
Aujourd'hui est un autre grand jour pour la communauté de l'IA open source, qui, en particulier, prospère grâce à ces moments, déconstruisant, testant et construisant avec enthousiasme sur le nouvel état de l'art. En juillet 2025, l'équipe Qwen d'Alibaba a déclenché un tel événement avec le lancement de sa série Qwen3, une nouvelle famille puissante de modèles prête à redéfinir les références de performance. Au cœur de cette version se trouve une variante fascinante et hautement spécialisée : Qwen3-235B-A22B-Thinking-2507.
Ce modèle n'est pas seulement une mise à jour incrémentale ; il représente une étape délibérée et stratégique vers la création de systèmes d'IA dotés de profondes capacités de raisonnement. Son nom seul est une déclaration d'intention, signalant un accent sur la logique, la planification et la résolution de problèmes en plusieurs étapes. Cet article propose une analyse approfondie de l'architecture, du but et de l'impact potentiel de Qwen3-Thinking, examinant sa place au sein de l'écosystème Qwen3 plus large et ce qu'il signifie pour l'avenir du développement de l'IA.
Vous voulez une plateforme intégrée tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix bien plus abordable !
La famille Qwen3 : Une offensive multifacette sur l'état de l'art
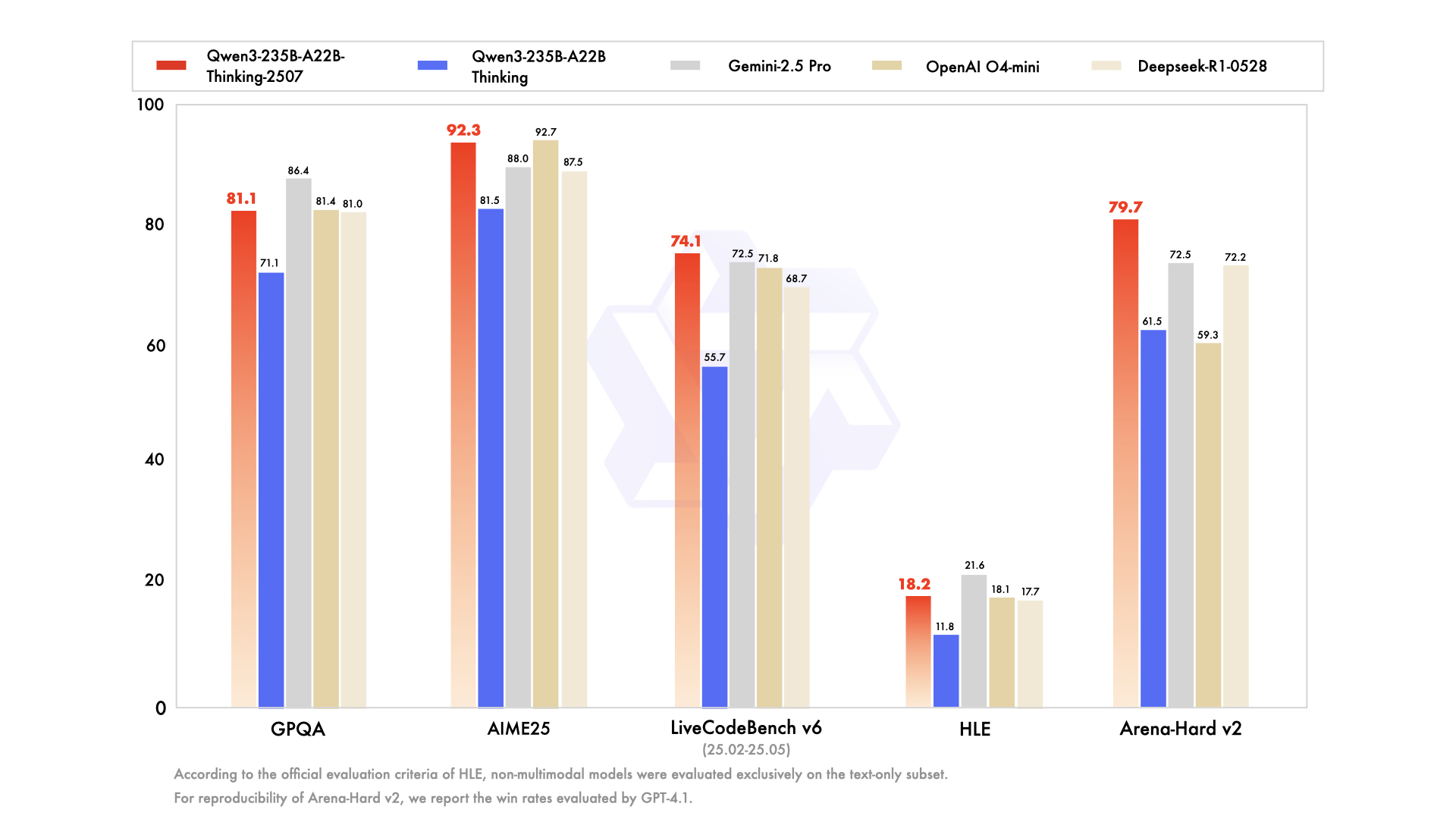
Pour comprendre le modèle Thinking, il faut d'abord apprécier le contexte de sa naissance. Il n'est pas apparu isolément, mais comme faisant partie d'une famille de modèles Qwen3 complète et stratégiquement diversifiée. La série Qwen a déjà cultivé un public massif, avec un historique de téléchargements se comptant par centaines de millions et favorisant une communauté dynamique qui a créé plus de 100 000 modèles dérivés sur des plateformes comme Hugging Face.
La série Qwen3 comprend plusieurs variantes clés, chacune adaptée à différents domaines :
- Qwen3-Instruct : Un modèle généraliste de suivi d'instructions conçu pour un large éventail d'applications conversationnelles et orientées tâches. La variante
Qwen3-235B-A22B-Instruct-2507, par exemple, est réputée pour son alignement amélioré avec les préférences des utilisateurs dans les tâches ouvertes et sa large couverture de connaissances. - Qwen3-Coder : Une série de modèles explicitement conçus pour le codage agentique. Le plus puissant d'entre eux, un modèle massif de 480 milliards de paramètres, établit une nouvelle norme pour la génération de code open source et l'automatisation du développement logiciel. Il est même livré avec un outil en ligne de commande, Qwen Code, pour mieux exploiter ses capacités agentiques.
- Qwen3-Thinking : L'objet de notre analyse, spécialisé dans les tâches cognitives complexes qui vont au-delà du simple suivi d'instructions ou de la génération de code.
Cette approche familiale démontre une stratégie sophistiquée : au lieu d'un modèle unique et monolithique essayant d'être un touche-à-tout, Alibaba fournit une suite d'outils spécialisés, permettant aux développeurs de choisir la bonne fondation pour leurs besoins spécifiques.
Parlons de la partie "Thinking" de Qwen3-235B-A22B-Thinking-2507
Le nom du modèle, Qwen3-235B-A22B-Thinking-2507, est dense d'informations qui révèlent son architecture sous-jacente et sa philosophie de conception. Décomposons-le pièce par pièce.
Qwen3: Cela signifie que le modèle appartient à la troisième génération de la série Qwen, s'appuyant sur les connaissances et les avancées de ses prédécesseurs.235B-A22B(Mixture of Experts - MoE) : C'est le détail architectural le plus crucial. Le modèle n'est pas un réseau dense de 235 milliards de paramètres, où chaque paramètre est utilisé pour chaque calcul. Au lieu de cela, il utilise une architecture de Mélange d'Experts (MoE).Thinking: Ce suffixe désigne la spécialisation du modèle, affiné sur des données récompensant la déduction logique et l'analyse étape par étape.2507: Il s'agit d'une balise de version, représentant probablement juillet 2025, indiquant la date de sortie ou d'achèvement de l'entraînement du modèle.
L'architecture MoE est la clé de la combinaison de puissance et d'efficacité de ce modèle. On peut la considérer comme une grande équipe d'"experts" spécialisés — des réseaux neuronaux plus petits — gérés par un "réseau de routage" ou un "routeur". Pour tout jeton d'entrée donné, le routeur sélectionne dynamiquement un petit sous-ensemble des experts les plus pertinents pour traiter l'information.
Dans le cas de Qwen3-235B-A22B, les spécificités sont :
- Paramètres Totaux (
235B) : Cela représente le vaste dépôt de connaissances distribué à travers tous les experts disponibles. Le modèle contient un total de 128 experts distincts. - Paramètres Actifs (
A22B) : Pour chaque passe d'inférence, le réseau de routage sélectionne 8 experts à activer. La taille combinée de ces experts actifs est d'environ 22 milliards de paramètres.
Les avantages de cette approche sont immenses. Elle permet au modèle de posséder la vaste connaissance, la nuance et les capacités d'un modèle de 235 milliards de paramètres tout en ayant un coût de calcul et une vitesse d'inférence proches de ceux d'un modèle dense beaucoup plus petit de 22 milliards de paramètres. Cela rend le déploiement et l'exécution d'un modèle aussi grand plus réalisables sans sacrifier sa profondeur de connaissance.
Spécifications techniques et profil de performance
Au-delà de l'architecture de haut niveau, les spécifications détaillées du modèle brossent un tableau plus clair de ses capacités.
- Architecture du modèle : Mélange d'Experts (MoE)
- Paramètres totaux : ~235 milliards
- Paramètres actifs : ~22 milliards par jeton
- Nombre d'experts : 128
- Experts activés par jeton : 8
- Longueur du contexte : Le modèle prend en charge une fenêtre de contexte de 128 000 jetons. Il s'agit d'une amélioration massive qui lui permet de traiter et de raisonner sur des documents extrêmement longs, des bases de code entières ou de longues histoires conversationnelles sans perdre le fil des informations cruciales du début de l'entrée.
- Tokeniseur : Il utilise un tokeniseur Byte Pair Encoding (BPE) personnalisé avec un vocabulaire de plus de 150 000 jetons. Cette grande taille de vocabulaire témoigne de son solide entraînement multilingue, lui permettant d'encoder efficacement du texte provenant d'un large éventail de langues, y compris l'anglais, le chinois, l'allemand, l'espagnol et bien d'autres, ainsi que des langages de programmation.
- Données d'entraînement : Bien que la composition exacte du corpus d'entraînement soit propriétaire, un modèle
Thinkingest certainement entraîné sur un mélange spécialisé de données conçu pour favoriser le raisonnement. Cet ensemble de données irait bien au-delà du texte web standard et inclurait probablement : - Articles académiques et scientifiques : De grands volumes de texte provenant de sources comme arXiv, PubMed et d'autres dépôts de recherche pour absorber un raisonnement scientifique et mathématique complexe.
- Ensembles de données logiques et mathématiques : Des ensembles de données comme GSM8K (Grade School Math) et l'ensemble de données MATH, qui contiennent des problèmes de mots nécessitant des solutions étape par étape.
- Problèmes de programmation et de code : Des ensembles de données comme HumanEval et MBPP, qui testent le raisonnement logique par la génération de code.
- Textes philosophiques et juridiques : Des documents qui nécessitent la compréhension d'arguments logiques denses, abstraits et hautement structurés.
- Données de chaîne de pensée (CoT) : Des exemples générés synthétiquement ou organisés par des humains où le modèle est explicitement montré comment "penser étape par étape" pour arriver à une réponse.
Ce mélange de données organisé est ce qui sépare le modèle Thinking de son homologue Instruct. Il n'est pas seulement entraîné pour être utile ; il est entraîné pour être rigoureux.
Le pouvoir de la "Pensée" : Un accent sur la cognition complexe
La promesse du modèle Qwen3-Thinking réside dans sa capacité à aborder des problèmes qui ont historiquement été des défis majeurs pour les grands modèles linguistiques. Ce sont des tâches où la simple correspondance de motifs ou la récupération d'informations est insuffisante. La spécialisation "Thinking" suggère une maîtrise dans des domaines tels que :
- Raisonnement en plusieurs étapes : Résoudre des problèmes qui nécessitent de décomposer une requête en une séquence d'étapes logiques. Par exemple, calculer les implications financières d'une décision commerciale basée sur plusieurs variables de marché ou planifier la trajectoire d'un projectile étant donné un ensemble de contraintes physiques.
- Déduction logique : Analyser un ensemble de prémisses et en tirer une conclusion valide. Cela pourrait impliquer de résoudre un puzzle de grille logique, d'identifier des sophismes logiques dans un texte, ou de déterminer les conséquences d'un ensemble de règles dans un contexte juridique ou contractuel.
- Planification stratégique : Élaborer une séquence d'actions pour atteindre un objectif. Cela a des applications dans les jeux complexes (comme les échecs ou le Go), les simulations de stratégie commerciale, l'optimisation de la chaîne d'approvisionnement et la gestion de projet automatisée.
- Inférence causale : Tenter d'identifier les relations de cause à effet au sein d'un système complexe décrit dans un texte, une pierre angulaire du raisonnement scientifique et analytique avec laquelle les modèles ont souvent du mal.
- Raisonnement abstrait : Comprendre et manipuler des concepts et des analogies abstraits. C'est essentiel pour la résolution créative de problèmes et une véritable intelligence de niveau humain, allant au-delà des faits concrets pour les relations entre eux.
Le modèle est conçu pour exceller sur des benchmarks qui mesurent spécifiquement ces capacités cognitives avancées, tels que MMLU (Massive Multitask Language Understanding) pour les connaissances générales et la résolution de problèmes, et les susmentionnés GSM8K et MATH pour le raisonnement mathématique.
Accessibilité, quantification et engagement communautaire
La puissance d'un modèle n'a de sens que s'il peut être accédé et utilisé. Fidèle à son engagement open source, Alibaba a rendu la famille Qwen3, y compris la variante Thinking, largement disponible sur des plateformes comme Hugging Face et ModelScope.
Reconnaissant les ressources de calcul importantes nécessaires pour exécuter un modèle de cette envergure, des versions quantifiées sont également disponibles. Le modèle Qwen3-235B-A22B-Thinking-2507-FP8 en est un excellent exemple. FP8 (virgule flottante 8 bits) est une technique de quantification de pointe qui réduit considérablement l'empreinte mémoire du modèle et augmente la vitesse d'inférence.
Décomposons l'impact :
- Un modèle de 235 milliards de paramètres en précision standard 16 bits (BF16/FP16) nécessiterait plus de 470 Go de VRAM, une quantité prohibitive pour tous les clusters de serveurs de niveau entreprise, à l'exception des plus grands.
- La version quantifiée FP8, cependant, réduit cette exigence à moins de 250 Go. Bien que toujours substantiel, cela rend le modèle possible pour les institutions de recherche, les startups et même les individus disposant de stations de travail multi-GPU équipées de matériel grand public ou prosumer haut de gamme.
Cela rend le raisonnement avancé accessible à un public beaucoup plus large. Pour les utilisateurs professionnels qui préfèrent les services gérés, les modèles sont également intégrés aux plateformes cloud d'Alibaba. L'accès à l'API via Model Studio et l'intégration à l'assistant IA phare d'Alibaba, Quark, garantissent que la technologie peut être exploitée à n'importe quelle échelle.
Conclusion : Un nouvel outil pour une nouvelle classe de problèmes
La sortie de Qwen3-235B-A22B-Thinking-2507 est plus qu'un simple point supplémentaire sur le graphique toujours croissant des performances des modèles d'IA. C'est une déclaration sur l'orientation future du développement de l'IA : un passage des modèles monolithiques et à usage général vers un écosystème diversifié d'outils puissants et spécialisés. En employant une architecture efficace de Mélange d'Experts, Alibaba a livré un modèle doté de la vaste connaissance d'un réseau de 235 milliards de paramètres et de la convivialité computationnelle relative d'un modèle de 22 milliards de paramètres.
En affinant explicitement ce modèle pour la "Pensée", l'équipe Qwen offre au monde un outil dédié à la résolution des défis analytiques et de raisonnement les plus ardus. Il a le potentiel d'accélérer la découverte scientifique en aidant les chercheurs à analyser des données complexes, de permettre aux entreprises de prendre de meilleures décisions stratégiques et de servir de couche fondamentale pour une nouvelle génération d'applications intelligentes capables de planifier, de déduire et de raisonner avec une sophistication sans précédent. Alors que la communauté open source commence à explorer pleinement ses profondeurs, Qwen3-Thinking est appelé à devenir un élément constitutif essentiel dans la quête continue d'une IA plus performante et véritablement intelligente.
Vous voulez une plateforme intégrée tout-en-un pour que votre équipe de développeurs travaille ensemble avec une productivité maximale ?
Apidog répond à toutes vos exigences et remplace Postman à un prix bien plus abordable !