
```html
Les grands modèles de langage (LLM) comme Qwen3 révolutionnent le paysage de l'IA grâce à leurs impressionnantes capacités en matière de codage, de raisonnement et de compréhension du langage naturel. Développé par l'équipe Qwen chez Alibaba, Qwen3 propose des modèles quantifiés qui permettent un déploiement local efficace, ce qui permet aux développeurs, aux chercheurs et aux passionnés d'exécuter ces puissants modèles sur leur propre matériel. Que vous utilisiez Ollama, LM Studio ou vLLM, ce guide vous expliquera le processus de configuration et d'exécution locale des modèles quantifiés Qwen3.
Dans ce guide technique, nous explorerons le processus de configuration, la sélection des modèles, les méthodes de déploiement et l'intégration de l'API. Commençons.
Que sont les modèles quantifiés Qwen3 ?
Qwen3 est la dernière génération de LLM d'Alibaba, conçue pour des performances élevées sur des tâches telles que le codage, les mathématiques et le raisonnement général. Les modèles quantifiés, tels que ceux aux formats BF16, FP8, GGUF, AWQ et GPTQ, réduisent les exigences de calcul et de mémoire, ce qui les rend idéaux pour un déploiement local sur du matériel grand public.
La famille Qwen3 comprend divers modèles :
- Qwen3-235B-A22B (MoE) : Un modèle de mélange d'experts avec les formats BF16, FP8, GGUF et GPTQ-int4.
- Qwen3-30B-A3B (MoE) : Une autre variante MoE avec des options de quantification similaires.
- Qwen3-32B, 14B, 8B, 4B, 1.7B, 0.6B (Dense) : Modèles denses disponibles aux formats BF16, FP8, GGUF, AWQ et GPTQ-int8.
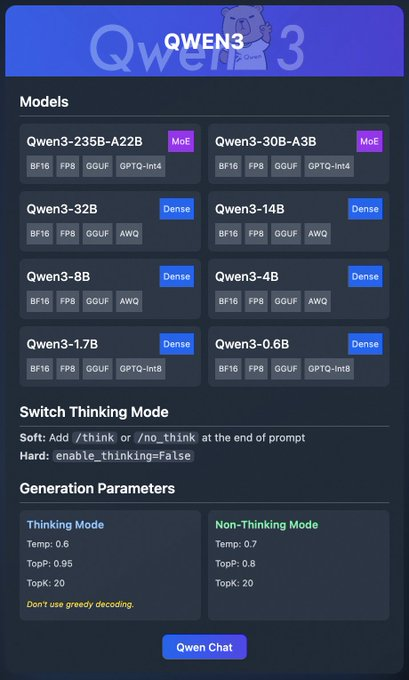
Ces modèles prennent en charge un déploiement flexible via des plateformes telles que Ollama, LM Studio et vLLM, que nous aborderons en détail. De plus, Qwen3 propose des fonctionnalités telles que le « mode de réflexion », qui peut être activé pour un meilleur raisonnement, et des paramètres de génération pour affiner la qualité de la sortie.
Maintenant que nous comprenons les bases, passons aux prérequis pour exécuter Qwen3 localement.
Conditions préalables à l'exécution de Qwen3 localement
Avant de déployer les modèles quantifiés Qwen3, assurez-vous que votre système répond aux exigences suivantes :
Matériel :
- Un processeur ou un GPU moderne (les GPU NVIDIA sont recommandés pour vLLM).
- Au moins 16 Go de RAM pour les modèles plus petits comme Qwen3-4B ; 32 Go ou plus pour les modèles plus volumineux comme Qwen3-32B.
- Stockage suffisant (par exemple, Qwen3-235B-A22B GGUF peut nécessiter ~150 Go).
Logiciel :
- Un système d'exploitation compatible (Windows, macOS ou Linux).
- Python 3.8+ pour les interactions vLLM et API.
- Docker (facultatif, pour vLLM).
- Git pour cloner les référentiels.
Dépendances :
- Installez les bibliothèques requises telles que
torch,transformersetvllm(pour vLLM). - Téléchargez les binaires Ollama ou LM Studio sur leurs sites Web officiels.
Avec ces prérequis en place, passons au téléchargement des modèles quantifiés Qwen3.
Étape 1 : Télécharger les modèles quantifiés Qwen3
Tout d'abord, vous devez télécharger les modèles quantifiés à partir de sources fiables. L'équipe Qwen fournit des modèles Qwen3 sur Hugging Face et ModelScope
- Hugging Face : Collection Qwen3
- ModelScope : Collection Qwen3
Comment télécharger depuis Hugging Face
- Visitez la collection Hugging Face Qwen3.
- Sélectionnez un modèle, tel que Qwen3-4B au format GGUF pour un déploiement léger.
- Cliquez sur le bouton « Télécharger » ou utilisez la commande
git clonepour récupérer les fichiers du modèle :
git clone https://huggingface.co/Qwen/Qwen3-4B-GGUF
- Stockez les fichiers du modèle dans un répertoire, tel que
/models/qwen3-4b-gguf.
Comment télécharger depuis ModelScope
- Accédez à la collection ModelScope Qwen3.
- Choisissez le modèle et le format de quantification souhaités (par exemple, AWQ ou GPTQ).
- Téléchargez les fichiers manuellement ou utilisez leur API pour un accès programmatique.
Une fois les modèles téléchargés, explorons comment les déployer à l'aide d'Ollama.
Étape 2 : Déployer Qwen3 à l'aide d'Ollama
Ollama fournit un moyen convivial d'exécuter des LLM localement avec une configuration minimale. Il prend en charge le format GGUF de Qwen3, ce qui le rend idéal pour les débutants.
Installer Ollama
- Visitez le site Web officiel d'Ollama et téléchargez le binaire pour votre système d'exploitation.
- Installez Ollama en exécutant le programme d'installation ou en suivant les instructions de la ligne de commande :
curl -fsSL https://ollama.com/install.sh | sh
- Vérifiez l'installation :
ollama --version
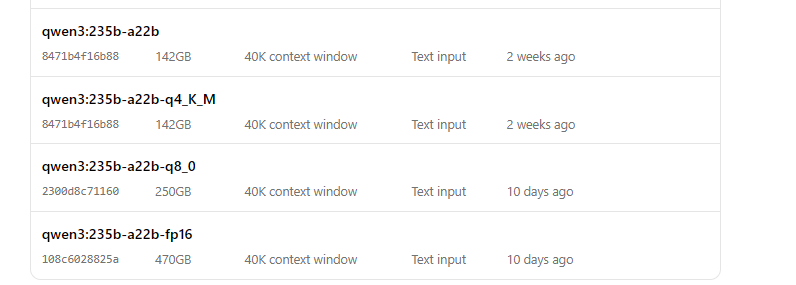
Exécuter Qwen3 avec Ollama
- Démarrez le modèle :
ollama run qwen3:235b-a22b-q8_0- Une fois le modèle en cours d'exécution, vous pouvez interagir avec lui via la ligne de commande :
>>> Bonjour, comment puis-je vous aider aujourd'hui ?
Ollama fournit également un point de terminaison API local (généralement http://localhost:11434) pour un accès programmatique, que nous testerons plus tard à l'aide d'Apidog.
Ensuite, explorons comment utiliser LM Studio pour exécuter Qwen3.
Étape 3 : Déployer Qwen3 à l'aide de LM Studio
LM Studio est un autre outil populaire pour exécuter des LLM localement, offrant une interface graphique pour la gestion des modèles.
Installer LM Studio
- Téléchargez LM Studio sur son site Web officiel.
- Installez l'application en suivant les instructions à l'écran.
- Lancez LM Studio et assurez-vous qu'il est en cours d'exécution.
Charger Qwen3 dans LM Studio
Dans LM Studio, accédez à la section « Modèles locaux ».
Cliquez sur « Ajouter un modèle » et recherchez le modèle pour le télécharger :
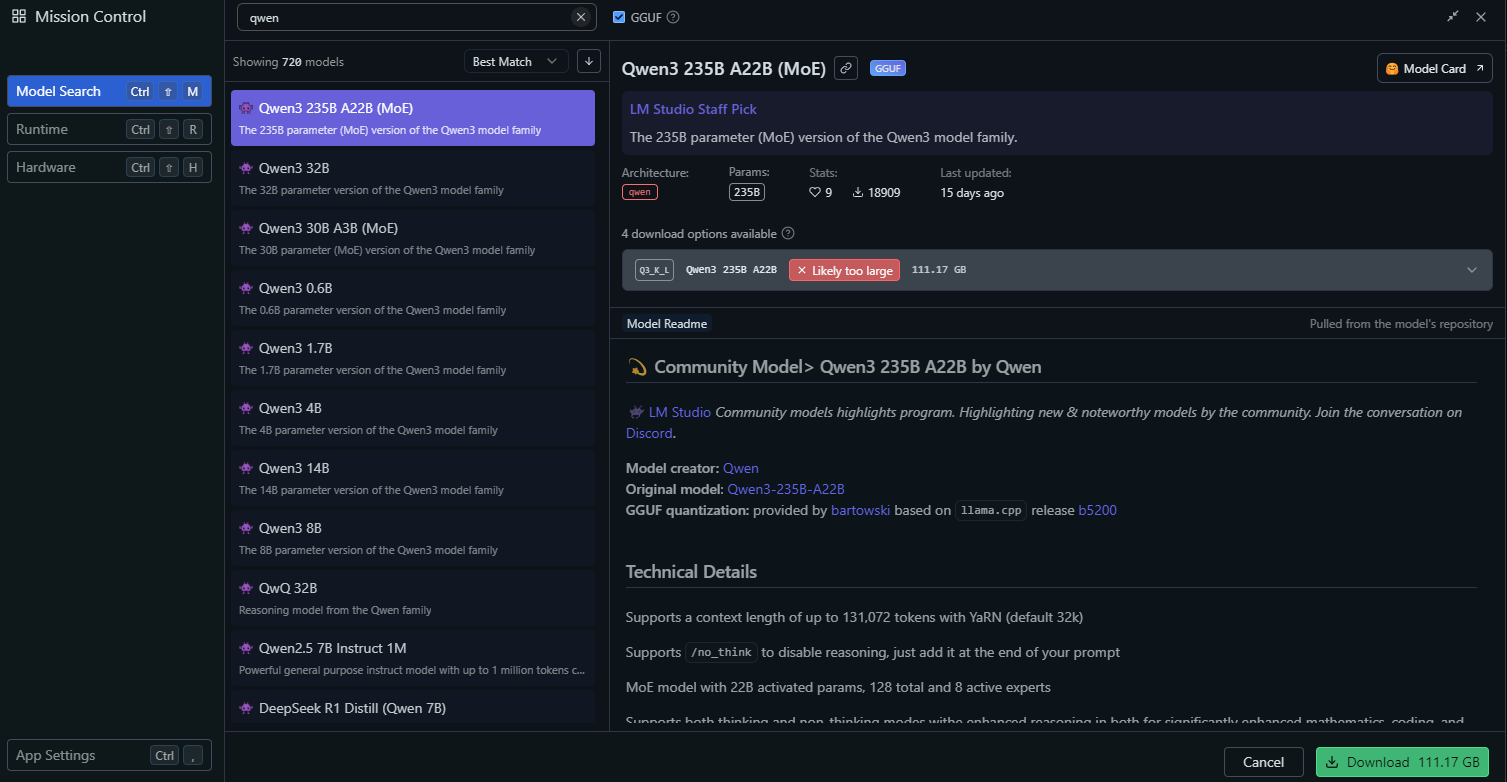
Configurez les paramètres du modèle, tels que :
- Température : 0,6
- Top-P : 0,95
- Top-K : 20
Ces paramètres correspondent aux paramètres recommandés du mode de réflexion de Qwen3.
Démarrez le serveur de modèles en cliquant sur « Démarrer le serveur ». LM Studio fournira un point de terminaison d'API local (par exemple, http://localhost:1234).
Interagir avec Qwen3 dans LM Studio
- Utilisez l'interface de discussion intégrée de LM Studio pour tester le modèle.
- Vous pouvez également accéder au modèle via son point de terminaison d'API, que nous explorerons dans la section de test de l'API.
Avec LM Studio configuré, passons à une méthode de déploiement plus avancée à l'aide de vLLM.
Étape 4 : Déployer Qwen3 à l'aide de vLLM
vLLM est une solution de service haute performance optimisée pour les LLM, prenant en charge les modèles quantifiés FP8 et AWQ de Qwen3. Il est idéal pour les développeurs qui créent des applications robustes.
Installer vLLM
- Assurez-vous que Python 3.8+ est installé sur votre système.
- Installez vLLM à l'aide de pip :
pip install vllm
- Vérifiez l'installation :
python -c "import vllm; print(vllm.__version__)"
Exécuter Qwen3 avec vLLM
Démarrez un serveur vLLM avec votre modèle Qwen3
# Charger et exécuter le modèle :
vllm serve "Qwen/Qwen3-235B-A22B"L'indicateur --enable-thinking=False désactive le mode de réflexion de Qwen3.
Une fois le serveur démarré, il fournira un point de terminaison API à http://localhost:8000.
Configurer vLLM pour des performances optimales
vLLM prend en charge des configurations avancées, telles que :
- Parallélisme tensoriel : Ajustez
--tensor-parallel-sizeen fonction de votre configuration GPU. - Longueur du contexte : Qwen3 prend en charge jusqu'à 32 768 jetons, qui peuvent être définis via
--max-model-len 32768. - Paramètres de génération : Utilisez l'API pour définir
temperature,top_pettop_k(par exemple, 0,7, 0,8, 20 pour le mode sans réflexion).
Avec vLLM en cours d'exécution, testons le point de terminaison de l'API à l'aide d'Apidog.
Étape 5 : Tester l'API Qwen3 avec Apidog
Apidog est un outil puissant pour tester les points de terminaison d'API, ce qui le rend parfait pour interagir avec votre modèle Qwen3 déployé localement.
Configurer Apidog
- Téléchargez et installez Apidog à partir du site Web officiel.
- Lancez Apidog et créez un nouveau projet.
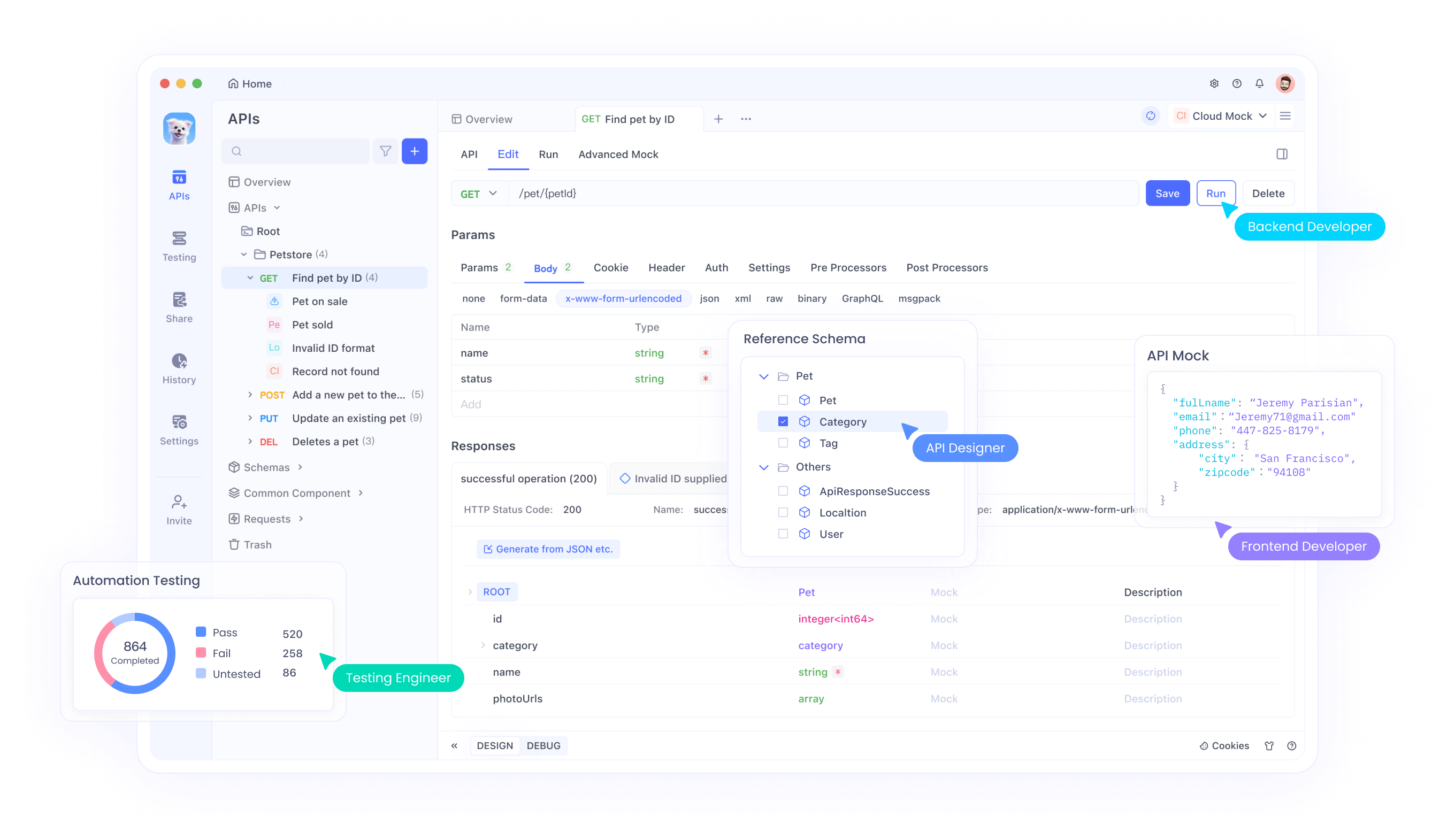
Tester l'API Ollama
- Créez une nouvelle requête d'API dans Apidog.
- Définissez le point de terminaison sur
http://localhost:11434/api/generate. - Configurez la requête :
- Méthode : POST
- Corps (JSON) :
{
"model": "qwen3-4b",
"prompt": "Bonjour, comment puis-je vous aider aujourd'hui ?",
"temperature": 0.6,
"top_p": 0.95,
"top_k": 20
}
- Envoyez la requête et vérifiez la réponse.
Tester l'API vLLM
- Créez une autre requête d'API dans Apidog.
- Définissez le point de terminaison sur
http://localhost:8000/v1/completions. - Configurez la requête :
- Méthode : POST
- Corps (JSON) :
{
"model": "qwen3-4b-awq",
"prompt": "Écrivez un script Python pour calculer la factorielle.",
"max_tokens": 512,
"temperature": 0.7,
"top_p": 0.8,
"top_k": 20
}
- Envoyez la requête et vérifiez la sortie.
Apidog facilite la validation de votre déploiement Qwen3 et garantit le bon fonctionnement de l'API. Maintenant, affinons les performances du modèle.
Étape 6 : Affiner les performances de Qwen3
Pour optimiser les performances de Qwen3, ajustez les paramètres suivants en fonction de votre cas d'utilisation :
Mode de réflexion
Qwen3 prend en charge un « mode de réflexion » pour un raisonnement amélioré, comme le souligne l'image de la publication X. Vous pouvez le contrôler de deux manières :
- Soft Switch : Ajoutez
/thinkou/no_thinkà votre invite.
- Exemple :
Résoudre ce problème mathématique /think.
- Hard Switch : Désactivez complètement la réflexion dans vLLM avec
--enable-thinking=False.
Paramètres de génération
Ajustez les paramètres de génération pour une meilleure qualité de sortie :
- Température : Utilisez 0,6 pour le mode de réflexion ou 0,7 pour le mode sans réflexion.
- Top-P : Définissez sur 0,95 (réflexion) ou 0,8 (sans réflexion).
- Top-K : Utilisez 20 pour les deux modes.
- Évitez le décodage gourmand, comme le recommande l'équipe Qwen.
Expérimentez avec ces paramètres pour obtenir l'équilibre souhaité entre créativité et précision.
Dépannage des problèmes courants
Lors du déploiement de Qwen3, vous pouvez rencontrer des problèmes. Voici des solutions aux problèmes courants :
Le modèle ne se charge pas dans Ollama :
- Assurez-vous que le chemin d'accès au fichier GGUF dans le
Modelfileest correct. - Vérifiez si votre système dispose de suffisamment de mémoire pour charger le modèle.
Erreur de parallélisme tensoriel vLLM :
- Si vous voyez une erreur telle que « output_size n'est pas divisible par weight quantization block_n », réduisez le
--tensor-parallel-size(par exemple, à 4).
La requête API échoue dans Apidog :
- Vérifiez que le serveur (Ollama, LM Studio ou vLLM) est en cours d'exécution.
- Vérifiez l'URL du point de terminaison et la charge utile de la requête.
En résolvant ces problèmes, vous pouvez garantir une expérience de déploiement fluide.
Conclusion
L'exécution des modèles quantifiés Qwen3 localement est un processus simple avec des outils tels que Ollama, LM Studio et vLLM. Que vous soyez un développeur qui crée des applications ou un chercheur qui expérimente des LLM, Qwen3 offre la flexibilité et les performances dont vous avez besoin. En suivant ce guide, vous avez appris à télécharger des modèles depuis Hugging Face et ModelScope, à les déployer à l'aide de divers frameworks et à tester leurs points de terminaison API avec Apidog.
Commencez à explorer Qwen3 dès aujourd'hui et libérez la puissance des LLM locaux pour vos projets !
```


