
Les développeurs et les passionnés d'IA recherchent constamment des modèles efficaces qui fonctionnent bien sans exiger de ressources massives. Google présente Gemma 3 270M, un modèle linguistique compact doté de 270 millions de paramètres. Ce modèle se distingue comme le plus petit de la famille Gemma 3, optimisé pour les tâches sur appareil. Vous bénéficiez de capacités de génération de texte, de réponse aux questions, de résumé et de raisonnement, tout en gardant les opérations locales.
Gemma 3 270M prend en charge une longueur de contexte de 32 000 jetons, ce qui lui permet de gérer efficacement des entrées substantielles. De plus, il intègre des techniques de quantification comme le Q4_0 Quantization Aware Training (QAT), réduisant les besoins en ressources sans sacrifier la qualité. En conséquence, vous obtenez des performances proches des modèles à pleine précision, mais avec des exigences de mémoire et de calcul moindres.
Cependant, ce qui rend Gemma 3 270M particulièrement attrayant réside dans son accessibilité. Vous l'exécutez sur du matériel standard, y compris des ordinateurs portables ou même des appareils mobiles, favorisant la confidentialité et les applications à faible latence. Ensuite, examinez comment ce modèle s'inscrit dans les tendances plus larges du développement de l'IA, où l'efficacité stimule l'innovation.
Comprendre l'architecture de Gemma 3 270M
Google construit Gemma 3 270M sur une architecture basée sur des transformeurs, comprenant 170 millions de paramètres pour les embeddings avec un vocabulaire de 256 000 jetons et 100 millions pour les blocs de transformeurs. Cette configuration permet un support multilingue et la gestion de tâches de niche. Vous bénéficiez de techniques telles que la quantification INT4, les embeddings de position rotatifs et l'attention de requête groupée, qui améliorent la vitesse d'inférence et la légèreté.
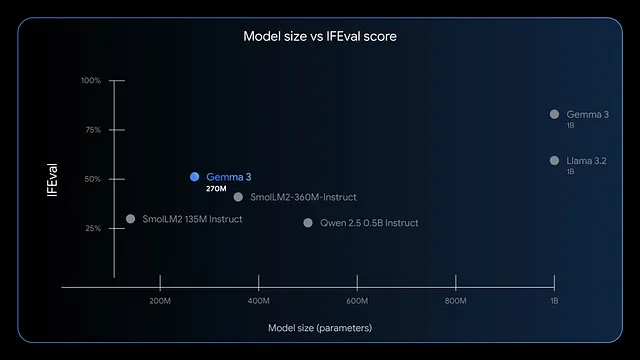
De plus, le modèle excelle dans le suivi des instructions et l'extraction de données. Les benchmarks montrent des scores F1 élevés sur IFEval, indiquant de solides performances dans les tâches d'évaluation. Comparé à des modèles plus grands comme GPT-4 ou Phi-3 Mini, Gemma 3 270M privilégie l'efficacité, utilisant moins de 200 Mo en mode 4 bits sur des appareils comme l'Apple M4 Max.
Par conséquent, vous le déployez pour des scénarios exigeant des réponses rapides, tels que l'analyse de sentiment en temps réel ou l'extraction d'entités de soins de santé. Pourtant, sa petite taille ne limite pas la créativité ; vous l'appliquez à l'écriture créative ou aux contrôles de conformité financière. À l'avenir, évaluez les avantages de l'exécution de ce modèle localement.
Avantages de l'exécution locale de Gemma 3 270M
Vous améliorez la confidentialité en gardant les données sur votre appareil, évitant les transmissions cloud qui risquent une exposition. Gemma 3 270M réduit la latence, fournissant des réponses en millisecondes plutôt qu'en secondes. De plus, il réduit les coûts puisque vous évitez les frais d'abonnement pour les API basées sur le cloud.
De plus, l'efficacité énergétique du modèle se distingue. Il ne consomme que 0,75 % de la batterie d'un Pixel 9 Pro pour 25 conversations en mode quantifié INT4. Cette caractéristique convient au calcul mobile et en périphérie, où l'énergie est importante. Vous personnalisez également facilement le modèle par fine-tuning avec des outils comme LoRA, nécessitant un minimum de données.
Néanmoins, l'exécution locale donne du pouvoir aux petites équipes ou aux développeurs individuels. Vous expérimentez librement, itérant sur des applications comme le routage de requêtes e-commerce ou la structuration de textes juridiques. Au fur et à mesure que vous avancez, vérifiez si votre système répond aux exigences.
Exigences système pour l'inférence de Gemma 3 270M
Gemma 3 270M exige un matériel modeste, le rendant accessible. Pour l'inférence uniquement CPU, vous avez besoin d'au moins 4 Go de RAM et d'un processeur moderne comme un Intel Core i5 ou équivalent. Cependant, l'accélération GPU améliore la vitesse ; une carte NVIDIA avec 2 Go de VRAM suffit pour les versions quantifiées.
Spécifiquement, en mode 4 bits, le modèle tient dans 200 Mo de mémoire, permettant des exécutions sur des appareils avec des ressources limitées. Les utilisateurs de puces Apple bénéficient de MLX-LM, atteignant plus de 650 jetons par seconde sur un M4 Max. Pour le fine-tuning, allouez 8 Go de RAM et un GPU avec 4 Go de VRAM pour gérer efficacement les petits ensembles de données.
Il est important de noter que les systèmes d'exploitation comme Windows, macOS ou Linux fonctionnent, mais assurez-vous d'avoir Python 3.10+ pour la compatibilité des bibliothèques. Le stockage nécessite environ 1 Go pour les fichiers du modèle. Avec ces éléments en place, vous installez et exécutez sans problème. Maintenant, explorez les méthodes d'installation.
Choisir le bon outil pour exécuter Gemma 3 270M localement
Plusieurs frameworks prennent en charge Gemma 3 270M, chacun offrant des atouts uniques. Hugging Face Transformers offre une flexibilité pour le scriptage Python et l'intégration. LM Studio offre une interface conviviale pour la gestion des modèles.
De plus, llama.cpp permet une inférence efficace basée sur C++, parfaite pour l'optimisation de bas niveau. Pour les appareils Apple, MLX optimise les performances sur les puces de la série M. Vous choisissez en fonction de votre expertise ; les débutants préfèrent LM Studio, tandis que les développeurs se tournent vers Transformers.
Ainsi, ces outils démocratisent l'accès. Dans les sections suivantes, suivez des guides étape par étape pour les méthodes populaires.
Guide étape par étape : Exécuter Gemma 3 270M avec Hugging Face Transformers
Vous commencez par installer les bibliothèques nécessaires. Ouvrez votre terminal et exécutez :
pip install transformers torch
Cette commande récupère Transformers et PyTorch. Ensuite, importez les composants dans un script Python :
from transformers import AutoTokenizer, AutoModelForCausalLM
Chargez le modèle et le tokenizer :
model_name = "google/gemma-3-270m"
tokenizer = AutoTokenizer.from_pretrained(model_name)
model = AutoModelForCausalLM.from_pretrained(model_name, device_map="auto")
Le device_map="auto" place le modèle sur le GPU si disponible. Préparez votre entrée :
input_text = "Explain quantum computing in simple terms."
inputs = tokenizer(input_text, return_tensors="pt").to(model.device)
Générez la sortie :
outputs = model.generate(**inputs, max_new_tokens=200)
response = tokenizer.decode(outputs[0], skip_special_tokens=True)
print(response)
Cela produit une explication cohérente. Pour optimiser, ajoutez la quantification :
from transformers import BitsAndBytesConfig
quant_config = BitsAndBytesConfig(load_in_4bit=True)
model = AutoModelForCausalLM.from_pretrained(model_name, quantization_config=quant_config)
La quantification réduit l'utilisation de la mémoire. Vous gérez les erreurs en vous assurant de la connexion Hugging Face pour les modèles à accès restreint :
from huggingface_hub import login
login(token="your_hf_token")
Obtenez le jeton depuis votre compte Hugging Face. Avec cette configuration, vous exécutez des inférences de manière répétée. Cependant, pour les utilisateurs non-Python, considérez LM Studio ensuite.
Guide étape par étape : Exécuter Gemma 3 270M avec LM Studio
LM Studio fournit une interface intuitive. Téléchargez-le depuis lmstudio.ai et installez-le.
Lancez l'application, puis recherchez "gemma-3-270m" dans le hub de modèles.
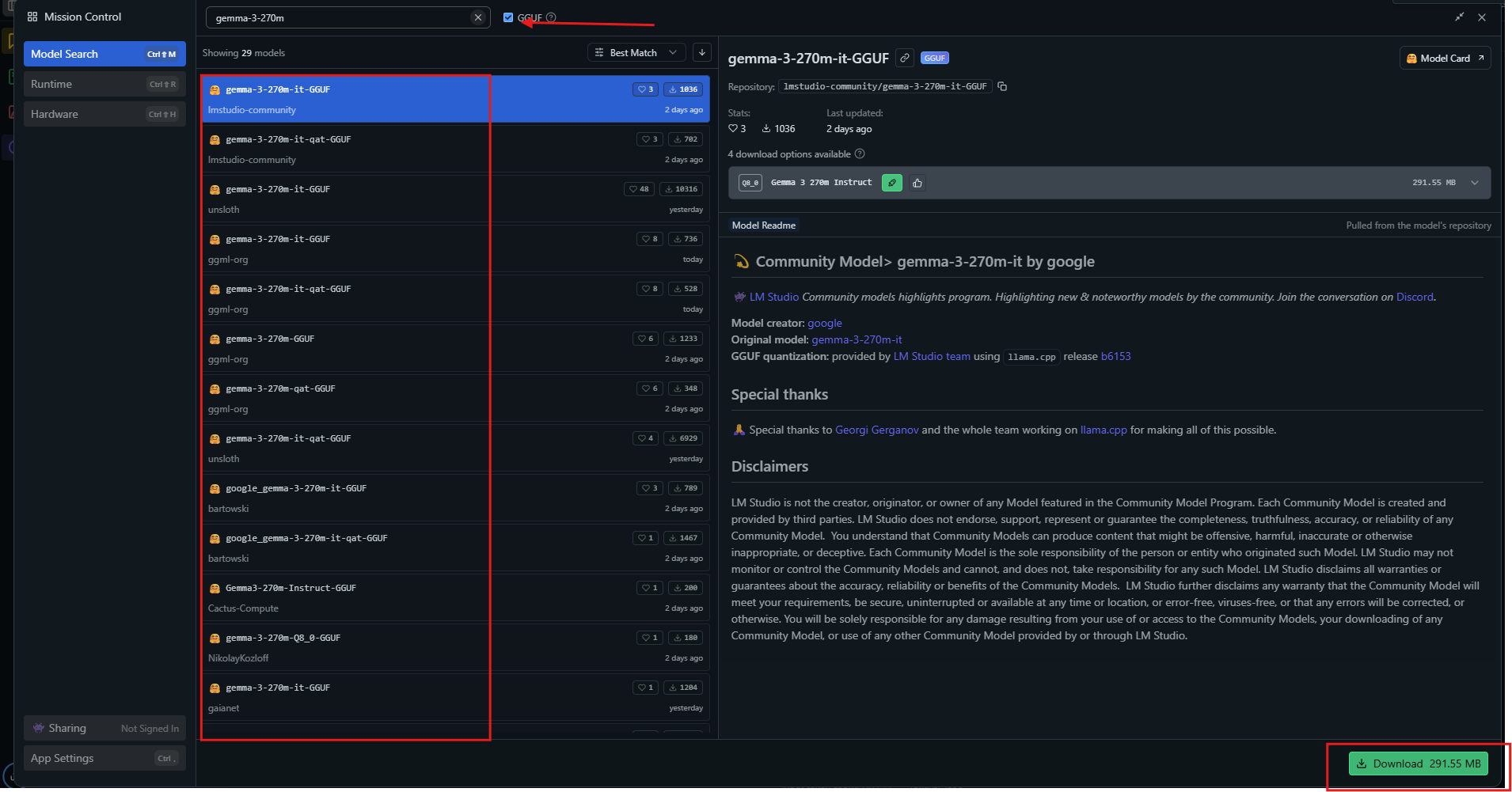
Sélectionnez une variante quantifiée comme Q4_0 et téléchargez-la. Une fois prêt, chargez le modèle depuis la barre latérale. Ajustez les paramètres : définissez le contexte à 32k, la température à 1.0.
Saisissez une invite dans la fenêtre de chat et appuyez sur envoyer. LM Studio affiche les réponses avec les vitesses de jetons. Exportez les chats ou effectuez un fine-tuning via les outils intégrés.
Pour une utilisation avancée, activez le déchargement GPU dans les paramètres. LM Studio sélectionne automatiquement les sources optimales, assurant la compatibilité. Cette méthode convient aux apprenants visuels. De plus, explorez llama.cpp pour des ajustements de performance.
Guide étape par étape : Exécuter Gemma 3 270M avec llama.cpp
llama.cpp offre une inférence à haute efficacité. Clonez le dépôt :
git clone https://github.com/ggerganov/llama.cpp
Compilez-le :
make -j
Téléchargez les fichiers GGUF depuis Hugging Face :
huggingface-cli download unsloth/gemma-3-270m-it-GGUF --include "*.gguf"
Exécutez l'inférence :
./llama-cli -m gemma-3-270m-it-Q4_K_M.gguf -p "Build a simple AI app."
Spécifiez des paramètres comme --n-gpu-layers 999 pour une utilisation complète du GPU. llama.cpp prend en charge les niveaux de quantification, équilibrant vitesse et précision. Vous compilez avec CUDA pour les GPU NVIDIA :
make GGML_CUDA=1
Cela accélère le traitement. llama.cpp excelle dans les systèmes embarqués. Maintenant, appliquez le modèle dans des exemples pratiques.
Exemples pratiques d'utilisation locale de Gemma 3 270M
Vous créez un analyseur de sentiment. Saisissez les avis clients, et le modèle les classifie comme positifs ou négatifs. Scripting en Python :
prompt = "Classify: This product is amazing!"
inputs = tokenizer(prompt, return_tensors="pt")
outputs = model.generate(**inputs)
print(tokenizer.decode(outputs[0]))
Gemma 3 270M renvoie "Positif". Étendez au résumé :
text = "Long article here..."
prompt = f"Summarize: {text}"
# Generate summary
Il condense le contenu efficacement. Pour la réponse aux questions, interrogez :
"Qu'est-ce qui cause le changement climatique ?"
Le modèle explique les gaz à effet de serre. Dans le domaine de la santé, extrayez les entités des notes. Ces utilisations démontrent la polyvalence. De plus, affinez pour la spécialisation.
Fine-tuning local de Gemma 3 270M
Le fine-tuning adapte le modèle. Utilisez la bibliothèque PEFT de Hugging Face :
pip install peft
Chargez avec la configuration LoRA :
from peft import LoraConfig, get_peft_model
lora_config = LoraConfig(r=16, lora_alpha=32, target_modules=["q_proj", "v_proj"])
model = get_peft_model(model, lora_config)
Préparez un jeu de données, puis entraînez :
from transformers import Trainer, TrainingArguments
trainer = Trainer(model=model, args=TrainingArguments(output_dir="./results"))
trainer.train()
LoRA nécessite peu de données, se terminant rapidement sur du matériel modeste. Enregistrez et rechargez l'adaptateur. Cela améliore les performances sur des tâches personnalisées comme la prédiction de coups d'échecs. Cependant, surveillez le surapprentissage.
Conseils d'optimisation des performances pour Gemma 3 270M
Vous maximisez la vitesse en quantifiant en 4 bits ou 8 bits. Utilisez le traitement par lots pour plusieurs inférences. Définissez la température à 1.0, top_k=64, top_p=0.95 comme recommandé.
Sur les GPU, activez la précision mixte. Pour les contextes longs, gérez attentivement le cache KV. Surveillez la VRAM avec des outils comme nvidia-smi. Mettez à jour régulièrement les bibliothèques pour les optimisations.
Par conséquent, ces ajustements produisent plus de 130 jetons par seconde sur du matériel approprié. Évitez les pièges courants comme les jetons BOS doubles dans les invites. Avec de la pratique, vous obtenez des exécutions efficaces.
Conclusion
Vous possédez maintenant les connaissances nécessaires pour exécuter Gemma 3 270M localement. De la configuration à l'optimisation, chaque étape développe les capacités. Expérimentez, affinez et déployez pour réaliser son potentiel. De petits modèles comme celui-ci ont un impact majeur sur l'accessibilité de l'IA.