
L'équipe Qwen d'Alibaba a une fois de plus repoussé les limites de l'intelligence artificielle avec la sortie du modèle Qwen2.5-VL-32B-Instruct, un modèle vision-langage (VLM) révolutionnaire qui promet d'être à la fois plus intelligent et plus léger.
Annoncé le 24 mars 2025, ce modèle de 32 milliards de paramètres trouve un équilibre optimal entre performance et efficacité, ce qui en fait un choix idéal pour les développeurs et les chercheurs. S'appuyant sur le succès de la série Qwen2.5-VL, cette nouvelle itération introduit des avancées significatives en matière de raisonnement mathématique, d'alignement des préférences humaines et de tâches de vision, tout en conservant une taille gérable pour un déploiement local.
Pour les développeurs désireux d'intégrer ce modèle puissant dans leurs projets, l'exploration d'outils API robustes est essentielle. C'est pourquoi nous recommandons de télécharger Apidog gratuitement — une plateforme de développement d'API conviviale qui simplifie les tests et l'intégration de modèles comme Qwen dans vos applications. Avec Apidog, vous pouvez interagir de manière transparente avec l'API Qwen, rationaliser les flux de travail et libérer tout le potentiel de ce VLM innovant. Téléchargez Apidog dès aujourd'hui et commencez à créer des applications plus intelligentes !
Cet outil API vous permet de tester et de déboguer les points de terminaison de votre modèle sans effort. Téléchargez Apidog gratuitement dès aujourd'hui et rationalisez votre flux de travail tout en explorant les capacités de Mistral Small 3.1 !
Qwen2.5-VL-32B : Un modèle vision-langage plus intelligent
Ce qui rend Qwen2.5-VL-32B unique ?
Qwen2.5-VL-32B se distingue comme un modèle vision-langage de 32 milliards de paramètres conçu pour remédier aux limites des modèles plus grands et plus petits de la famille Qwen. Bien que les modèles de 72 milliards de paramètres comme Qwen2.5-VL-72B offrent des capacités robustes, ils nécessitent souvent des ressources informatiques importantes, ce qui les rend peu pratiques pour un déploiement local. Inversement, les modèles de 7 milliards de paramètres, bien que plus légers, peuvent manquer de la profondeur nécessaire aux tâches complexes. Qwen2.5-VL-32B comble cette lacune en offrant des performances élevées avec une empreinte plus gérable.
Ce modèle s'appuie sur la série Qwen2.5-VL, qui a été largement saluée pour ses capacités multimodales. Cependant, Qwen2.5-VL-32B introduit des améliorations critiques, notamment l'optimisation par l'apprentissage par renforcement (RL). Cette approche améliore l'alignement du modèle avec les préférences humaines, garantissant des résultats plus détaillés et conviviaux. De plus, le modèle démontre un raisonnement mathématique supérieur, une caractéristique essentielle pour les tâches impliquant la résolution de problèmes complexes et l'analyse de données.

Principales améliorations techniques
Qwen2.5-VL-32B exploite l'apprentissage par renforcement pour affiner son style de sortie, rendant les réponses plus cohérentes, détaillées et formatées pour une meilleure interaction humaine. De plus, ses capacités de raisonnement mathématique ont connu des améliorations significatives, comme en témoignent ses performances sur des références telles que MathVista et MMMU. Ces améliorations découlent de processus d'entraînement affinés qui privilégient la précision et la déduction logique, en particulier dans les contextes multimodaux où le texte et les données visuelles se croisent.
Le modèle excelle également dans la compréhension et le raisonnement d'images fines, permettant une analyse précise du contenu visuel, tel que les graphiques, les diagrammes et les documents. Cette capacité positionne Qwen2.5-VL-32B comme un concurrent de premier plan pour les applications nécessitant une déduction logique visuelle avancée et une reconnaissance de contenu.
Repères de performance Qwen2.5-VL-32B : Surclasser les modèles plus grands
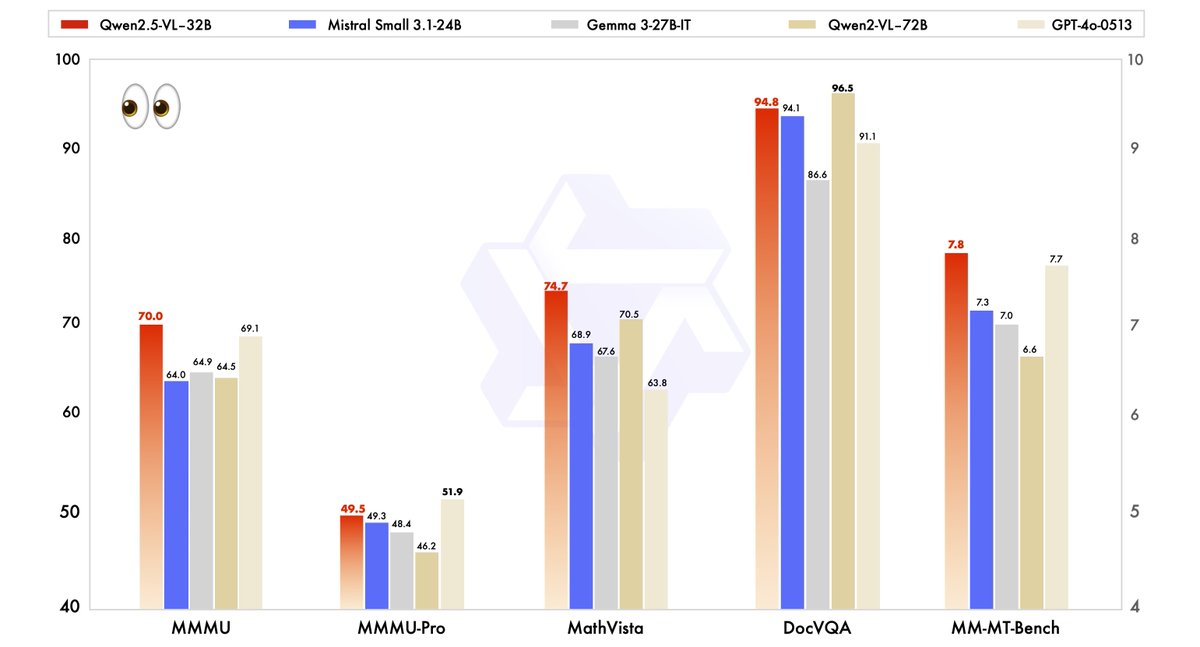
Les performances de Qwen2.5-VL-32B ont été rigoureusement évaluées par rapport aux modèles de pointe, y compris son grand frère, Qwen2.5-VL-72B, ainsi que des concurrents comme Mistral-Small-3.1–24B et Gemma-3–27B-IT. Les résultats mettent en évidence la supériorité du modèle dans plusieurs domaines clés.
- MMMU (Massive Multitask Language Understanding) : Qwen2.5-VL-32B obtient un score de 70,0, dépassant les 64,5 de Qwen2.5-VL-72B. Ce benchmark teste un raisonnement complexe en plusieurs étapes sur diverses tâches, démontrant les capacités cognitives améliorées du modèle.
- MathVista : Avec un score de 74,7, Qwen2.5-VL-32B surpasse les 70,5 de Qwen2.5-VL-72B, soulignant sa force dans les tâches de raisonnement mathématique et visuel.
- MM-MT-Bench : Ce benchmark d'évaluation de l'expérience utilisateur subjective montre Qwen2.5-VL-32B devançant son prédécesseur d'une marge significative, reflétant une amélioration de l'alignement des préférences humaines.
- Tâches basées sur le texte (par exemple, MMLU, MATH, HumanEval) : Le modèle est en concurrence efficace avec des modèles plus grands comme GPT-4o-Mini, obtenant des scores de 78,4 sur MMLU, 82,2 sur MATH et 91,5 sur HumanEval, malgré son nombre de paramètres plus petit.
Ces benchmarks illustrent que Qwen2.5-VL-32B non seulement correspond, mais dépasse souvent les performances des modèles plus grands, tout en nécessitant moins de ressources informatiques. Cet équilibre entre puissance et efficacité en fait une option attrayante pour les développeurs et les chercheurs travaillant avec du matériel limité.
Pourquoi la taille est importante : l'avantage 32B
La taille de 32 milliards de paramètres de Qwen2.5-VL-32B trouve un juste milieu pour le déploiement local. Contrairement aux modèles 72B, qui exigent des ressources GPU importantes, ce modèle plus léger s'intègre de manière transparente aux moteurs d'inférence comme SGLang et vLLM, comme indiqué dans les résultats Web connexes. Cette compatibilité assure un déploiement plus rapide et une utilisation de la mémoire plus faible, ce qui le rend accessible à un plus large éventail d'utilisateurs, des startups aux grandes entreprises.
De plus, l'optimisation du modèle pour la vitesse et l'efficacité ne compromet pas ses capacités. Sa capacité à gérer des tâches multimodales — telles que la reconnaissance d'objets, l'analyse de graphiques et le traitement de sorties structurées comme les factures et les tableaux — reste robuste, ce qui en fait un outil polyvalent pour les applications du monde réel.

Exécution de Qwen2.5-VL-32B localement avec MLX
Pour exécuter ce puissant modèle localement sur votre Mac avec Apple Silicon, suivez ces étapes :
Configuration système requise
- Un Mac avec Apple Silicon (puce M1, M2 ou M3)
- Au moins 32 Go de RAM (64 Go recommandés)
- 60 Go+ d'espace de stockage libre
- macOS Sonoma ou version ultérieure
Étapes d'installation
- Installer les dépendances Python
pip install mlx mlx-llm transformers pillow
- Télécharger le modèle
git lfs install
git clone https://huggingface.co/Qwen/Qwen2.5-VL-32B-Instruct
- Convertir le modèle au format MLX
python -m mlx_llm.convert --model-name Qwen/Qwen2.5-VL-32B-Instruct --mlx-path ./qwen2.5-vl-32b-mlx
- Créer un script simple pour interagir avec le modèle
import mlx.core as mx
from mlx_llm import load, generate
from PIL import Image
# Charger le modèle
model, tokenizer = load("./qwen2.5-vl-32b-mlx")
# Charger une image
image = Image.open("path/to/your/image.jpg")
# Créer une invite avec l'image
prompt = "Que voyez-vous dans cette image ?"
outputs = generate(model, tokenizer, prompt=prompt, image=image, max_tokens=512)
print(outputs)
Applications pratiques : Tirer parti de Qwen2.5-VL-32B
Tâches de vision et au-delà
Les capacités visuelles avancées de Qwen2.5-VL-32B ouvrent les portes à un large éventail d'applications. Par exemple, il peut servir d'agent visuel, interagissant dynamiquement avec les interfaces d'ordinateur ou de téléphone pour effectuer des tâches telles que la navigation ou l'extraction de données. Sa capacité à comprendre de longues vidéos (jusqu'à une heure) et à identifier des segments pertinents améliore encore son utilité dans l'analyse vidéo et la localisation temporelle.
Dans l'analyse de documents, le modèle excelle dans le traitement de contenu multiscène et multilingue, y compris le texte manuscrit, les tableaux, les graphiques et les formules chimiques. Cela le rend inestimable pour des secteurs comme la finance, l'éducation et la santé, où l'extraction précise de données structurées est essentielle.
Raisonnement textuel et mathématique
Au-delà des tâches de vision, Qwen2.5-VL-32B brille dans les applications textuelles, en particulier celles impliquant le raisonnement mathématique et le codage. Ses scores élevés sur des références comme MATH et HumanEval indiquent sa compétence à résoudre des problèmes algébriques complexes, à interpréter des graphiques de fonctions et à générer des extraits de code précis. Cette double compétence en vision et en texte positionne Qwen2.5-VL-32B comme une solution holistique pour les défis de l'IA multimodale.

Où vous pouvez utiliser Qwen2.5-VL-32B
Open Source et accès API
Qwen2.5-VL-32B est disponible sous la licence Apache 2.0, ce qui le rend open source et accessible aux développeurs du monde entier. Vous pouvez accéder au modèle via plusieurs plateformes :
- Hugging Face : Le modèle est hébergé sur Hugging Face, où vous pouvez le télécharger pour une utilisation locale ou l'intégrer via la bibliothèque Transformers.
- ModelScope : La plateforme ModelScope d'Alibaba offre une autre voie pour accéder et déployer le modèle.
Pour une intégration transparente, les développeurs peuvent utiliser l'API Qwen, qui simplifie l'interaction avec le modèle. Que vous construisiez une application personnalisée ou que vous expérimentiez des tâches multimodales, l'API Qwen garantit une connectivité efficace et des performances robustes.
Déploiement avec des moteurs d'inférence
Qwen2.5-VL-32B prend en charge le déploiement avec des moteurs d'inférence comme SGLang et vLLM. Ces outils optimisent le modèle pour une inférence rapide, réduisant la latence et l'utilisation de la mémoire. En tirant parti de ces moteurs, les développeurs peuvent déployer le modèle sur du matériel local ou des plateformes cloud, l'adaptant à des cas d'utilisation spécifiques.
Pour commencer, installez les bibliothèques requises (par exemple, transformers, vllm) et suivez les instructions sur la page GitHub de Qwen ou la documentation de Hugging Face. Ce processus garantit une intégration en douceur, vous permettant d'exploiter tout le potentiel du modèle.
Optimisation des performances locales
Lors de l'exécution de Qwen2.5-VL-32B localement, tenez compte de ces conseils d'optimisation :
- Quantification : Ajoutez l'indicateur
--quantizelors de la conversion pour réduire les exigences de mémoire - Gérer la longueur du contexte : Limitez les jetons d'entrée pour des réponses plus rapides
- Fermer les applications gourmandes en ressources lors de l'exécution du modèle
- Traitement par lots : Pour plusieurs images, traitez-les par lots plutôt qu'individuellement
Conclusion : Pourquoi Qwen2.5-VL-32B est important
Qwen2.5-VL-32B représente une étape importante dans l'évolution des modèles vision-langage. En combinant un raisonnement plus intelligent, des exigences de ressources plus légères et des performances robustes, ce modèle de 32 milliards de paramètres répond aux besoins des développeurs et des chercheurs. Ses avancées en matière de raisonnement mathématique, d'alignement des préférences humaines et de tâches de vision le positionnent comme un choix de premier plan pour le déploiement local et les applications du monde réel.
Que vous construisiez des outils éducatifs, des systèmes de veille économique ou des solutions de support client, Qwen2.5-VL-32B offre la polyvalence et l'efficacité dont vous avez besoin. Avec un accès via des plateformes open source et l'API Qwen, l'intégration de ce modèle dans vos projets est plus facile que jamais. Alors que l'équipe Qwen continue d'innover, nous pouvons nous attendre à des développements encore plus passionnants dans l'avenir de l'IA multimodale.
Cet outil API vous permet de tester et de déboguer les points de terminaison de votre modèle sans effort. Téléchargez Apidog gratuitement dès aujourd'hui et rationalisez votre flux de travail tout en explorant les capacités de Mistral Small 3.1 !


