L'exécution de grands modèles linguistiques (LLM) en local offre aux développeurs confidentialité, contrôle et économies. Les modèles open-weight d'OpenAI, collectivement connus sous le nom de **GPT-OSS** (gpt-oss-120b et gpt-oss-20b), offrent de puissantes capacités de raisonnement pour des tâches telles que le codage, les flux de travail agentiques et l'analyse de données. Avec **Ollama**, une plateforme open-source, vous pouvez déployer ces modèles sur votre propre matériel sans dépendances cloud. Ce guide technique vous explique comment installer Ollama, configurer les modèles GPT-OSS et déboguer avec **Apidog**, un outil qui simplifie les tests d'API pour les LLM locaux.
Pourquoi exécuter GPT-OSS en local avec Ollama ?
L'exécution de **GPT-OSS** en local à l'aide d'Ollama offre des avantages distincts pour les développeurs et les chercheurs. Premièrement, elle assure la **confidentialité des données**, car vos entrées et sorties restent sur votre machine. Deuxièmement, elle élimine les coûts récurrents des API cloud, ce qui la rend idéale pour les cas d'utilisation à volume élevé ou expérimentaux. Troisièmement, la compatibilité d'Ollama avec la structure d'API d'OpenAI permet une intégration transparente avec les outils existants, tandis que son support des modèles quantifiés comme gpt-oss-20b (ne nécessitant que 16 Go de mémoire) assure l'accessibilité sur du matériel modeste.

De plus, Ollama simplifie les complexités du déploiement des LLM. Il gère les poids des modèles, les dépendances et les configurations via un seul Modelfile, semblable à un conteneur Docker pour l'IA. Associé à **Apidog**, qui offre une visualisation en temps réel des réponses d'IA en streaming, vous obtenez un écosystème robuste pour le développement d'IA locale. Ensuite, explorons les prérequis pour configurer cet environnement.
Prérequis pour l'exécution locale de GPT-OSS
Avant de poursuivre, assurez-vous que votre système répond aux exigences suivantes :
- **Matériel** :
- Pour gpt-oss-20b : Minimum 16 Go de RAM, idéalement avec un GPU (par exemple, NVIDIA 1060 4 Go).
- Pour gpt-oss-120b : 80 Go de mémoire GPU (par exemple, un seul GPU de 80 Go ou une configuration de centre de données haut de gamme).
- 20-50 Go de stockage libre pour les poids des modèles et les dépendances.
- **Logiciel** :
- Système d'exploitation : Linux ou macOS recommandé ; Windows pris en charge avec une configuration supplémentaire.
- Ollama : Téléchargez depuis ollama.com.
- Optionnel : Docker pour exécuter Open WebUI ou Apidog pour les tests d'API.
- **Internet** : Connexion stable pour les téléchargements initiaux des modèles.
- **Dépendances** : Pilotes GPU NVIDIA/AMD si vous utilisez l'accélération GPU ; le mode CPU seul fonctionne mais est plus lent.
Une fois ces éléments en place, vous êtes prêt à installer Ollama et à déployer GPT-OSS. Passons au processus d'installation.
Étape 1 : Installation d'Ollama sur votre système
L'installation d'Ollama est simple, prenant en charge macOS, Linux et Windows. Suivez ces étapes pour le configurer :
Télécharger Ollama :
- Visitez ollama.com et téléchargez l'installateur pour votre OS.
- Pour Linux/macOS, utilisez la commande terminal :
curl -fsSL https://ollama.com/install.sh | sh
Ce script automatise le processus de téléchargement et de configuration.
Vérifier l'installation :
- Exécutez
ollama --versiondans votre terminal. Vous devriez voir un numéro de version (par exemple, 0.1.44). Si ce n'est pas le cas, consultez le GitHub d'Ollama pour le dépannage.
Démarrer le serveur Ollama :
- Exécutez
ollama servepour lancer le serveur, qui écoute surhttp://localhost:11434. Gardez ce terminal en cours d'exécution ou configurez Ollama comme un service d'arrière-plan pour une utilisation continue.
Une fois installé, Ollama est prêt à télécharger et exécuter les modèles **GPT-OSS**. Passons au téléchargement des modèles.
Étape 2 : Téléchargement des modèles GPT-OSS
Les modèles **GPT-OSS** d'OpenAI (gpt-oss-120b et gpt-oss-20b) sont disponibles sur Hugging Face et optimisés pour Ollama avec la quantification MXFP4, réduisant les exigences de mémoire. Suivez ces étapes pour les télécharger :
Choisir le modèle :
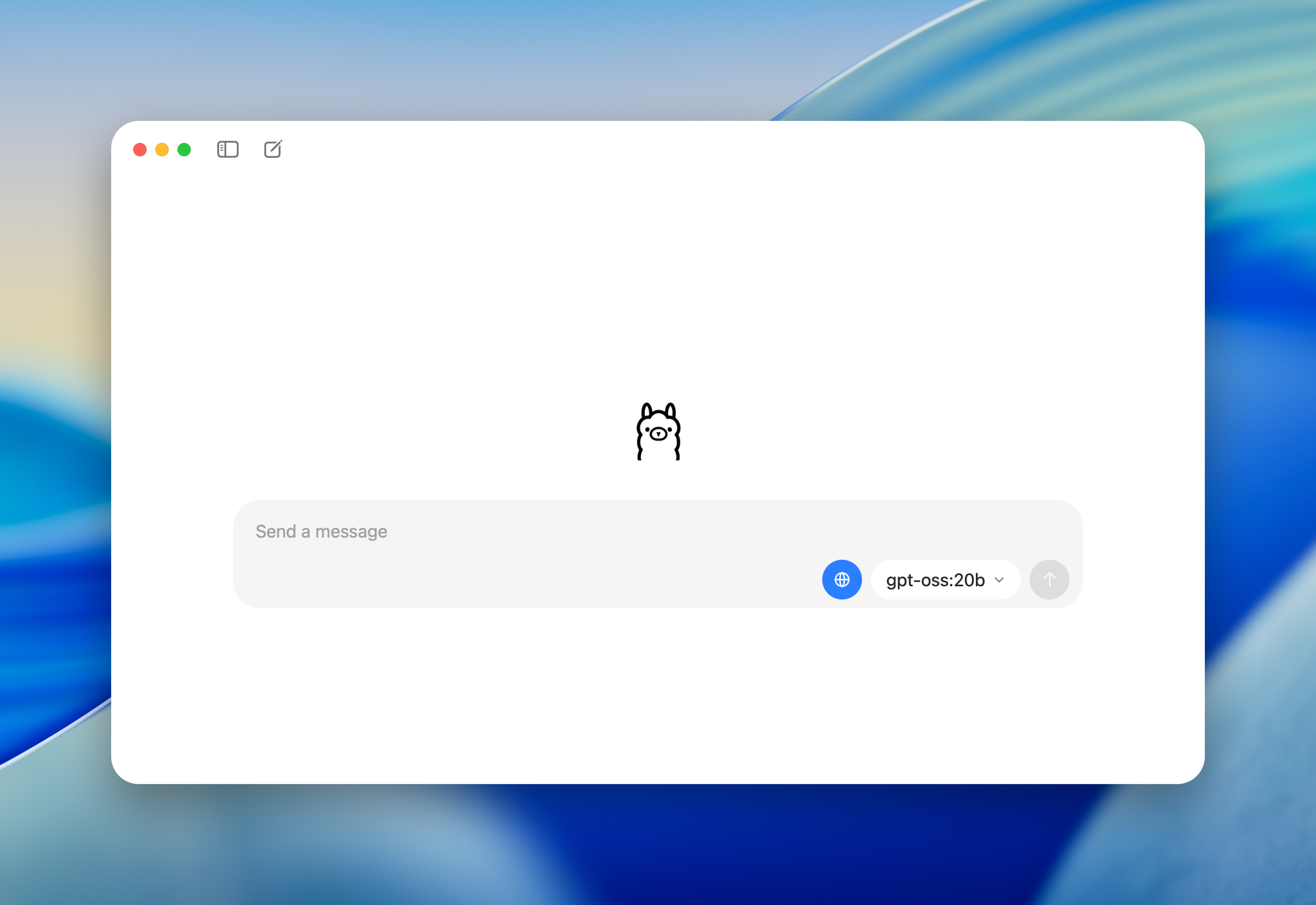
- **gpt-oss-20b** : Idéal pour les ordinateurs de bureau/portables avec 16 Go de RAM. Il active 3,6 milliards de paramètres par jeton, adapté aux appareils périphériques.
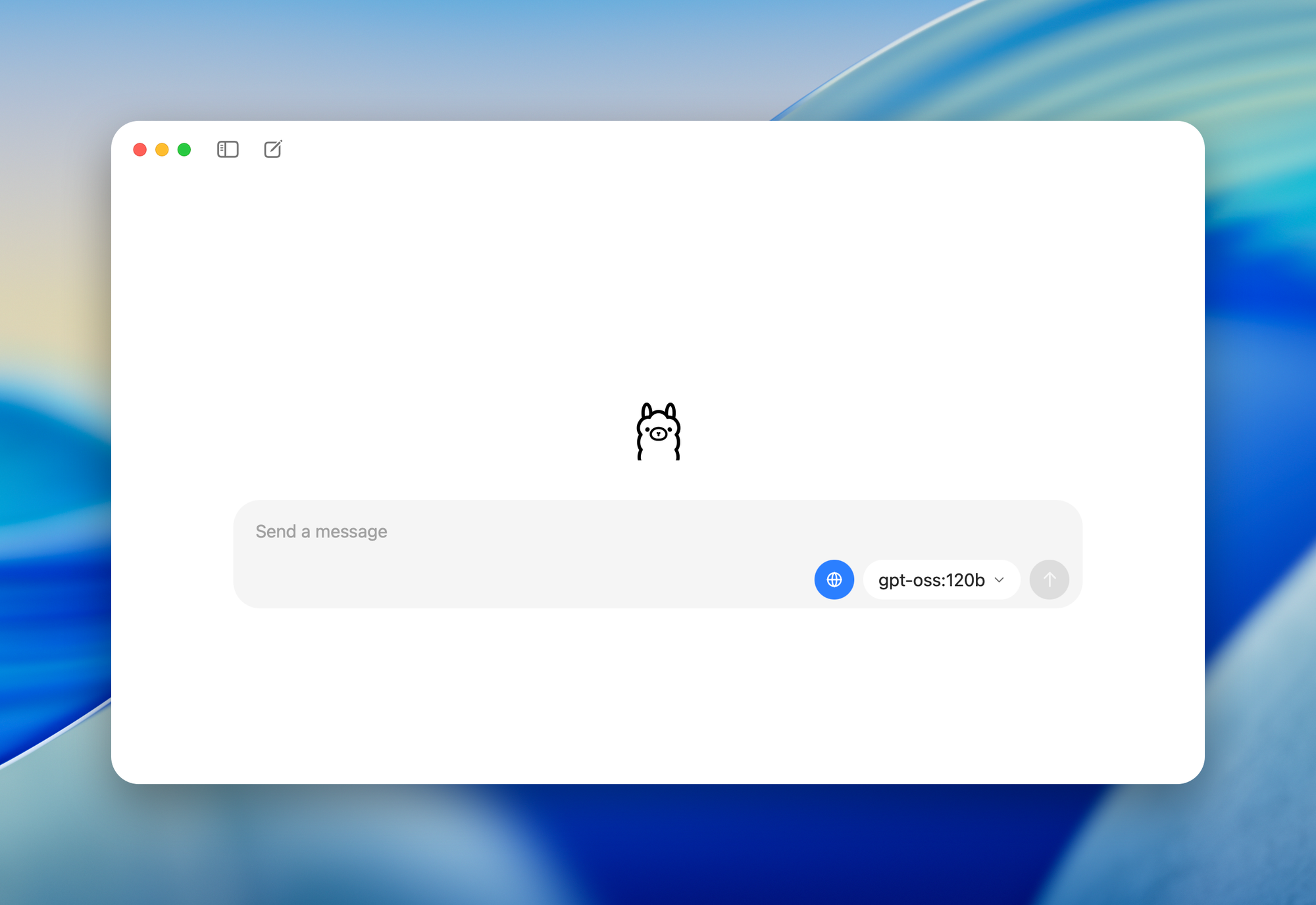
- **gpt-oss-120b** : Conçu pour les centres de données ou les GPU haut de gamme avec 80 Go de mémoire, activant 5,1 milliards de paramètres par jeton.
Télécharger via Ollama :
- Dans votre terminal, exécutez :
ollama pull gpt-oss-20b
ou
ollama pull gpt-oss-120b
Selon votre matériel, le téléchargement (20-50 Go) peut prendre du temps. Assurez une connexion Internet stable.
Vérifier le téléchargement :
- Listez les modèles installés avec :
ollama list
Recherchez gpt-oss-20b:latest ou gpt-oss-120b:latest.
Une fois le modèle téléchargé, vous pouvez maintenant l'exécuter localement. Explorons comment interagir avec **GPT-OSS**.
Étape 3 : Exécuter les modèles GPT-OSS avec Ollama
Ollama offre plusieurs façons d'interagir avec les modèles **GPT-OSS** : interface de ligne de commande (CLI), API, ou interfaces graphiques comme Open WebUI. Commençons par la CLI pour plus de simplicité.
Lancer une session interactive :
- Exécutez :
ollama run gpt-oss-20b
Ceci ouvre une session de chat en temps réel. Tapez votre requête (par exemple, « Écrire une fonction Python pour la recherche binaire ») et appuyez sur Entrée. Utilisez /help pour les commandes spéciales.
Requêtes ponctuelles :
- Pour des réponses rapides sans mode interactif, utilisez :
ollama run gpt-oss-20b "Expliquer l'informatique quantique en termes simples"
Ajuster les paramètres :
- Modifiez le comportement du modèle avec des paramètres comme la température (créativité) et top-p (diversité des réponses). Par exemple :
ollama run gpt-oss-20b --temperature 0.1 --top-p 1.0 "Rédiger un résumé factuel de la technologie blockchain"
Une température plus basse (par exemple, 0,1) assure des sorties déterministes et factuelles, idéales pour les tâches techniques.
Ensuite, personnalisons le comportement du modèle à l'aide de Modelfiles pour des cas d'utilisation spécifiques.
Étape 4 : Personnalisation de GPT-OSS avec les Modelfiles d'Ollama
Les Modelfiles d'Ollama vous permettent d'adapter le comportement de **GPT-OSS** sans réentraînement. Vous pouvez définir des invites système, ajuster la taille du contexte ou affiner les paramètres. Voici comment créer un modèle personnalisé :
Créer un Modelfile :
- Créez un fichier nommé
Modelfileavec :
FROM gpt-oss-20b
SYSTEM "Vous êtes un assistant technique spécialisé en programmation Python. Fournissez du code concis et précis avec des commentaires."
PARAMETER temperature 0.5
PARAMETER num_ctx 4096
Ceci configure le modèle comme un assistant axé sur Python avec une créativité modérée et une fenêtre de contexte de 4k jetons.
Construire le modèle personnalisé :
- Naviguez vers le répertoire contenant le Modelfile et exécutez :
ollama create python-gpt-oss -f Modelfile
Exécuter le modèle personnalisé :
- Lancez-le avec :
ollama run python-gpt-oss
Maintenant, le modèle priorise les réponses liées à Python avec le comportement spécifié.
Cette personnalisation améliore **GPT-OSS** pour des domaines spécifiques, tels que le codage ou la documentation technique. Maintenant, intégrons le modèle dans des applications en utilisant l'API d'Ollama.
Étape 5 : Intégration de GPT-OSS avec l'API d'Ollama
L'API d'Ollama, fonctionnant sur http://localhost:11434, permet un accès programmatique à **GPT-OSS**. C'est idéal pour les développeurs qui créent des applications basées sur l'IA. Voici comment l'utiliser :
Points d'accès API :
- POST /api/generate : Génère du texte pour une seule invite. Exemple :
curl http://localhost:11434/api/generate -H "Content-Type: application/json" -d '{"model": "gpt-oss-20b", "prompt": "Écrire un script Python pour une API REST"}'
- POST /api/chat : Prend en charge les interactions conversationnelles avec l'historique des messages :
curl http://localhost:11434/v1/chat/completions -H "Content-Type: application/json" -d '{"model": "gpt-oss-20b", "messages": [{"role": "user", "content": "Expliquer les réseaux neuronaux"}]}'
- POST /api/embeddings : Génère des embeddings vectoriels pour des tâches sémantiques comme la recherche ou la classification.
Compatibilité OpenAI :
- Ollama prend en charge le format de l'API Chat Completions d'OpenAI. Utilisez Python avec la bibliothèque OpenAI :
from openai import OpenAI
client = OpenAI(base_url="http://localhost:11434/v1", api_key="ollama")
response = client.chat.completions.create(
model="gpt-oss-20b",
messages=[{"role": "user", "content": "Qu'est-ce que l'apprentissage automatique ?"}]
)
print(response.choices[0].message.content)
Cette intégration API permet à **GPT-OSS** d'alimenter des chatbots, des générateurs de code ou des outils d'analyse de données. Cependant, le débogage des réponses en streaming peut être difficile. Voyons comment **Apidog** simplifie cela.
Étape 6 : Débogage de GPT-OSS avec Apidog
**Apidog** est un puissant outil de test d'API qui visualise les réponses en streaming des points d'accès d'Ollama, facilitant ainsi le débogage des sorties de **GPT-OSS**. Voici comment l'utiliser :
Installer Apidog :
- Téléchargez Apidog depuis apidog.com et installez-le sur votre système.
Configurer l'API Ollama dans Apidog :
- Créez une nouvelle requête API dans Apidog.
- Définissez l'URL sur
http://localhost:11434/api/generate. - Utilisez un corps JSON comme :
{
"model": "gpt-oss-20b",
"prompt": "Générer une fonction Python pour le tri",
"stream": true
}
Visualiser les réponses :
- Apidog fusionne les jetons diffusés en un format lisible, contrairement aux sorties JSON brutes. Cela aide à identifier les problèmes de formatage ou les erreurs logiques dans le raisonnement du modèle.
- Utilisez l'analyse de raisonnement d'Apidog pour inspecter le processus de pensée étape par étape de **GPT-OSS**, en particulier pour les tâches complexes comme le codage ou la résolution de problèmes.
Tests comparatifs :
- Créez des collections d'invites dans Apidog pour tester comment différents paramètres (par exemple, température, top-p) affectent les sorties de **GPT-OSS**. Cela garantit une performance optimale du modèle pour votre cas d'utilisation.
La visualisation d'**Apidog** transforme le débogage d'une tâche fastidieuse en un processus clair et exploitable, améliorant votre flux de travail de développement. Maintenant, abordons les problèmes courants que vous pourriez rencontrer.
Étape 7 : Dépannage des problèmes courants
L'exécution de **GPT-OSS** en local peut présenter des défis. Voici des solutions aux problèmes fréquents :
Erreur de mémoire GPU :
- Problème : gpt-oss-120b échoue en raison d'une mémoire GPU insuffisante.
- Solution : Passez à gpt-oss-20b ou assurez-vous que votre système dispose d'un GPU de 80 Go. Vérifiez l'utilisation de la mémoire avec
nvidia-smi.
Le modèle ne démarre pas :
- Problème :
ollama runéchoue avec une erreur. - Solution : Vérifiez que le modèle est téléchargé (
ollama list) et que le serveur Ollama est en cours d'exécution (ollama serve). Vérifiez les journaux dans~/.ollama/logs.
L'API ne répond pas :
- Problème : Les requêtes API vers
localhost:11434échouent. - Solution : Assurez-vous que
ollama serveest actif et que le port 11434 est ouvert. Utiliseznetstat -tuln | grep 11434pour confirmer.
Performances lentes :
- Problème : L'inférence basée sur le CPU est lente.
- Solution : Activez l'accélération GPU avec les pilotes appropriés ou utilisez un modèle plus petit comme gpt-oss-20b.
Pour les problèmes persistants, consultez le GitHub d'Ollama ou la communauté Hugging Face pour le support **GPT-OSS**.
Étape 8 : Améliorer GPT-OSS avec Open WebUI
Pour une interface conviviale, associez Ollama à Open WebUI, un tableau de bord basé sur un navigateur pour **GPT-OSS** :
Installer Open WebUI :
- Utilisez Docker :
docker run -d -p 3000:8080 --name open-webui ghcr.io/open-webui/open-webui:main
Accéder à l'interface :
- Ouvrez
http://localhost:3000dans votre navigateur. - Sélectionnez
gpt-oss-20bougpt-oss-120bet commencez à discuter. Les fonctionnalités incluent l'historique des chats, le stockage des invites et la commutation de modèle.
Téléchargements de documents :
- Téléchargez des fichiers pour des réponses contextuelles (par exemple, révisions de code ou analyse de données) en utilisant la Génération Augmentée par Récupération (RAG).
Open WebUI simplifie l'interaction pour les utilisateurs non techniques, complétant les capacités de débogage technique d'**Apidog**.
Conclusion : Libérer le potentiel de GPT-OSS avec Ollama et Apidog
L'exécution de **GPT-OSS** en local avec Ollama vous permet d'exploiter les modèles open-weight d'OpenAI gratuitement, avec un contrôle total sur la confidentialité et la personnalisation. En suivant ce guide, vous avez appris à installer Ollama, à télécharger les modèles **GPT-OSS**, à personnaliser leur comportement, à les intégrer via une API et à déboguer avec **Apidog**. Que vous développiez des applications basées sur l'IA ou que vous expérimentiez des tâches de raisonnement, cette configuration offre une flexibilité inégalée. De petits ajustements, comme le réglage des paramètres ou l'utilisation de la visualisation d'**Apidog**, peuvent améliorer considérablement votre flux de travail. Commencez dès aujourd'hui à explorer l'IA locale et débloquez le potentiel de **GPT-OSS** !