
Dans le paysage en constante évolution du développement web, GraphQL est apparu comme une alternative puissante aux API REST traditionnelles, offrant une approche plus flexible et efficace pour la récupération de données. Si vous êtes désireux d'explorer cette technologie créative et de l'intégrer de manière transparente avec Spring, vous êtes au bon endroit.
Bienvenue dans notre tutoriel complet sur GraphQL, où nous allons entreprendre un voyage pour démystifier les concepts de GraphQL et vous guider tout au long du processus de prise en main de Spring pour GraphQL.
Qu'est-ce que Spring GraphQL et ses principales fonctionnalités
Spring GraphQL est une extension du populaire Spring Framework qui permet aux développeurs de créer des API basées sur GraphQL de manière transparente. Il combine la puissance de la facilité de développement de Spring Boot avec la flexibilité et l'efficacité de GraphQL, ce qui en fait un choix idéal pour le développement d'API modernes.
Les principales fonctionnalités de Spring GraphQL incluent :
- Développement axé sur le schéma : Avec Spring GraphQL, les développeurs peuvent commencer par définir le schéma de l'API à l'aide du GraphQL Schema Definition Language (SDL). Cette approche axée sur le schéma garantit que la conception de l'API est claire et bien définie dès le départ, ce qui favorise un processus de développement plus organisé et structuré.
- Récupération de données avec des résolveurs : Spring GraphQL simplifie la récupération de données en fournissant des résolveurs. Les résolveurs sont responsables de la récupération des données requises pour chaque champ d'une requête GraphQL. Les développeurs peuvent implémenter des résolveurs pour récupérer des données à partir de diverses sources telles que des bases de données, des API externes ou tout autre référentiel de données, ce qui permet une plus grande flexibilité et réutilisabilité.
- Intégration avec l'écosystème Spring : En tant que membre de la famille Spring, Spring GraphQL s'intègre de manière transparente avec d'autres composants Spring, tels que Spring Data JPA pour les interactions avec la base de données et Spring Security pour l'authentification et l'autorisation. Cette intégration étroite garantit une expérience de développement fluide et cohérente.
- Mises à jour en temps réel avec les abonnements : Spring GraphQL prend en charge les mises à jour de données en temps réel via les abonnements GraphQL. Les abonnements permettent aux clients de s'abonner à des événements spécifiques et de recevoir des mises à jour de données en temps réel lorsque ces événements se produisent. Cette fonctionnalité est particulièrement utile pour la création d'applications en temps réel, telles que des systèmes de chat ou des flux de données en direct.
Comment configurer votre environnement ?
Avant de commencer votre voyage avec GraphQL et Spring, assurez-vous que votre configuration est prête. Voici comment vous pouvez préparer votre environnement pour créer un projet Spring Boot avec GraphQL :
Prérequis :
- JDK 17 : Installez JDK 17 sur votre système. Vous pouvez le télécharger depuis Oracle ou OpenJDK.
- Compréhension de base de Spring Boot : Connaître les bases de Spring Boot. Cela vous aidera lorsque vous mélangerez GraphQL.
Création d'un projet Spring Boot :
Spring Initializr : Accédez à start.spring.io, votre point de départ pour les projets Spring Boot.
Tout d'abord, fournissez les détails de configuration du projet, tels que la dénomination de votre projet, la spécification d'un nom de groupe au format de domaine inversé (par exemple, com.example) et la désignation d'un nom de package pour le code Java de votre application. Vous pouvez également inclure des métadonnées telles qu'une description et une version si nécessaire.
Deuxièmement, ajoutez les dépendances nécessaires. Dans la section Dépendances, sélectionnez "Spring Web" pour activer la prise en charge de la création d'applications web avec Spring. De même, cochez "Spring GraphQL" pour activer les fonctionnalités liées à GraphQL. Une fois que vous avez configuré votre projet et choisi les dépendances, cliquez sur le bouton "Générer" pour continuer.
Importation de votre projet dans votre IDE :
Tout d'abord, extrayez le contenu du fichier ZIP pour accéder à son contenu. Deuxièmement, ouvrez votre environnement de développement intégré (IDE), tel qu'IntelliJ IDEA. Ensuite, importez le projet que vous avez précédemment extrait.
C'est tout ! Votre environnement est configuré, vous avez créé un projet Spring Boot et vous avez GraphQL à bord. Votre IDE est votre terrain de jeu pour les aventures de codage.
Comment configurer la couche de données ?
Dans cette section, nous allons créer un exemple simple, tel qu'un café, pour démontrer comment GraphQL peut améliorer la récupération et la gestion des données.
Introduction à l'exemple :
Imaginez que vous développez une API pour un café afin de gérer son menu et ses commandes. Pour illustrer cela, nous allons définir des modèles de données de base pour les articles de café et les clients, et configurer un service pour gérer ces données.
Définition des modèles de données de base :
Commençons par créer deux modèles de données simples : Coffee et Size. Ces modèles seront implémentés en tant que classes Java, chacune avec des attributs représentant les informations pertinentes.
Vous devrez créer deux classes dans deux fichiers différents et dans chaque classe, vous devrez ajouter des constructeurs, des getters et des setters pour les attributs.
public class Coffee {
private int id;
private String name;
private Size size;
// Constructors, getters, setters
}
public class Size {
private int id;
private String name;
// Constructors, getters, setters
}
Après avoir créé et ajouté ces classes, vous devez vous assurer qu'elles se trouvent dans le package approprié de votre projet Spring Boot. La structure du package doit refléter le nom du package que vous avez fourni lors de la génération du projet dans Spring Initializr.
Voici comment vous pouvez ajouter des setters, des getters et des constructeurs pour la classe Coffee.java.
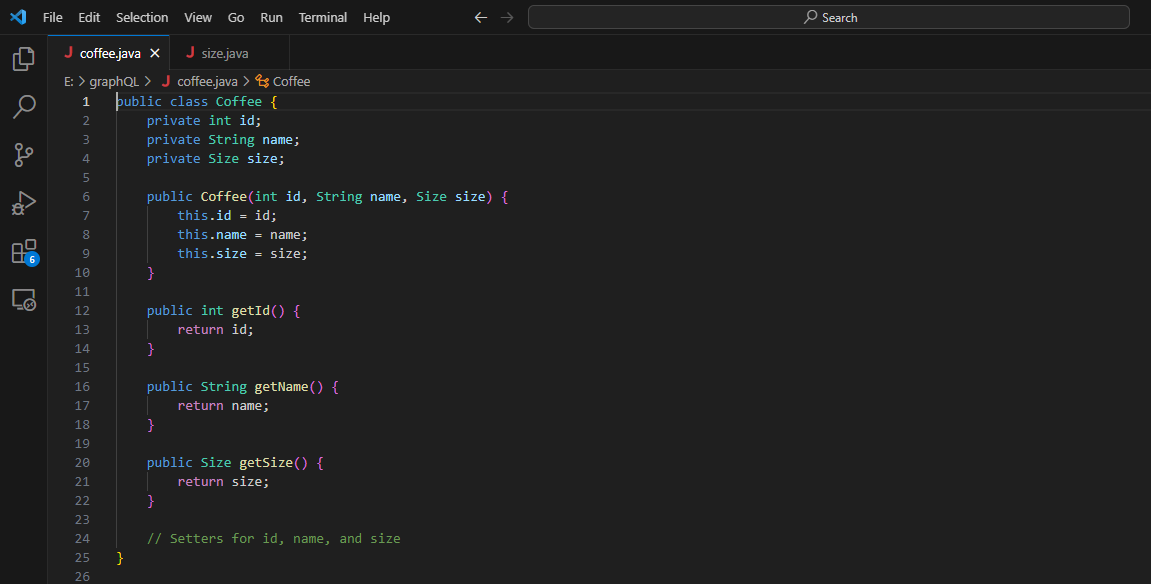
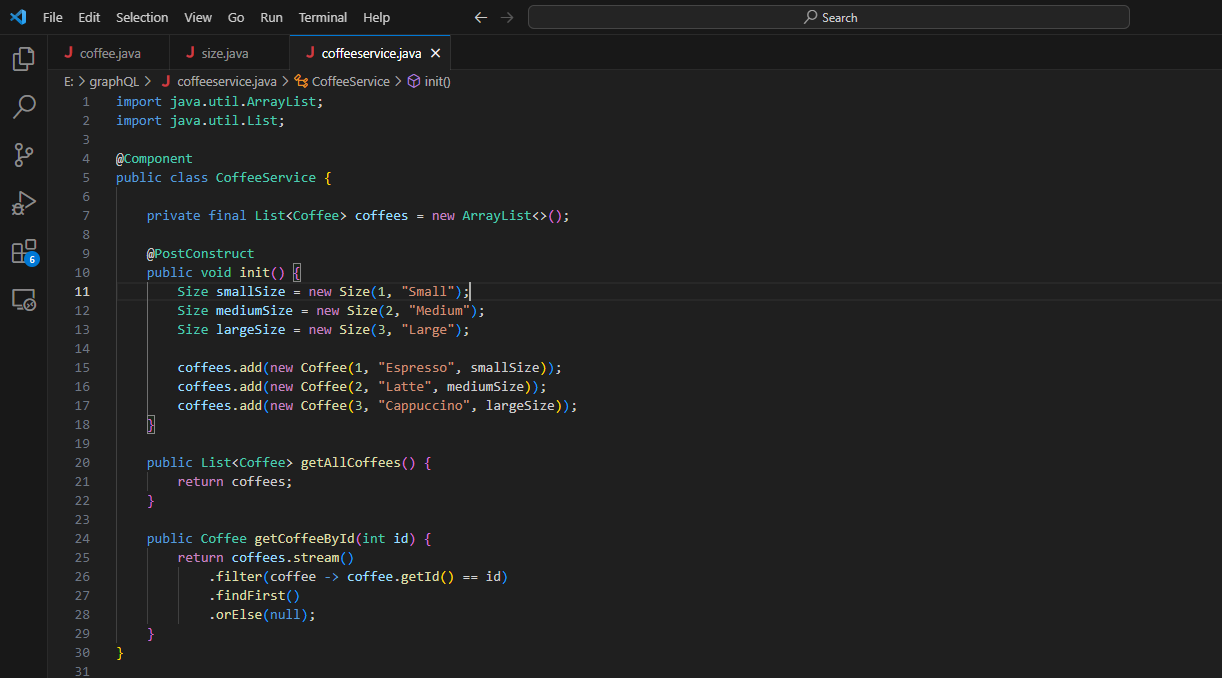
Configuration de la gestion des données :
Nous allons créer une simple classe CoffeeService pour servir de référentiel de données en mémoire et gérer les données de café. Pour démontrer, nous allons remplir ce référentiel avec quelques exemples d'articles de café.
import java.util.ArrayList;
import java.util.List;
@Component
public class CoffeeService {
private final List<Coffee> coffees = new ArrayList<>();
@PostConstruct
public void init() {
Size smallSize = new Size(1, "Small");
Size mediumSize = new Size(2, "Medium");
Size largeSize = new Size(3, "Large");
coffees.add(new Coffee(1, "Espresso", smallSize));
coffees.add(new Coffee(2, "Latte", mediumSize));
coffees.add(new Coffee(3, "Cappuccino", largeSize));
}
public List<Coffee> getAllCoffees() {
return coffees;
}
public Coffee getCoffeeById(int id) {
return coffees.stream()
.filter(coffee -> coffee.getId() == id)
.findFirst()
.orElse(null);
}
}
La classe CoffeeService gère les données relatives au café, agissant comme un système de stockage et de récupération. Elle initialise des exemples de données de café lors de la création, offrant des méthodes pour récupérer tous les cafés ou un café spécifique par ID. Cette abstraction simplifie l'accès et la manipulation des données, préparant les données à l'interaction dans le schéma GraphQL.
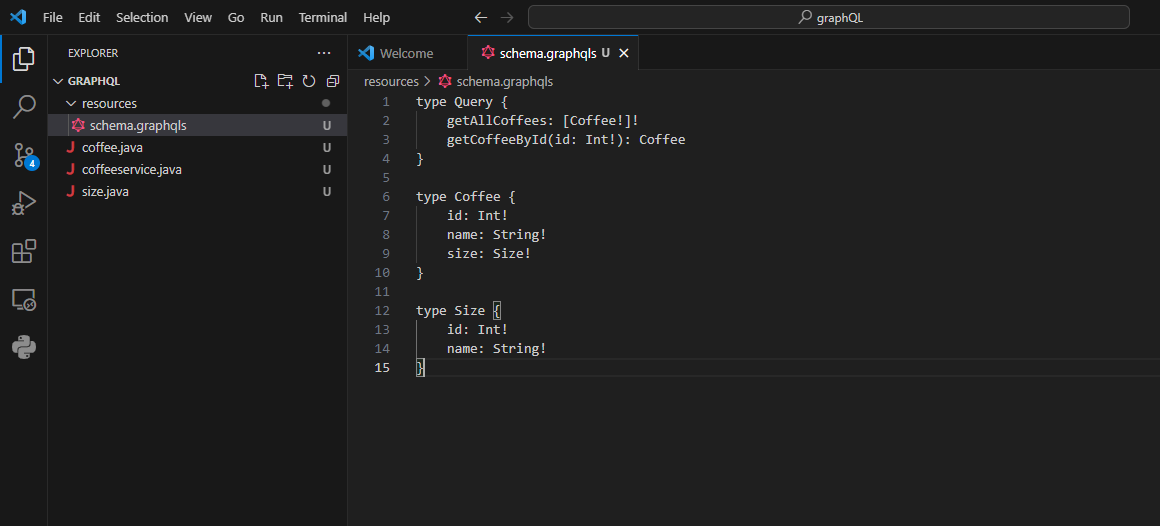
Comment créer le schéma GraphQL ?
Créez un fichier nommé schema.graphqls dans le dossier src/main/resources et définissez le schéma GraphQL à l'aide du langage de définition de schéma (SDL).
type Query {
getAllCoffees: [Coffee!]!
getCoffeeById(id: Int!): Coffee
}
type Coffee {
id: Int!
name: String!
size: Size!
}
type Size {
id: Int!
name: String!
}
Voici comment vous pouvez le faire.
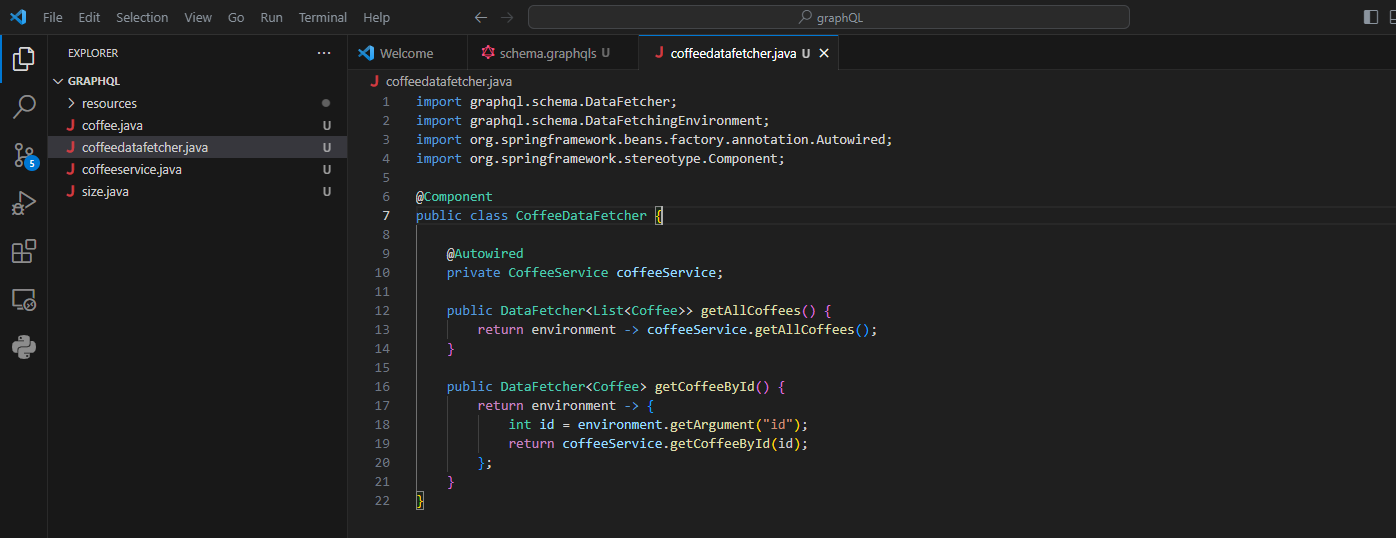
Créer des récupérateurs de données :
Le code définit une classe nommée CoffeeDataFetcher chargée de récupérer les données pour les requêtes GraphQL. Elle est annotée avec @Component pour être gérée par Spring. Le récupérateur getAllCoffees() récupère une liste d'articles de café à l'aide de la méthode coffeeService.getAllCoffees(). Le récupérateur getCoffeeById() extrait un ID des arguments de la requête et l'utilise pour récupérer un article de café spécifique du CoffeeService.
import graphql.schema.DataFetcher;
import graphql.schema.DataFetchingEnvironment;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.stereotype.Component;
@Component
public class CoffeeDataFetcher {
@Autowired
private CoffeeService coffeeService;
public DataFetcher<List<Coffee>> getAllCoffees() {
return environment -> coffeeService.getAllCoffees();
}
public DataFetcher<Coffee> getCoffeeById() {
return environment -> {
int id = environment.getArgument("id");
return coffeeService.getCoffeeById(id);
};
}
}
Voici comment vous pouvez le faire.
Créer un contrôleur GraphQL :
Dans Spring, les contrôleurs GraphQL fournissent des points de terminaison pour interagir avec votre schéma GraphQL. Ces contrôleurs gèrent les requêtes entrantes et renvoient les données correspondantes.
import graphql.GraphQL;
import org.springframework.beans.factory.annotation.Autowired;
import org.springframework.web.bind.annotation.PostMapping;
import org.springframework.web.bind.annotation.RequestBody;
import org.springframework.web.bind.annotation.RestController;
@RestController
public class GraphQLController {
@Autowired
private GraphQL graphQL;
@PostMapping("/graphql")
public Map<String, Object> executeQuery(@RequestBody String query) {
ExecutionResult executionResult = graphQL.execute(query);
return executionResult.toSpecification();
}
}
Ce contrôleur gérera les requêtes GraphQL entrantes et interagira avec votre schéma GraphQL. Il fournit un point de terminaison RESTful à /graphql qui accepte les requêtes POST avec la requête GraphQL dans le corps de la requête. Le contrôleur utilise ensuite l'instance GraphQL pour exécuter la requête et renvoie le résultat de l'exécution sous forme de carte.
Spring GraphQL est un framework puissant qui permet aux développeurs de créer des API efficaces à l'aide du langage de requête GraphQL. Contrairement aux API REST traditionnelles, où plusieurs points de terminaison dictent la récupération des données, GraphQL permet aux clients de spécifier exactement les données dont ils ont besoin dans une seule requête, réduisant ainsi la sur-récupération ou la sous-récupération des données. Spring GraphQL s'appuie sur les points forts de l'écosystème Spring, combinant la simplicité de Spring Boot avec la flexibilité de GraphQL.
Le processus implique de définir vos modèles de données, de créer une couche de service pour gérer les données et d'établir un schéma avec des types et des requêtes. L'approche axée sur le schéma de Spring GraphQL garantit une conception claire et un processus de développement structuré. La récupération des données est simplifiée grâce aux résolveurs, et les mises à jour en temps réel sont facilitées par les abonnements.
Outils de test GraphQL :
GraphQL est devenu un moyen populaire de créer des API, et les tester est crucial pour s'assurer qu'elles fonctionnent correctement. Les outils de test aident les développeurs à vérifier si leurs API GraphQL fonctionnent comme prévu.
L'un de ces outils est Apidog, qui offre une gamme de fonctionnalités pour faciliter les tests d'API. Examinons ce que Apidog peut faire et mentionnons d'autres outils de test utiles pour GraphQL.
Apidog :
Apidog est une boîte à outils polyvalente qui couvre l'ensemble du processus de création d'API. C'est comme un couteau suisse pour les API, aidant à la conception, aux tests et plus encore. Voici ce qu'Apidog propose :
Ce qu'Apidog offre pour les tests GraphQL :
Apidog fonctionne également bien pour tester les API GraphQL. Il possède des fonctionnalités telles que :
- Prise en charge de GraphQL : Apidog peut tester et déboguer les API GraphQL.
- Automatisation : Il peut automatiser les tâches et synchroniser vos définitions d'API.
- Intégration de bases de données : Apidog peut se connecter à des bases de données pour de meilleurs tests.
Conclusion
Alors que les API continuent d'évoluer, le mélange de GraphQL, Spring GraphQL et d'outils comme Apidog remodèle la façon dont les API sont créées. Cette combinaison donne aux développeurs plus de contrôle et d'efficacité, ce qui se traduit par des API solides, adaptables et performantes.


