
Tongyi DeepResearch d'Alibaba redéfinit les agents d'IA autonomes avec son modèle Mixture of Experts (MoE) de 30 milliards de paramètres, n'activant que 3 milliards de paramètres par jeton pour une recherche web efficace et de haute fidélité. Cette puissance open source écrase les benchmarks comme Humanity's Last Exam (32,9 % contre 24,9 % pour OpenAI o3) et xbench-DeepSearch (75,0 % contre 67,0 %), permettant aux développeurs de s'attaquer à des requêtes complexes et multi-étapes – de l'analyse juridique aux itinéraires de voyage – sans dépendance propriétaire.
bouton
Les ingénieurs du Tongyi Lab ont conçu cet agent pour relever de front le raisonnement à long terme et l'utilisation dynamique d'outils. Par conséquent, il surpasse les modèles fermés en matière de synthèse dans le monde réel, tout en fonctionnant localement via Hugging Face. Dans cette analyse technique, nous disséquons son architecture éparse, son pipeline de données automatisé, son entraînement optimisé par RL, sa domination des benchmarks et ses astuces de déploiement. À la fin, vous verrez comment Tongyi DeepResearch – et des outils comme Apidog – débloquent l'IA agentique évolutive pour vos projets.
Comprendre Tongyi DeepResearch : concepts clés et innovations
Tongyi DeepResearch redéfinit l'IA agentique en se concentrant sur la récupération et la synthèse d'informations approfondies. Contrairement aux modèles de langage étendus (LLM) traditionnels qui excellent dans la génération de formes courtes, cet agent navigue dans des environnements dynamiques comme les navigateurs web pour découvrir des informations nuancées. Plus précisément, il utilise une architecture Mixture of Experts (MoE), où les 30 milliards de paramètres complets s'activent sélectivement à seulement 3 milliards par jeton. Cette efficacité permet des performances robustes sur du matériel aux ressources limitées tout en maintenant une conscience contextuelle élevée jusqu'à 128K jetons.
De plus, le modèle s'intègre parfaitement aux paradigmes d'inférence qui imitent la prise de décision humaine. En mode ReAct, il parcourt nativement les étapes de pensée, d'action et d'observation, contournant l'ingénierie de prompt lourde. Pour les tâches plus exigeantes, le mode Heavy active le framework IterResearch, qui orchestre des explorations d'agents parallèles pour éviter la surcharge contextuelle. En conséquence, les utilisateurs obtiennent des résultats supérieurs dans des scénarios nécessitant un raffinement itératif, tels que les revues de littérature académique ou l'analyse de marché.
Ce qui distingue Tongyi DeepResearch, c'est son engagement envers l'ouverture. L'intégralité de la pile – des poids du modèle au code d'entraînement – réside sur des plateformes comme Hugging Face et GitHub. Les développeurs accèdent directement à la variante Tongyi-DeepResearch-30B-A3B, facilitant le réglage fin pour des besoins spécifiques à un domaine. De plus, sa compatibilité avec les environnements Python standards abaisse la barrière à l'entrée. Par exemple, l'installation implique une simple commande pip après la configuration d'un environnement Conda avec Python 3.10.
En passant à l'utilité pratique, Tongyi DeepResearch alimente des applications qui exigent des sorties vérifiables. Dans la recherche juridique, il analyse les statuts et la jurisprudence, citant les sources avec précision. De même, dans la planification de voyages, il construit des itinéraires de plusieurs jours en recoupant des données en temps réel. Ces capacités découlent d'une philosophie de conception délibérée : privilégier le raisonnement agentique plutôt que la simple prédiction.
L'architecture de Tongyi DeepResearch : efficacité et puissance
À la base, Tongyi DeepResearch exploite une conception MoE éparse pour équilibrer les exigences computationnelles avec la puissance expressive. Le modèle n'active qu'un sous-ensemble d'experts par jeton, acheminant les entrées dynamiquement en fonction de la complexité de la requête. Cette approche réduit la latence jusqu'à 90 % par rapport aux homologues denses, ce qui la rend viable pour les déploiements d'agents en temps réel. De plus, la fenêtre contextuelle de 128K prend en charge les interactions étendues, cruciales pour les tâches impliquant de longues chaînes de documents ou des recherches web thématiques.
Les composants architecturaux clés incluent un tokenizer personnalisé optimisé pour les jetons agentiques – tels que les préfixes d'action et les délimiteurs d'observation – et une suite d'outils intégrée pour la navigation de navigateur, la récupération et le calcul. Le framework prend en charge l'intégration de l'apprentissage par renforcement (RL) en politique, où les agents apprennent à partir de simulations dans un environnement stable. Par conséquent, le modèle présente moins d'hallucinations dans les invocations d'outils, comme en témoignent ses scores élevés sur les benchmarks d'utilisation d'outils.
De plus, Tongyi DeepResearch intègre une mémoire de connaissances ancrée aux entités, dérivée de la synthèse de données basée sur des graphes. Ce mécanisme ancre les réponses à des entités factuelles, améliorant la traçabilité. Par exemple, lors d'une requête sur les avancées de l'informatique quantique, l'agent récupère et synthétise des articles via des outils de type WebSailor, basant les résultats sur des sources vérifiables. Ainsi, l'architecture ne se contente pas de traiter l'information, elle la sélectionne activement.
Pour illustrer, considérons la gestion des entrées multimodales par le modèle. Bien que principalement basé sur du texte, les extensions via le dépôt GitHub permettent l'intégration avec des analyseurs d'images ou des exécuteurs de code. Les développeurs configurent ces éléments dans le script d'inférence, en spécifiant les chemins pour les jeux de données au format JSONL. Ainsi, l'architecture favorise l'extensibilité, invitant les contributions de la communauté open source.
Synthèse de données automatisée : alimenter les capacités de Tongyi DeepResearch
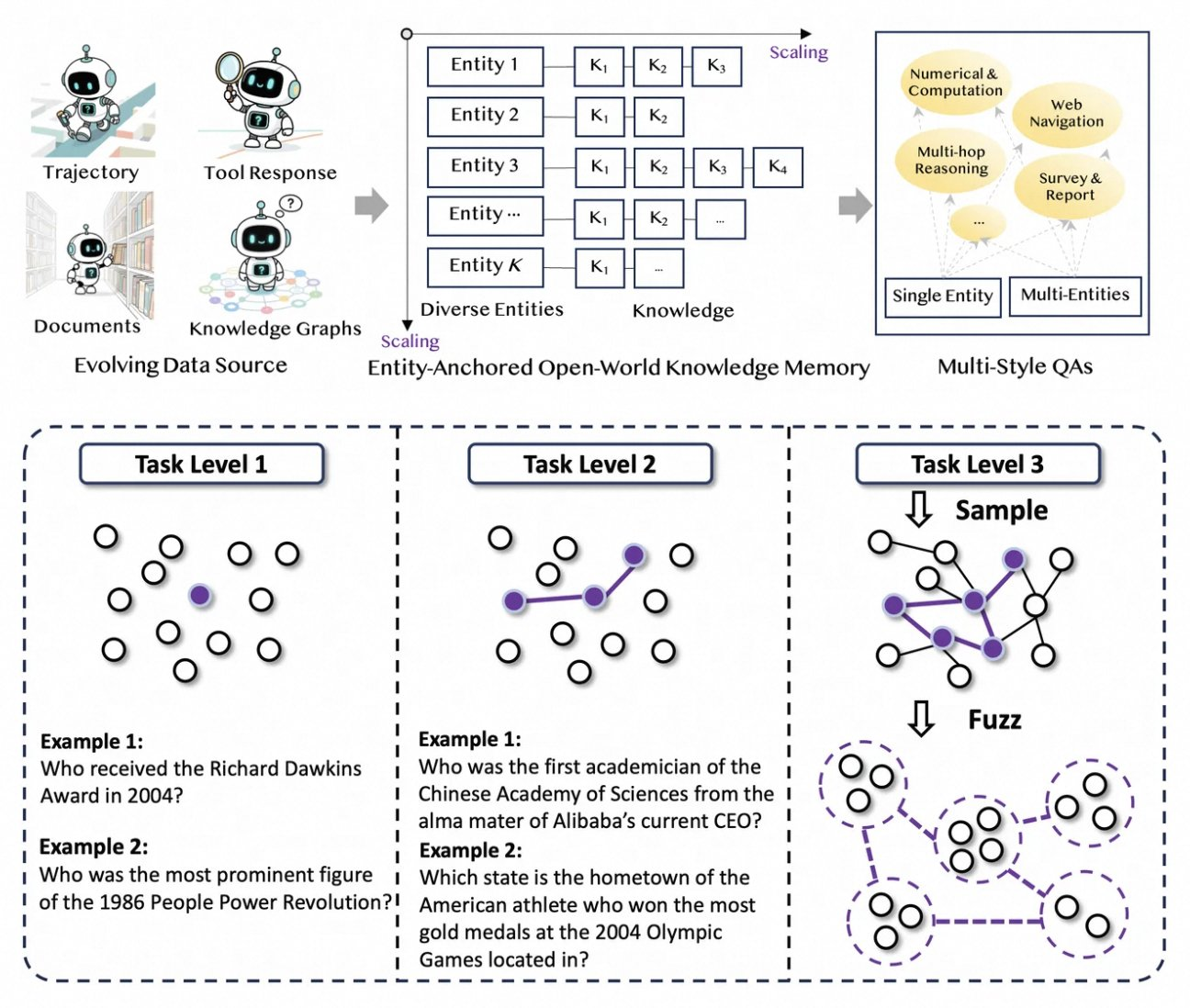
Tongyi DeepResearch prospère grâce à un pipeline de données novateur, entièrement automatisé, qui élimine les goulots d'étranglement de l'annotation humaine. Le processus commence avec AgentFounder, un moteur de synthèse qui réorganise les corpus bruts – documents, explorations web et graphes de connaissances – en paires QA ancrées aux entités. Cette étape génère diverses trajectoires pour le pré-entraînement continu (CPT), couvrant les chaînes de raisonnement, les appels d'outils et les arbres de décision.
Ensuite, le pipeline augmente la difficulté par des mises à niveau itératives. Pour le post-entraînement, il utilise des méthodes basées sur des graphes comme WebSailor-V2 pour simuler des défis "surhumains", tels que des questions de niveau doctorat modélisées via la théorie des ensembles. En conséquence, l'ensemble de données s'étend sur des millions d'interactions de haute fidélité, garantissant que le modèle se généralise à travers les domaines. Notamment, cette automatisation évolue linéairement avec la puissance de calcul, permettant des mises à jour continues sans curation manuelle.
De plus, Tongyi DeepResearch intègre des données multi-styles pour la robustesse. Les enregistrements de synthèse d'actions capturent les schémas d'utilisation d'outils, tandis que les paires QA multi-étapes affinent les compétences de planification. En pratique, cela produit des agents qui s'adaptent aux environnements web bruyants, filtrant efficacement les extraits non pertinents. Pour les développeurs, le dépôt fournit des scripts pour reproduire ce pipeline, permettant la création de jeux de données personnalisés.
En privilégiant la qualité à la quantité, la stratégie de synthèse aborde les pièges courants de l'entraînement d'agents, comme les changements de distribution. Par conséquent, les modèles entraînés de cette manière démontrent une meilleure adéquation avec les tâches du monde réel, comme en témoigne sa domination des benchmarks.
Pipeline d'entraînement de bout en bout : du CPT à l'optimisation RL
L'entraînement de Tongyi DeepResearch se déroule dans un pipeline fluide : CPT agentique, réglage fin supervisé (SFT) et apprentissage par renforcement (RL). Premièrement, le CPT expose le modèle de base à de vastes données agentiques, l'infusant avec des a priori de navigation web et des signaux de fraîcheur. Cette phase active des capacités latentes, telles que la planification implicite, par la modélisation de langage masqué sur les trajectoires.

Après le CPT, le SFT aligne le modèle sur des formats instructionnels, utilisant des simulations synthétiques pour enseigner la formulation précise d'actions. Ici, le modèle apprend à générer des cycles ReAct cohérents, minimisant les erreurs d'analyse d'observation. En passant en douceur, l'étape RL emploie l'optimisation de politique relative de groupe (GRPO), un algorithme sur-politique personnalisé.
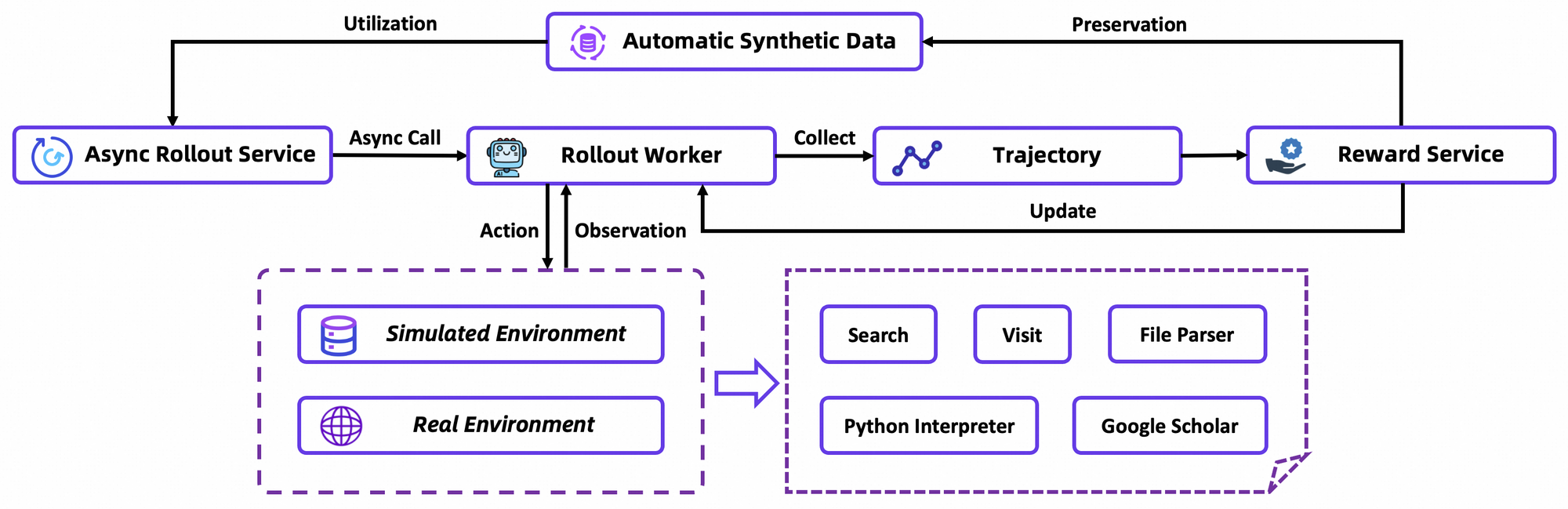
GRPO calcule les gradients de politique au niveau du jeton avec une estimation de l'avantage leave-one-out, réduisant la variance dans les environnements non stationnaires. Il filtre également les échantillons négatifs de manière conservatrice, stabilisant les mises à jour dans le simulateur personnalisé – une base de données Wikipedia hors ligne associée à un bac à sable d'outils. Les rollouts asynchrones via le framework rLLM accélèrent la convergence, atteignant l'état de l'art (SOTA) avec une puissance de calcul modeste.
En détail, l'environnement RL simule fidèlement les interactions du navigateur, récompensant le succès multi-étapes plutôt que les actions uniques. Cela favorise la planification à long terme, où les agents itèrent sur des échecs partiels. À titre de note technique, la fonction de perte intègre la divergence KL pour le conservatisme, empêchant l'effondrement de mode. Les développeurs reproduisent cela via les scripts d'évaluation du dépôt, en comparant les politiques personnalisées.
Dans l'ensemble, ce pipeline marque une avancée : il connecte le pré-entraînement au déploiement sans silos, produisant des agents qui évoluent par essais et erreurs.
Performance des benchmarks : comment Tongyi DeepResearch excelle
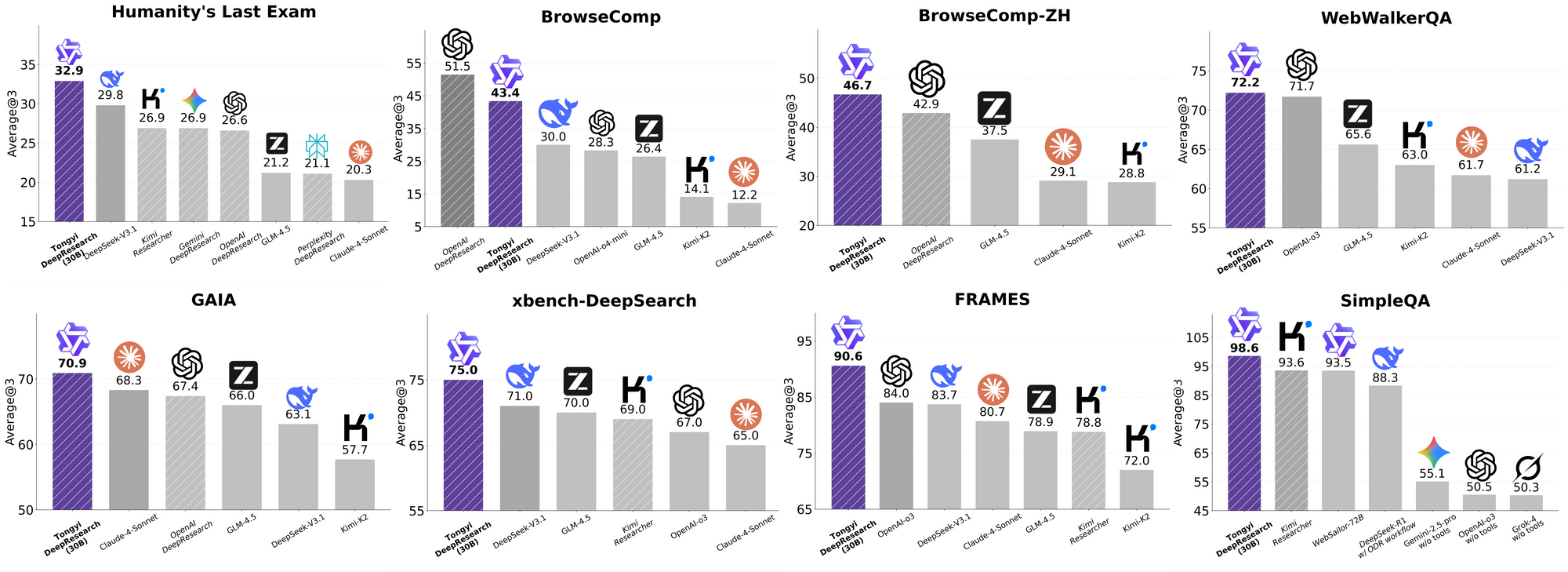
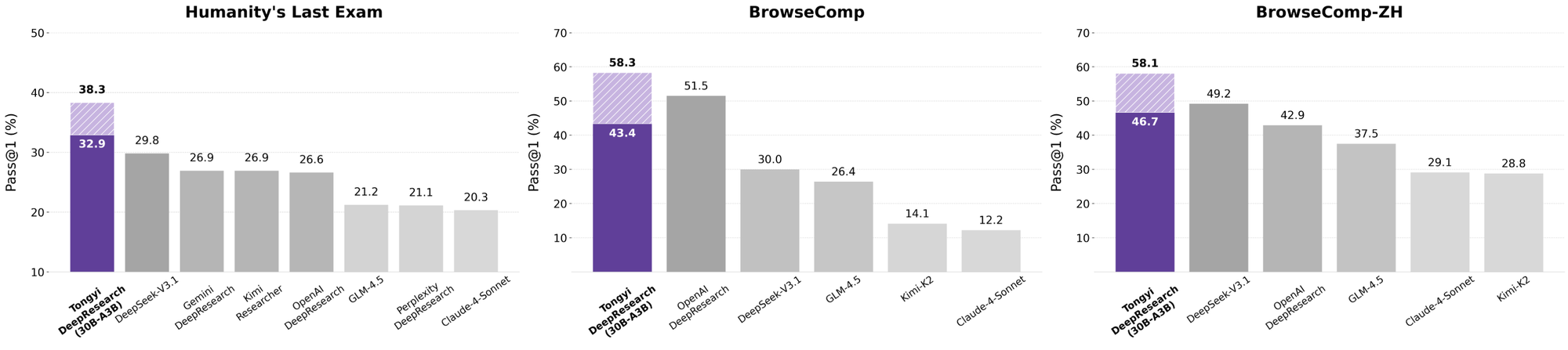
Tongyi DeepResearch brille dans les benchmarks agentiques rigoureux, validant sa conception. Sur Humanity's Last Exam (HLE), un test de raisonnement académique, il obtient un score de 32,9 en mode ReAct – dépassant OpenAI o3 à 24,9. Cet écart s'élargit en mode Heavy à 38,3, soulignant l'efficacité d'IterResearch.
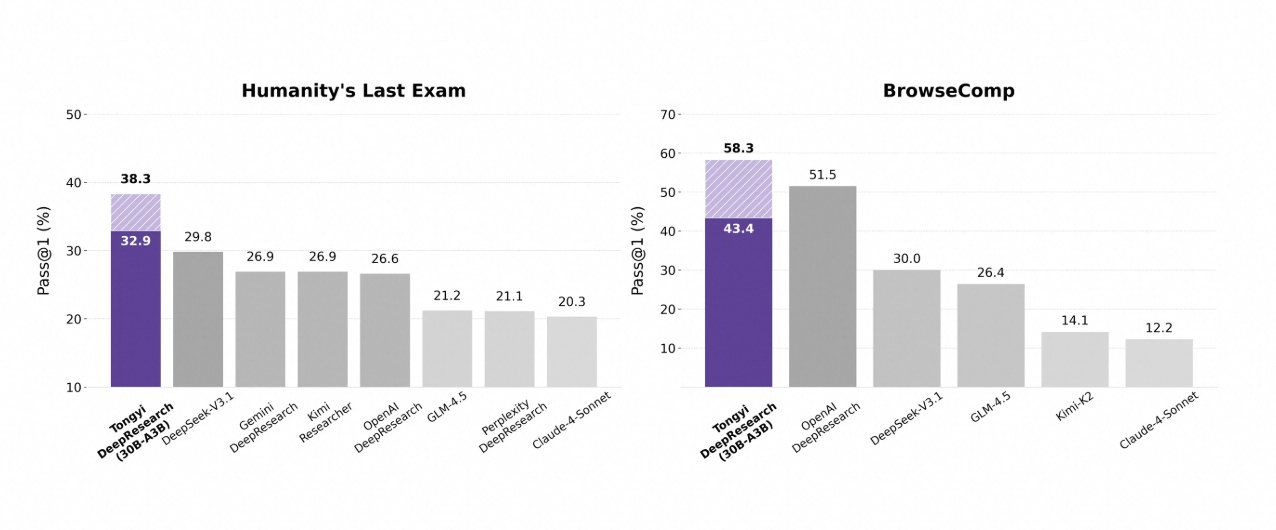
De même, BrowseComp évalue la recherche d'informations complexes ; Tongyi atteint 43,4 (EN) et 46,7 (ZH), dépassant respectivement o3 à 49,7 et 58,1 en efficacité. Le benchmark xbench-DeepSearch, centré sur l'utilisateur pour les requêtes approfondies, voit Tongyi à 75,0 contre 67,0 pour o3, soulignant une synthèse de récupération supérieure.
D'autres métriques renforcent cela : FRAMES à 90,6 (contre 84,0 pour o3), GAIA à 70,9 et SimpleQA à 95,0. Un tableau comparatif les visualise, avec des barres pour Tongyi DeepResearch dominant Gemini, Claude et d'autres sur HLE, BrowseComp, xbench, FRAMES, et plus encore. Les barres bleues indiquent les avances de Tongyi, les lignes de base grises montrent les lacunes des concurrents.
Ces résultats proviennent d'optimisations ciblées, telles que le routage sélectif d'experts pour les tâches de recherche. Ainsi, Tongyi DeepResearch non seulement rivalise mais mène dans les agentiques open source.
Comparaison de Tongyi DeepResearch aux leaders de l'industrie
Lorsque les développeurs évaluent les agents d'IA, les comparaisons révèlent la vraie valeur. Tongyi DeepResearch, à 30B-A3B, surpasse l'o3 d'OpenAI en HLE (32,9 contre 24,9) et xbench (75,0 contre 67,0), malgré l'échelle plus grande d'o3. Contre Gemini de Google, il revendique 35,2 sur BrowseComp-ZH, un avantage de 10 points.
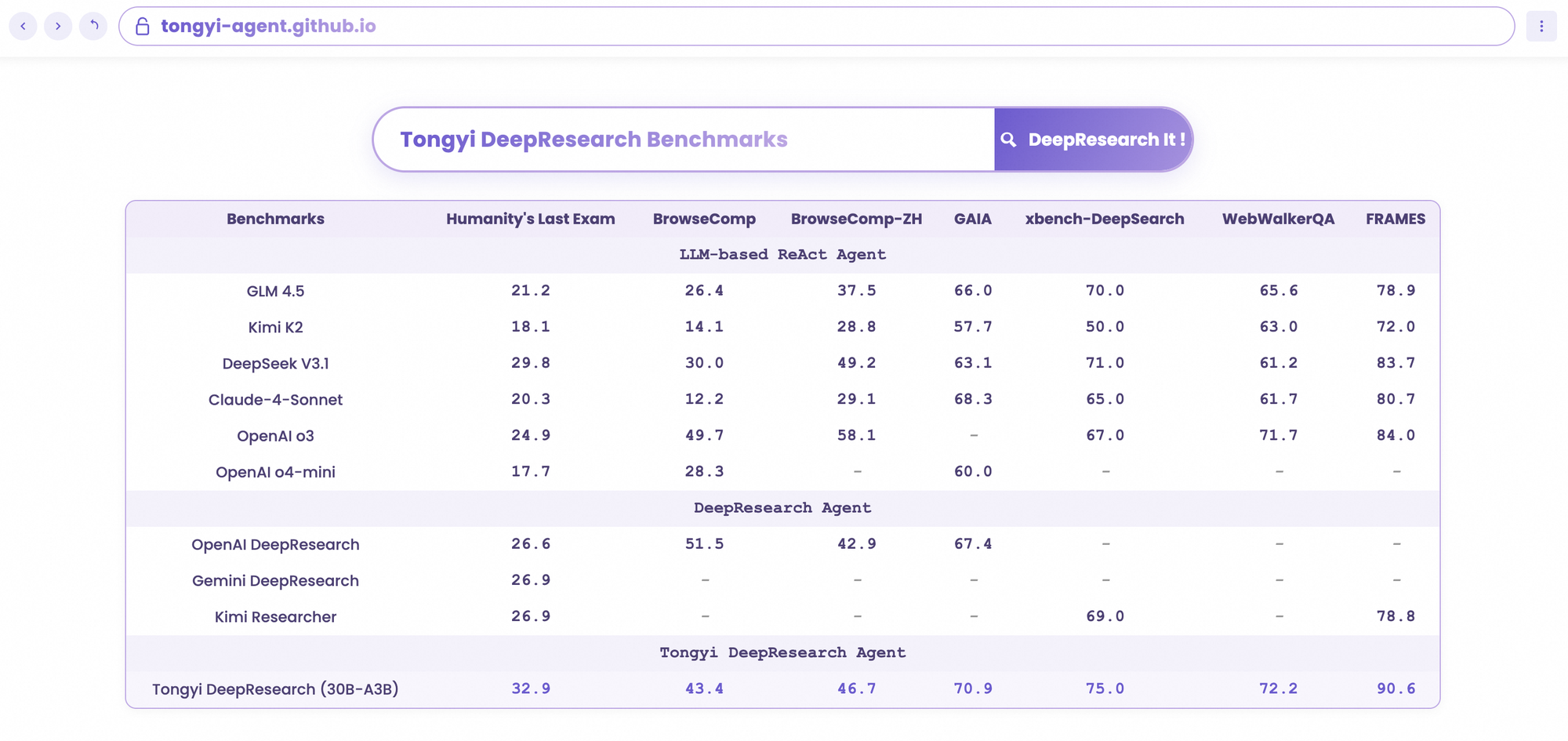
Les modèles propriétaires comme Claude 3.5 Sonnet sont à la traîne en matière d'utilisation d'outils ; le score de 90,6 de Tongyi sur FRAMES éclipse les 84,3 de Sonnet. Les pairs open source, tels que les variantes Llama, sont encore plus en retrait – par exemple, 21,1 sur HLE. La sparsité MoE de Tongyi permet cette parité, consommant moins de calcul d'inférence.
De plus, l'accessibilité fait pencher la balance : tandis qu'o3 exige des crédits API, Tongyi fonctionne localement via Hugging Face. Pour les flux de travail gourmands en API, associez-le à Apidog pour simuler des points de terminaison, simulant efficacement les appels d'outils.
En substance, Tongyi DeepResearch démocratise les performances d'élite, défiant les écosystèmes fermés.
Applications réelles : Tongyi DeepResearch en action
Tongyi DeepResearch transcende les benchmarks, générant un impact tangible. Dans Gaode Mate, l'application de navigation d'Alibaba, il planifie des voyages complexes – en interrogeant les vols, les hôtels et les événements en parallèle via le mode Heavy. Les utilisateurs reçoivent des itinéraires synthétisés avec des citations, réduisant le temps de planification de 70 %.
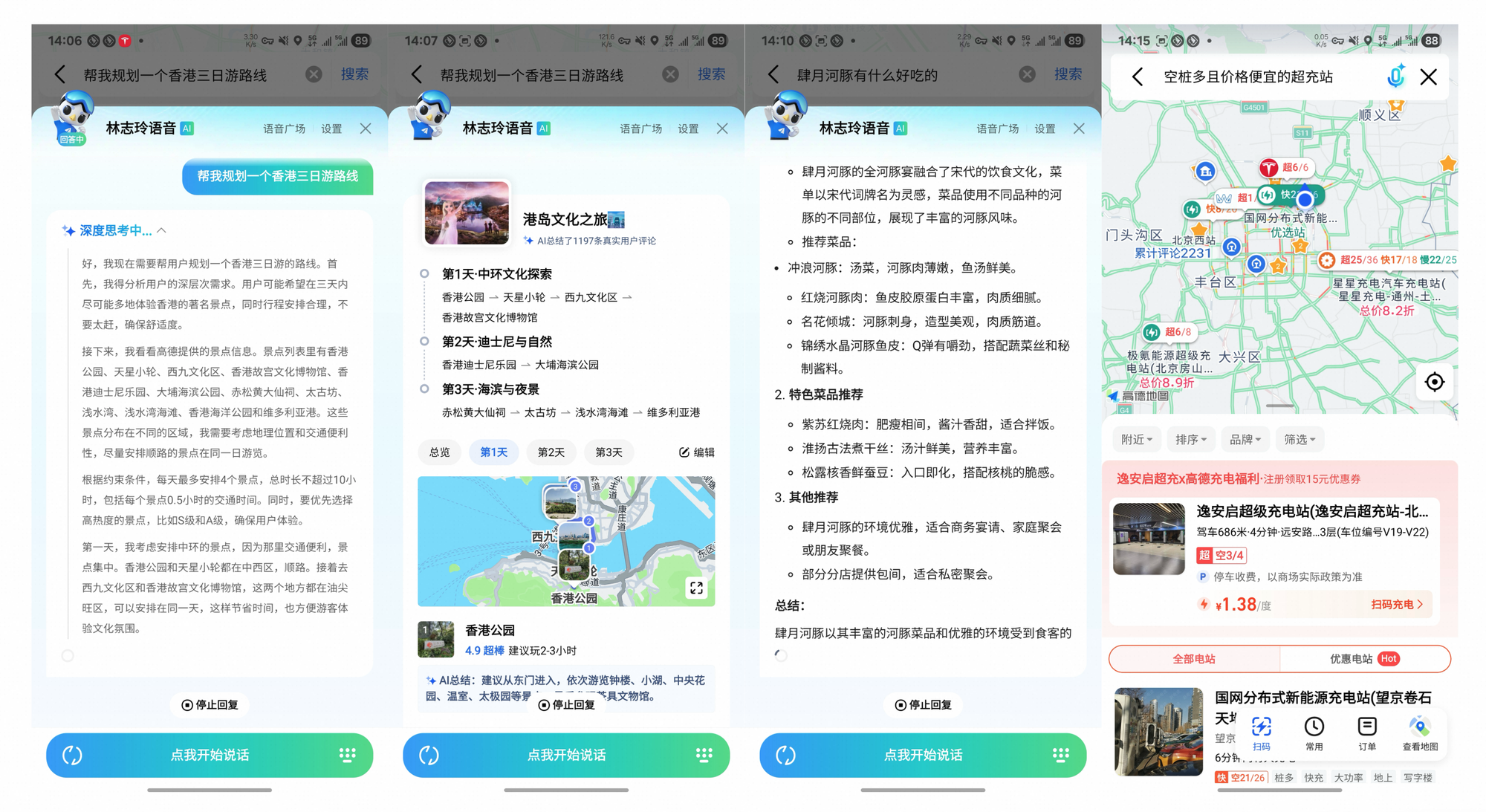
De même, Tongyi FaRui révolutionne la recherche juridique. L'agent analyse les statuts, recoupe les précédents et génère des mémoires avec des liens vérifiables. Les professionnels vérifient rapidement les résultats, minimisant les erreurs dans les domaines à enjeux élevés.
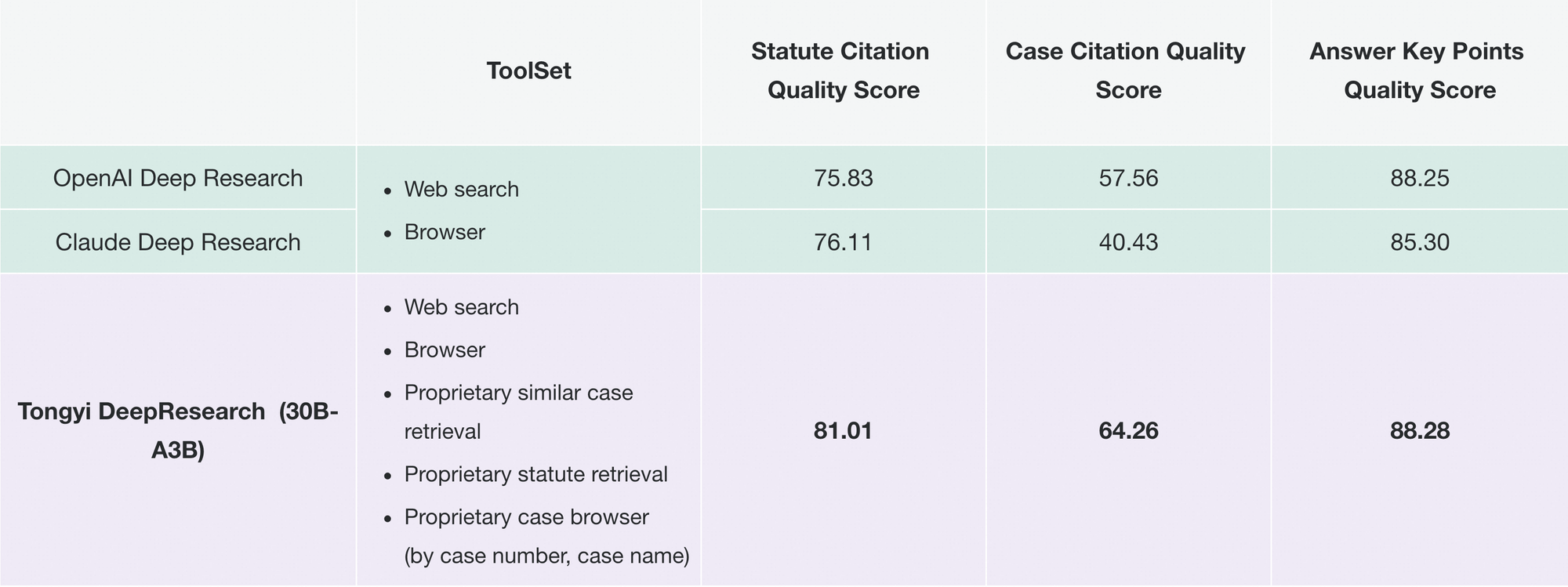
Au-delà de cela, les entreprises l'adaptent pour l'intelligence de marché : grattage de données concurrentielles, synthèse de tendances. La modularité du dépôt prend en charge de telles extensions – ajoutez des outils personnalisés via des configurations JSON.
À mesure que l'adoption augmente, Tongyi DeepResearch s'intègre dans des écosystèmes comme LangChain, amplifiant les essaims d'agents. Pour les développeurs API, Apidog complète cela en validant les intégrations avant le déploiement.
Ces cas démontrent l'évolutivité : des applications grand public aux outils B2B, le modèle offre une autonomie fiable.
Démarrer avec Tongyi DeepResearch : un guide pour les développeurs
Implémentez Tongyi DeepResearch sans effort avec son dépôt GitHub. Commencez par créer un environnement Conda : conda create -n deepresearch python=3.10. Activez et installez : pip install -r requirements.txt.
Préparez les données dans eval_data/ au format JSONL, avec les clés question et answer. Pour les fichiers, préfixez les noms aux questions et stockez-les dans file_corpus/. Modifiez run_react_infer.sh pour le chemin du modèle (par exemple, URL Hugging Face) et les clés API pour les outils.
Exécutez : bash run_react_infer.sh. Les sorties atterrissent dans les chemins spécifiés, prêtes pour l'analyse.
Pour le mode Heavy, configurez les paramètres IterResearch dans le code – définissez le nombre d'agents et les tours. Référencez via les scripts evaluation/, en comparant aux bases de référence.
Dépannez avec les journaux ; les problèmes courants comme les incompatibilités de tokenizer se résolvent via les vérifications de tenseurs BF16. Pour améliorer, téléchargez Apidog gratuitement pour la simulation d'API, testant les points de terminaison d'outils sans appels en direct.
Cette configuration vous permet de prototyper rapidement des agents.
Orientations futures : étendre Tongyi DeepResearch davantage
À l'avenir, Tongyi Lab vise l'expansion du contexte au-delà de 128K, permettant des horizons ultra-longs comme des analyses de la taille d'un livre. Ils prévoient une validation sur des bases MoE plus grandes, sondant les limites de l'évolutivité.
Les améliorations de RL incluent des rollouts partiels pour l'efficacité et des méthodes hors politique pour atténuer les changements. Les contributions de la communauté pourraient intégrer des outils de vision ou multilingues, élargissant la portée.
À mesure que l'open source évolue, Tongyi DeepResearch ancrera les avancées collaboratives, favorisant les recherches en AGI.
Conclusion : Adoptez l'ère Tongyi DeepResearch
Tongyi DeepResearch transforme l'IA agentique, alliant efficacité, ouverture et prouesse. Ses benchmarks, son architecture et ses applications le positionnent comme un leader, dépassant des rivaux comme les offres d'OpenAI. Développeurs, exploitez cette puissance – téléchargez le modèle, expérimentez et intégrez-le avec Apidog pour des API fluides.
Dans un domaine qui court vers l'autonomie, Tongyi DeepResearch accélère le progrès. Commencez à construire dès aujourd'hui ; les aperçus vous attendent.
bouton