
L'exécution de grands modèles linguistiques comme Mistral 3 sur votre machine locale offre aux développeurs un contrôle inégalé sur la confidentialité des données, la vitesse d'inférence et la personnalisation. À mesure que les charges de travail d'IA deviennent plus exigeantes, l'exécution locale devient essentielle pour le prototypage, les tests et le déploiement d'applications hors ligne. De plus, des outils comme Ollama simplifient ce processus, vous permettant de tirer parti des capacités de Mistral 3 directement depuis votre ordinateur de bureau ou votre serveur.
Ce guide vous fournit des instructions étape par étape pour installer et exécuter les variantes de Mistral 3 localement. Nous nous concentrons sur la série open source Ministral 3, qui excelle dans les déploiements en périphérie. À la fin, vous optimiserez les performances pour des tâches réelles, garantissant des réponses à faible latence et une efficacité des ressources.
Comprendre Mistral 3 : La puissance open source de l'IA
Mistral AI continue de repousser les limites avec sa dernière version : Mistral 3. Les développeurs et les chercheurs louent cette famille de modèles pour son équilibre entre précision, efficacité et accessibilité. Contrairement aux géants propriétaires, Mistral 3 adopte les principes open source, étant publié sous la licence Apache 2.0. Cette démarche permet à la communauté de modifier, distribuer et innover sans restrictions.
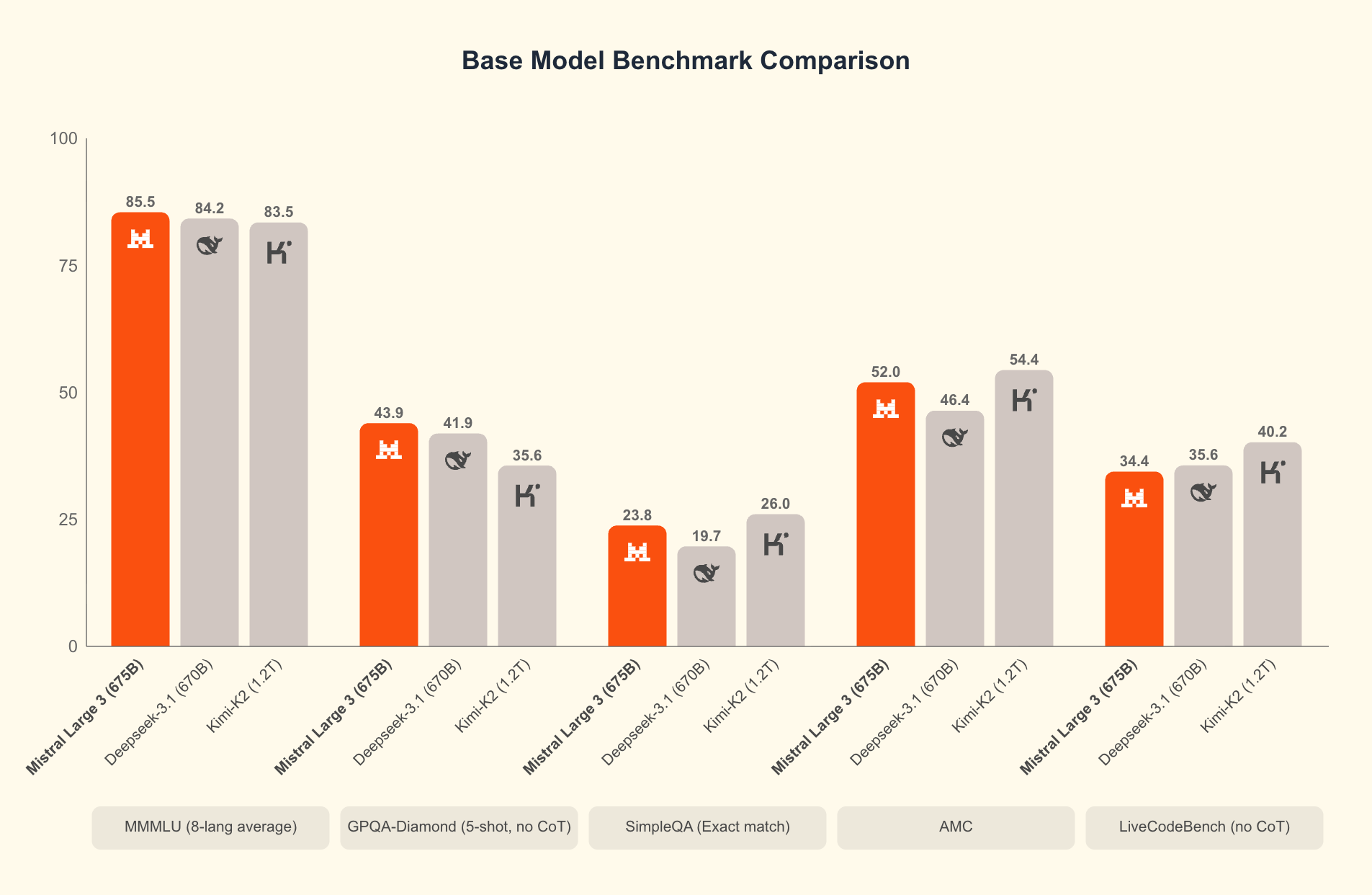
À la base, Mistral 3 comprend deux branches principales : la série compacte Ministral 3 et le vaste Mistral Large 3. Les modèles Ministral 3 – disponibles en tailles de paramètres 3B, 8B et 14B – ciblent les environnements à ressources limitées. Les ingénieurs les conçoivent pour les cas d'utilisation locaux et en périphérie, où chaque watt et chaque cœur comptent. Par exemple, la variante 3B tient confortablement sur des ordinateurs portables avec des GPU modestes, tandis que la 14B repousse les limites sur les configurations multi-GPU sans sacrifier la vitesse.
Mistral Large 3, d'autre part, utilise une architecture de mélange d'experts (mixture-of-experts) éparse avec 41 milliards de paramètres actifs et 675 milliards au total. Cette conception n'active que les experts pertinents par requête, réduisant considérablement la surcharge computationnelle. Les développeurs accèdent à des versions réglées sur des instructions pour des tâches telles que l'assistance au codage, la synthèse de documents et la traduction multilingue. Le modèle prend en charge plus de 40 langues nativement, surpassant ses pairs dans les dialogues non-anglais.
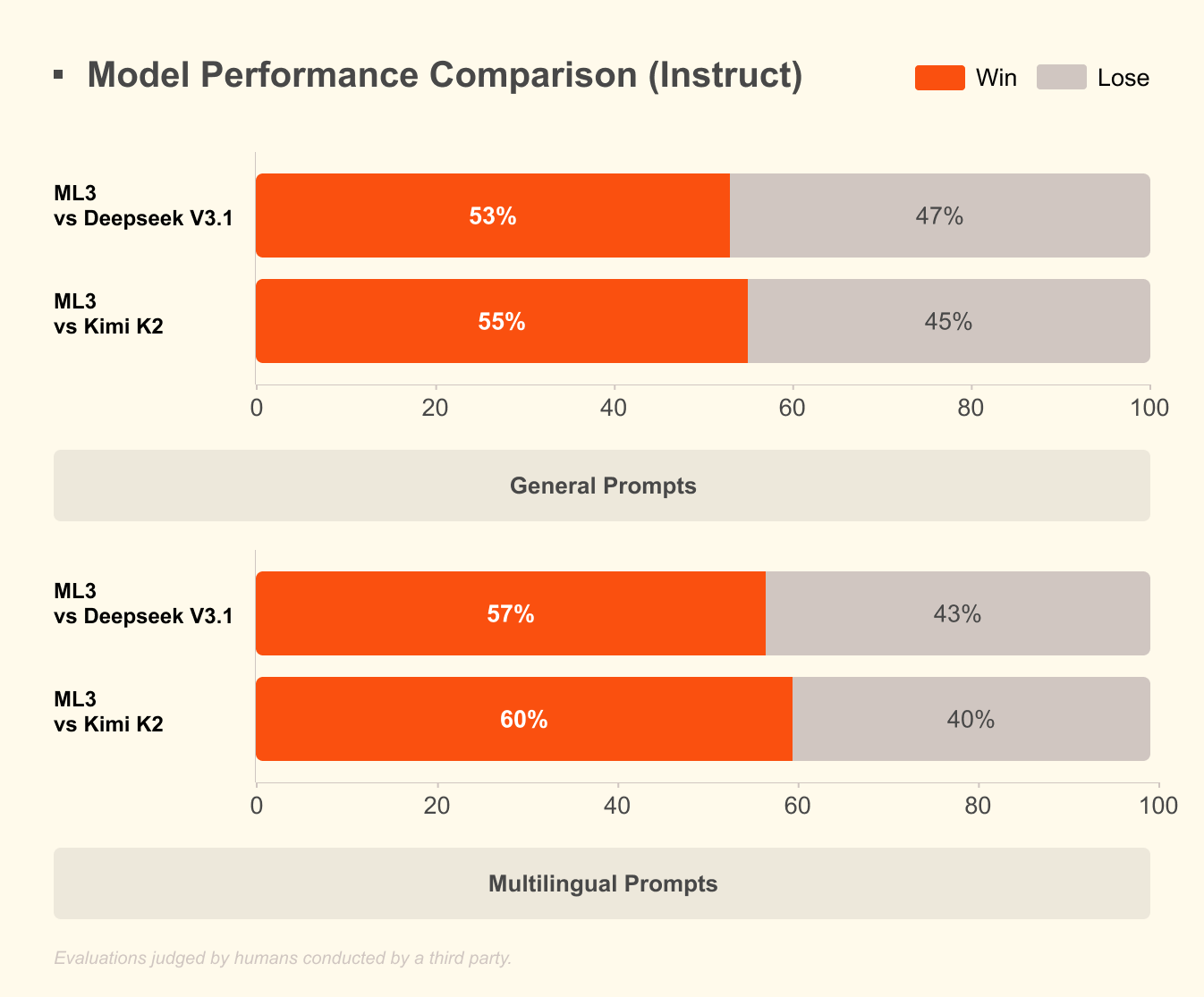
Qu'est-ce qui distingue Mistral 3 ? Les benchmarks révèlent son avantage dans des scénarios réels. Sur l'ensemble de données GPQA Diamond — un test rigoureux de raisonnement scientifique — les variantes de Mistral 3 maintiennent une grande précision même lorsque les jetons de sortie augmentent. Par exemple, le modèle Ministral 3B Instruct maintient une précision d'environ 35-40 % jusqu'à 20 000 jetons, rivalisant avec des modèles plus grands comme Gemma 2 9B tout en utilisant moins de ressources. Cette efficacité découle de techniques de quantification avancées, telles que la compression NVFP4, qui réduit la taille du modèle sans dégrader la qualité de sortie.
De plus, Mistral 3 intègre des fonctionnalités multimodales, traitant des images parallèlement au texte pour des applications de réponse visuelle aux questions ou de génération de contenu. L'ouverture de ces modèles favorise une itération rapide ; les communautés les affinent déjà pour des domaines spécialisés comme l'analyse juridique ou l'écriture créative. En conséquence, Mistral 3 démocratise l'IA de pointe, permettant aux startups et aux développeurs individuels de concurrencer les géants de la technologie.

Passant de la théorie à la pratique, l'exécution de ces modèles localement libère tout leur potentiel. Les API cloud introduisent de la latence et des coûts, mais l'inférence locale offre des réponses en moins d'une seconde. Ensuite, nous examinerons les prérequis matériels qui rendent cela possible.
Pourquoi exécuter Mistral 3 localement ? Avantages pour les développeurs et gains d'efficacité
Les développeurs choisissent l'exécution locale pour plusieurs raisons impérieuses. Premièrement, la confidentialité est primordiale : les données sensibles restent sur votre machine, évitant les serveurs tiers. Dans les industries réglementées comme la santé ou la finance, cet avantage de conformité s'avère inestimable. Deuxièmement, les économies de coûts s'accumulent rapidement. La grande efficacité de Mistral 3 signifie que vous évitez les frais par jeton, idéal pour les tests à volume élevé.
De plus, les exécutions locales accélèrent l'expérimentation. Itérez sur les invites, affinez les hyperparamètres ou chaînez les modèles sans délais réseau. Les benchmarks le confirment : sur du matériel grand public, Ministral 8B atteint 50-60 jetons par seconde, comparable aux configurations cloud mais avec zéro temps d'arrêt.
L'efficacité définit l'attrait de Mistral 3. Les modèles sont optimisés pour une inférence à faible coût, comme le montrent les résultats de GPQA Diamond où les variantes de Ministral surpassent Gemma 3 4B et 12B en précision soutenue. Ceci est important pour les tâches à contexte long ; à mesure que les sorties s'étendent à 20 000 jetons, la précision diminue très peu, assurant des performances fiables dans les chatbots ou les générateurs de code.
De plus, l'accès open source via des plateformes comme Hugging Face permet une intégration transparente avec des outils comme Apidog pour le prototypage d'API. Testez les points de terminaison de Mistral 3 localement avant de passer à l'échelle, comblant ainsi le fossé entre le développement et la production.
Cependant, le succès dépend d'une configuration appropriée. Une fois le matériel en place, vous passez à l'installation. Cette préparation assure un fonctionnement fluide et maximise le débit.
Exigences matérielles et logicielles pour le déploiement local de Mistral 3
Avant de lancer Mistral 3, évaluez les capacités de votre système. Les spécifications minimales incluent un CPU moderne (Intel i7 ou AMD Ryzen 7) avec 16 Go de RAM pour le modèle 3B. Pour les variantes 8B et 14B, allouez 32 Go de RAM et un GPU NVIDIA avec au moins 8 Go de VRAM — pensez RTX 3060 ou mieux. Les utilisateurs d'Apple Silicon bénéficient de la mémoire unifiée ; le M1 Pro avec 16 Go gère le 3B sans effort, tandis que le M3 Max excelle avec le 14B.
Les exigences de stockage varient : le modèle 3B occupe environ 2 Go quantifiés, passant à environ 9 Go pour le 14B. Utilisez des SSD pour un chargement plus rapide. Systèmes d'exploitation ? Linux (Ubuntu 22.04) offre les meilleures performances, suivi de macOS Ventura+. Windows 11 fonctionne via WSL2, bien que le passthrough GPU nécessite des ajustements.
Côté logiciel, Python 3.10+ constitue l'épine dorsale. Installez CUDA 12.1 pour les cartes NVIDIA afin d'activer l'accélération GPU — essentielle pour des latences inférieures à 100 ms. Pour les exécutions uniquement CPU, utilisez des bibliothèques comme ONNX Runtime.
La quantification joue ici un rôle essentiel. Mistral 3 prend en charge les formats 4 bits et 8 bits, réduisant l'empreinte mémoire de 75 % tout en conservant 95 % de précision. Des outils comme bitsandbytes gèrent cela automatiquement.
Une fois équipé, l'installation suit un chemin simple. Nous recommandons Ollama pour sa simplicité, mais des alternatives existent. Ce choix simplifie le processus, nous menant aux étapes de configuration essentielles.
Installer Ollama : La porte d'entrée vers une IA locale sans effort
Ollama se distingue comme l'outil principal pour exécuter des modèles open source comme Mistral 3 localement. Cette plateforme légère abstrait les complexités, fournissant une CLI et un serveur API dans un seul package. Les développeurs apprécient son support multiplateforme et sa détection GPU sans configuration.
Commencez par télécharger Ollama depuis le site officiel (ollama.com). Sur Linux, exécutez :
curl -fsSL https://ollama.com/install.sh | sh
Ce script installe les binaires et configure les services. Vérifiez avec ollama --version ; attendez-vous à une sortie comme "ollama version 0.3.0". Pour macOS, l'installeur DMG gère les dépendances, y compris Rosetta pour l'émulation Intel sur ARM.
Les utilisateurs de Windows peuvent télécharger l'EXE depuis les releases GitHub. Après l'installation, lancez via PowerShell : ollama serve. Ollama se met en tâche de fond (daemonize), exposant une API REST sur le port 11434.
Pourquoi Ollama ? Il télécharge les modèles de son registre, y compris Ministral 3, avec une quantification intégrée. Aucun clonage manuel de Hugging Face n'est nécessaire. De plus, il prend en charge les Modelfiles pour l'affinement personnalisé, s'alignant sur l'éthos open source de Mistral 3.
Avec Ollama prêt, vous téléchargez et exécutez les modèles ensuite. Cette étape transforme votre configuration en un poste de travail IA fonctionnel.
Télécharger et exécuter les modèles Ministral 3 avec Ollama
La bibliothèque d'Ollama héberge les variantes de Ministral 3.
Commencez par lister les tags disponibles :
ollama list
Pour télécharger le modèle 3B :
ollama pull ministral:3b-instruct-q4_0
Cette commande télécharge environ 2 Go, vérifiant l'intégrité via des hachages. Des barres de progression suivent le téléchargement, se terminant généralement en quelques minutes sur une connexion haut débit.
Lancez une session interactive :
ollama run ministral-3
Ollama charge le modèle en mémoire, chauffant les caches pour les requêtes ultérieures. Saisissez les invites directement ; par exemple :
>> Explain quantum entanglement in simple terms.

Le modèle répond en temps réel, tirant parti du réglage des instructions pour des sorties cohérentes. Quittez avec /bye.
Vous rencontrez des problèmes courants ? Si la sous-utilisation du GPU se produit, définissez la variable d'environnement OLLAMA_NUM_GPU=999. Pour les erreurs OOM, passez à une quantification inférieure comme q3_K_M.
Au-delà des bases, l'API d'Ollama permet un accès programmatique. Envoyez une requête de complétion avec curl :
curl http://localhost:11434/api/generate -d '{
"model": "ministral:3b-instruct-q4_0",
"prompt": "Write a Python function to sort a list.",
"stream": false
}'
Cette réponse JSON inclut le texte généré, parfait pour l'intégration avec Apidog pendant le développement d'API.
L'exécution des modèles marque le début ; l'optimisation améliore les performances. Par conséquent, nous nous tournons vers des techniques qui exploitent chaque goutte d'efficacité de votre matériel.
Optimisation de l'inférence Mistral 3 : Compromis entre vitesse, mémoire et précision
L'efficacité définit le succès de l'IA locale. La conception de Mistral 3 brille ici, mais des ajustements amplifient les gains. Commencez par la quantification : Ollama utilise par défaut Q4_0, équilibrant taille et fidélité. Pour des ressources ultra-faibles, essayez Q2_K — réduisant de moitié la mémoire au coût de 10 % de perplexité.
L'orchestration GPU est importante. Activez l'attention flash via OLLAMA_FLASH_ATTENTION=1 pour des accélérations 2x sur des contextes longs. Mistral 3 prend en charge jusqu'à 128K jetons ; testez avec des invites de type GPQA pour vérifier la précision soutenue.
Le traitement par lots augmente le débit. Utilisez /api/generate d'Ollama avec plusieurs invites en parallèle, en tirant parti des clients Python asynchrones. Par exemple, écrivez une boucle :
import requests
import json
model = "ministral:8b-instruct-q4_0"
url = "http://localhost:11434/api/generate"
prompts = ["Prompt 1", "Prompt 2"]
for p in prompts:
response = requests.post(url, json={"model": model, "prompt": p})
print(json.loads(response.text)["response"])
Ceci gère plus de 10 requêtes par seconde sur des configurations multi-cœurs.
La gestion de la mémoire évite les échanges. Surveillez avec nvidia-smi ; déchargez les couches vers le CPU si la VRAM est saturée. Des bibliothèques comme vLLM s'intègrent à Ollama pour le traitement par lots continu, maintenant 100 jetons/seconde sur les A100.
Réglage de la précision ? Affinez avec des adaptateurs LoRA sur des données de domaine. La bibliothèque PEFT de Hugging Face les applique à Ministral 3, nécessitant environ 1 Go d'espace supplémentaire. Après l'affinage, exportez au format Ollama via ollama create.
Évaluez votre configuration par rapport à GPQA Diamond. Scriptez les évaluations pour tracer la précision par rapport aux jetons, en reproduisant les graphiques de Mistral. Les variantes à haute efficacité comme Ministral 8B maintiennent des scores de plus de 50 %, soulignant leur avantage sur Qwen 2.5 VL.
Ces optimisations vous préparent aux applications avancées. Ainsi, nous explorons des intégrations qui étendent la portée de Mistral 3.
Intégrer Mistral 3 avec les outils de développement : API et au-delà
Mistral 3 local prospère dans les écosystèmes. Associez-le à Apidog pour simuler des API basées sur l'IA. Concevez des points de terminaison qui interrogent Ollama, testez les charges utiles et validez les réponses — tout cela hors ligne.
Par exemple, créez une route POST /generate dans Apidog, la redirigeant vers l'API d'Ollama. Importez des collections pour les modèles d'invites, garantissant que Mistral 3 gère les requêtes multilingues sans faille.
Les utilisateurs de LangChain chaînent Mistral 3 avec des outils :
from langchain_ollama import OllamaLLM
from langchain_core.prompts import PromptTemplate
llm = OllamaLLM(model="ministral:3b-instruct-q4_0")
prompt = PromptTemplate.from_template("Translate {text} to French.")
chain = prompt | llm
print(chain.invoke({"text": "Hello world"}))
Cette configuration traite 50 requêtes/minute, idéale pour les pipelines RAG.
Les tableaux de bord Streamlit visualisent les sorties. Intégrez les appels Ollama dans les applications pour des chats interactifs, en tirant parti du raisonnement de Mistral 3 pour des Q&A dynamiques.
Considérations de sécurité ? Exécutez Ollama derrière des proxys NGINX, en limitant le débit des points de terminaison. Pour la production, conteneurisez avec Docker :
FROM ollama/ollama
COPY Modelfile .
RUN ollama create mistral-local -f Modelfile
Ceci isole les environnements, permettant un passage à l'échelle vers Kubernetes.
À mesure que les applications évoluent, la surveillance devient essentielle. Des outils comme Prometheus suivent la latence, alertant sur les écarts par rapport à l'efficacité de référence.
En résumé, ces intégrations transforment Mistral 3 d'un modèle autonome en un moteur polyvalent. Cependant, des défis surgissent ; les relever assure des déploiements robustes.
Dépannage des problèmes courants lors de l'exécution locale de Mistral 3
Même les configurations optimisées rencontrent des obstacles. Les incohérences CUDA sont en tête de liste : vérifiez les versions avec nvcc --version. Rétrogradez si des conflits surviennent, car Mistral 3 tolère la version 11.8 et plus.
Le chargement du modèle échoue ? Videz le cache d'Ollama : ollama rm ministral:3b-instruct-q4_0 puis téléchargez à nouveau. Les téléchargements corrompus proviennent des réseaux ; utilisez --insecure avec parcimonie.
Sur macOS, l'accélération Metal est moins performante que CUDA. Forcez le CPU pour la stabilité : OLLAMA_METAL=0. Les utilisateurs de Windows WSL activent les pilotes NVIDIA via wsl --update.
La surchauffe est un fléau pour les ordinateurs portables ; limitez la puissance avec nvidia-smi -pl 100. Pour les baisses de précision, examinez les invites — Ministral 3 excelle dans les formats d'instruction.
Les forums communautaires sur Reddit et Hugging Face résolvent 90 % des cas limites. Enregistrez les erreurs avec OLLAMA_DEBUG=1 pour le diagnostic.
Une fois les pièges surmontés, Mistral 3 offre une valeur constante. Enfin, nous réfléchissons à son impact plus large.
Conclusion : Exploitez Mistral 3 localement pour les innovations de l'IA de demain
Mistral 3 redéfinit l'IA open source avec son mélange de puissance et de praticité. En l'exécutant localement via Ollama, les développeurs bénéficient d'une vitesse, d'une confidentialité et d'un contrôle des coûts inaccessibles ailleurs. Du téléchargement des modèles à l'intégration des ajustements, ce guide vous fournit des étapes concrètes.
Expérimentez audacieusement : commencez avec la variante 3B, passez à 14B et mesurez-vous aux benchmarks. À mesure que Mistral AI itère, les exécutions locales vous permettent de garder une longueur d'avance.
Prêt à construire ? Téléchargez Apidog gratuitement et prototypez des API alimentées par votre configuration Mistral 3. L'avenir de l'IA efficace commence sur votre machine — faites en sorte que cela compte.