
Exécuter Gemma 3 localement avec Ollama vous donne le contrôle total de votre environnement d'IA sans dépendre des services cloud. Ce guide vous explique comment configurer Ollama, télécharger Gemma 3 et le faire fonctionner sur votre machine.
Commençons.
Pourquoi exécuter Gemma 3 localement avec Ollama ?
« Pourquoi s'embêter à exécuter Gemma 3 localement ? » Eh bien, il y a des raisons convaincantes. D'une part, le déploiement local vous donne le contrôle total de vos données et de votre confidentialité, pas besoin d'envoyer des informations sensibles vers le cloud. De plus, c'est rentable, car vous évitez les frais d'utilisation d'API continus. De plus, l'efficacité de Gemma 3 signifie que même le modèle 27B peut fonctionner sur un seul GPU, ce qui le rend accessible aux développeurs disposant d'un matériel modeste.
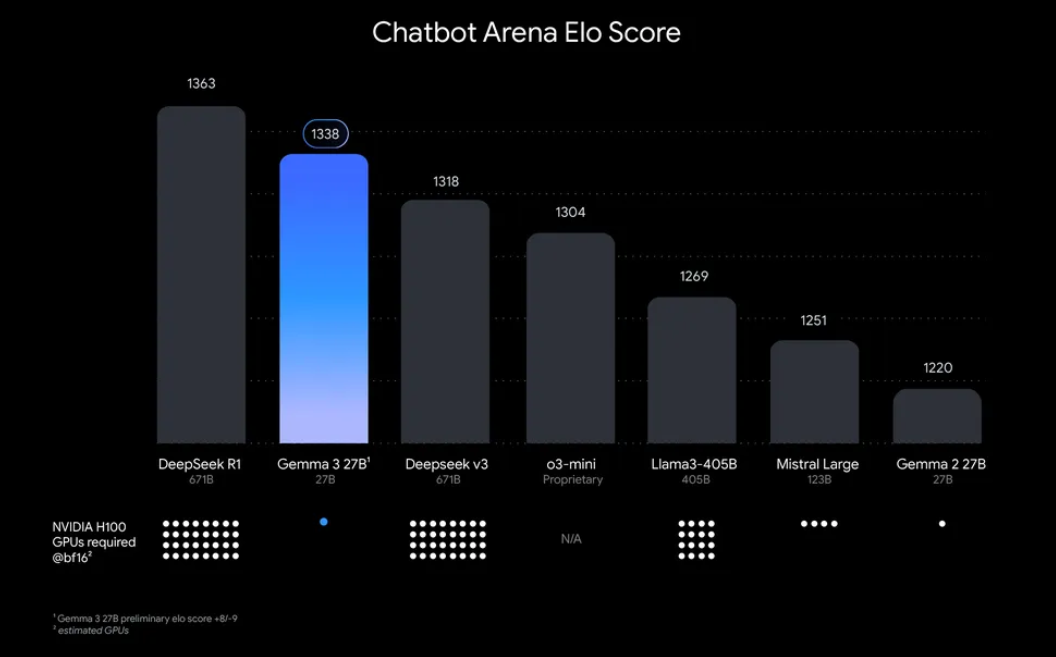
Ollama, une plateforme légère pour exécuter des modèles de langage volumineux (LLM) localement, simplifie ce processus. Il regroupe tout ce dont vous avez besoin : les poids des modèles, les configurations et les dépendances dans un format facile à utiliser. Cette combinaison de Gemma 3 et Ollama est parfaite pour bricoler, créer des applications ou tester des flux de travail d'IA sur votre machine. Alors, retroussons nos manches et commençons !
Ce dont vous aurez besoin pour exécuter Gemma 3 avec Ollama
Avant de passer à la configuration, assurez-vous d'avoir les prérequis suivants :
- Une machine compatible : vous aurez besoin d'un ordinateur avec un GPU (de préférence NVIDIA pour des performances optimales) ou un processeur puissant. Le modèle 27B nécessite des ressources importantes, mais les versions plus petites comme 1B ou 4B peuvent fonctionner sur du matériel moins puissant.
- Ollama installé : téléchargez et installez Ollama, disponible pour MacOS, Windows et Linux. Vous pouvez l'obtenir sur ollama.com.
- Compétences de base en ligne de commande : vous interagirez avec Ollama via le terminal ou l'invite de commande.
- Connexion Internet : initialement, vous devrez télécharger les modèles Gemma 3, mais une fois téléchargés, vous pourrez les exécuter hors ligne.
- Optionnel : Apidog pour les tests API : si vous prévoyez d'intégrer Gemma 3 à une API ou de tester ses réponses par programmation, l'interface intuitive d'Apidog peut vous faire gagner du temps et des efforts.
Maintenant que vous êtes équipé, passons au processus d'installation et de configuration.
Guide étape par étape : installation d'Ollama et téléchargement de Gemma 3
1. Installez Ollama sur votre machine
Ollama facilite le déploiement local de LLM, et son installation est simple. Voici comment :
- Pour MacOS/Windows : visitez ollama.com et téléchargez le programme d'installation pour votre système d'exploitation. Suivez les instructions à l'écran pour terminer l'installation.
- Pour Linux (par exemple, Ubuntu) : ouvrez votre terminal et exécutez la commande suivante :
curl -fsSL https://ollama.com/install.sh | sh
Ce script détecte automatiquement votre matériel (y compris les GPU) et installe Ollama.
Une fois installé, vérifiez l'installation en exécutant :
ollama --version

Vous devriez voir le numéro de version actuel, confirmant qu'Ollama est prêt à fonctionner.
2. Extraire les modèles Gemma 3 à l'aide d'Ollama
La bibliothèque de modèles d'Ollama comprend Gemma 3, grâce à son intégration avec des plateformes comme Hugging Face et les offres d'IA de Google. Pour télécharger Gemma 3, utilisez la commande ollama pull.
ollama pull gemma3

Pour les modèles plus petits, vous pouvez utiliser :
ollama pull gemma3:12bollama pull gemma3:4bollama pull gemma3:1b
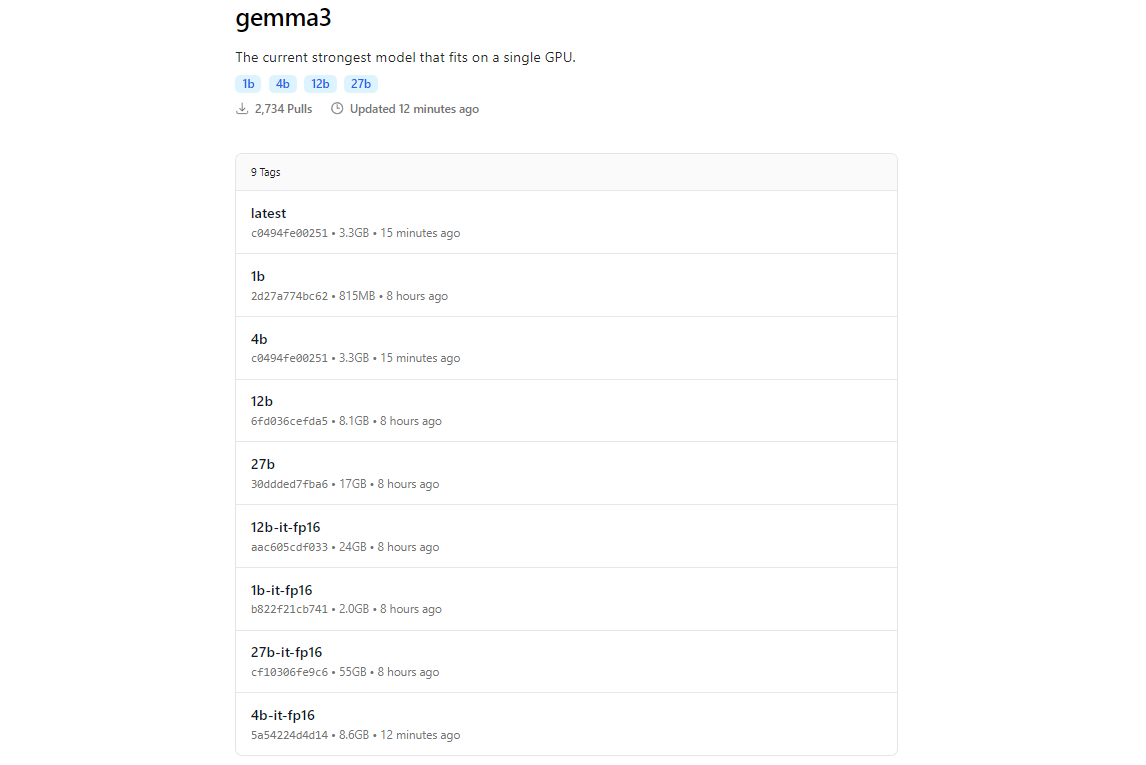
La taille du téléchargement varie selon le modèle, attendez-vous à ce que le modèle 27B fasse plusieurs gigaoctets, assurez-vous donc de disposer d'un stockage suffisant. Les modèles Gemma 3 sont optimisés pour l'efficacité, mais ils nécessitent toujours un matériel décent pour les variantes plus volumineuses.
3. Vérifiez l'installation
Une fois téléchargé, vérifiez que le modèle est disponible en répertoriant tous les modèles :
ollama list

Vous devriez voir gemma3 (ou la taille que vous avez choisie) dans la liste. S'il est là, vous êtes prêt à exécuter Gemma 3 localement !
Exécution de Gemma 3 avec Ollama : mode interactif et intégration API
Mode interactif : discuter avec Gemma 3
Le mode interactif d'Ollama vous permet de discuter avec Gemma 3 directement depuis le terminal. Pour commencer, exécutez :
ollama run gemma3
Vous verrez une invite où vous pourrez taper des requêtes. Par exemple, essayez :
Quelles sont les principales caractéristiques de Gemma 3 ?
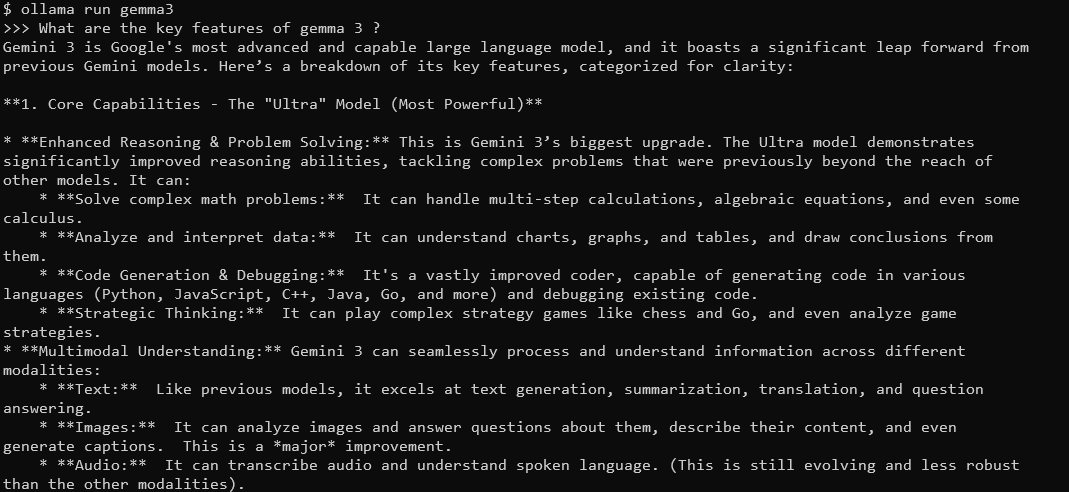
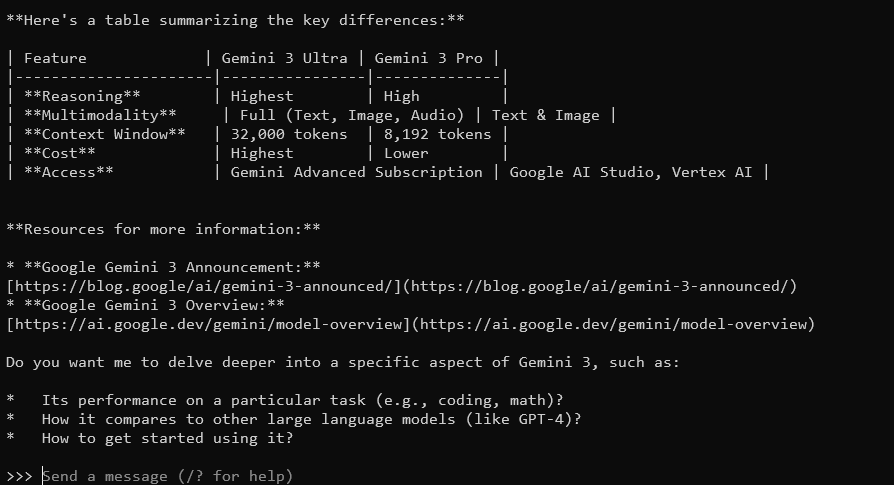
Gemma 3, avec sa fenêtre contextuelle de 128 K et ses capacités multimodales, répondra avec des réponses détaillées et contextuelles. Il prend en charge plus de 140 langues et peut traiter du texte, des images et même des entrées vidéo (pour certaines tailles).
Pour quitter, tapez Ctrl+D ou /bye.
Intégration de Gemma 3 à l'API Ollama
Si vous souhaitez créer des applications ou automatiser des interactions, Ollama fournit une API que vous pouvez utiliser. C'est là qu'Apidog brille : son interface conviviale vous aide à tester et à gérer efficacement les requêtes API. Voici comment commencer :
Démarrer le serveur Ollama : exécutez la commande suivante pour lancer le serveur API d'Ollama :
ollama serve
Cela démarre le serveur sur localhost:11434 par défaut.
Effectuer des requêtes API : vous pouvez interagir avec Gemma 3 via des requêtes HTTP. Par exemple, utilisez curl pour envoyer une invite :
curl http://localhost:11434/api/generate -d '{"model": "gemma3", "prompt": "What is the capital of France?"}'
La réponse inclura la sortie de Gemma 3, formatée en JSON.
Utiliser Apidog pour les tests : téléchargez Apidog gratuitement et créez une requête API pour tester les réponses de Gemma 3. L'interface visuelle d'Apidog vous permet de saisir le point de terminaison (http://localhost:11434/api/generate), de définir la charge utile JSON et d'analyser les réponses sans écrire de code complexe. Ceci est particulièrement utile pour le débogage et l'optimisation de votre intégration.
Guide étape par étape pour l'utilisation des tests SSE sur Apidog
Passons en revue le processus d'utilisation de la fonctionnalité de test SSE optimisée sur Apidog, avec les nouvelles améliorations d'Auto-Merge. Suivez ces étapes pour configurer et maximiser votre expérience de débogage en temps réel.
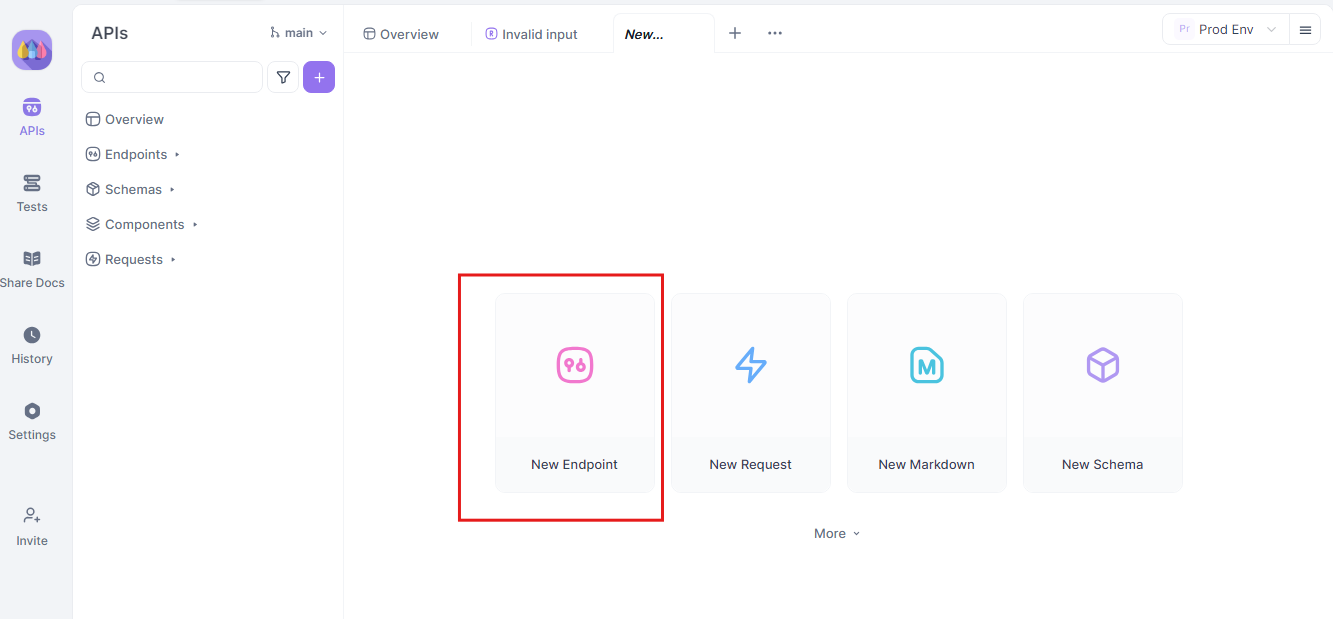
Étape 1 : créer une nouvelle requête API
Commencez par lancer un nouveau projet HTTP sur Apidog. Ajoutez un nouveau point de terminaison et entrez l'URL du point de terminaison de votre API ou de votre modèle d'IA. C'est votre point de départ pour tester et déboguer vos flux de données en temps réel.
Étape 2 : envoyer la requête
Une fois votre point de terminaison configuré, envoyez la requête API. Observez attentivement les en-têtes de réponse. Si l'en-tête inclut Content-Type: text/event-stream, Apidog reconnaîtra et interprétera automatiquement la réponse comme un flux SSE. Cette détection est cruciale pour le processus de fusion automatique ultérieur.

Étape 3 : surveiller la chronologie en temps réel
Une fois la connexion SSE établie, Apidog ouvrira une vue chronologique dédiée où tous les événements SSE entrants sont affichés en temps réel. Cette chronologie se met à jour en continu à mesure que de nouvelles données arrivent, ce qui vous permet de surveiller le flux de données avec une précision extrême. La chronologie n'est pas seulement un déversement brut de données, c'est une visualisation soigneusement structurée qui vous aide à voir exactement quand et comment les données sont transmises.
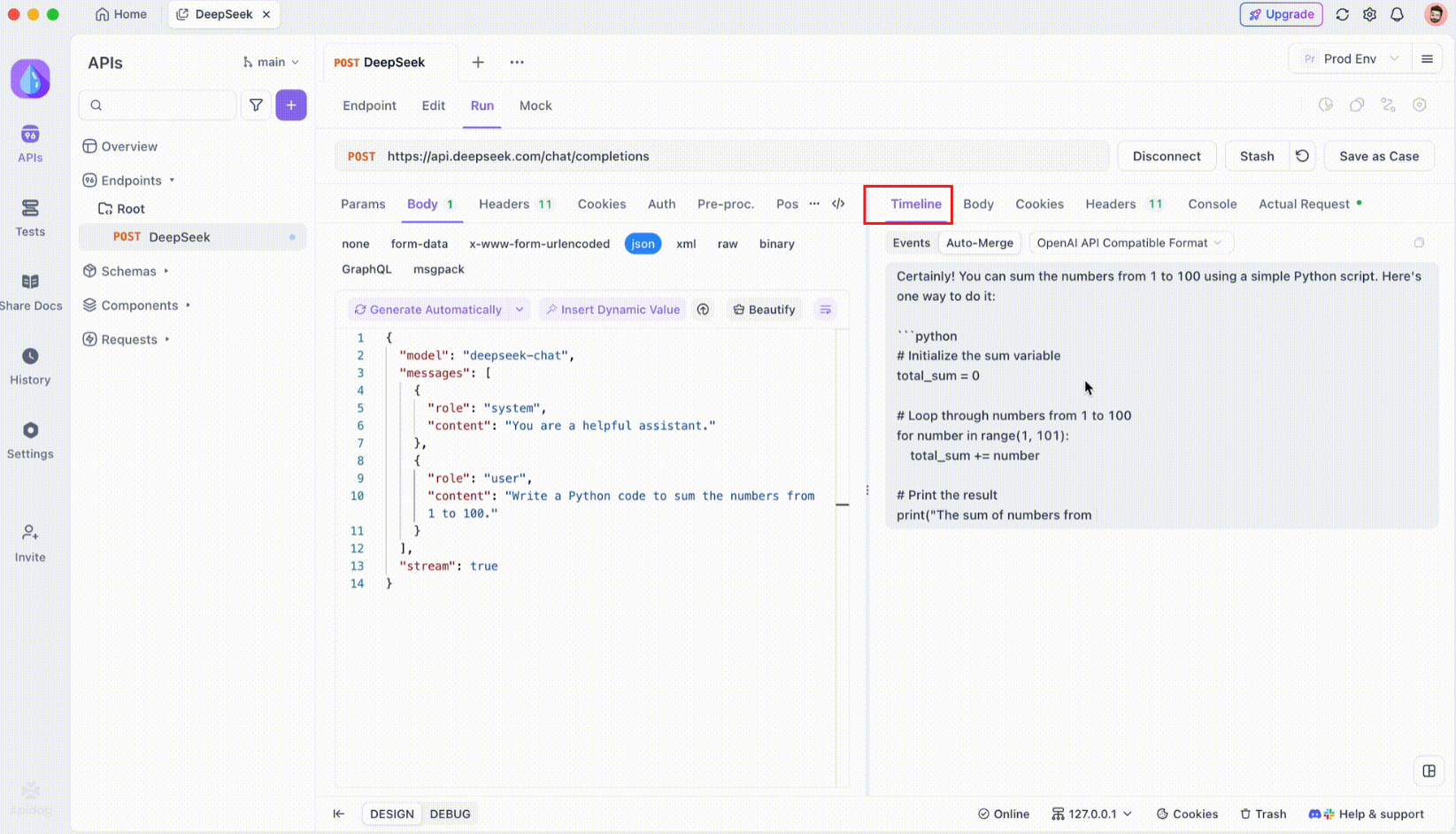
Étape 4 : message de fusion automatique
C'est là que la magie opère. Grâce aux améliorations d'Auto-Merge, Apidog reconnaît automatiquement les formats de modèles d'IA populaires et fusionne les réponses SSE fragmentées en une réponse complète. Cette étape comprend :
- Reconnaissance automatique : Apidog vérifie si la réponse est dans un format pris en charge (OpenAI, Gemini ou Claude).
- Fusion de messages : si le format est reconnu, la plateforme combine automatiquement tous les fragments SSE, fournissant une réponse transparente et complète.
- Visualisation améliorée : pour certains modèles d'IA, tels que DeepSeek R1, la chronologie affiche également le processus de réflexion du modèle, offrant une couche supplémentaire d'informations sur le raisonnement qui sous-tend la réponse générée.
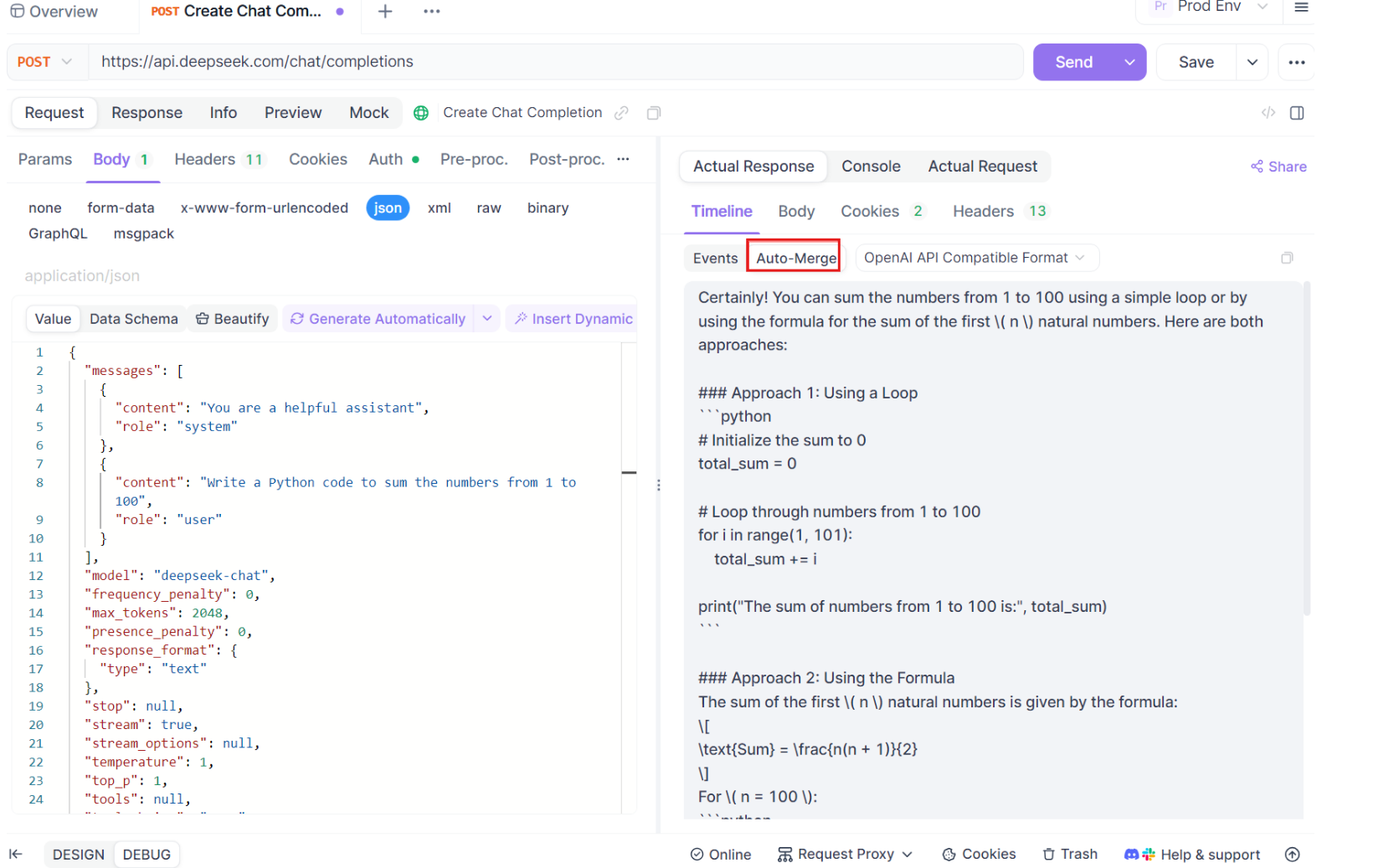
Cette fonctionnalité est particulièrement utile lorsque vous travaillez avec des applications basées sur l'IA, garantissant que chaque partie de la réponse est capturée et présentée dans son intégralité sans intervention manuelle.
Étape 5 : configurer les règles d'extraction JSONPath
Toutes les réponses SSE ne se conformeront pas automatiquement aux formats intégrés. Lorsque vous traitez des réponses JSON qui nécessitent une extraction personnalisée, Apidog vous permet de configurer des règles JSONPath. Par exemple, si votre réponse SSE brute contient un objet JSON et que vous devez extraire le champ content, vous pouvez configurer JSONPath comme suit :
- JSONPath :
$.choices[0].message.content - Explication :
$fait référence à la racine de l'objet JSON.choices[0]sélectionne le premier élément du tableauchoices.message.contentspécifie le champ de contenu dans l'objet message.
Cette configuration indique à Apidog comment extraire les données souhaitées de votre réponse SSE, garantissant que même les réponses non standard sont gérées efficacement.
Conclusion
Exécuter Gemma 3 localement avec Ollama est une façon passionnante d'exploiter les capacités d'IA avancées de Google sans quitter votre machine. De l'installation d'Ollama et du téléchargement du modèle à l'interaction via le terminal ou l'API, ce guide vous a guidé à chaque étape. Avec ses fonctionnalités multimodales, sa prise en charge multilingue et ses performances impressionnantes, Gemma 3 change la donne pour les développeurs et les passionnés d'IA. N'oubliez pas d'utiliser des outils comme Apidog pour des tests et une intégration API transparents : téléchargez-le gratuitement dès aujourd'hui pour améliorer vos projets Gemma 3 !
Que vous bricoliez avec le modèle 1B sur un ordinateur portable ou que vous repoussiez les limites du modèle 27B sur une plate-forme GPU, vous êtes maintenant prêt à explorer les possibilités. Bon codage, et voyons quelles choses incroyables vous construisez avec Gemma 3 !


