
L'équipe Qwen d'Alibaba a lancé Qwen3-Coder-Flash, sa dernière variante de modèle de codage qui promet une "génération de code ultra-rapide et précise" avec des spécifications techniques impressionnantes. Cependant, la vraie question que se posent les développeurs est de savoir si ce nouveau modèle peut réellement gérer les défis de codage de niveau entreprise ou s'il ne s'agit que d'une amélioration incrémentale.
Ce qui rend Qwen3-Coder-Flash différent
Comprendre Qwen3-Coder-Flash nécessite d'examiner son architecture et son positionnement au sein de l'écosystème de modèles en expansion d'Alibaba. Ce modèle dispose de 30,5 milliards de paramètres au total, dont 3,3 milliards sont actifs à tout moment, utilisant une architecture de Mixture-of-Experts (MoE) qui lui permet de fonctionner efficacement sur des systèmes Mac de 64 Go ou même des systèmes de 32 Go une fois quantifié.
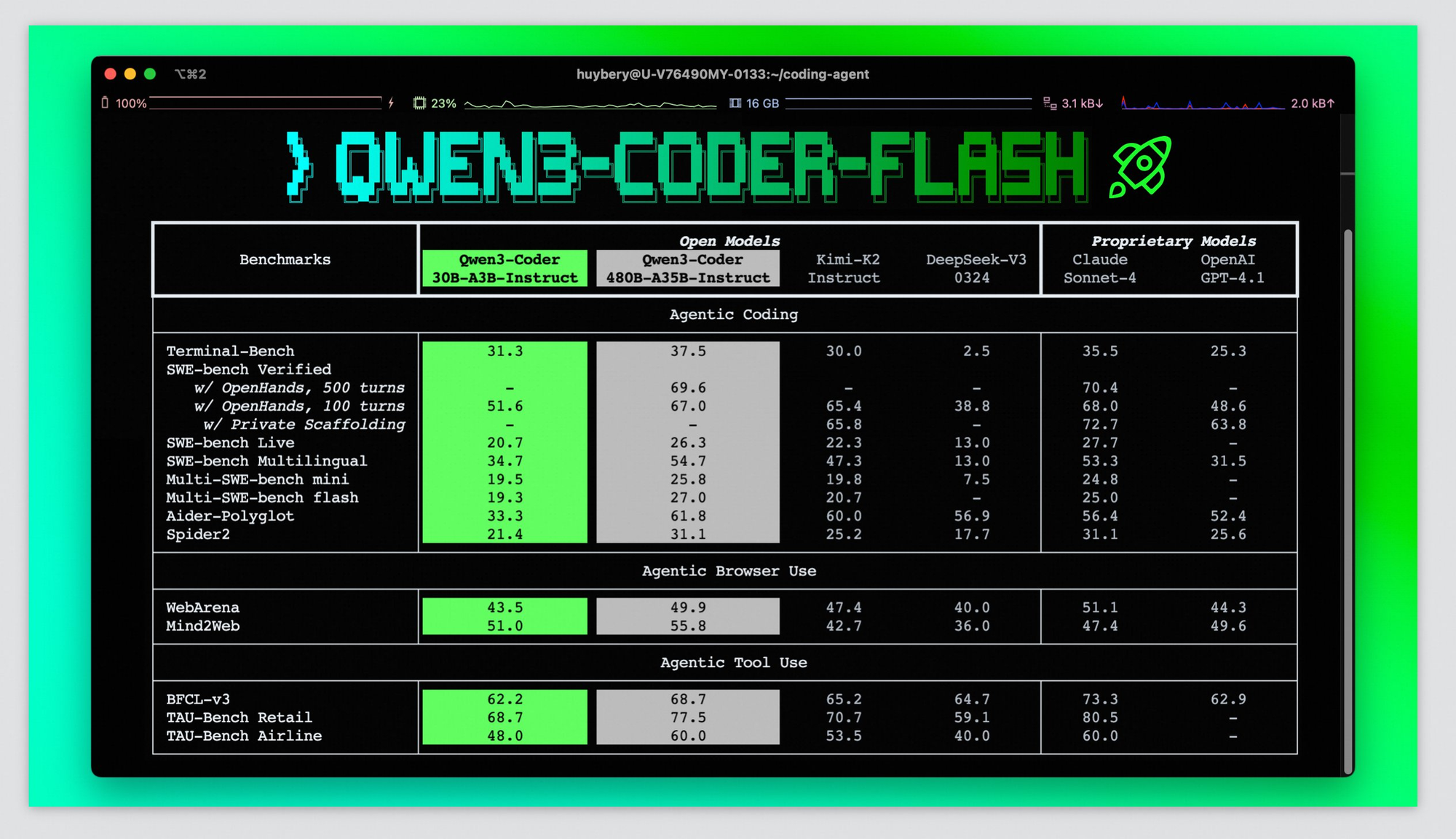
La convention de dénomination révèle un positionnement stratégique. Alors que la famille plus large Qwen3-Coder inclut des variantes massives comme le modèle à 480 milliards de paramètres, Qwen3-Coder-Flash cible spécifiquement les développeurs qui ont besoin d'une génération de code rapide et efficace sans nécessiter d'énormes ressources de calcul. Cette approche rend le codage IA avancé accessible aux développeurs individuels et aux petites équipes.
De plus, la désignation "Flash" met l'accent sur l'optimisation de la vitesse. Le modèle est conçu comme un "modèle non-pensant spécialement entraîné pour les tâches de codage", ce qui signifie qu'il se concentre sur la génération rapide de code plutôt que sur des processus de raisonnement complexes qui pourraient ralentir les flux de travail de développement.
Analyse approfondie de l'architecture technique
L'architecture Mixture-of-Experts (MoE) représente une avancée technique significative dans le fonctionnement des modèles de codage. Contrairement aux modèles denses traditionnels qui activent tous les paramètres pour chaque calcul, Qwen3-Coder-Flash active sélectivement uniquement les réseaux d'experts les plus pertinents pour des tâches de codage spécifiques. Cette activation sélective réduit considérablement la surcharge de calcul tout en maintenant des niveaux de performance élevés.
De plus, le modèle intègre plusieurs innovations architecturales qui le distinguent de ses concurrents. La distribution des paramètres permet aux réseaux d'experts spécialisés de gérer plus efficacement différents langages de programmation et paradigmes de codage. La génération de code Python pourrait activer différentes combinaisons d'experts par rapport aux tâches de développement JavaScript ou C++.
La méthodologie d'entraînement met également l'accent sur des scénarios de codage pratiques. Le modèle a utilisé Qwen2.5-Coder pour nettoyer et réécrire des données bruyantes, améliorant considérablement les performances globales grâce à des techniques avancées de génération de données synthétiques. Cette approche garantit que le modèle comprend les modèles de codage du monde réel plutôt que de simples exemples de programmation académiques.
Les capacités de longueur de contexte transforment les flux de travail de développement
L'un des avantages les plus significatifs de Qwen3-Coder-Flash réside dans ses capacités de gestion du contexte. Le modèle offre une prise en charge native de 256K de contexte avec des capacités d'extension jusqu'à 1M de tokens en utilisant la technologie YaRN (Yet another RoPE extensioN). Cette fenêtre de contexte étendue modifie fondamentalement la manière dont les développeurs peuvent interagir avec les assistants de codage IA.
Les modèles de codage traditionnels ont souvent du mal avec les grandes bases de code car ils ne peuvent pas maintenir un contexte suffisant sur la structure du projet, les dépendances et les modèles architecturaux. Cependant, le contexte étendu de Qwen3-Coder-Flash lui permet de comprendre simultanément des dépôts entiers, des hiérarchies d'héritage complexes et des dépendances multi-fichiers.
De plus, le contexte étendu s'avère particulièrement précieux pour les flux de travail de développement d'API. Lorsqu'il est intégré à des outils comme Apidog, les développeurs peuvent fournir une documentation API complète, plusieurs spécifications de points d'extrémité et des schémas de données complexes dans une seule fenêtre de contexte. Cette capacité permet une génération de code plus précise qui gère correctement les exigences d'intégration d'API et maintient la cohérence entre les différents points d'extrémité.
Les implications pratiques vont au-delà de la simple complétion de code. Les développeurs peuvent désormais fournir des spécifications de projet entières, des diagrammes architecturaux et des documents d'exigences comme contexte, permettant au modèle de générer du code qui s'aligne sur des objectifs de projet plus larges plutôt que sur des fonctionnalités isolées.
Intégration de la plateforme et écosystème de développeurs
Qwen3-Coder-Flash a été optimisé pour des plateformes comme Qwen Code, Cline, Roo Code et Kilo Code, ce qui indique l'orientation stratégique d'Alibaba vers le développement d'écosystèmes plutôt que le déploiement de modèles autonomes. Cette approche centrée sur la plateforme reconnaît que les flux de travail de développement modernes nécessitent des chaînes d'outils intégrées plutôt que des capacités d'IA isolées.
La stratégie d'intégration s'étend aux appels de fonctions et aux flux de travail d'agents. Le modèle dispose d'un format d'appel de fonction spécialement conçu qui prend en charge le codage agentique sur plusieurs plateformes. Cette normalisation permet aux développeurs de créer des flux de travail d'automatisation plus sophistiqués qui peuvent interagir avec plusieurs outils et services de développement.
De plus, la compatibilité du modèle avec les environnements de développement populaires réduit les frictions d'adoption. Les développeurs peuvent intégrer Qwen3-Coder-Flash dans les flux de travail existants sans modifications d'infrastructure significatives ni apprentissage de nouveaux paradigmes d'interface. Cette approche d'intégration transparente contraste avec les modèles qui nécessitent des environnements spécialisés ou des processus de configuration étendus.
Les capacités de flux de travail d'agents permettent également une automatisation du développement plus sophistiquée. Les équipes peuvent créer des agents IA qui gèrent les tâches de codage de routine, les processus de révision de code et la génération de documentation tout en maintenant la cohérence avec les normes de projet et les modèles architecturaux.
Benchmarks de performance et tests en situation réelle
L'évaluation des performances de Qwen3-Coder-Flash nécessite d'examiner à la fois les benchmarks synthétiques et les scénarios de développement réels. La famille Qwen3-Coder plus large atteint des performances de codage de pointe rivalisant avec Claude Sonnet-4, GPT-4.1 et Kimi K2, avec 61,8 % de performances sur les benchmarks Aider Polygot. Bien que des benchmarks spécifiques pour la variante Flash ne soient pas encore disponibles, ses similitudes architecturales suggèrent des niveaux de performance comparables.
Cependant, la performance des benchmarks ne raconte qu'une partie de l'histoire. Le développement réel implique des scénarios complexes que les benchmarks standard ne capturent pas : débogage de code hérité, intégration avec des API mal documentées, gestion des cas limites dans les systèmes de production et maintien de la qualité du code au sein de grandes équipes.
Les premiers retours des développeurs suggèrent que Qwen3-Coder-Flash excelle dans les scénarios de prototypage rapide où la vitesse est plus importante qu'une optimisation parfaite. Le modèle génère rapidement du code fonctionnel, permettant aux développeurs d'itérer rapidement pendant les phases d'exploration. Cependant, le déploiement en production nécessite souvent une révision et une optimisation supplémentaires que le modèle ne peut pas fournir automatiquement.
Les performances du modèle varient également considérablement selon les langages de programmation et les frameworks. Bien qu'il démontre de solides capacités avec des langages populaires comme Python et JavaScript, les performances avec des langages spécialisés ou des frameworks émergents peuvent être moins cohérentes.
Intégration avec les outils de développement d'API
La synergie entre Qwen3-Coder-Flash et les plateformes de développement d'API comme Apidog crée des flux de travail de développement puissants qui rationalisent l'ensemble du cycle de vie des API. Lorsque les développeurs utilisent les capacités complètes de conception et de test d'API d'Apidog aux côtés des fonctionnalités de génération de code de Qwen3-Coder-Flash, ils peuvent prototyper, implémenter et tester rapidement des points d'extrémité d'API avec une efficacité sans précédent.
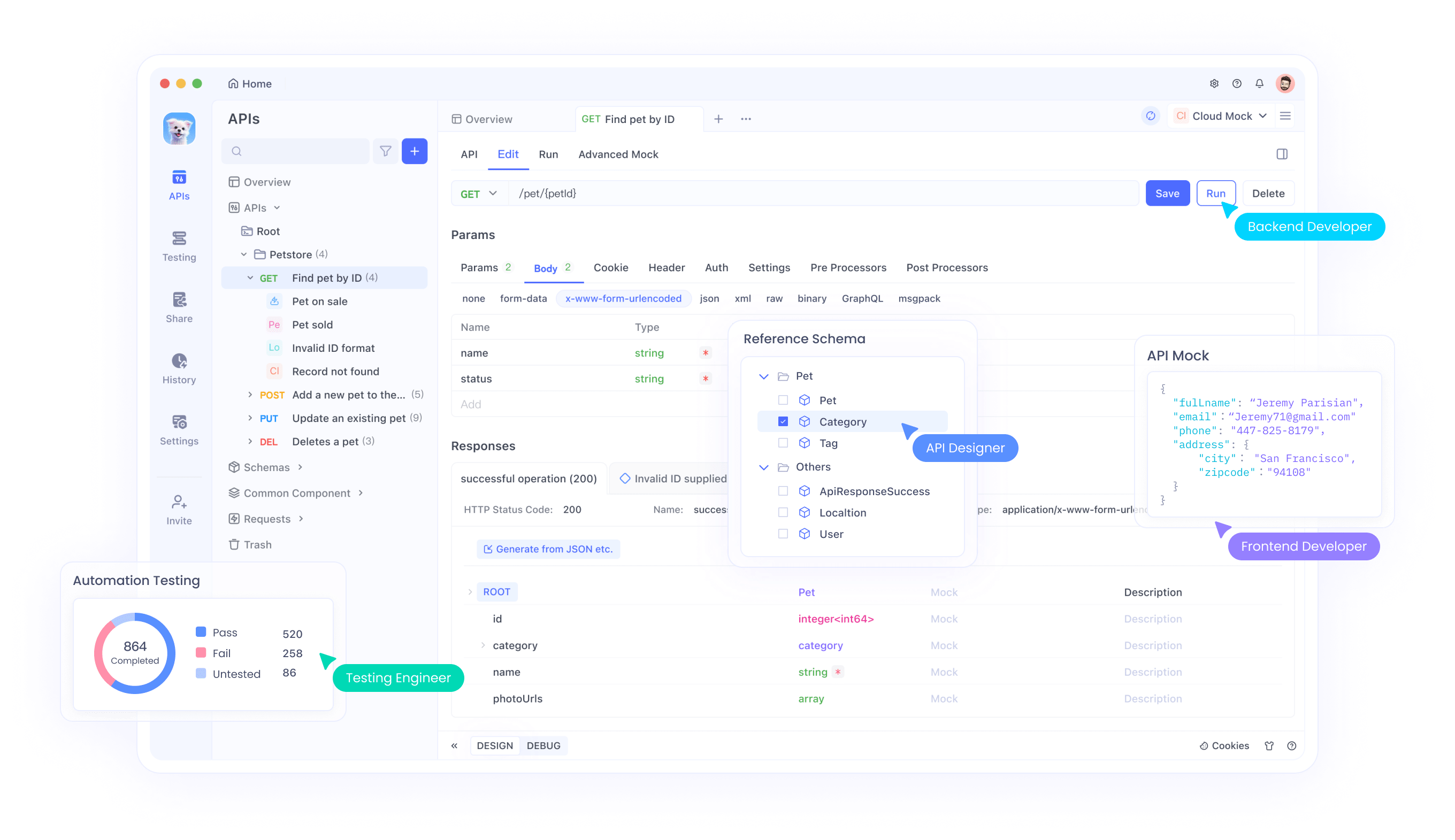
Plus précisément, le concepteur d'API visuel d'Apidog peut générer des spécifications complètes que Qwen3-Coder-Flash peut ensuite convertir en implémentations de code fonctionnelles. La fenêtre de contexte étendue du modèle lui permet de comprendre simultanément les schémas d'API complexes, les exigences d'authentification et les règles de validation des données, produisant un code qui gère correctement toutes les exigences spécifiées.
De plus, l'intégration permet des flux de travail de test automatisés où Qwen3-Coder-Flash génère des cas de test basés sur les spécifications d'API, tandis qu'Apidog exécute ces tests et fournit un feedback détaillé sur l'exactitude de l'implémentation. Ce processus de développement en boucle fermée réduit considérablement le temps entre la conception de l'API et l'implémentation fonctionnelle.
Le potentiel de collaboration s'étend aux scénarios de développement en équipe où plusieurs développeurs travaillent sur différents composants d'API. Qwen3-Coder-Flash peut maintenir la cohérence entre les différentes implémentations de points d'extrémité en comprenant l'architecture API plus large via la gestion centralisée des spécifications d'Apidog.
Limitations et considérations
Malgré ses capacités impressionnantes, Qwen3-Coder-Flash présente plusieurs limitations que les développeurs doivent prendre en compte. L'accent mis par le modèle sur la vitesse se fait parfois au détriment de l'optimisation du code et des meilleures pratiques. Le code généré peut être fonctionnellement correct mais manquer des optimisations d'efficacité qu'implémenteraient des développeurs expérimentés.
Les considérations de sécurité nécessitent également une attention particulière. Bien que le modèle génère du code syntaxiquement correct, il peut ne pas toujours implémenter des mesures de sécurité appropriées telles que la validation des entrées, la prévention des injections SQL ou la gestion correcte de l'authentification. Les développeurs doivent toujours effectuer des audits de sécurité et mettre en œuvre les protections appropriées.
De plus, les limitations des données d'entraînement du modèle signifient qu'il peut avoir du mal avec les frameworks de pointe, les fonctionnalités de langage nouvellement publiées ou les connaissances de domaine hautement spécialisées. Les développeurs travaillant avec des technologies émergentes devraient s'attendre à fournir un contexte et des conseils supplémentaires pour obtenir des résultats optimaux.
Les coûts et les exigences d'infrastructure présentent également des défis pratiques. Bien que plus efficace que les modèles plus grands, Qwen3-Coder-Flash nécessite toujours des ressources de calcul importantes pour des performances optimales. Les organisations doivent équilibrer les avantages en termes de productivité avec les coûts et la complexité de l'infrastructure.
Stratégies d'implémentation pour les équipes de développement
La mise en œuvre réussie de Qwen3-Coder-Flash nécessite une planification stratégique qui tient compte à la fois des exigences techniques et de la dynamique d'équipe. Les organisations devraient commencer par des projets pilotes qui tirent parti des forces du modèle tout en minimisant l'exposition à ses limitations.
L'implémentation initiale devrait se concentrer sur les cas d'utilisation où la génération rapide de code apporte une valeur claire : création de points d'extrémité API, génération de cas de test, automatisation de la documentation et développement de prototypes. Ces scénarios permettent aux équipes d'acquérir de l'expérience avec le modèle tout en offrant des améliorations tangibles de la productivité.
La formation et la gestion du changement nécessitent également une attention particulière. Les équipes de développement ont besoin de conseils sur l'ingénierie des invites efficace, la compréhension des limitations du modèle et l'intégration du code généré par l'IA dans les processus d'assurance qualité existants. Sans une formation appropriée, les équipes peuvent soit sous-utiliser les capacités du modèle, soit trop se fier à sa production sans validation appropriée.
L'intégration avec les outils de développement existants devrait être progressive et mesurée. Plutôt que de remplacer entièrement les flux de travail établis, les organisations devraient identifier les points douloureux spécifiques où Qwen3-Coder-Flash peut apporter des améliorations immédiates tout en maintenant la stabilité globale du flux de travail.
Conclusion
Qwen3-Coder-Flash représente une avancée significative dans l'assistance au codage IA accessible, offrant des capacités de niveau entreprise dans un ensemble plus efficace et plus rentable. Ses capacités de contexte étendu, son architecture MoE et ses intégrations de plateforme créent de puissantes opportunités pour les équipes de développement cherchant à accélérer leurs flux de travail de codage.
Cependant, le succès avec Qwen3-Coder-Flash exige des attentes réalistes et une implémentation stratégique. Le modèle excelle dans la génération rapide de code et le prototypage, mais ne peut pas remplacer l'expertise humaine en matière de conception d'architecture, d'implémentation de la sécurité et d'optimisation du code. Les organisations qui comprennent ces limites et mettent en œuvre des processus appropriés réaliseront des gains de productivité significatifs.