
Qwen, l'initiative de modèle de fondation ouvert d'Alibaba, repousse constamment les limites de l'intelligence artificielle grâce à des itérations et des versions rapides. Les développeurs et les chercheurs attendent avec impatience chaque mise à jour, car les modèles Qwen établissent souvent de nouvelles normes en matière de performances et de polyvalence. Récemment, Qwen a lancé trois modèles innovants : Qwen-Image-Edit-2509, Qwen3-TTS-Flash et Qwen3-Omni. Ces versions améliorent respectivement les capacités d'édition d'images, de synthèse vocale et de traitement omni-modal.
De plus, ces modèles arrivent à un moment charnière du développement de l'IA, où l'intégration multimodale devient essentielle pour les applications pratiques. Qwen-Image-Edit-2509 répond à la demande de manipulations visuelles précises, tandis que Qwen3-TTS-Flash s'attaque aux problèmes de latence dans la génération vocale. Parallèlement, l'introduction de Qwen3-Omni unifie diverses entrées dans un cadre cohérent. Ensemble, ils démontrent l'engagement de Qwen envers une IA accessible et performante. Cependant, comprendre leurs fondements techniques nécessite un examen plus approfondi. Cet article décortique chaque modèle, en soulignant ses caractéristiques, ses architectures, ses benchmarks et ses impacts potentiels.
Qwen-Image-Edit-2509 : Élever la précision de l'édition d'images
Qwen-Image-Edit-2509 représente une avancée significative dans la manipulation d'images basée sur l'IA. Les ingénieurs de Qwen ont reconstruit ce modèle pour répondre aux besoins des créateurs, des designers et des développeurs qui exigent un contrôle granulaire sur le contenu visuel. Contrairement aux itérations précédentes, cette version prend en charge l'édition multi-images, permettant aux utilisateurs de combiner sans effort des éléments tels qu'une personne avec un produit ou une scène. Par conséquent, elle élimine les artefacts courants comme les mélanges mal assortis, produisant des sorties cohérentes.

Le modèle excelle dans la cohérence d'une seule image. Il préserve les identités faciales à travers les poses, les styles et les filtres, ce qui s'avère inestimable pour les applications publicitaires et de personnalisation. Pour les images de produits, Qwen-Image-Edit-2509 maintient l'intégrité de l'objet, garantissant que les modifications ne déforment pas les attributs clés. De plus, il gère les éléments textuels de manière exhaustive, permettant des modifications du contenu, des polices, des couleurs et même des textures. Cette polyvalence découle des mécanismes ControlNet intégrés, qui incorporent des cartes de profondeur, la détection des bords et des points clés pour un guidage précis.
Techniquement, Qwen-Image-Edit-2509 s'appuie sur l'architecture fondamentale de Qwen-Image mais intègre des techniques d'entraînement avancées. Les développeurs l'ont entraîné en utilisant des méthodes de concaténation d'images pour faciliter les entrées multi-images. Par exemple, la combinaison de "personne + personne" ou "personne + scène" exploite des flux de données concaténés, améliorant la capacité du modèle à fusionner des visuels disparates. De plus, l'architecture intègre des processus basés sur la diffusion, où le bruit est progressivement supprimé pour générer des images raffinées. Cette approche, courante dans les variantes de diffusion stable, permet une génération conditionnelle basée sur les invites de l'utilisateur.
En termes de benchmarks, Qwen-Image-Edit-2509 démontre des performances supérieures en matière de métriques de cohérence. Des évaluations internes montrent qu'il surpasse ses concurrents en matière de préservation des visages, avec des scores de similarité dépassant 95 % sur diverses modifications. Les benchmarks de cohérence des produits révèlent une distorsion minimale, ce qui le rend idéal pour le commerce électronique. Cependant, les données quantitatives provenant de sources externes restent limitées en raison de sa sortie récente. Néanmoins, les démonstrations des utilisateurs sur des plateformes comme Hugging Face soulignent son avantage sur des modèles comme Stable Diffusion XL dans le mélange multi-éléments.
Les applications abondent pour Qwen-Image-Edit-2509. Les spécialistes du marketing l'utilisent pour créer des publicités personnalisées en modifiant les placements de produits de manière transparente. Les designers l'emploient pour le prototypage rapide, modifiant des scènes sans retouche manuelle. De plus, dans le jeu vidéo, il facilite la génération dynamique d'actifs. Un exemple illustratif implique la transformation de la tenue d'une personne : une image d'entrée d'une femme en tenue décontractée, combinée à une référence de robe noire, produit un résultat où la robe s'adapte naturellement, préservant la posture et l'éclairage. Cette capacité, comme le montrent les démonstrations visuelles, souligne son utilité pratique.


En ce qui concerne l'implémentation, les développeurs accèdent à Qwen-Image-Edit-2509 via les référentiels GitHub et les espaces Hugging Face. L'installation implique généralement le clonage du dépôt et la configuration des dépendances comme PyTorch. Un script d'utilisation de base pourrait ressembler à ceci :
import torch
from qwen_image_edit import QwenImageEdit
model = QwenImageEdit.from_pretrained("Qwen/Qwen-Image-Edit-2509")
input_image = load_image("person.jpg")
reference_image = load_image("dress.jpg")
output = model.edit_multi(input_image, reference_image, prompt="Apply the black dress to the person")
output.save("edited.jpg")
Un tel code permet des itérations rapides. Cependant, les utilisateurs doivent prendre en compte les exigences de calcul, car l'inférence exige une accélération GPU pour une vitesse optimale.
Malgré ses atouts, Qwen-Image-Edit-2509 fait face à des défis. Les modifications haute résolution peuvent consommer une mémoire significative, et les invites complexes conduisent occasionnellement à des incohérences. Néanmoins, les contributions continues de la communauté via les canaux open source atténuent ces problèmes. Dans l'ensemble, ce modèle redéfinit l'édition d'images en combinant précision et accessibilité.
Qwen3-TTS-Flash : Accélérer la synthèse vocale
Qwen3-TTS-Flash apparaît comme une puissance dans la technologie de synthèse vocale (TTS), privilégiant la vitesse et le naturel. Les ingénieurs de Qwen l'ont conçu pour délivrer des voix humaines avec une latence minimale, résolvant les goulots d'étranglement dans les applications en temps réel. Plus précisément, il atteint une latence du premier paquet de seulement 97 ms dans les environnements à thread unique, permettant des interactions fluides dans les chatbots et les assistants virtuels.
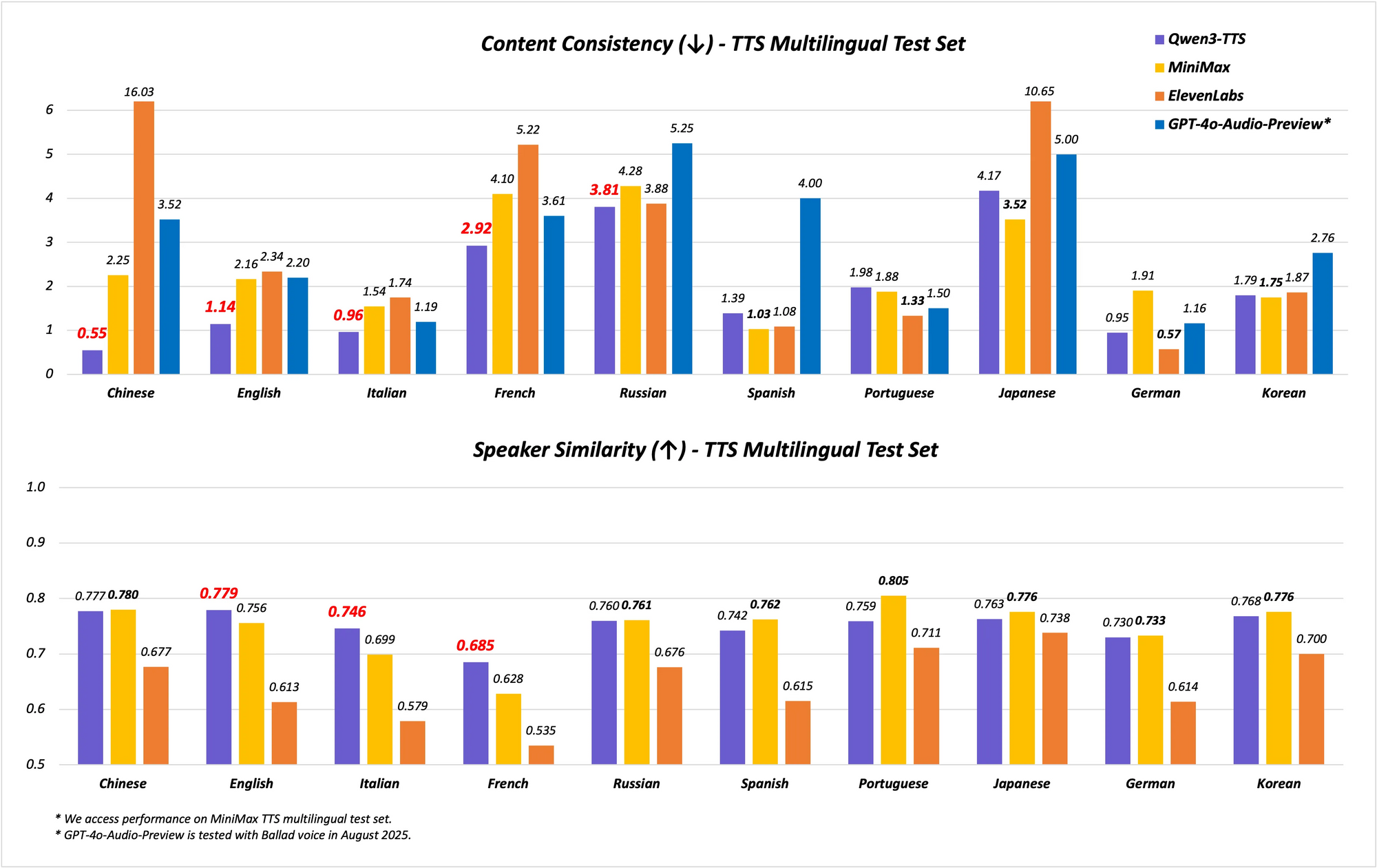
Le modèle prend en charge des capacités multilingues et multi-dialectes, couvrant 10 langues avec 17 voix expressives. Il excelle en stabilité chinoise et anglaise, atteignant des performances de pointe (SOTA) sur des benchmarks comme l'ensemble de test Seed-TTS-Eval. Ici, il surpasse des modèles tels que SeedTTS, MiniMax et GPT-4o-Audio-Preview en termes de métriques de stabilité. De plus, lors des évaluations multilingues sur l'ensemble de test MiniMax TTS, Qwen3-TTS-Flash enregistre le taux d'erreur de mots (WER) le plus bas pour le chinois, l'anglais, l'italien et le français.
Le support des dialectes distingue Qwen3-TTS-Flash. Il gère neuf dialectes chinois, dont le cantonais, le hokkien, le sichuanais, le pékinois, le nankinois, le tianjinois et le shaanxi. Cette fonctionnalité permet une parole culturellement nuancée, essentielle sur des marchés diversifiés. De plus, le modèle adapte automatiquement les tons, s'appuyant sur de vastes données d'entraînement pour correspondre au sentiment d'entrée. La gestion robuste du texte améliore encore la fiabilité, car il extrait les informations clés de formats complexes comme les dates, les nombres et les acronymes.
Architecturalement, Qwen3-TTS-Flash utilise un cadre encodeur-décodeur basé sur des transformeurs, optimisé pour l'inférence à faible latence. Il utilise des représentations multi-codebooks pour une modélisation vocale plus riche, améliorant l'expressivité. L'entraînement a impliqué de vastes ensembles de données englobant 119 langues pour le texte et 19 pour la compréhension de la parole, bien que la sortie se concentre sur 10 langues. Cette configuration permet la génération interlingue, où les entrées dans une langue produisent des sorties dans une autre de manière transparente.

Les benchmarks illustrent ses prouesses. Lors des tests de stabilité, Qwen3-TTS-Flash obtient des scores plus élevés en similitude de timbre et en naturel par rapport à ElevenLabs et GPT-4o. Par exemple :
| Benchmark | Qwen3-TTS-Flash | MiniMax | GPT-4o-Audio-Preview |
|---|---|---|---|
| Stabilité chinoise | SOTA | Inférieur | Inférieur |
| WER anglais | Le plus bas | Supérieur | Supérieur |
| Similitude de timbre multilingue | SOTA | Inférieur | Inférieur |
Ces résultats proviennent d'évaluations rigoureuses, le positionnant comme un leader en TTS.
Lors des démonstrations, Qwen3-TTS-Flash génère une parole expressive, comme la description d'un "latte miel lavande" avec enthousiasme ou la gestion de dialogues dans des dialectes. Les transcriptions vidéo révèlent sa capacité à traiter des entrées en langues mixtes, comme "Je suis vraiment heureux aujourd'hui. Je connais cette fille de Chine", prononcées avec des voix accentuées. Les applications incluent les systèmes de réponse vocale interactive (IVR), les PNJ de jeux et la création de contenu, où une faible latence double l'efficacité.
L'implémentation nécessite l'accès au modèle via des API ou des démos Hugging Face. Un exemple d'invocation Python :
from qwen_tts import QwenTTSFlash
model = QwenTTSFlash.from_pretrained("Qwen/Qwen3-TTS-Flash")
audio = model.synthesize(text="Hello, world!", voice="expressive_english", dialect="sichuanese")
audio.save("output.wav")
Cette simplicité accélère le développement. Cependant, la précision du dialecte peut varier avec des entrées rares, nécessitant un ajustement fin.
Qwen3-TTS-Flash transforme la TTS en équilibrant vitesse, qualité et diversité, ce qui le rend indispensable pour les systèmes d'IA modernes.
Présentation de Qwen3-Omni : La puissance multimodale unifiée
L'introduction de Qwen3-Omni marque une étape importante dans l'IA multimodale, car Qwen intègre le texte, l'image, l'audio et la vidéo dans un seul modèle de bout en bout. Cette unification native évite les compromis de modalité, permettant un raisonnement trans-modal plus profond. Le modèle traite 119 langues pour le texte, 19 pour l'entrée vocale et 10 pour la sortie vocale, avec une latence remarquable de 211 ms pour les réponses.
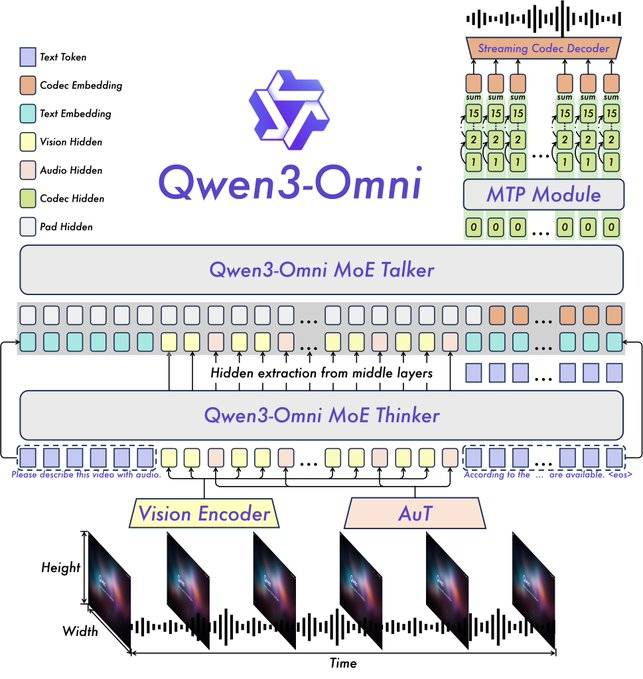
Les principales caractéristiques incluent des performances SOTA sur 22 des 36 benchmarks audio et audio-visuels, des invites système personnalisables, un appel d'outils intégré et un modèle de sous-titrage open source avec de faibles taux d'hallucination. Qwen a mis en open source des variantes comme Qwen3-Omni-30B-A3B-Instruct pour le suivi des instructions et Qwen3-Omni-30B-A3B-Thinking pour un raisonnement amélioré.
L'architecture s'appuie sur le cadre Thinker-Talker de Qwen2.5-Omni, avec des améliorations telles que le remplacement de l'encodeur audio Whisper par un transformateur audio (AuT) pour une meilleure représentation. La gestion de la parole multi-codebooks enrichit la sortie vocale, tandis que le contexte étendu prend en charge plus de 30 minutes d'audio. Cela permet un raisonnement toutes modalités, où les entrées vidéo informent les réponses audio.
Les benchmarks confirment sa domination. Il atteint le SOTA global sur 32 benchmarks, excellant dans la compréhension et la génération audio. Par exemple, dans les tâches audio-visuelles, il surpasse des modèles comme GPT-4o en termes de latence et de précision. Un tableau comparatif :
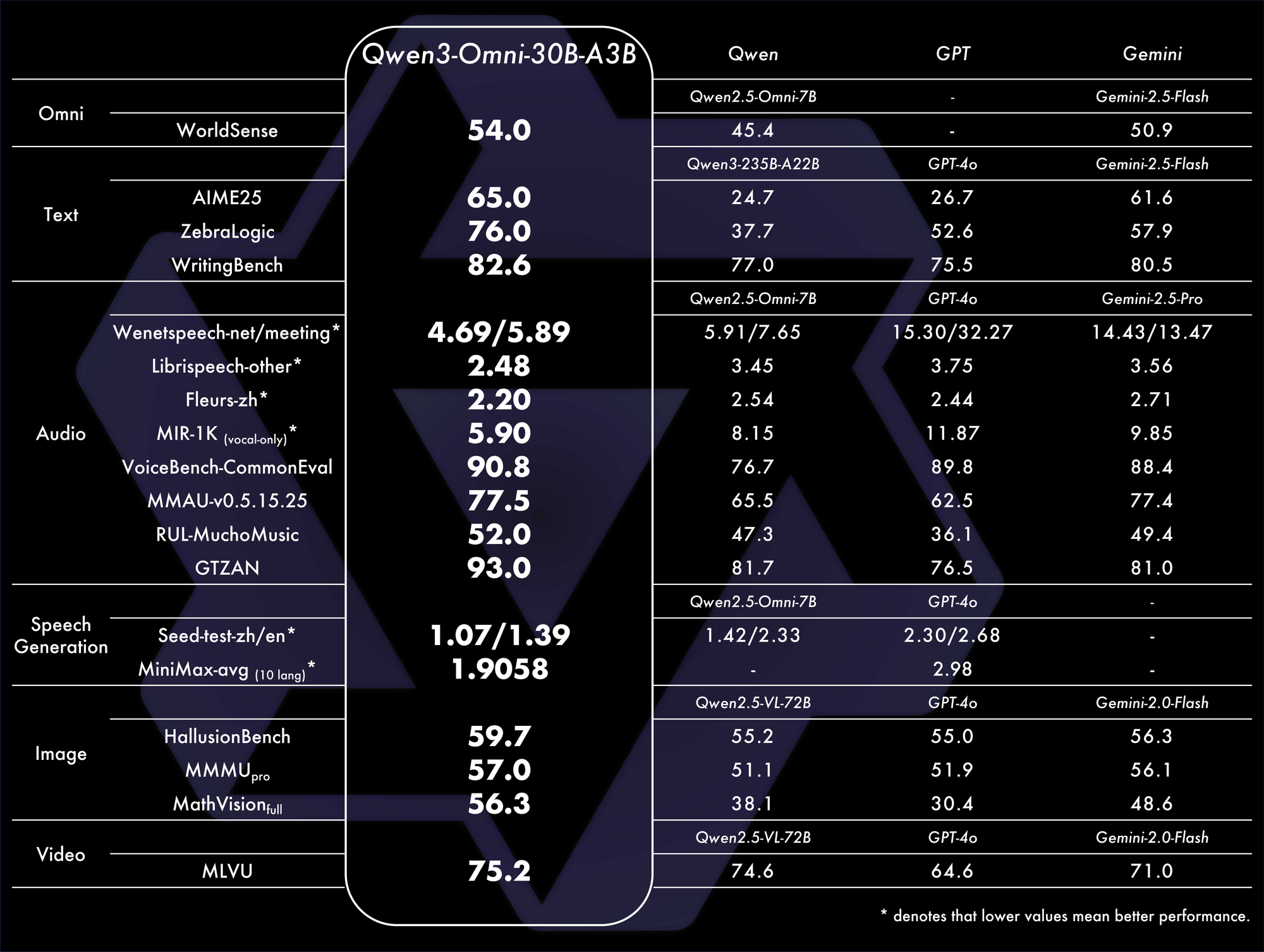
Ces métriques soulignent son efficacité dans des scénarios réels.
Les applications couvrent le chat vocal, l'analyse vidéo et les agents multimodaux. Par exemple, il analyse un clip vidéo et génère des résumés parlés, idéal pour les outils d'accessibilité. Les démos sur Qwen Chat présentent des interactions vocales et vidéo, où les utilisateurs interrogent des images ou des audios verbalement.
Sur GitHub, le README le décrit comme capable de générer de la parole en temps réel à partir d'entrées diverses. La configuration implique :
from qwen_omni import Qwen3Omni
model = Qwen3Omni.from_pretrained("Qwen/Qwen3-Omni-30B-A3B-Instruct")
response = model.process(inputs={"text": "Describe this", "image": "img.jpg", "audio": "clip.wav"})
print(response.text)
response.audio.save("reply.wav")
Cette approche modulaire facilite la personnalisation. Les défis incluent des exigences de calcul élevées pour le traitement vidéo, mais des optimisations comme la quantification aident.
L'introduction de Qwen3-Omni consolide les modalités, favorisant des écosystèmes d'IA innovants.
Synergies entre les nouveaux modèles de Qwen et implications futures
Qwen-Image-Edit-2509, Qwen3-TTS-Flash et Qwen3-Omni se complètent, permettant des flux de travail de bout en bout. Par exemple, éditez une image avec Qwen-Image-Edit-2509, décrivez-la via Qwen3-Omni et vocalisez la sortie avec Qwen3-TTS-Flash. Cette intégration amplifie l'utilité dans la création de contenu et l'automatisation.
De plus, leur nature open source invite aux améliorations de la communauté. Les développeurs utilisant Apidog peuvent tester les API efficacement, garantissant des intégrations robustes.
Cependant, des considérations éthiques surgissent, telles que l'utilisation abusive dans les deepfakes. Qwen atténue cela grâce à des garde-fous.
En conclusion, les lancements de Qwen redéfinissent les paysages de l'IA. En faisant progresser les frontières techniques, ils permettent aux utilisateurs d'accomplir davantage. À mesure que l'adoption se développera, ces modèles propulseront la prochaine vague d'innovation.