L'équipe Qwen d'Alibaba Cloud a lancé deux ajouts puissants à sa gamme de grands modèles linguistiques (LLM) : Qwen3-4B-Instruct-2507 et Qwen3-4B-Thinking-2507. Ces modèles apportent des avancées significatives en matière de raisonnement, de suivi d'instructions et de compréhension de contextes longs, avec un support natif pour une longueur de contexte de 256K tokens. Conçus pour les développeurs, les chercheurs et les passionnés d'IA, ces modèles offrent des capacités robustes pour des tâches allant du codage à la résolution de problèmes complexes. De plus, des outils comme Apidog, une plateforme gratuite de gestion d'API, peuvent simplifier les tests et l'intégration de ces modèles dans vos applications.
Comprendre les modèles Qwen3-4B
La série Qwen3 représente la dernière évolution de la famille de grands modèles linguistiques d'Alibaba Cloud, succédant à la série Qwen2.5. Plus précisément, Qwen3-4B-Instruct-2507 et Qwen3-4B-Thinking-2507 sont adaptés à des cas d'utilisation distincts : le premier excelle dans le dialogue général et le suivi d'instructions, tandis que le second est optimisé pour les tâches de raisonnement complexes. Les deux modèles prennent en charge une longueur de contexte native de 262 144 tokens, ce qui leur permet de traiter facilement des ensembles de données étendus, de longs documents ou des conversations multi-tours. De plus, leur compatibilité avec des frameworks comme Hugging Face Transformers et des outils de déploiement comme Apidog les rend accessibles pour les applications locales et basées sur le cloud.
Qwen3-4B-Instruct-2507 : Optimisé pour l'efficacité
Le modèle Qwen3-4B-Instruct-2507 fonctionne en mode non-réflexion, se concentrant sur des réponses efficaces et de haute qualité pour les tâches générales. Ce modèle a été affiné pour améliorer le suivi d'instructions, le raisonnement logique, la compréhension de texte et les capacités multilingues. Notamment, il ne génère pas de blocs <think></think>, ce qui le rend idéal pour les scénarios où des réponses rapides et directes sont préférées au raisonnement étape par étape.
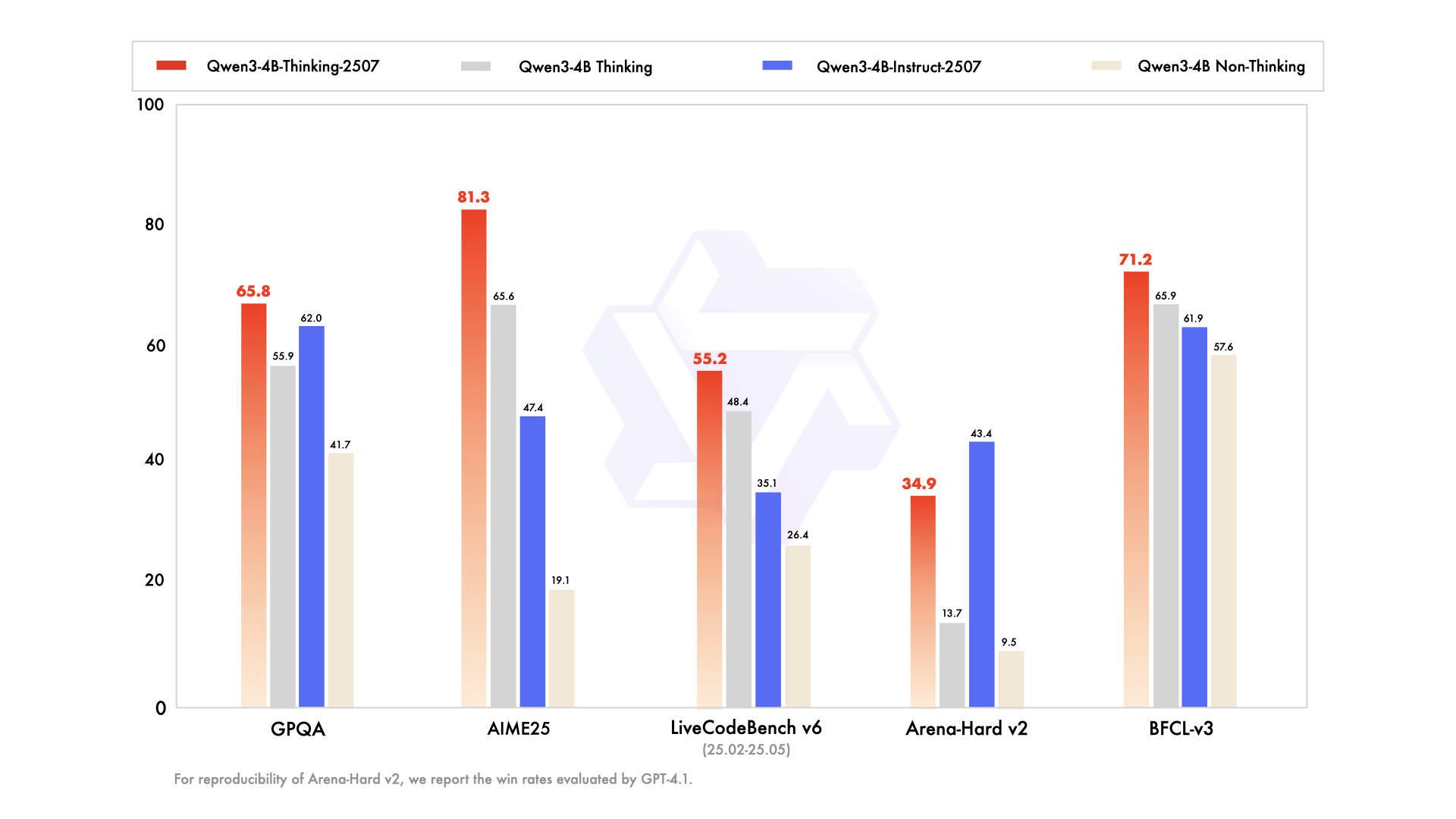
Les améliorations clés incluent :
- Capacités générales améliorées : Le modèle démontre des performances supérieures en mathématiques, sciences, codage et utilisation d'outils, le rendant polyvalent pour les applications techniques.
- Support multilingue : Il couvre plus de 100 langues et dialectes, assurant des performances robustes dans les applications globales.
- Compréhension de contexte long : Avec une longueur de contexte de 256K tokens, il gère les entrées étendues, telles que les documents juridiques ou les bases de code volumineuses, sans troncature.
- Alignement avec les préférences de l'utilisateur : Le modèle fournit des réponses plus naturelles et engageantes, excellant dans l'écriture créative et les dialogues multi-tours.
Pour les développeurs intégrant ce modèle dans des API, Apidog fournit une interface conviviale pour tester et gérer les points d'accès API, assurant un déploiement sans heurts. Cette efficacité fait de Qwen3-4B-Instruct-2507 un choix privilégié pour les applications nécessitant des réponses rapides et précises.
Qwen3-4B-Thinking-2507 : Conçu pour le raisonnement profond
En revanche, Qwen3-4B-Thinking-2507 est conçu pour les tâches exigeant un raisonnement intensif, telles que la résolution de problèmes logiques, les mathématiques et les benchmarks académiques. Ce modèle fonctionne exclusivement en mode réflexion, incorporant automatiquement des processus de chaîne de pensée (CoT) pour décomposer les problèmes complexes. Sa sortie peut inclure une balise de fermeture </think> sans balise d'ouverture <think>, car le modèle de chat par défaut intègre un comportement de réflexion.
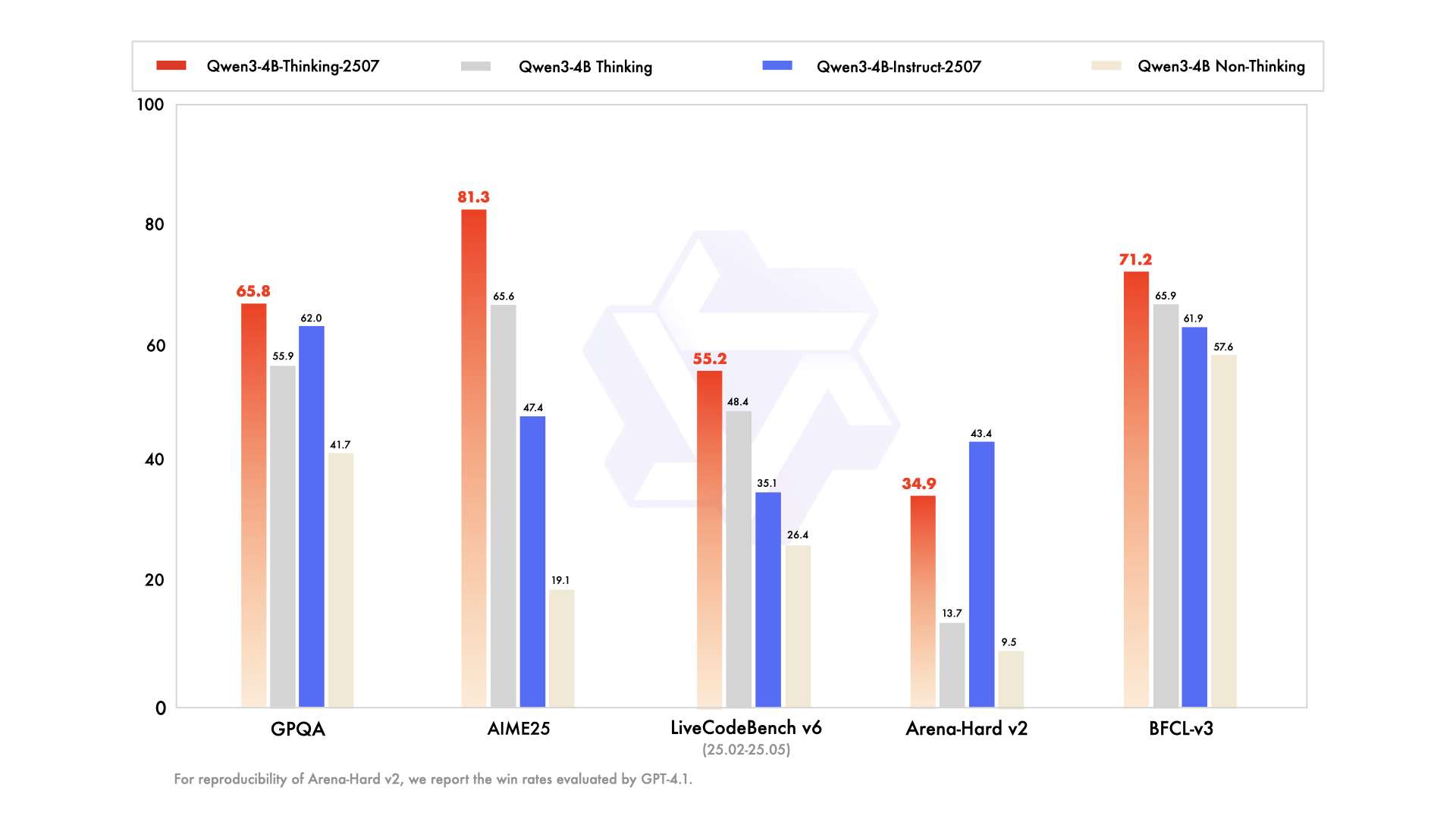
Les améliorations clés incluent :
- Capacités de raisonnement avancées : Le modèle atteint des résultats de pointe parmi les modèles de réflexion open source, en particulier dans les domaines STEM et le codage.
- Profondeur de réflexion accrue : Il excelle dans les tâches nécessitant un raisonnement de niveau expert humain, avec une longueur de réflexion étendue pour une analyse approfondie.
- Longueur de contexte de 256K : Comme son homologue Instruct, il prend en charge des fenêtres de contexte massives, idéales pour le traitement de grands ensembles de données ou de requêtes complexes.
- Intégration d'outils : Le modèle tire parti d'outils comme Qwen-Agent pour des flux de travail agiles rationalisés, améliorant son utilité dans les systèmes automatisés.
Pour les développeurs travaillant avec des applications à forte intensité de raisonnement, Apidog peut faciliter les tests d'API, garantissant que les sorties du modèle correspondent aux résultats attendus. Ce modèle est particulièrement adapté aux environnements de recherche et aux scénarios de résolution de problèmes complexes.
Spécifications techniques et architecture
Les deux modèles Qwen3-4B font partie de la famille Qwen3, qui comprend des architectures denses et de mélange d'experts (MoE). La désignation 4B fait référence à leurs 4 milliards de paramètres, ce qui établit un équilibre entre l'efficacité computationnelle et les performances. Par conséquent, ces modèles sont accessibles sur du matériel grand public, contrairement aux modèles plus grands comme Qwen3-235B-A22B, qui nécessitent des ressources substantielles.
Points forts de l'architecture
- Conception de modèle dense : Contrairement aux modèles MoE, les modèles Qwen3-4B utilisent une architecture dense, garantissant des performances constantes sur toutes les tâches sans nécessiter d'activation sélective des paramètres.
- YaRN pour l'extension de contexte : Les modèles utilisent YaRN pour étendre leur longueur de contexte de 32 768 à 262 144 tokens, permettant un traitement de contexte long sans dégradation significative des performances.
- Pipeline d'entraînement : L'équipe Qwen a utilisé un processus d'entraînement en quatre étapes, comprenant un démarrage à froid de longue chaîne de pensée, un apprentissage par renforcement basé sur le raisonnement, une fusion du mode de réflexion et un apprentissage par renforcement général. Cette approche améliore à la fois les capacités de raisonnement et de dialogue.
- Support de quantification : Les deux modèles prennent en charge la quantification FP8, réduisant les exigences de mémoire tout en maintenant la précision. Par exemple, Qwen3-4B-Thinking-2507-FP8 est disponible pour les environnements à ressources limitées.
Exigences matérielles
Pour exécuter ces modèles efficacement, considérez les points suivants :
- Mémoire GPU : Un minimum de 8 Go de VRAM est recommandé pour les modèles quantifiés FP8, tandis que les modèles bfloat16 peuvent nécessiter 16 Go ou plus.
- RAM : Pour des performances optimales, 16 Go de mémoire unifiée (VRAM + RAM) sont suffisants pour la plupart des tâches.
- Frameworks d'inférence : Les deux modèles sont compatibles avec Hugging Face Transformers (version ≥4.51.0), vLLM (≥0.8.5) et SGLang (≥0.4.6.post1). Des outils locaux comme Ollama et LMStudio prennent également en charge Qwen3.
Pour les développeurs déployant ces modèles, Apidog simplifie le processus en fournissant des outils pour surveiller et tester les performances des API, assurant une intégration efficace avec les frameworks d'inférence.
Intégration avec Hugging Face et ModelScope
Les modèles Qwen3-4B sont disponibles sur Hugging Face et ModelScope, offrant une flexibilité aux développeurs. Ci-dessous, nous fournissons un extrait de code pour démontrer comment utiliser Qwen3-4B-Instruct-2507 avec Hugging Face Transformers.

from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Instruct-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Écrire une fonction Python pour calculer les nombres de Fibonacci."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=16384)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()content = tokenizer.decode(output_ids, skip_special_tokens=True)print("Code généré :\n", content)Pour Qwen3-4B-Thinking-2507, un parsing supplémentaire est nécessaire pour gérer le contenu de réflexion :
from transformers import AutoModelForCausalLM, AutoTokenizer
model_name = "Qwen/Qwen3-4B-Thinking-2507"tokenizer = AutoTokenizer.from_pretrained(model_name)model = AutoModelForCausalLM.from_pretrained(model_name, torch_dtype="auto", device_map="auto")
prompt = "Résoudre l'équation 2x^2 + 3x - 5 = 0."messages = [{"role": "user", "content": prompt}]text = tokenizer.apply_chat_template(messages, tokenize=False, add_generation_prompt=True)model_inputs = tokenizer([text], return_tensors="pt").to(model.device)
generated_ids = model.generate(**model_inputs, max_new_tokens=32768)output_ids = generated_ids[0][len(model_inputs.input_ids[0]):].tolist()
try:index = len(output_ids) - output_ids[::-1].index(151668) # tokenexcept ValueError:index = 0thinking_content = tokenizer.decode(output_ids[:index], skip_special_tokens=True).strip("\n")content = tokenizer.decode(output_ids[index:], skip_special_tokens=True).strip("\n")print("Processus de réflexion :\n", thinking_content)print("Solution :\n", content)Ces extraits démontrent la facilité d'intégration des modèles Qwen dans les flux de travail Python. Pour les déploiements basés sur des API, Apidog peut aider à tester ces points d'accès, garantissant des performances fiables.
Optimisation des performances et meilleures pratiques
Pour maximiser les performances des modèles Qwen3-4B, considérez les recommandations suivantes :
- Paramètres d'échantillonnage : Pour Qwen3-4B-Instruct-2507, utilisez
temperature=0.7,top_p=0.8,top_k=20etmin_p=0. Pour Qwen3-4B-Thinking-2507, utiliseztemperature=0.6,top_p=0.95,top_k=20etmin_p=0. Évitez le décodage glouton pour prévenir la dégradation des performances. - Gestion de la longueur de contexte : Si vous rencontrez des problèmes de mémoire insuffisante, réduisez la longueur de contexte à 32 768 tokens. Cependant, pour les tâches de raisonnement, maintenez une longueur de contexte supérieure à 131 072 tokens.
- Pénalité de présence : Réglez
presence_penaltyentre 0 et 2 pour réduire les répétitions, mais évitez les valeurs élevées pour éviter le mélange de langues. - Frameworks d'inférence : Utilisez vLLM ou SGLang pour l'inférence à haut débit, et utilisez Apidog pour surveiller les performances des API.
Comparaison de Qwen3-4B-Instruct-2507 et Qwen3-4B-Thinking-2507
Bien que les deux modèles partagent la même architecture de 4 milliards de paramètres, leurs philosophies de conception diffèrent :
- Qwen3-4B-Instruct-2507 : Privilégie la vitesse et l'efficacité, le rendant adapté aux chatbots, au support client et aux applications à usage général.
- Qwen3-4B-Thinking-2507 : Se concentre sur le raisonnement profond, idéal pour la recherche académique, la résolution de problèmes complexes et les tâches nécessitant des processus de chaîne de pensée.
Les développeurs peuvent basculer entre les modes en utilisant les invites /think et /no_think, ce qui permet une flexibilité basée sur les exigences de la tâche. Apidog peut aider à tester ces commutations de mode dans les applications basées sur API.
Support de la communauté et de l'écosystème
Les modèles Qwen3-4B bénéficient d'un écosystème robuste, avec le support de Hugging Face, ModelScope et d'outils comme Ollama, LMStudio et llama.cpp. La nature open source de ces modèles, sous licence Apache 2.0, encourage les contributions de la communauté et le fine-tuning. Par exemple, Unsloth fournit des outils pour un fine-tuning 2 fois plus rapide avec 70 % de VRAM en moins, rendant ces modèles accessibles à un public plus large.
Conclusion
Les modèles Qwen3-4B-Instruct-2507 et Qwen3-4B-Thinking-2507 marquent un bond significatif dans la série Qwen d'Alibaba Cloud, offrant des capacités inégalées en matière de suivi d'instructions, de raisonnement et de traitement de contextes longs. Avec une longueur de contexte de 256K tokens, un support multilingue et une compatibilité avec des outils comme Apidog, ces modèles permettent aux développeurs de construire des applications intelligentes et évolutives. Que vous génériez du code, résolviez des équations ou créiez des chatbots multilingues, ces modèles offrent des performances exceptionnelles. Commencez à explorer leur potentiel dès aujourd'hui, et utilisez Apidog pour rationaliser vos intégrations API pour une expérience de développement fluide.