
```html
Le paysage des grands modèles de langage (LLM) évolue à une vitesse fulgurante. Les modèles deviennent plus puissants, plus performants et, surtout, plus accessibles. L'équipe Qwen a récemment dévoilé Qwen3, sa dernière génération de LLM, affichant des performances impressionnantes sur divers benchmarks, notamment en codage, en mathématiques et en raisonnement général. Avec des modèles phares comme le Mixture-of-Experts (MoE) Qwen3-235B-A22B rivalisant avec des géants établis et même des modèles denses plus petits comme Qwen3-4B en concurrence avec les modèles de paramètres de 72B de la génération précédente, Qwen3 représente un bond en avant significatif.
Un aspect clé de cette sortie est l'ouverture de plusieurs modèles, dont deux variantes MoE (Qwen3-235B-A22B et Qwen3-30B-A3B) et six modèles denses allant de 0,6B à 32B paramètres. Cette ouverture invite les développeurs, les chercheurs et les passionnés à explorer, utiliser et s'appuyer sur ces outils puissants. Bien que les API basées sur le cloud offrent une commodité, le désir d'exécuter ces modèles sophistiqués localement se développe, motivé par les besoins de confidentialité, de contrôle des coûts, de personnalisation et d'accessibilité hors ligne.
Heureusement, l'écosystème d'outils pour l'exécution locale de LLM a considérablement mûri. Deux plateformes exceptionnelles simplifiant ce processus sont Ollama et vLLM. Ollama offre un moyen incroyablement convivial de démarrer avec divers modèles, tandis que vLLM propose une solution de service haute performance optimisée pour le débit et l'efficacité, en particulier pour les modèles plus volumineux. Cet article vous guidera à travers la compréhension de Qwen3 et la configuration de ces modèles puissants sur votre machine locale en utilisant à la fois Ollama et vLLM.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !
Qu'est-ce que Qwen 3 et les benchmarks
Qwen3 représente la troisième génération de grands modèles de langage (LLM) développés par l'équipe Qwen, sortie en avril 2025. Cette itération marque une avancée substantielle par rapport aux versions précédentes, en se concentrant sur des capacités de raisonnement améliorées, l'efficacité grâce à des innovations architecturales comme Mixture-of-Experts (MoE), une prise en charge multilingue plus large et des performances améliorées sur un large éventail de benchmarks. La sortie comprenait l'ouverture de plusieurs modèles sous la licence Apache 2.0, favorisant l'accessibilité pour la recherche et le développement.
Architecture et variantes du modèle Qwen 3, expliquées
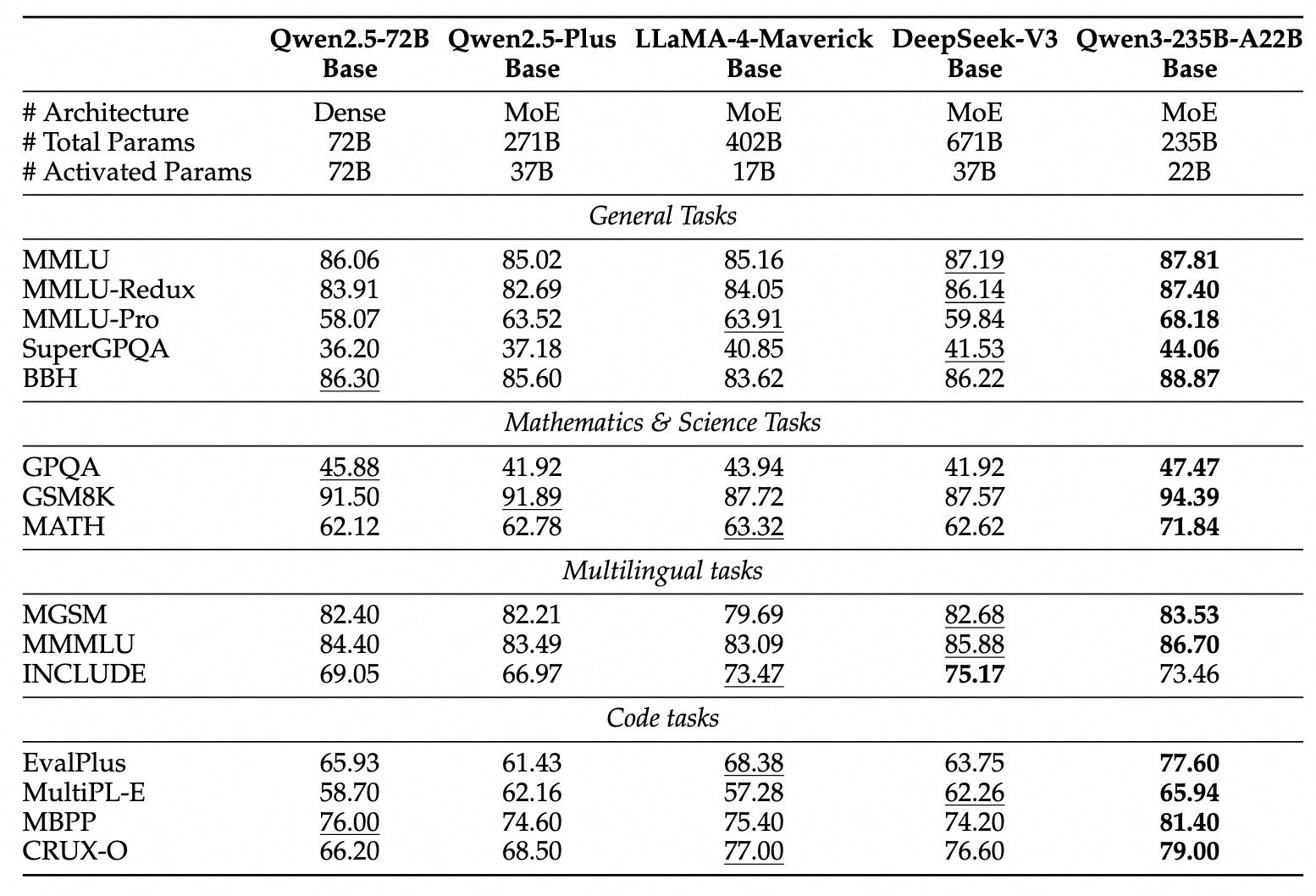
La famille Qwen3 englobe à la fois des modèles denses traditionnels et des architectures MoE clairsemées, répondant à divers budgets informatiques et exigences de performance.
Modèles denses : Ces modèles utilisent tous leurs paramètres pendant l'inférence. Les principaux détails architecturaux incluent :
| Model | Couches | Têtes d'attention (Requête / Clé-Valeur) | Lier les intégrations de mots | Longueur maximale du contexte |
|---|---|---|---|---|
| Qwen3-0.6B | 28 | 16 / 8 | Oui | 32 768 jetons (32K) |
| Qwen3-1.7B | 28 | 16 / 8 | Oui | 32 768 jetons (32K) |
| Qwen3-4B | 36 | 32 / 8 | Oui | 32 768 jetons (32K) |
| Qwen3-8B | 36 | 32 / 8 | Non | 131 072 jetons (128K) |
| Qwen3-14B | 40 | 40 / 8 | Non | 131 072 jetons (128K) |
| Qwen3-32B | 64 | 64 / 8 | Non | 131 072 jetons (128K) |
Remarque : L'attention groupée par requête (GQA) est utilisée dans tous les modèles, comme l'indique le nombre différent de têtes de requête et de clé-valeur.
Modèles Mixture-of-Experts (MoE) : Ces modèles tirent parti de la parcimonie en n'activant qu'un sous-ensemble de réseaux de neurones à propagation avant (FFN) « experts » pour chaque jeton pendant l'inférence. Cela permet d'avoir un grand nombre total de paramètres tout en maintenant les coûts de calcul plus proches de ceux des modèles denses plus petits.
| Model | Couches | Têtes d'attention (Requête / Clé-Valeur) | # Experts (Total / Activé) | Longueur maximale du contexte |
|---|---|---|---|---|
| Qwen3-30B-A3B | 48 | 32 / 4 | 128 / 8 | 131 072 jetons (128K) |
| Qwen3-235B-A22B | 94 | 64 / 4 | 128 / 8 | 131 072 jetons (128K) |
Remarque : Les deux modèles MoE utilisent 128 experts au total, mais n'en activent que 8 par jeton, ce qui réduit considérablement la charge de calcul par rapport à un modèle dense de taille équivalente.
Principales caractéristiques techniques de Qwen 3
Modes de pensée hybrides : Une caractéristique distinctive de Qwen3 est sa capacité à fonctionner dans deux modes distincts, contrôlables par l'utilisateur :
- Mode de réflexion (par défaut) : Le modèle effectue un raisonnement interne, étape par étape (style Chaîne de pensée) avant de générer la réponse finale. Ce processus de pensée latent est encapsulé, souvent marqué par des jetons spéciaux (par exemple, en affichant le contenu
<think>...</think>avant la réponse finale lors de l'utilisation de configurations de framework spécifiques). Ce mode améliore les performances sur les tâches complexes nécessitant une déduction logique, un raisonnement mathématique ou une planification. Il permet des améliorations de performances évolutives directement corrélées au budget de raisonnement informatique alloué. - Mode sans réflexion : Le modèle génère une réponse directe sans la phase de raisonnement interne explicite, optimisant la vitesse et réduisant le coût de calcul sur les requêtes plus simples.
Les utilisateurs peuvent basculer dynamiquement entre ces modes, potentiellement au tour par tour dans les conversations à plusieurs tours en utilisant des balises comme/thinket/no_thinkdans leurs invites (si le framework le permet), ce qui permet un contrôle précis du compromis entre la latence/le coût et la profondeur du raisonnement.
Prise en charge multilingue étendue : Les modèles Qwen3 sont pré-entraînés sur un corpus diversifié permettant la prise en charge de 119 langues et dialectes dans les principales familles de langues (indo-européennes, sino-tibétaines, afro-asiatiques, austronésiennes, dravidiennes, turques, etc.), ce qui les rend adaptés à un large éventail d'applications mondiales.
Méthodologie de formation avancée :
- Pré-entraînement : Les modèles ont été pré-entraînés sur un ensemble de données à grande échelle comprenant des milliers de milliards de jetons. La phase finale de pré-entraînement impliquait l'utilisation de données de contexte long de haute qualité pour étendre la fenêtre de contexte effective jusqu'à 32 000 jetons au départ, avec d'autres extensions à 128 000 pour les modèles plus volumineux.
- Post-entraînement : Un pipeline sophistiqué en quatre étapes a été utilisé pour imprégner les modèles de capacités de suivi des instructions, de compétences de raisonnement et du mécanisme de pensée hybride :
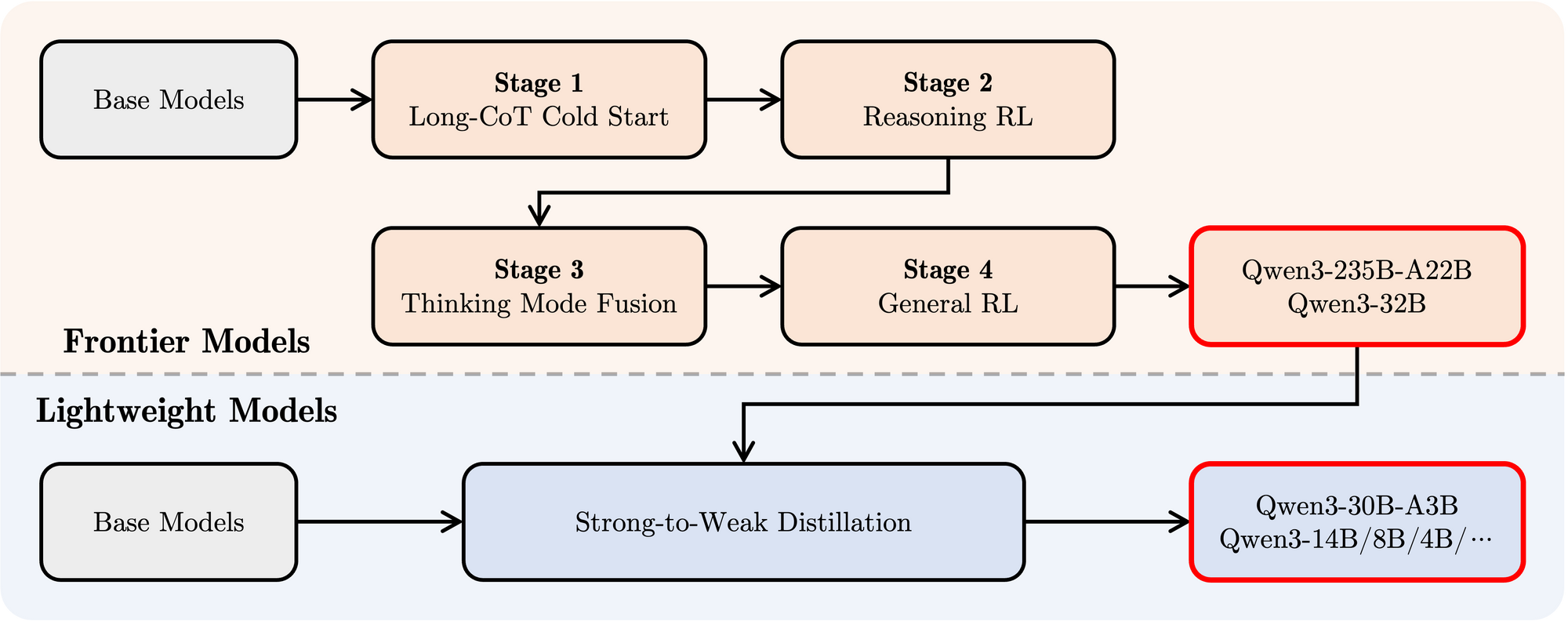
- Démarrage à froid Long CoT : Réglage fin supervisé (SFT) sur diverses données de chaîne de pensée (CoT) longues couvrant les mathématiques, le codage, le raisonnement logique et les STEM pour développer des capacités de raisonnement fondamentales.
- Apprentissage par renforcement basé sur le raisonnement (RL) : Augmentation des ressources informatiques pour le RL en utilisant des récompenses basées sur des règles pour améliorer l'exploration et l'exploitation spécifiquement pour les tâches de raisonnement.
- Fusion du mode de pensée : Intégration de capacités de non-réflexion en affinant le modèle amélioré de raisonnement sur un mélange de données CoT longues et de données d'instruction-tuning standard générées par le modèle de l'étape 2. Cela combine un raisonnement profond avec une génération de réponses rapides.
- RL général : Application du RL à de nombreuses tâches de domaine général (suivi des instructions, respect du format, capacités de l'agent) pour affiner le comportement global et atténuer les sorties indésirables.
Performances de référence de Qwen 3
Qwen3 démontre des performances très compétitives par rapport aux autres modèles contemporains de premier plan :
MoE phare : Le modèle Qwen3-235B-A22B obtient des résultats comparables à ceux des modèles de premier plan tels que DeepSeek-R1, o1 et o3-mini de Google, Grok-3 et Gemini-2.5-Pro sur divers benchmarks évaluant le codage, les mathématiques et les capacités générales.
MoE plus petit : Le modèle Qwen3-30B-A3B surpasse de manière significative les modèles comme QwQ-32B, malgré l'activation d'une fraction seulement (3B contre 32B) des paramètres pendant l'inférence, ce qui met en évidence l'efficacité de l'architecture MoE.
Modèles denses : En raison des avancées architecturales et de l'entraînement, les modèles denses Qwen3 égalent ou dépassent généralement les performances des modèles denses Qwen2.5 plus volumineux. Par exemple :
Qwen3-1.7B≈Qwen2.5-3BQwen3-4B≈Qwen2.5-7B(et rivalise avecQwen2.5-72B-Instructdans certains aspects)Qwen3-8B≈Qwen2.5-14BQwen3-14B≈Qwen2.5-32BQwen3-32B≈Qwen2.5-72B
Notamment, les modèles de base denses Qwen3 montrent des améliorations de performances particulièrement fortes par rapport à leurs prédécesseurs dans les tâches STEM, de codage et de raisonnement.
Efficacité MoE : Les modèles de base MoE Qwen3 atteignent des performances comparables à celles des modèles denses Qwen2.5 de taille significativement plus grande tout en activant seulement ~10 % des paramètres, ce qui entraîne des économies substantielles en termes de calcul d'entraînement et d'inférence.
Ces résultats de référence soulignent la position de Qwen3 en tant que famille de modèles de pointe offrant à la fois des performances élevées et, en particulier avec les variantes MoE, une efficacité de calcul améliorée. Les modèles sont disponibles via des plateformes standard comme Hugging Face, ModelScope et Kaggle, et sont pris en charge par des frameworks de déploiement populaires tels que Ollama, vLLM, SGLang, LMStudio et llama.cpp, facilitant leur intégration dans divers flux de travail et applications, y compris l'exécution locale.
Comment exécuter Qwen 3 localement avec Ollama
Ollama a gagné une immense popularité pour sa simplicité de téléchargement, de gestion et d'exécution locale des LLM. Il abstrait une grande partie de la complexité, en fournissant une interface de ligne de commande et un serveur API.
1. Installation :
L'installation d'Ollama est généralement simple. Visitez le site Web officiel d'Ollama (ollama.com) et suivez les instructions de téléchargement pour votre système d'exploitation (macOS, Linux, Windows).
2. Extraction des modèles Qwen3 :
Ollama maintient une bibliothèque de modèles facilement disponibles. Pour exécuter un modèle Qwen3 spécifique, vous utilisez la commande ollama run. Si le modèle n'est pas présent localement, Ollama le télécharge automatiquement. L'équipe Qwen a mis plusieurs variantes Qwen3 à disposition directement sur la bibliothèque Ollama.
Vous pouvez trouver les balises Qwen3 disponibles sur la page Qwen3 du site Web d'Ollama (par exemple, ollama.com/library/qwen3). Les balises courantes peuvent inclure :
qwen3:0.6bqwen3:1.7bqwen3:4bqwen3:8bqwen3:14bqwen3:32bqwen3:30b-a3b(Le modèle MoE plus petit)
Pour exécuter le modèle de paramètres 4B, par exemple, ouvrez simplement votre terminal et tapez :
ollama run qwen3:4b
Cette commande téléchargera le modèle (si nécessaire) et démarrera une session de chat interactive.
3. Interaction avec le modèle :
Une fois la commande ollama run active, vous pouvez taper vos invites directement dans le terminal. Ollama démarre également un serveur local (généralement à http://localhost:11434) qui expose une API compatible avec la norme OpenAI. Vous pouvez interagir avec cela par programmation à l'aide d'outils comme curl ou de diverses bibliothèques clientes en Python, JavaScript, etc.
4. Considérations matérielles :
L'exécution de LLM localement nécessite des ressources substantielles.
- RAM : Même les modèles plus petits (0,6B, 1,7B) nécessitent plusieurs gigaoctets de RAM. Les modèles plus volumineux (8B, 14B, 32B, 30B-A3B) en nécessitent beaucoup plus, souvent 16 Go, 32 Go, voire 64 Go+, selon le niveau de quantification utilisé par Ollama.
- VRAM (GPU) : Pour des performances acceptables, un GPU dédié avec une VRAM suffisante est fortement recommandé. Ollama utilise automatiquement les GPU compatibles (NVIDIA, Apple Silicon). La quantité de VRAM dicte le plus grand modèle que vous pouvez exécuter confortablement entièrement sur le GPU, ce qui accélère considérablement l'inférence.
- CPU : Bien qu'Ollama puisse exécuter des modèles sur le CPU, les performances seront considérablement plus lentes que sur un GPU.
Ollama est excellent pour démarrer rapidement, le développement local, l'expérimentation et les applications de chat à utilisateur unique, en particulier sur le matériel grand public (dans les limites).
Comment exécuter Ollama localement avec vLLM
vLLM est une bibliothèque de service LLM à haut débit qui utilise des optimisations comme PagedAttention pour améliorer considérablement la vitesse d'inférence et l'efficacité de la mémoire, ce qui la rend idéale pour les applications exigeantes et le service de modèles plus volumineux. L'équipe vLLM fournit un excellent support pour les nouvelles architectures, y compris le support Day 0 pour Qwen3 dès sa sortie.
1. Installation :
Installez vLLM à l'aide de pip. Il est généralement recommandé d'utiliser un environnement virtuel :
pip install -U vllm
Assurez-vous d'avoir les prérequis nécessaires, généralement un GPU NVIDIA compatible avec le kit d'outils CUDA approprié installé. Reportez-vous à la documentation vLLM pour connaître les exigences spécifiques.
2. Servir les modèles Qwen3 :
vLLM utilise la commande vllm serve pour charger un modèle et lancer un serveur API compatible OpenAI. L'équipe Qwen et la documentation vLLM fournissent des conseils sur l'exécution de Qwen3.
Sur la base des informations fournies et de l'utilisation courante de vLLM, voici comment vous pourriez servir le grand modèle MoE Qwen3-235B en utilisant la quantification FP8 (pour une utilisation réduite de la mémoire) et le parallélisme tensoriel sur 4 GPU :
vllm serve Qwen/Qwen3-235B-A22B-FP8 \
--enable-reasoning \
--reasoning-parser deepseek_r1 \
--tensor-parallel-size 4
Décomposons cette commande :
Qwen/Qwen3-235B-A22B-FP8: Il s'agit de l'identifiant du modèle, pointant probablement vers un emplacement de référentiel Hugging Face.FP8indique l'utilisation de la quantification en virgule flottante 8 bits, réduisant l'empreinte mémoire du modèle par rapport à FP16 ou BF16, ce qui est crucial pour un modèle aussi volumineux.--enable-reasoning: Cet indicateur est essentiel pour activer les capacités de pensée hybride de Qwen3 au sein de vLLM.--reasoning-parser deepseek_r1: La sortie de pensée de Qwen3 a un format spécifique. vLLM nécessite un analyseur pour gérer cela. L'article de blog indique que pour vLLM, l'analyseurdeepseek_r1doit être utilisé (tandis que SGLang utilise un analyseurqwen3). Cela garantit que vLLM peut interpréter correctement et potentiellement séparer les étapes de réflexion de la réponse finale.--tensor-parallel-size 4: Cela indique à vLLM de distribuer les poids et le calcul du modèle sur 4 GPU. Le parallélisme tensoriel est essentiel pour exécuter des modèles trop volumineux pour tenir sur un seul GPU. Vous ajusteriez ce nombre en fonction de vos GPU disponibles.
Vous pouvez adapter cette commande à d'autres modèles Qwen3 (par exemple, Qwen/Qwen3-30B-A3B ou Qwen/Qwen3-32B) et ajuster les paramètres comme tensor-parallel-size en fonction de votre matériel.
3. Interaction avec le serveur vLLM :
Une fois que vllm serve est en cours d'exécution, il héberge un serveur API (par défaut http://localhost:8000) qui reflète la spécification de l'API OpenAI. Vous pouvez interagir avec lui à l'aide d'outils standard :
- curl :
curl http://localhost:8000/v1/completions \
-H "Content-Type: application/json" \
-d '{
"model": "Qwen/Qwen3-235B-A22B-FP8", # Utilisez le nom du modèle que vous avez servi
"prompt": "Expliquez le concept de Mixture-of-Experts dans les LLM.",
"max_tokens": 150,
"temperature": 0.7
}'
- Client Python OpenAI :
from openai import OpenAI
# Pointer vers le serveur vLLM local
client = OpenAI(base_url="http://localhost:8000/v1", api_key="EMPTY")
completion = client.completions.create(
model="Qwen/Qwen3-235B-A22B-FP8", # Utilisez le nom du modèle que vous avez servi
prompt="Écrivez une courte histoire sur un robot découvrant la musique.",
max_tokens=200
)
print(completion.choices[0].text)
4. Performances et cas d'utilisation :
vLLM brille dans les scénarios nécessitant un débit élevé (nombre de requêtes par seconde) et une faible latence. Ses optimisations le rendent adapté à :
- Création d'applications alimentées par des LLM locaux.
- Servir des modèles à plusieurs utilisateurs simultanément.
- Déploiement de modèles volumineux qui nécessitent des configurations multi-GPU.
- Environnements de production où les performances sont critiques.
Tester l'API locale Ollama avec Apidog
Apidog est un outil de test d'API qui s'associe bien au mode API d'Ollama. Il vous permet d'envoyer des requêtes, d'afficher les réponses et de déboguer efficacement votre configuration Qwen 3.
Voici comment utiliser Apidog avec Ollama :
- Créez une nouvelle requête API :
- Point de terminaison :
http://localhost:11434/api/generate - Envoyez la requête et surveillez la réponse dans la chronologie en temps réel d'Apidog.
- Utilisez l'extraction JSONPath d'Apidog pour analyser automatiquement les réponses, une fonctionnalité qui surpasse les outils comme Postman.


Réponses en streaming :
- Pour les applications en temps réel, activez le streaming :
- La fonctionnalité de fusion automatique d'Apidog consolide les messages diffusés en continu, simplifiant le débogage.
curl http://localhost:11434/api/generate -d '{"model": "gemma3:4b-it-qat", "prompt": "Écrivez un poème sur l'IA.", "stream": true}'

Ce processus garantit que votre modèle fonctionne comme prévu, faisant d'Apidog un ajout précieux.
Conclusion
La sortie de la famille de modèles Qwen3 puissante et diversifiée, combinée à des outils d'exécution locaux matures comme Ollama et vLLM, marque une période passionnante pour les praticiens de l'IA. Que vous donniez la priorité à la simplicité plug-and-play d'Ollama pour un usage personnel et l'expérimentation ou aux capacités de service haute performance de vLLM pour la création d'applications robustes, l'exécution locale de LLM de pointe est plus réalisable que jamais.
En intégrant des modèles comme Qwen3-30B-A3B ou même les variantes denses plus volumineuses sur votre propre matériel, vous gagnez un contrôle, une confidentialité et une rentabilité sans précédent. Vous pouvez tirer parti de leurs fonctionnalités avancées, comme la pensée hybride et la prise en charge multilingue étendue, pour des projets innovants. À mesure que les écosystèmes matériels et logiciels continuent de s'améliorer, la puissance des grands modèles de langage deviendra de plus en plus démocratisée, passant des serveurs cloud distants directement sur nos machines locales. Expérimentez avec Qwen3 en utilisant Ollama et vLLM pour découvrir le fer de lance de cette révolution de l'IA locale.
Vous voulez une plateforme intégrée, tout-en-un, pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos demandes et remplace Postman à un prix beaucoup plus abordable !
```


