
L'exécution d'un LLM sur votre machine locale présente plusieurs avantages. Tout d'abord, cela vous donne un contrôle total sur vos données, garantissant le respect de la confidentialité. Deuxièmement, vous pouvez expérimenter sans vous soucier des appels d'API coûteux ou des abonnements mensuels. De plus, les déploiements locaux offrent un moyen pratique d'en apprendre davantage sur le fonctionnement de ces modèles.
De plus, lorsque vous exécutez des LLM localement, vous évitez les problèmes potentiels de latence réseau et la dépendance aux services cloud. Cela signifie que vous pouvez créer, tester et itérer plus rapidement, surtout si vous travaillez sur des projets qui nécessitent une intégration étroite avec votre base de code.
Comprendre les LLM : un aperçu rapide
Avant de plonger dans nos meilleurs choix, abordons brièvement ce qu'est un LLM. En termes simples, un grand modèle linguistique (LLM) est un modèle d'IA qui a été entraîné sur de vastes quantités de données textuelles. Ces modèles apprennent les schémas statistiques dans le langage, ce qui leur permet de générer du texte semblable à celui des humains en fonction des invites que vous fournissez.
Les LLM sont au cœur de nombreuses applications d'IA modernes. Ils alimentent les chatbots, les assistants d'écriture, les générateurs de code et même des agents conversationnels sophistiqués. Cependant, l'exécution de ces modèles, en particulier les plus grands, peut être gourmande en ressources. C'est pourquoi il est si important d'avoir un outil fiable pour les exécuter localement.
En utilisant des outils LLM locaux, vous pouvez expérimenter avec ces modèles sans envoyer vos données vers des serveurs distants. Cela peut améliorer à la fois la sécurité et les performances. Tout au long de ce tutoriel, vous remarquerez que le mot-clé « LLM » est mis en évidence lorsque nous explorons comment chaque outil vous aide à exploiter ces modèles puissants sur votre propre matériel.
Outil n° 1 : Llama.cpp
Llama.cpp est sans doute l'un des outils les plus populaires lorsqu'il s'agit d'exécuter des LLM localement. Créée par Georgi Gerganov et maintenue par une communauté dynamique, cette bibliothèque C/C++ est conçue pour effectuer l'inférence sur des modèles comme LLaMA et d'autres avec un minimum de dépendances.

Pourquoi vous allez adorer Llama.cpp
- Léger et rapide : Llama.cpp est conçu pour la vitesse et l'efficacité. Avec une configuration minimale, vous pouvez exécuter des modèles complexes, même sur du matériel modeste. Il exploite des instructions CPU avancées comme AVX et Neon, ce qui signifie que vous tirez le meilleur parti des performances de votre système.
- Prise en charge matérielle polyvalente : Que vous utilisiez une machine x86, un appareil basé sur ARM ou même un Mac Apple Silicon, Llama.cpp vous couvre.
- Flexibilité de la ligne de commande : Si vous préférez le terminal aux interfaces graphiques, les outils de ligne de commande de Llama.cpp facilitent le chargement des modèles et la génération de réponses directement à partir de votre shell.
- Communauté et open source : En tant que projet open source, il bénéficie des contributions et des améliorations continues des développeurs du monde entier.
Comment démarrer
- Installation : Clonez le référentiel depuis GitHub et compilez le code sur votre machine.
- Configuration du modèle : Téléchargez votre modèle préféré (par exemple, une variante LLaMA quantifiée) et utilisez les utilitaires de ligne de commande fournis pour démarrer l'inférence.
- Personnalisation : Ajustez les paramètres tels que la longueur du contexte, la température et la taille du faisceau pour voir comment la sortie du modèle varie.
Par exemple, une commande simple pourrait ressembler à ceci :
./main -m ./models/llama-7b.gguf -p "Tell me a joke about programming" --temp 0.7 --top_k 100
Cette commande charge le modèle et génère du texte en fonction de votre invite. La simplicité de cette configuration est un énorme avantage pour tous ceux qui débutent avec l'inférence LLM locale.
Passant en douceur de Llama.cpp, explorons un autre outil fantastique qui adopte une approche légèrement différente.
Outil n° 2 : GPT4All
GPT4All est un écosystème open source conçu par Nomic AI qui démocratise l'accès aux LLM. L'un des aspects les plus intéressants de GPT4All est qu'il est conçu pour fonctionner sur du matériel grand public, que vous soyez sur un processeur ou un GPU. Cela le rend parfait pour les développeurs qui souhaitent expérimenter sans avoir besoin de machines coûteuses.
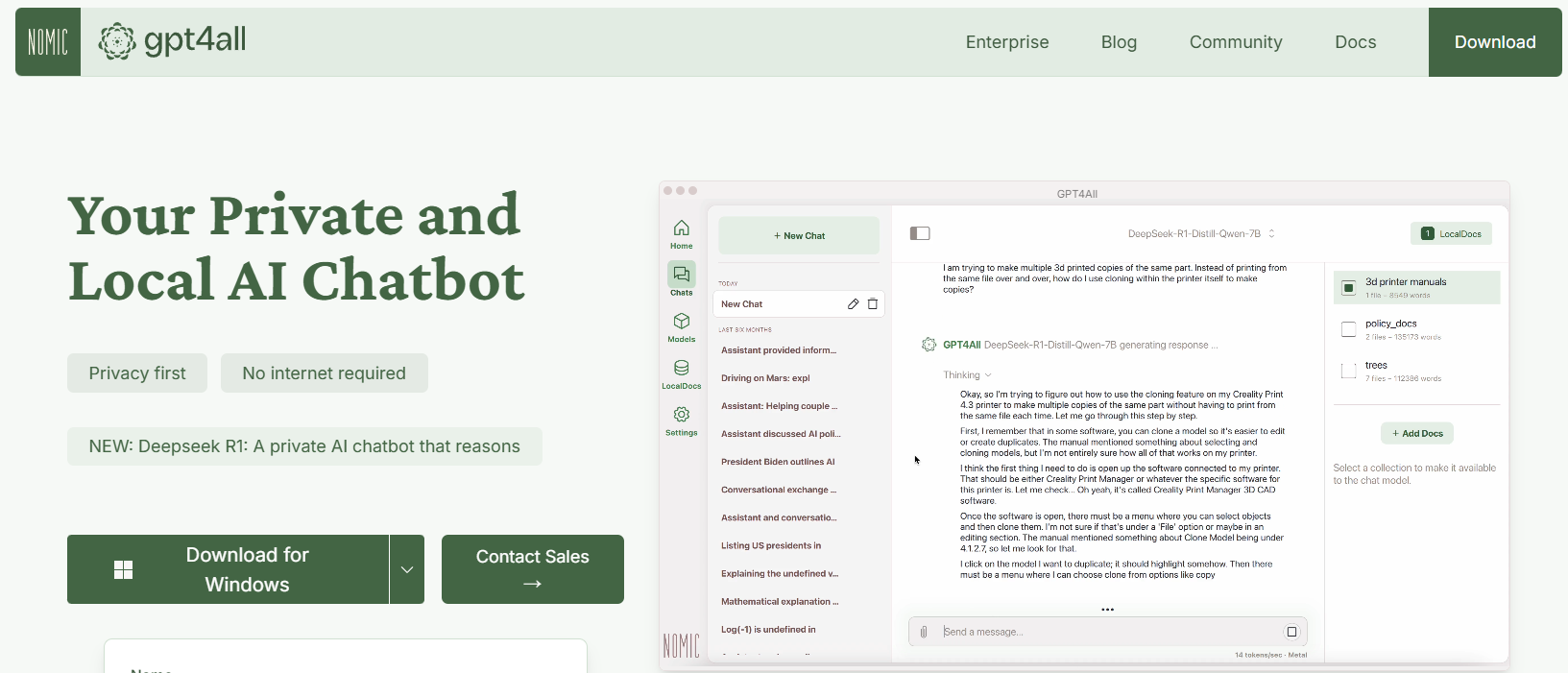
Principales caractéristiques de GPT4All
- Approche locale d'abord : GPT4All est conçu pour fonctionner entièrement sur votre appareil local. Cela signifie qu'aucune donnée ne quitte jamais votre machine, garantissant la confidentialité et des temps de réponse rapides.
- Convivial : Même si vous débutez avec les LLM, GPT4All est livré avec une interface simple et intuitive qui vous permet d'interagir avec le modèle sans connaissances techniques approfondies.
- Léger et efficace : Les modèles de l'écosystème GPT4All sont optimisés pour les performances. Vous pouvez les exécuter sur votre ordinateur portable, ce qui les rend accessibles à un public plus large.
- Open source et axé sur la communauté : Avec sa nature open source, GPT4All invite les contributions de la communauté, garantissant qu'il reste à jour avec les dernières innovations.
Démarrer avec GPT4All
- Installation : Vous pouvez télécharger GPT4All depuis son site Web. Le processus d'installation est simple et des binaires précompilés sont disponibles pour Windows, macOS et Linux.
- Exécution du modèle : Une fois installé, lancez simplement l'application et choisissez parmi une variété de modèles pré-réglés. L'outil propose même une interface de chat, ce qui est parfait pour les expérimentations occasionnelles.
- Personnalisation : Ajustez les paramètres tels que la longueur de la réponse du modèle et les paramètres de créativité pour voir comment la sortie change. Cela vous aide à comprendre comment les LLM fonctionnent dans différentes conditions.
Par exemple, vous pouvez taper une invite comme :
What are some fun facts about artificial intelligence?
Et GPT4All générera une réponse amicale et perspicace, le tout sans avoir besoin d'une connexion Internet.
Outil n° 3 : LM Studio
Ensuite, LM Studio est un autre excellent outil pour exécuter des LLM localement, en particulier si vous recherchez une interface graphique qui facilite la gestion des modèles.
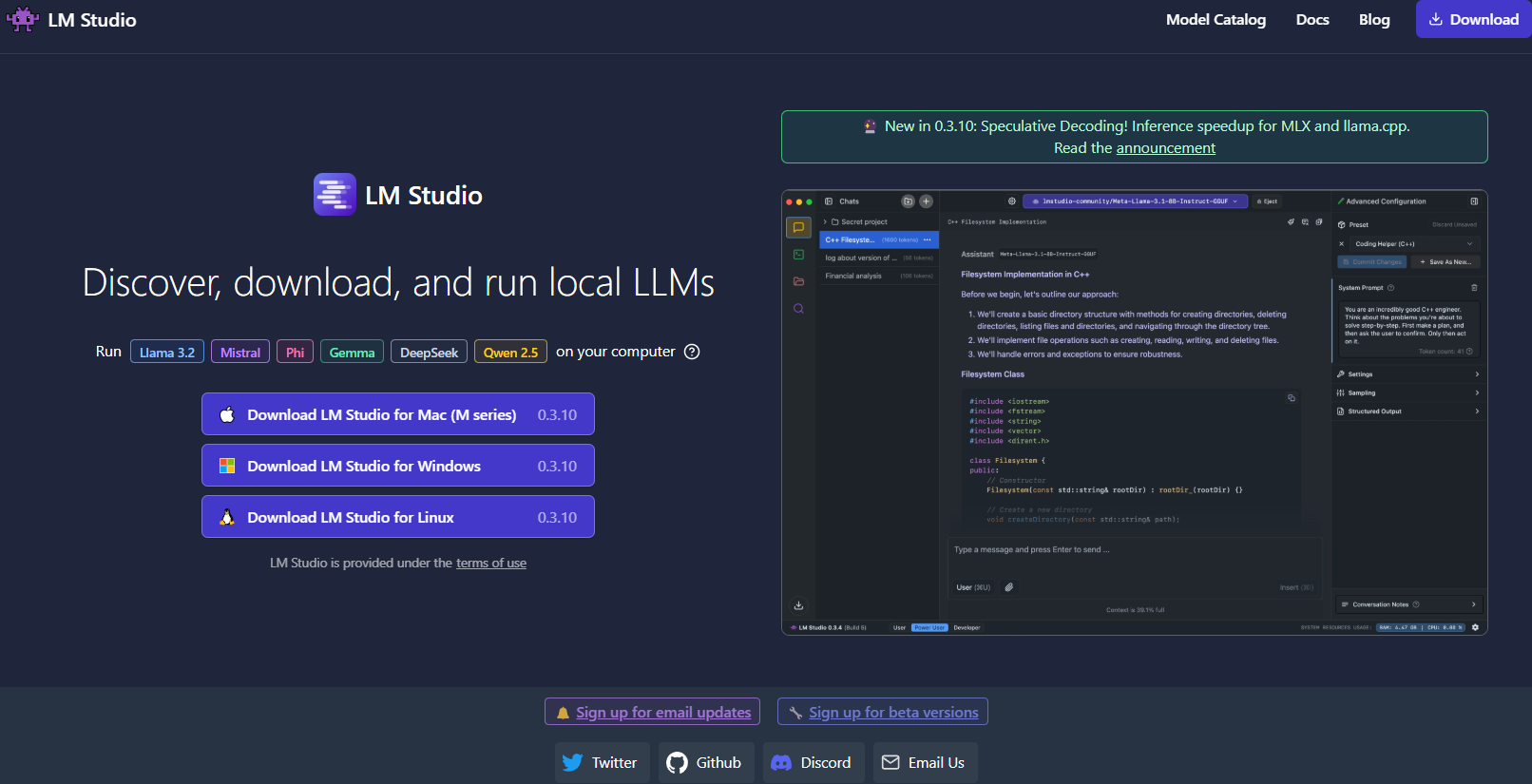
Ce qui distingue LM Studio ?
- Interface utilisateur intuitive : LM Studio fournit une application de bureau élégante et conviviale. Ceci est idéal pour ceux qui préfèrent ne pas travailler uniquement sur la ligne de commande.
- Gestion des modèles : Avec LM Studio, vous pouvez facilement parcourir, télécharger et basculer entre différents LLM. L'application propose des filtres intégrés et des fonctionnalités de recherche, vous permettant de trouver le modèle parfait pour votre projet.
- Paramètres personnalisables : Ajustez les paramètres tels que la température, le nombre maximal de jetons et la fenêtre contextuelle directement à partir de l'interface utilisateur. Cette boucle de rétroaction immédiate est parfaite pour apprendre comment différentes configurations affectent le comportement du modèle.
- Compatibilité multiplateforme : LM Studio fonctionne sur Windows, macOS et Linux, ce qui le rend accessible à un large éventail d'utilisateurs.
- Serveur d'inférence local : Les développeurs peuvent également tirer parti de son serveur HTTP local, qui imite l'API OpenAI. Cela simplifie considérablement l'intégration des capacités LLM dans vos applications.
Comment configurer LM Studio
- Téléchargement et installation : Visitez le site Web de LM Studio, téléchargez le programme d'installation pour votre système d'exploitation et suivez les instructions de configuration.
- Lancement et exploration : Ouvrez l'application, explorez la bibliothèque de modèles disponibles et sélectionnez celui qui correspond à vos besoins.
- Expérimentation : Utilisez l'interface de chat intégrée pour interagir avec le modèle. Vous pouvez également expérimenter avec plusieurs modèles simultanément pour comparer les performances et la qualité.
Imaginez que vous travaillez sur un projet d'écriture créative ; l'interface de LM Studio facilite le basculement entre les modèles et l'affinement de la sortie en temps réel. Ses commentaires visuels et sa facilité d'utilisation en font un choix judicieux pour ceux qui débutent ou pour les professionnels qui ont besoin d'une solution locale robuste.
Outil n° 4 : Ollama
Vient ensuite Ollama, un outil de ligne de commande puissant mais simple, axé à la fois sur la simplicité et la fonctionnalité. Ollama est conçu pour vous aider à exécuter, créer et partager des LLM sans les tracas des configurations complexes.
Pourquoi choisir Ollama ?
- Déploiement facile du modèle : Ollama regroupe tout ce dont vous avez besoin : les pondérations du modèle, la configuration et même les données, en une seule unité portable appelée « Modelfile ». Cela signifie que vous pouvez rapidement télécharger et exécuter un modèle avec une configuration minimale.
- Capacités multimodales : Contrairement à certains outils qui se concentrent uniquement sur le texte, Ollama prend en charge les entrées multimodales. Vous pouvez fournir à la fois du texte et des images comme invites, et l'outil générera des réponses qui en tiennent compte.
- Disponibilité multiplateforme : Ollama est disponible sur macOS, Linux et Windows. C'est une excellente option pour les développeurs qui travaillent sur différents systèmes.
- Efficacité de la ligne de commande : Pour ceux qui préfèrent travailler dans le terminal, Ollama offre une interface de ligne de commande propre et efficace qui permet un déploiement et une interaction rapides.
- Mises à jour rapides : L'outil est fréquemment mis à jour par sa communauté, ce qui vous garantit de toujours travailler avec les dernières améliorations et fonctionnalités.
Configuration d'Ollama
1. Installation : Visitez le site Web d'Ollama et téléchargez le programme d'installation pour votre système d'exploitation. L'installation est aussi simple que d'exécuter quelques commandes dans votre terminal.
2. Exécuter un modèle : Une fois installé, utilisez une commande telle que :
ollama run llama3
Cette commande téléchargera automatiquement le modèle Llama 3 (ou tout autre modèle pris en charge) et démarrera le processus d'inférence.
3. Expérimentez avec la multimodalité : Essayez d'exécuter un modèle qui prend en charge les images. Par exemple, si vous avez un fichier image prêt, vous pouvez le faire glisser et le déposer dans votre invite (ou utiliser le paramètre d'API pour les images) pour voir comment le modèle répond.
Ollama est particulièrement intéressant si vous cherchez à prototyper ou à déployer rapidement des LLM localement. Sa simplicité ne se fait pas au détriment de la puissance, ce qui le rend idéal pour les débutants et les développeurs chevronnés.
Outil n° 5 : Jan
Enfin et surtout, nous avons Jan. Jan est une plateforme open source, locale d'abord, qui gagne régulièrement en popularité auprès de ceux qui privilégient la confidentialité des données et le fonctionnement hors ligne. Sa philosophie est simple : permettre aux utilisateurs d'exécuter des LLM puissants entièrement sur leur propre matériel, sans transferts de données cachés.
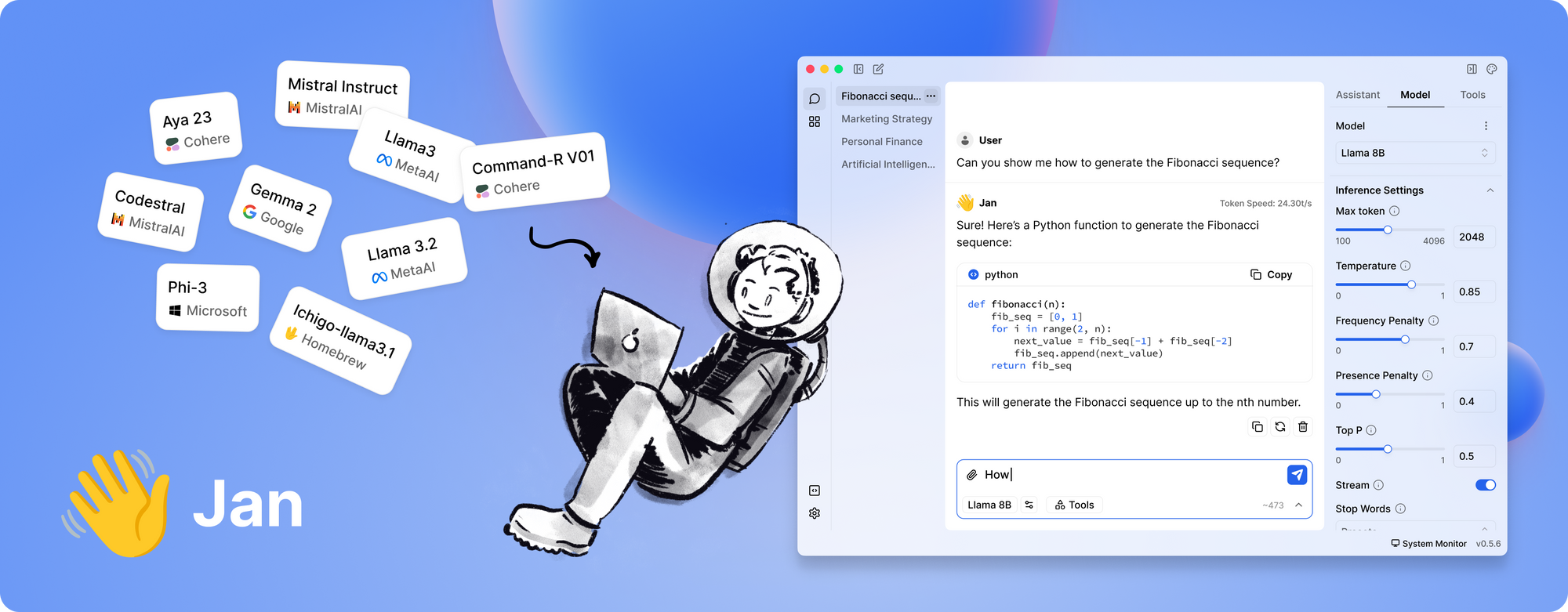
Qu'est-ce qui distingue Jan ?
- Entièrement hors ligne : Jan est conçu pour fonctionner sans connexion Internet. Cela garantit que toutes vos interactions et données restent locales, améliorant ainsi la confidentialité et la sécurité.
- Centré sur l'utilisateur et extensible : L'outil offre une interface épurée et prend en charge un framework d'applications/plugins. Cela signifie que vous pouvez facilement étendre ses capacités ou l'intégrer à vos outils existants.
- Exécution efficace du modèle : Jan est conçu pour gérer une variété de modèles, y compris ceux qui sont affinés pour des tâches spécifiques. Il est optimisé pour fonctionner même sur du matériel modeste, sans compromettre les performances.
- Développement axé sur la communauté : Comme bon nombre des outils de notre liste, Jan est open source et bénéficie des contributions d'une communauté dédiée de développeurs.
- Pas de frais d'abonnement : Contrairement à de nombreuses solutions basées sur le cloud, Jan est gratuit. Cela en fait un excellent choix pour les startups, les amateurs et tous ceux qui souhaitent expérimenter les LLM sans barrières financières.
Comment démarrer avec Jan
- Télécharger et installer : Rendez-vous sur le site Web officiel de Jan ou sur le référentiel GitHub. Suivez les instructions d'installation, qui sont simples et conçues pour vous permettre d'être opérationnel rapidement.
- Lancer et personnaliser : Ouvrez Jan et choisissez parmi une variété de modèles préinstallés. Si nécessaire, vous pouvez importer des modèles à partir de sources externes telles que Hugging Face.
- Expérimenter et développer : Utilisez l'interface de chat pour interagir avec votre LLM. Ajustez les paramètres, installez des plugins et voyez comment Jan s'adapte à votre flux de travail. Sa flexibilité vous permet d'adapter votre expérience LLM locale à vos besoins précis.
Jan incarne véritablement l'esprit de l'exécution LLM locale axée sur la confidentialité. Il est parfait pour tous ceux qui souhaitent un outil personnalisable et sans tracas qui conserve toutes les données sur leur propre machine.
Conseil de pro : diffusion en continu des réponses LLM à l'aide du débogage SSE
Si vous travaillez avec des LLM (grands modèles linguistiques), l'interaction en temps réel peut grandement améliorer l'expérience utilisateur. Qu'il s'agisse d'un chatbot fournissant des réponses en direct ou d'un outil de contenu se mettant à jour dynamiquement au fur et à mesure de la génération des données, la diffusion en continu est essentielle. Les événements envoyés par le serveur (SSE) offrent une solution efficace pour cela, permettant aux serveurs d'envoyer des mises à jour aux clients via une seule connexion HTTP. Contrairement aux protocoles bidirectionnels comme WebSockets, SSE est plus simple et plus direct, ce qui en fait un excellent choix pour les fonctionnalités en temps réel.
Le débogage SSE peut être difficile. C'est là qu'Apidog entre en jeu. La fonctionnalité de débogage SSE d'Apidog vous permet de tester, de surveiller et de dépanner les flux SSE avec facilité. Dans cette section, nous allons explorer pourquoi SSE est adapté au débogage des API LLM et vous guiderons dans un tutoriel étape par étape sur l'utilisation d'Apidog pour configurer et tester les connexions SSE.
Pourquoi SSE est important pour le débogage des API LLM
Avant de plonger dans le tutoriel, voici pourquoi SSE est idéal pour le débogage des API LLM :
- Commentaires en temps réel : SSE diffuse les données au fur et à mesure de leur génération, ce qui permet aux utilisateurs de voir les réponses se dérouler naturellement.
- Faible surcharge : contrairement à l'interrogation, SSE utilise une seule connexion persistante, minimisant ainsi l'utilisation des ressources.
- Facilité d'utilisation : SSE s'intègre de manière transparente dans les applications Web, nécessitant une configuration minimale côté client.
Prêt à le tester ? Configurons le débogage SSE dans Apidog.
Tutoriel étape par étape : utilisation du débogage SSE dans Apidog
Suivez ces étapes pour configurer et tester une connexion SSE avec Apidog.
Étape 1 : créer un nouveau point de terminaison dans Apidog
Créez un nouveau projet HTTP dans Apidog pour tester et déboguer les requêtes API. Ajoutez un point de terminaison avec l'URL du modèle d'IA pour le flux SSE, en utilisant DeepSeek dans cet exemple. (CONSEIL DE PRO : Clonez le projet d'API DeepSeek prêt à l'emploi à partir du hub d'API d'Apidog).
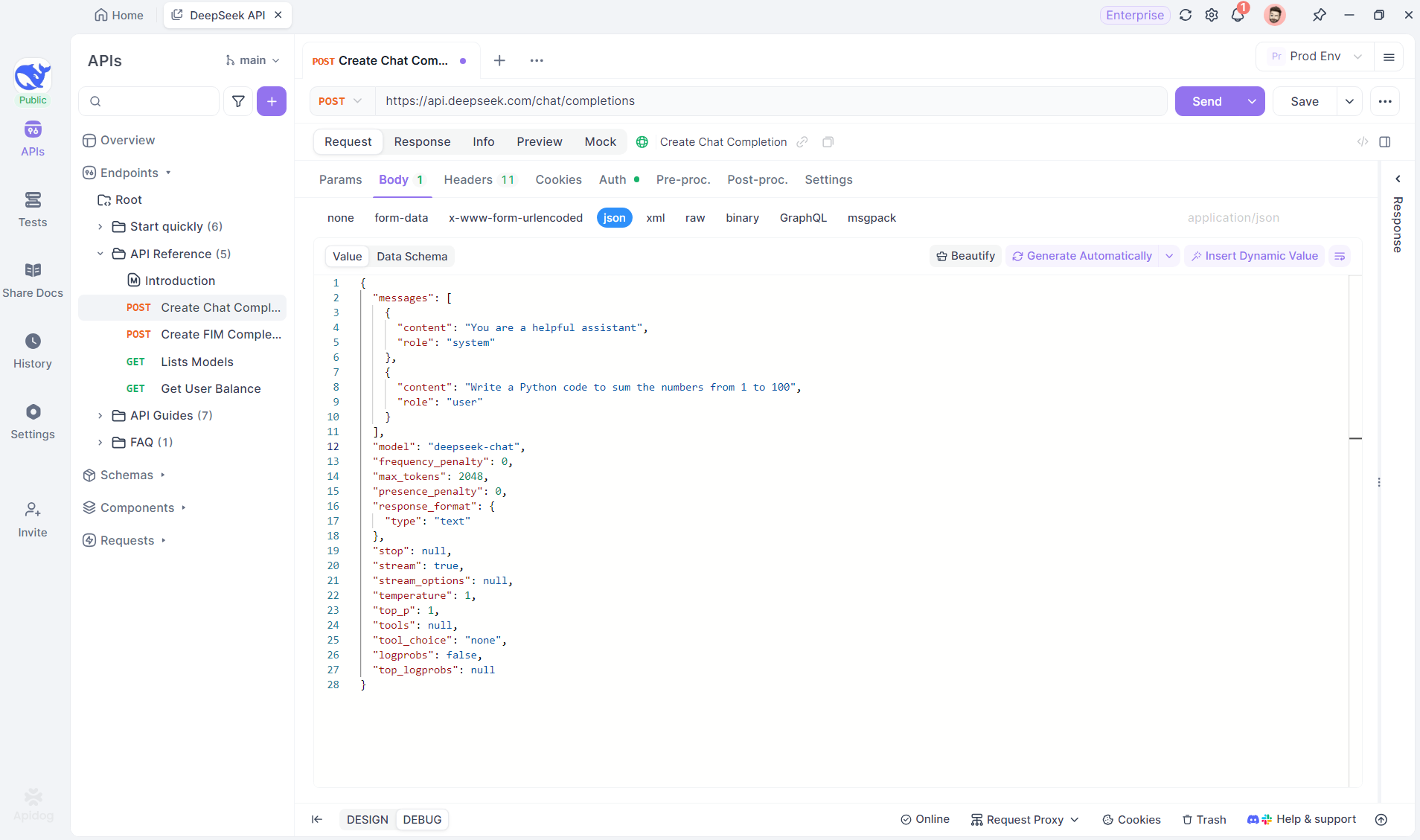
Étape 2 : envoyer la requête
Après avoir ajouté le point de terminaison, cliquez sur Envoyer pour envoyer la requête. Si l'en-tête de réponse inclut Content-Type : text/event-stream, Apidog détectera le flux SSE, analysera les données et les affichera en temps réel.
Étape 3 : afficher les réponses en temps réel
La vue chronologique d'Apidog se met à jour en temps réel au fur et à mesure que le modèle d'IA diffuse les réponses, affichant chaque fragment de manière dynamique. Cela vous permet de suivre le processus de réflexion de l'IA et d'obtenir des informations sur sa génération de sortie.
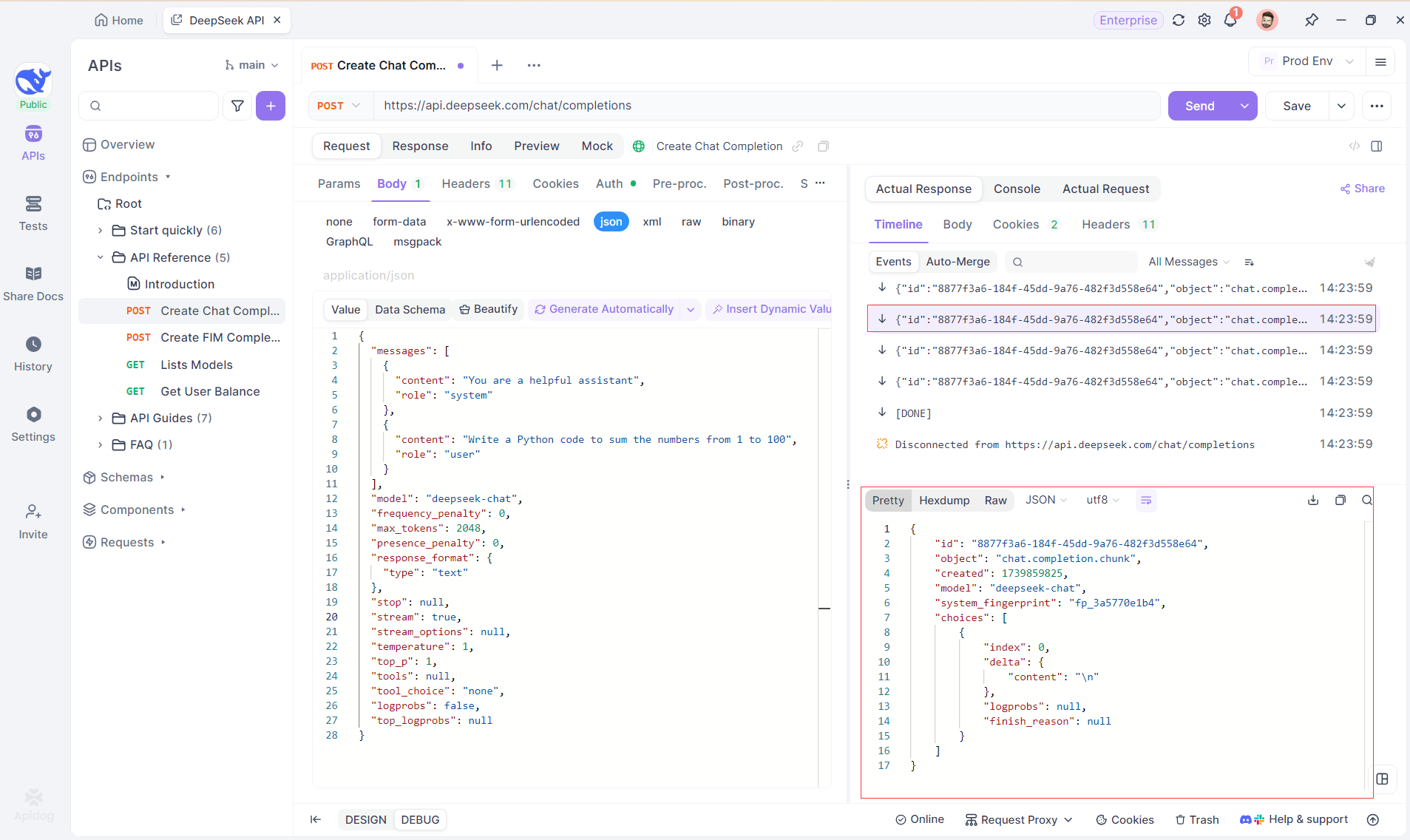
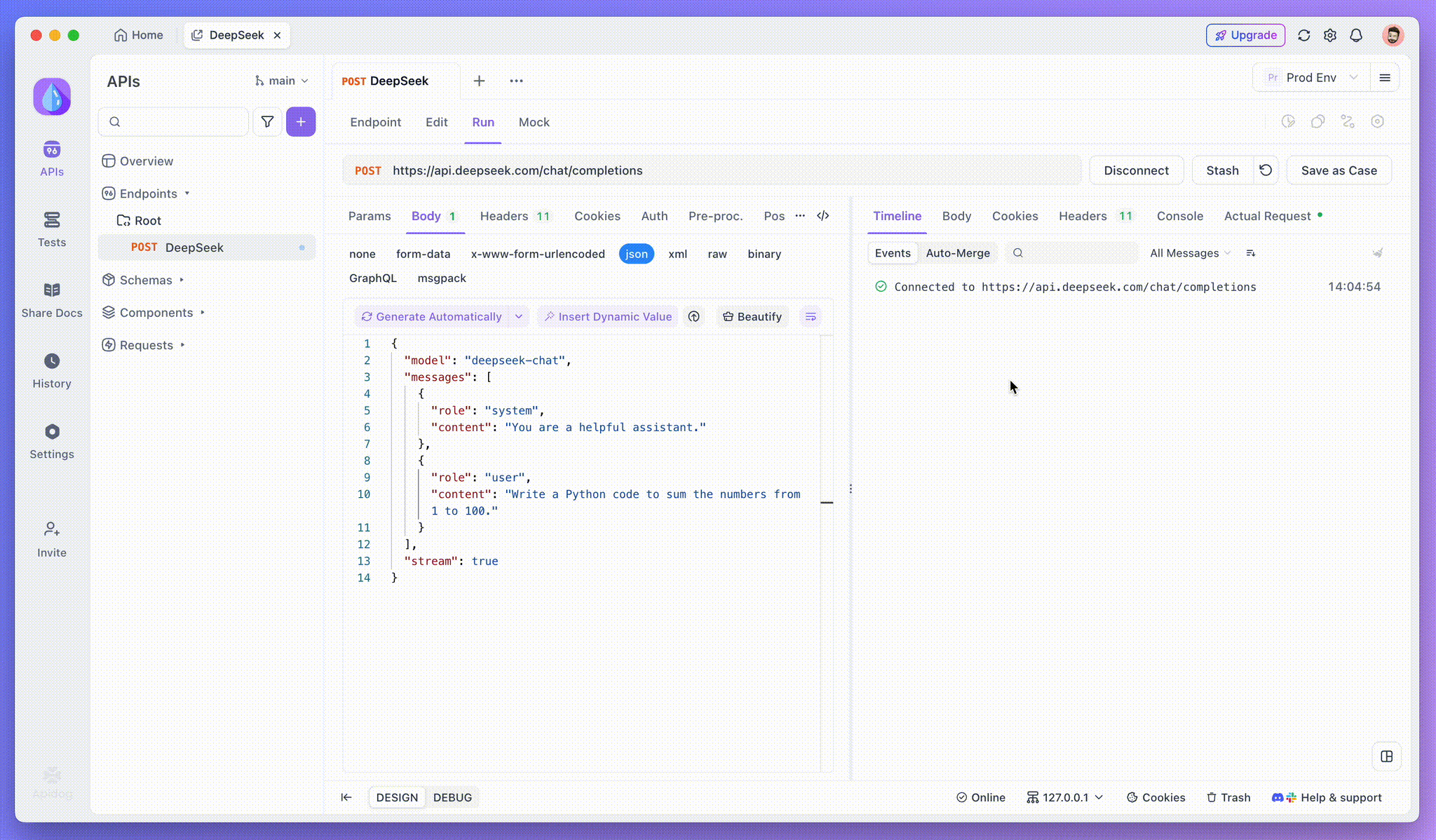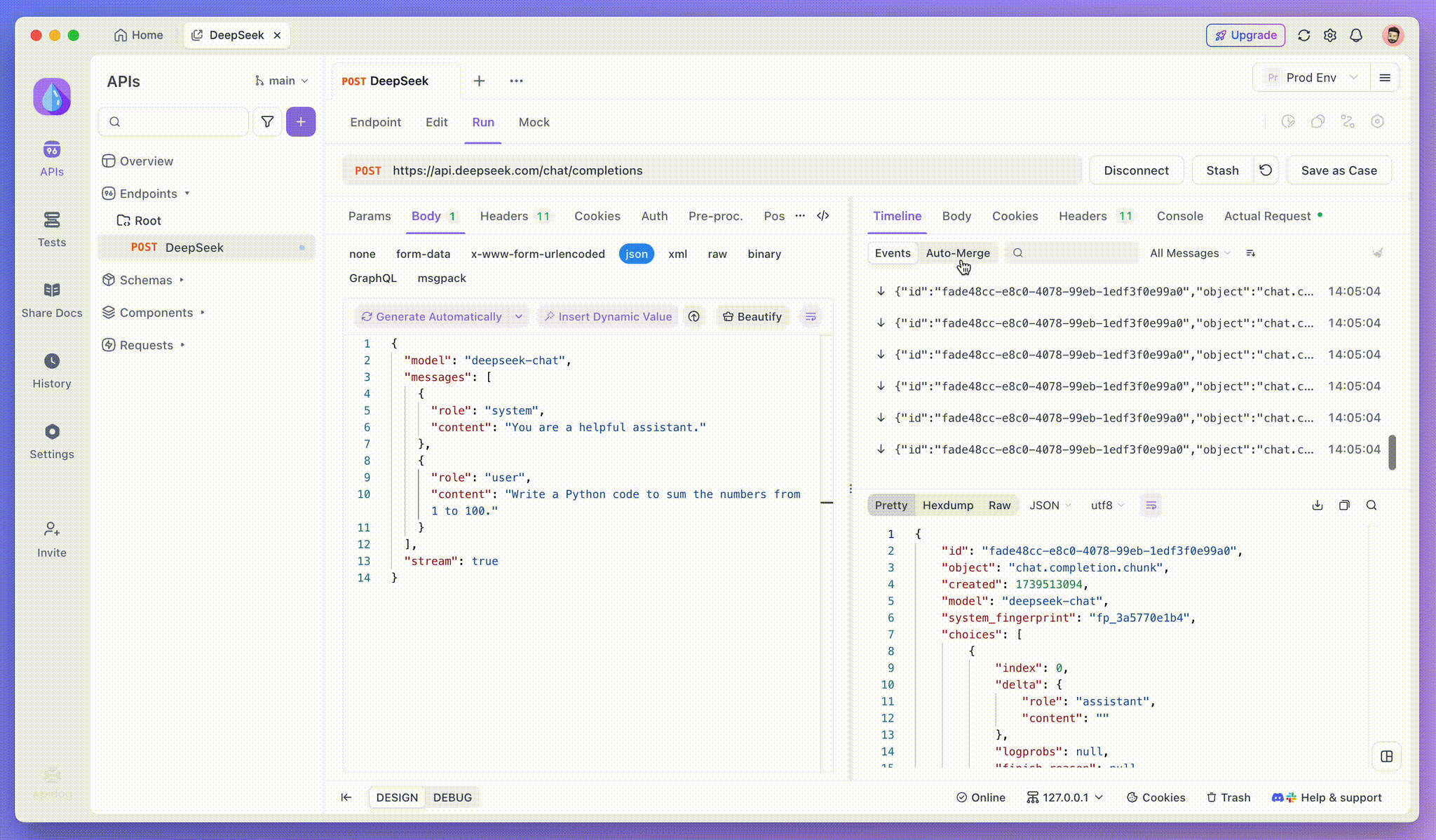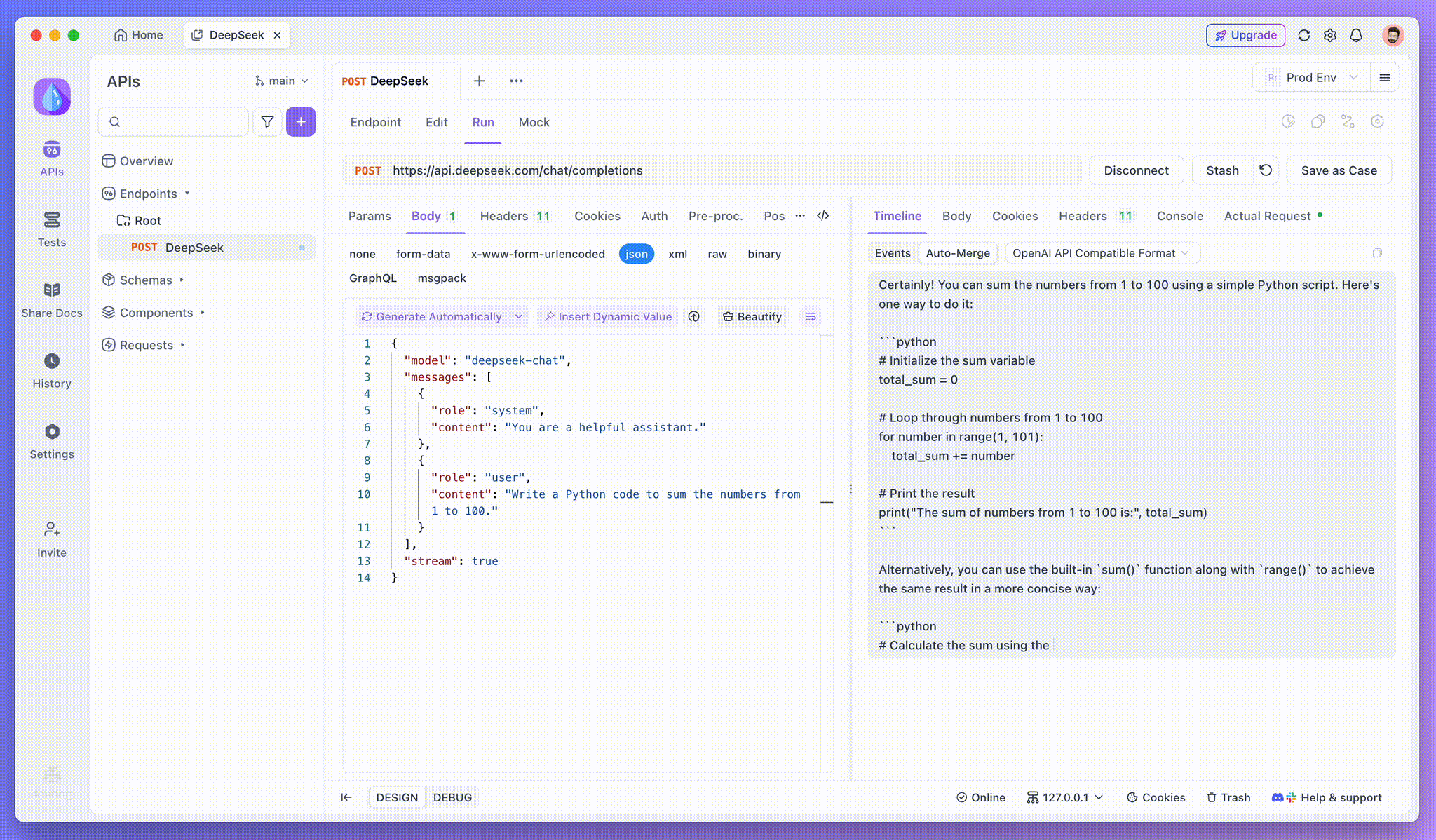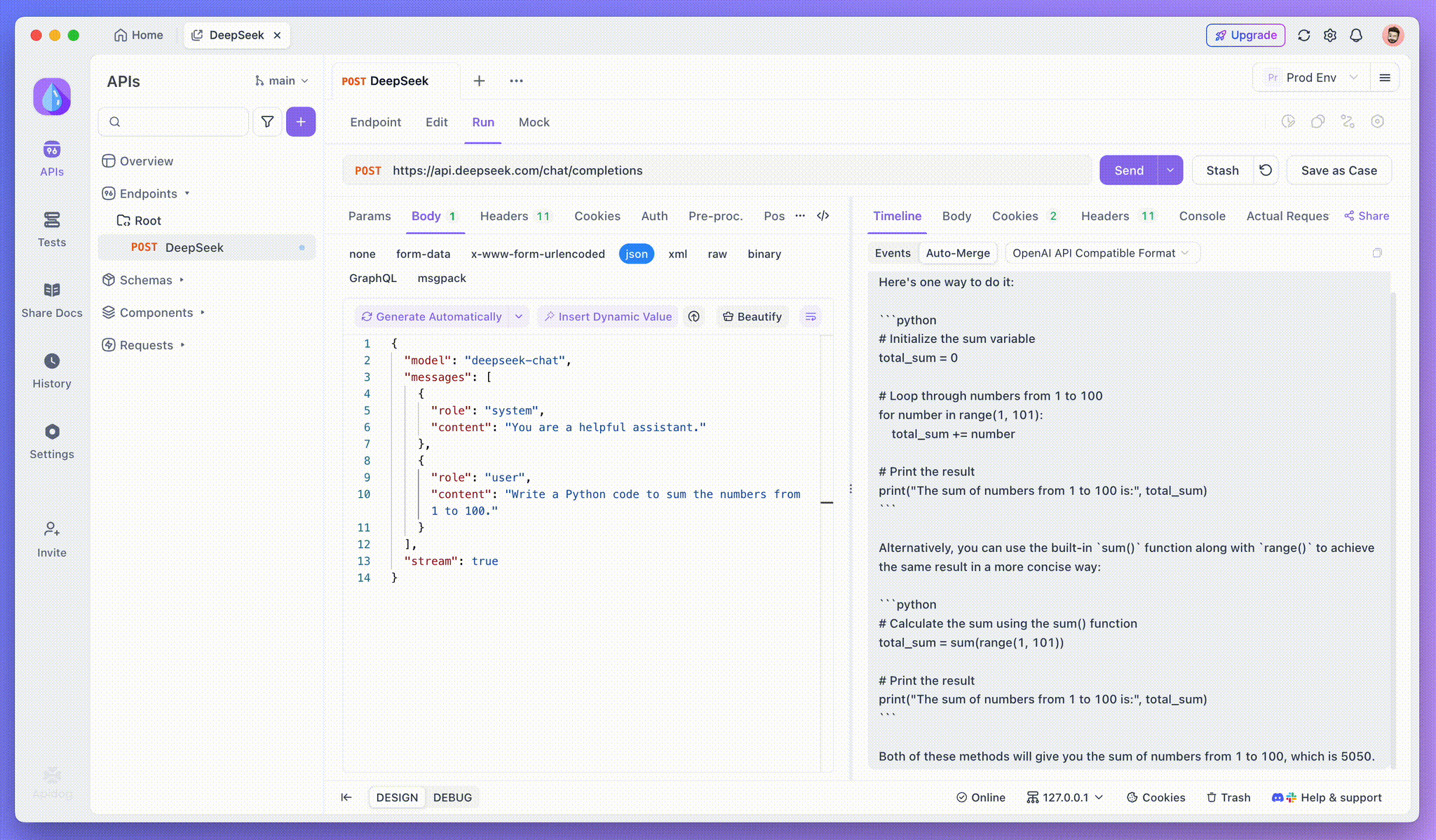
Étape 4 : afficher la réponse SSE dans une réponse complète
SSE diffuse les données par fragments, ce qui nécessite une gestion supplémentaire. La fonctionnalité Fusion automatique d'Apidog résout ce problème en combinant automatiquement les réponses d'IA fragmentées de modèles tels que OpenAI, Gemini ou Claude en une sortie complète.
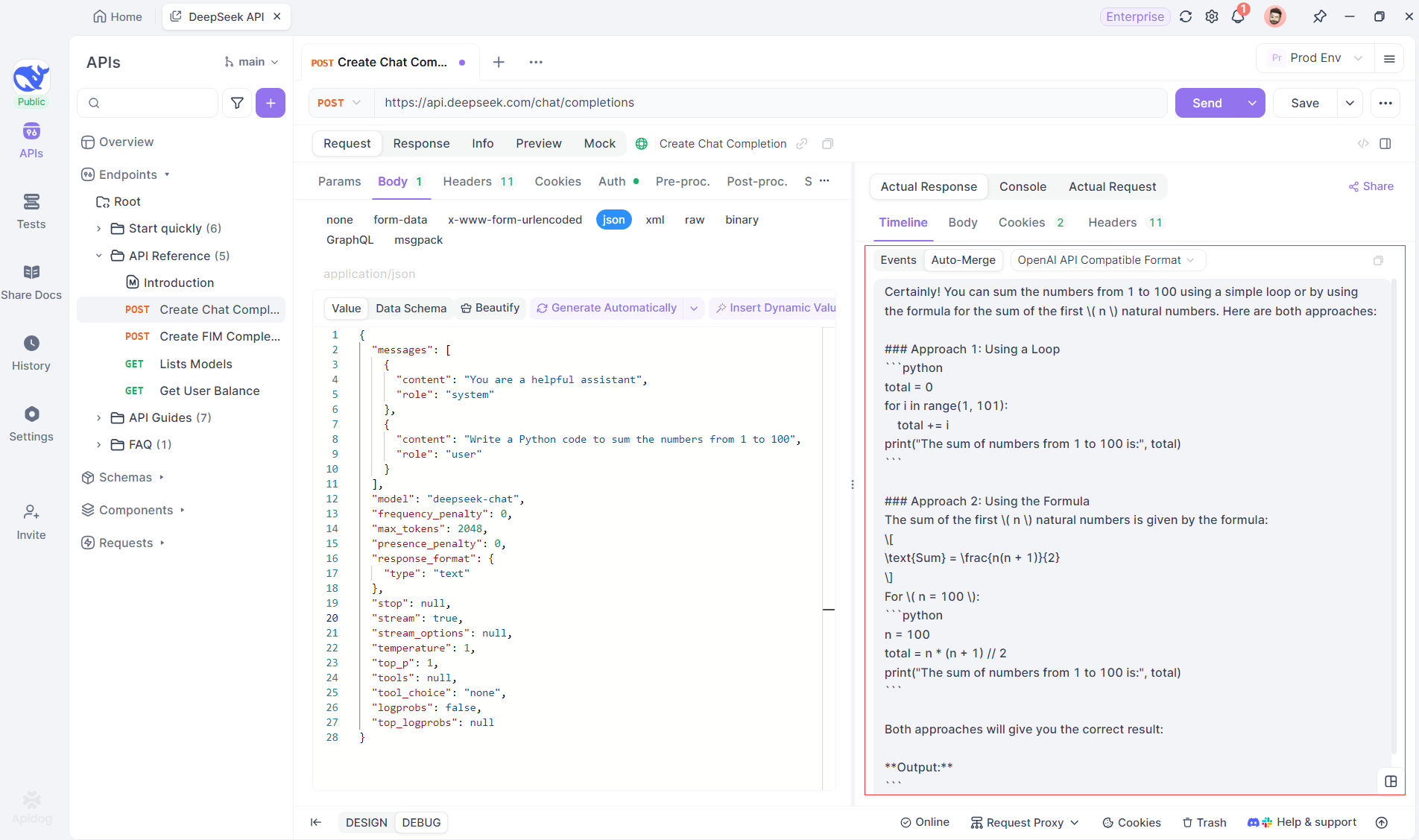
La fonctionnalité Fusion automatique d'Apidog élimine la gestion manuelle des données en combinant automatiquement les réponses d'IA fragmentées de modèles tels que OpenAI, Gemini ou Claude.
Pour les modèles de raisonnement comme DeepSeek R1, la vue chronologique d'Apidog mappe visuellement le processus de réflexion de l'IA, ce qui facilite le débogage et la compréhension de la façon dont les conclusions sont formées.
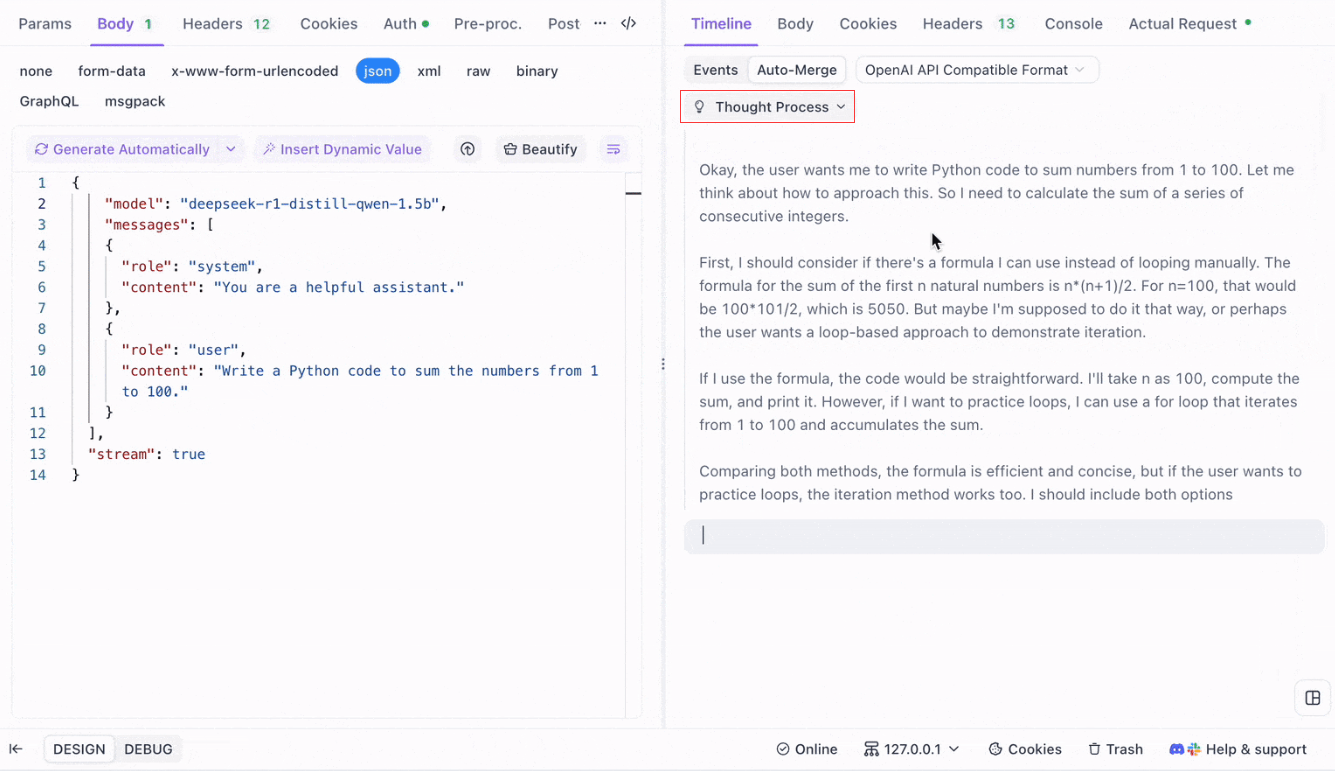
Apidog reconnaît et fusionne de manière transparente les réponses d'IA de :
- Format d'API OpenAI
- Format d'API Gemini
- Format d'API Claude
Lorsqu'une réponse correspond à ces formats, Apidog combine automatiquement les fragments, éliminant ainsi l'assemblage manuel et rationalisant le débogage SSE.
Conclusion et prochaines étapes
Nous avons couvert beaucoup de terrain aujourd'hui ! Pour résumer, voici les cinq outils exceptionnels pour exécuter des LLM localement :
- Llama.cpp : Idéal pour les développeurs qui souhaitent un outil de ligne de commande léger, rapide et très efficace avec une large prise en charge matérielle.
- GPT4All : Un écosystème local d'abord qui fonctionne sur du matériel grand public, offrant une interface intuitive et des performances puissantes.
- LM Studio : Parfait pour ceux qui préfèrent une interface graphique, avec une gestion facile des modèles et de nombreuses options de personnalisation.
- Ollama : Un outil de ligne de commande robuste avec des capacités multimodales et un emballage de modèle transparent grâce à son système « Modelfile ».
- Jan : Une plateforme open source, axée sur la confidentialité, qui fonctionne entièrement hors ligne, offrant un framework extensible pour l'intégration de divers LLM.
Chacun de ces outils offre des avantages uniques, qu'il s'agisse de performances, de facilité d'utilisation ou de confidentialité. En fonction des exigences de votre projet, l'une de ces solutions peut être parfaitement adaptée à vos besoins. La beauté des outils LLM locaux est qu'ils vous permettent d'explorer et d'expérimenter sans vous soucier des fuites de données, des coûts d'abonnement ou de la latence du réseau.
N'oubliez pas qu'expérimenter avec les LLM locaux est un processus d'apprentissage. N'hésitez pas à mélanger et à associer ces outils, à tester différentes configurations et à voir celle qui correspond le mieux à votre flux de travail. De plus, si vous intégrez ces modèles dans vos propres applications, des outils comme Apidog peuvent vous aider à gérer et à tester vos points de terminaison d'API LLM à l'aide d'événements envoyés par le serveur (SSE) de manière transparente. N'oubliez pas de télécharger Apidog gratuitement et d'améliorer votre expérience de développement local.
Prochaines étapes
- Expérimenter : Choisissez un outil dans notre liste et configurez-le sur votre machine. Jouez avec différents modèles et paramètres pour comprendre comment les modifications affectent la sortie.
- Intégrer : Si vous développez une application, utilisez l'outil LLM local dans le cadre de votre backend. Bon nombre de ces outils offrent une compatibilité API (par exemple, le serveur d'inférence local de LM Studio) qui peut faciliter l'intégration.
- Contribuer : La plupart de ces projets sont open source. Si vous trouvez un bug, une fonctionnalité manquante ou si vous avez simplement des idées d'amélioration, envisagez de contribuer à la communauté. Votre contribution peut aider à améliorer encore ces outils.
- En savoir plus : Continuez à explorer le monde des LLM en lisant des articles sur des sujets tels que la quantification des modèles, les techniques d'optimisation et l'ingénierie des invites. Plus vous comprenez, plus vous pouvez exploiter ces modèles à leur plein potentiel.
D'ici là, vous devriez avoir une base solide pour choisir le bon outil LLM local pour vos projets. Le paysage de la technologie LLM évolue rapidement, et l'exécution de modèles localement est une étape clé vers la création de solutions d'IA privées, évolutives et performantes.
Au fur et à mesure que vous expérimenterez avec ces outils, vous découvrirez que les possibilités sont infinies. Que vous travailliez sur un chatbot, un assistant de code ou un outil d'écriture créative personnalisé, les LLM locaux peuvent offrir la flexibilité et la puissance dont vous avez besoin. Profitez du voyage et bon codage !


