPSEEK_OCR_MODE"] = "large"
Inférence Lente
Problème : Le traitement prend trop de temps
Solutions :
- Utiliser vLLM au lieu de Transformers (2-3 fois plus rapide)
- Activer Flash Attention 2
- Utiliser le traitement par lots au lieu du séquentiel
- Déployer sur un GPU avec des Tensor Cores (A100, H100)
Sortie Inintelligible
Problème : La sortie contient des caractères insensés ou répétés
Solutions :
# S'assurer que le processeur de logits est activé
from vllm.model_executor.models.deepseek_ocr import NGramPerReqLogitsProcessor
llm = LLM(
model="deepseek-ai/DeepSeek-OCR-2",
logits_processors=[NGramPerReqLogitsProcessor], # Requis !
)
# Utiliser temperature=0 pour une sortie déterministe
sampling_params = SamplingParams(temperature=0.0)
Prêt à extraire du texte de vos documents ? Téléchargez Apidog pour tester les appels d'API DeepSeek-OCR 2 avec une interface visuelle, puis déployez en toute confiance en utilisant les modèles de production de ce guide.