
Si vous avez toujours souhaité pouvoir poser des questions directement à un PDF ou à un manuel technique, ce guide est fait pour vous. Aujourd'hui, nous allons construire un système de Génération Augmentée par Récupération (RAG) en utilisant DeepSeek R1, une centrale de raisonnement open-source, et Ollama, le framework léger pour exécuter des modèles d'IA locaux.
Prêt à Booster Vos Tests API ? N'oubliez pas de consulter Apidog ! Apidog agit comme une plateforme unique pour créer, gérer et exécuter des tests et des serveurs simulés, vous permettant d'identifier les goulots d'étranglement et de maintenir la fiabilité de vos API.
Au lieu de jongler avec plusieurs outils ou d'écrire des scripts volumineux, vous pouvez automatiser des parties critiques de votre flux de travail, obtenir des pipelines CI/CD fluides et passer plus de temps à peaufiner les fonctionnalités de votre produit.
Si cela ressemble à quelque chose qui pourrait vous simplifier la vie, essayez Apidog !
Dans cet article, nous allons explorer comment DeepSeek R1—un modèle qui rivalise avec les performances d'o1 d'OpenAI mais coûte 95 % de moins—peut suralimenter vos systèmes RAG. Décomposons pourquoi les développeurs affluent vers cette technologie et comment vous pouvez construire votre propre pipeline RAG avec elle.
Combien coûte ce système RAG local ?
| Component | Cost |
|---|---|
| DeepSeek R1 1.5B | Free |
| Ollama | Free |
| 16GB RAM PC | $0 |
Le modèle 1.5B de DeepSeek R1 brille ici car :
- Récupération ciblée : Seuls 3 morceaux de documents alimentent chaque réponse
- Invite stricte : « Je ne sais pas » empêche les hallucinations
- Exécution locale : Zéro latence par rapport aux API cloud
Ce dont vous aurez besoin
Avant de coder, configurons nos boîtes à outils :
1. Ollama
Ollama vous permet d'exécuter des modèles comme DeepSeek R1 localement.
- Télécharger : https://ollama.com/
- Installez, puis ouvrez votre terminal et exécutez :
ollama run deepseek-r1 # For the 7B model (default)
2. Variantes de modèles DeepSeek R1
DeepSeek R1 est disponible en tailles allant de 1,5 B à 671 B de paramètres. Pour cette démo, nous utiliserons le modèle 1,5 B, parfait pour le RAG léger :
ollama run deepseek-r1:1.5b
Conseil de pro : Les modèles plus volumineux comme 70 B offrent un meilleur raisonnement, mais nécessitent plus de RAM. Commencez petit, puis augmentez l'échelle !

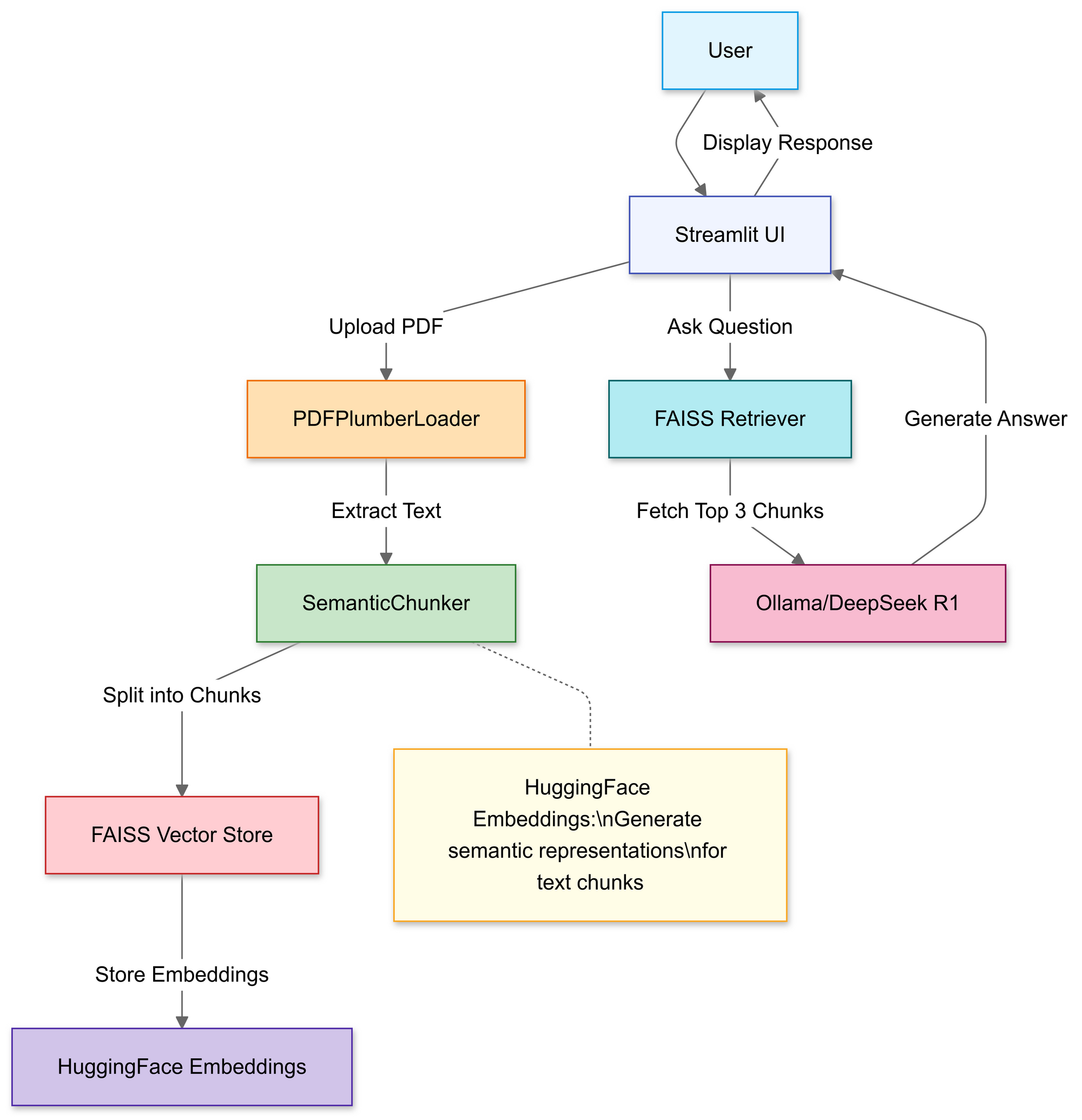
Construction du pipeline RAG : présentation du code
Étape 1 : Importer les bibliothèques
Nous utiliserons :
import streamlit as st
from langchain_community.document_loaders import PDFPlumberLoader
from langchain_experimental.text_splitter import SemanticChunker
from langchain_community.embeddings import HuggingFaceEmbeddings
from langchain_community.vectorstores import FAISS
from langchain_community.llms import Ollama
Étape 2 : Télécharger et traiter les PDF
Dans cette section, vous utilisez le téléchargeur de fichiers de Streamlit pour permettre aux utilisateurs de sélectionner un fichier PDF local.
# Streamlit file uploader
uploaded_file = st.file_uploader("Upload a PDF file", type="pdf")
if uploaded_file:
# Save PDF temporarily
with open("temp.pdf", "wb") as f:
f.write(uploaded_file.getvalue())
# Load PDF text
loader = PDFPlumberLoader("temp.pdf")
docs = loader.load()
Une fois téléchargée, la fonction PDFPlumberLoader extrait le texte du PDF, le préparant pour la prochaine étape du pipeline. Cette approche est pratique car elle prend en charge la lecture du contenu du fichier sans exiger d'analyse manuelle approfondie.
Étape 3 : Diviser les documents de manière stratégique
Nous voulons utiliser le RecursiveCharacterTextSplitter, le code décompose le texte PDF d'origine en segments plus petits (morceaux). Expliquons ici les concepts de bon et de mauvais découpage :
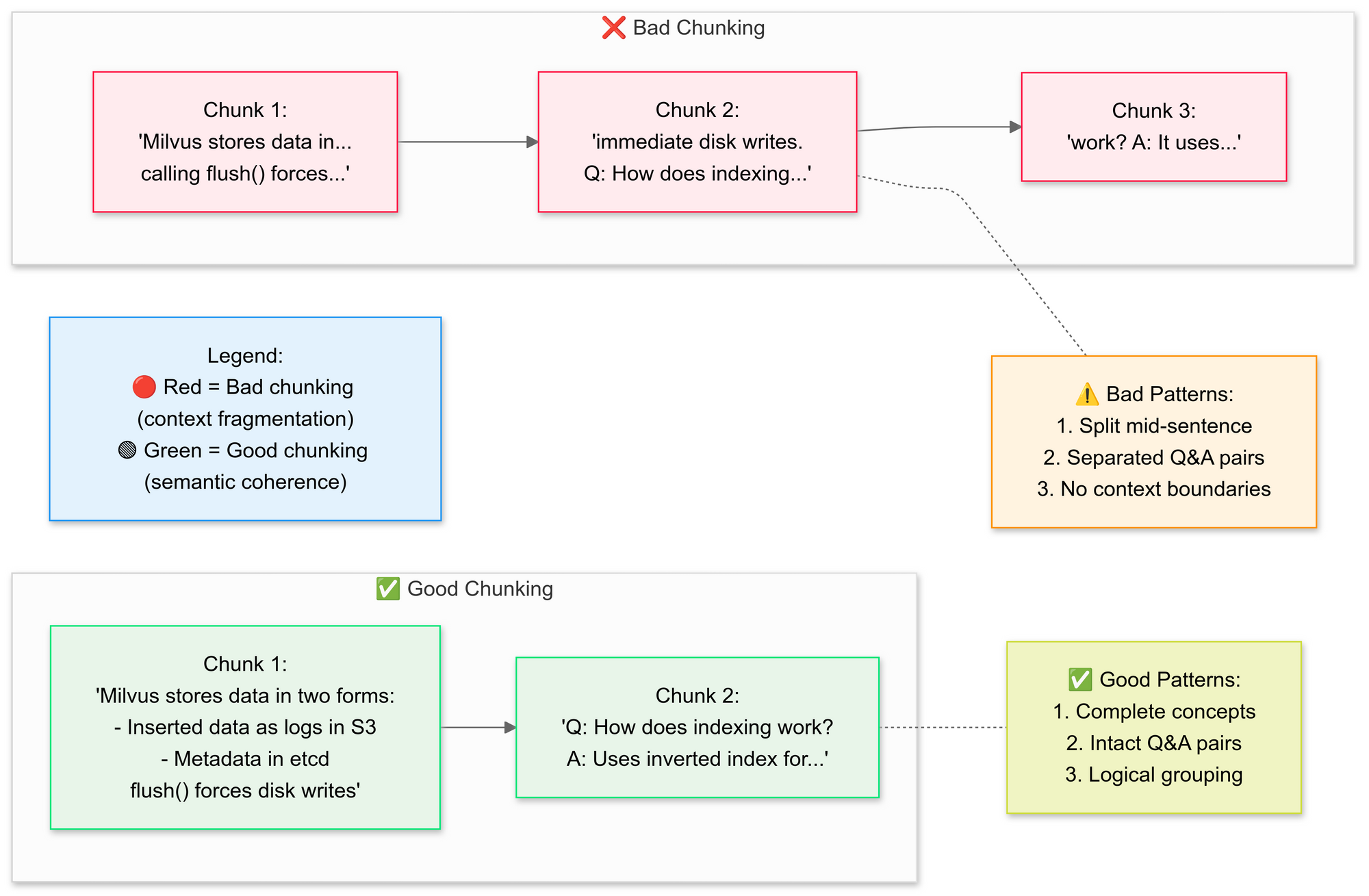
Pourquoi le découpage sémantique ?
- Regroupe les phrases associées (par exemple, « Comment Milvus stocke les données » reste intact)
- Évite de diviser les tableaux ou les diagrammes
# Split text into semantic chunks
text_splitter = SemanticChunker(HuggingFaceEmbeddings())
documents = text_splitter.split_documents(docs)
Cette étape préserve le contexte en chevauchant légèrement les segments, ce qui aide le modèle linguistique à répondre aux questions avec plus de précision. Les petits morceaux de documents bien définis rendent également les recherches plus efficaces et pertinentes.
Étape 4 : Créer une base de connaissances consultable
Après la division, le pipeline génère des intégrations vectorielles pour les segments et les stocke dans un index FAISS.
# Generate embeddings
embeddings = HuggingFaceEmbeddings()
vector_store = FAISS.from_documents(documents, embeddings)
# Connect retriever
retriever = vector_store.as_retriever(search_kwargs={"k": 3}) # Fetch top 3 chunks
Cela transforme le texte en une représentation numérique qui est beaucoup plus facile à interroger. Les requêtes sont ensuite exécutées par rapport à cet index pour trouver les morceaux les plus pertinents contextuellement.
Étape 5 : Configurer DeepSeek R1
Ici, vous instanciez une chaîne RetrievalQA en utilisant Deepseek R1 1.5B comme LLM local.
llm = Ollama(model="deepseek-r1:1.5b") # Our 1.5B parameter model
# Craft the prompt template
prompt = """
1. Use ONLY the context below.
2. If unsure, say "I don’t know".
3. Keep answers under 4 sentences.
Context: {context}
Question: {question}
Answer:
"""
QA_CHAIN_PROMPT = PromptTemplate.from_template(prompt)
Ce modèle force le modèle à baser les réponses sur le contenu de votre PDF. En enveloppant le modèle linguistique avec un récupérateur lié à l'index FAISS, toutes les requêtes effectuées via la chaîne rechercheront le contexte dans le contenu du PDF, ce qui rendra les réponses basées sur le matériel source.
Étape 6 : Assembler la chaîne RAG
Ensuite, vous pouvez lier les étapes de téléchargement, de découpage et de récupération en un pipeline cohérent.
# Chain 1: Generate answers
llm_chain = LLMChain(llm=llm, prompt=QA_CHAIN_PROMPT)
# Chain 2: Combine document chunks
document_prompt = PromptTemplate(
template="Context:\ncontent:{page_content}\nsource:{source}",
input_variables=["page_content", "source"]
)
# Final RAG pipeline
qa = RetrievalQA(
combine_documents_chain=StuffDocumentsChain(
llm_chain=llm_chain,
document_prompt=document_prompt
),
retriever=retriever
)
Il s'agit du cœur de la conception RAG (Retrieval-Augmented Generation), qui fournit au grand modèle linguistique un contexte vérifié au lieu de le faire reposer uniquement sur sa formation interne.
Étape 7 : Lancer l'interface web
Enfin, le code utilise les fonctions d'entrée et d'écriture de texte de Streamlit afin que les utilisateurs puissent taper des questions et afficher les réponses immédiatement.
# Streamlit UI
user_input = st.text_input("Ask your PDF a question:")
if user_input:
with st.spinner("Thinking..."):
response = qa(user_input)["result"]
st.write(response)
Dès que l'utilisateur entre une requête, la chaîne récupère les morceaux les plus pertinents, les introduit dans le modèle linguistique et affiche une réponse. Avec la bibliothèque langchain correctement installée, le code devrait fonctionner maintenant sans déclencher l'erreur de module manquant.
Posez et soumettez des questions et obtenez des réponses instantanées !
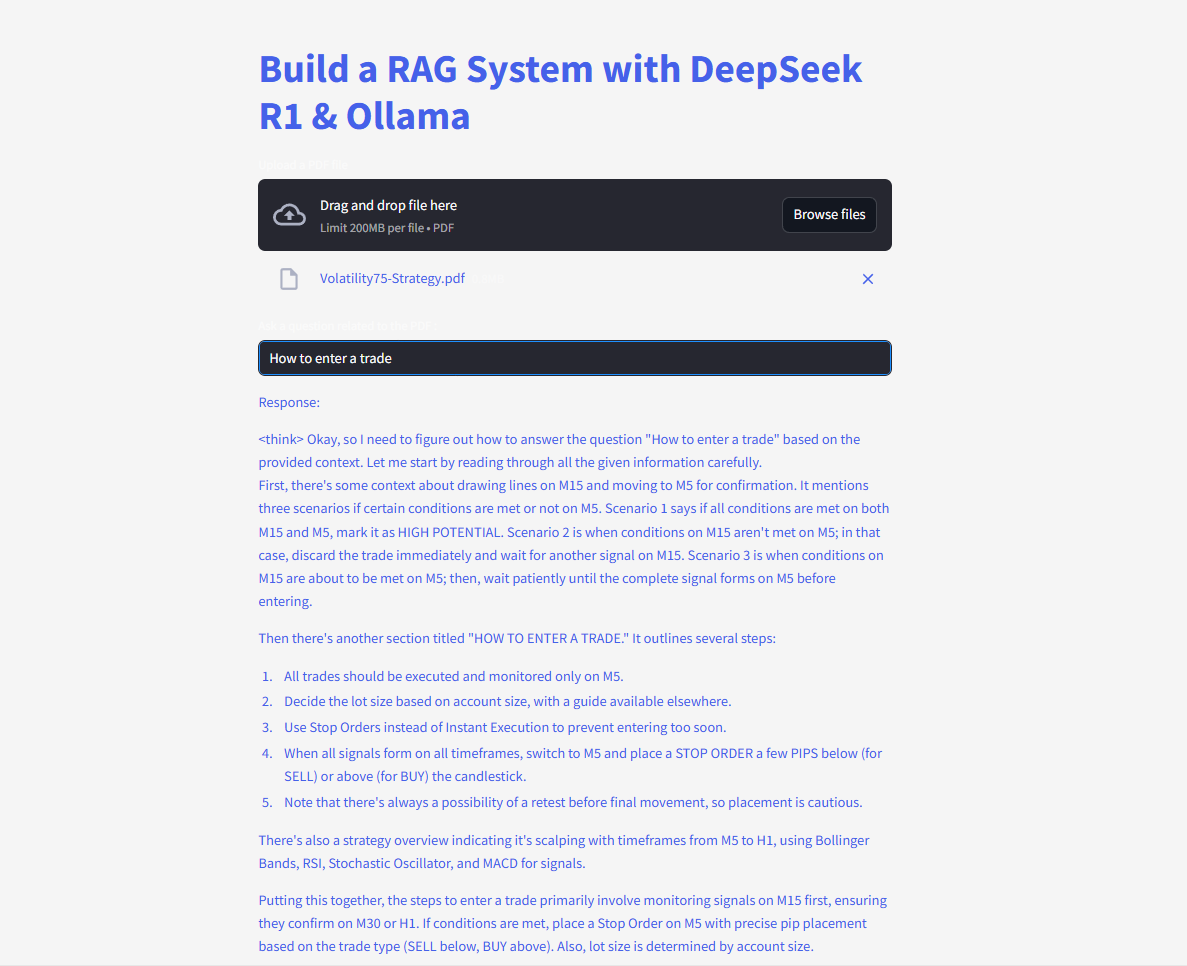
Voici le code complet :
L'avenir du RAG avec DeepSeek
Avec des fonctionnalités telles que la self-vérification et le raisonnement multi-sauts en développement, DeepSeek R1 est prêt à débloquer des applications RAG encore plus avancées. Imaginez une IA qui non seulement répond aux questions, mais débat de sa propre logique—autonomement.


