
Qwen-Image, un modèle de fondation d'image MMDiT 20B de pointe de l'équipe Qwen d'Alibaba Cloud, redéfinit les possibilités de la création visuelle basée sur l'IA. Lancé le 4 août 2025, ce modèle offre des capacités inégalées pour générer des images de haute qualité, rendre des textes multilingues complexes et effectuer des modifications d'image précises. Que vous créiez des visuels marketing dynamiques ou analysiez des données d'image complexes, Qwen-Image offre aux développeurs des outils robustes pour donner vie à leurs idées.
Qu'est-ce que Qwen-Image ? Un aperçu technique
Qwen-Image, faisant partie de la série Qwen d'Alibaba Cloud, est un modèle de transformateur de diffusion multimodale (MMDiT) avec 20 milliards de paramètres, conçu à la fois pour la génération et l'édition d'images. Contrairement aux modèles traditionnels qui se concentrent uniquement sur la génération de visuels, Qwen-Image intègre un rendu de texte avancé et une compréhension d'image, ce qui en fait un outil polyvalent pour les tâches créatives et analytiques. Le modèle, open source sous la licence Apache 2.0, est accessible via des plateformes comme GitHub, Hugging Face et ModelScope, permettant aux développeurs de l'intégrer dans divers flux de travail.

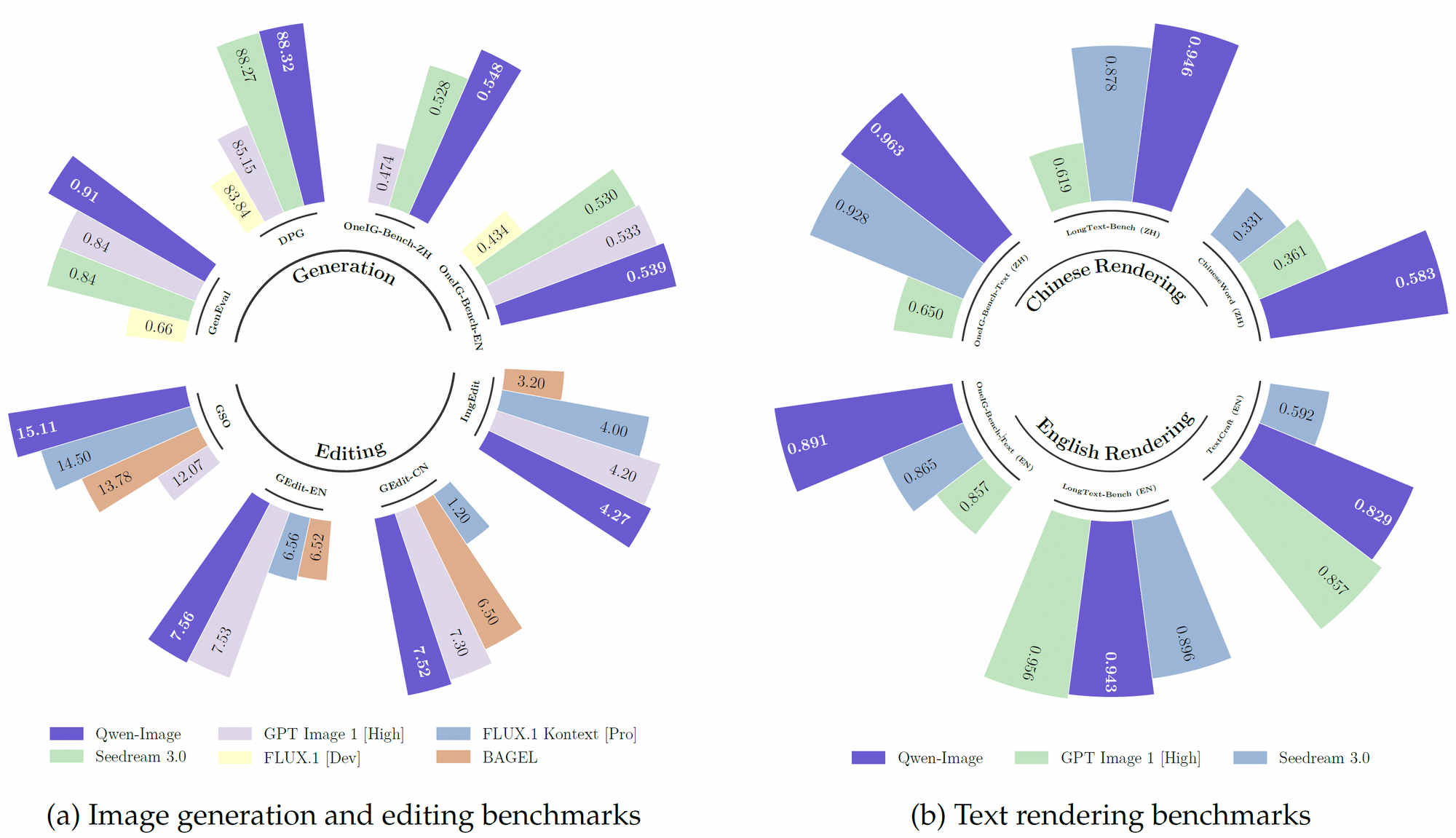
De plus, Qwen-Image s'appuie sur un robuste ensemble de données de pré-entraînement, incorporant plus de 30 billions de jetons dans 119 langues, avec un accent sur le chinois et l'anglais. Cet ensemble de données étendu, combiné à des techniques d'apprentissage par renforcement, permet au modèle de gérer des tâches complexes comme le rendu de texte multilingue et la manipulation précise d'objets. Par conséquent, il surpasse de nombreux modèles existants sur des benchmarks tels que GenEval, DPG et LongText-Bench.
Fonctionnalités clés de Qwen-Image
Rendu de texte supérieur pour les visuels multilingues
Qwen-Image excelle dans le rendu de texte complexe au sein des images, une fonctionnalité qui le distingue de ses concurrents. Il prend en charge à la fois les langues alphabétiques (par exemple, l'anglais) et les écritures logographiques (par exemple, le chinois), garantissant une intégration de texte de haute fidélité. Par exemple, le modèle peut générer une affiche de film avec des mises en page de texte précises, comme un titre tel que « Imagination déchaînée » et des sous-titres sur plusieurs lignes, en maintenant la cohérence typographique. Cette capacité découle de son entraînement sur divers ensembles de données, y compris LongText-Bench et ChineseWord, où il atteint des performances de pointe.
De plus, Qwen-Image gère les mises en page multi-lignes et la sémantique au niveau du paragraphe avec une précision remarquable. Dans un scénario de test, il a rendu avec précision un poème manuscrit sur du papier jauni à l'intérieur d'une image, bien que le texte occupe moins d'un dixième de l'espace visuel. Cette précision le rend idéal pour des applications telles que l'affichage numérique, la conception d'affiches et la visualisation de documents.
Capacités avancées d'édition d'images
Au-delà du rendu de texte, Qwen-Image offre des fonctionnalités sophistiquées d'édition d'images. Il prend en charge des opérations telles que le transfert de style, l'insertion d'objets, l'amélioration des détails et la manipulation de la pose humaine. Par exemple, les utilisateurs peuvent demander au modèle d'« ajouter un ciel ensoleillé à cette image » ou de « transformer cette peinture en style Van Gogh », et Qwen-Image fournit des résultats cohérents. Son paradigme d'entraînement multi-tâches amélioré garantit que les modifications préservent le sens sémantique et le réalisme visuel.
De plus, la capacité du modèle à éditer du texte dans les images est particulièrement remarquable. Les développeurs peuvent modifier le texte sur des panneaux ou des affiches sans perturber le contexte visuel environnant, une fonctionnalité précieuse pour la publicité et la création de contenu. Ces capacités sont prises en charge par la compréhension visuelle profonde de Qwen-Image, qui lui permet d'interpréter et de manipuler les éléments d'image avec précision.
Compréhension visuelle complète
Qwen-Image ne se contente pas de créer ou d'éditer, il comprend. Le modèle prend en charge une suite de tâches de compréhension d'images, y compris la détection d'objets, la segmentation sémantique, l'estimation de la profondeur, la détection de contours (Canny), la synthèse de nouvelles vues et la super-résolution. Ces tâches sont alimentées par sa capacité à traiter des entrées haute résolution et à extraire des détails fins. Par exemple, Qwen-Image peut générer des boîtes englobantes pour des objets décrits en langage naturel, tels que « détecter le chien Husky dans la scène du métro », ce qui en fait un outil puissant pour l'analyse visuelle.
De plus, son support de plusieurs langues améliore son utilisabilité dans les applications mondiales. En s'intégrant à des outils comme le Qwen-Plus Prompt Enhancement Tool, les développeurs peuvent optimiser les invites pour une meilleure performance multilingue, garantissant des résultats précis dans divers contextes linguistiques.
Excellence des performances multi-benchmarks
Qwen-Image surpasse constamment ses concurrents sur plusieurs benchmarks publics, y compris GenEval, DPG, OneIG-Bench, GEdit, ImgEdit et GSO. Sa performance supérieure en rendu de texte, en particulier pour le chinois, est évidente dans des benchmarks comme TextCraft, où il surpasse les modèles de pointe existants. De plus, ses capacités générales de génération d'images prennent en charge un large éventail de styles artistiques, des scènes photoréalistes à l'esthétique anime, ce qui en fait un choix polyvalent pour les professionnels de la création.
Architecture technique de Qwen-Image
Transformateur de diffusion multimodale (MMDiT)
À la base, Qwen-Image utilise une architecture de transformateur de diffusion multimodale (MMDiT), qui combine les forces des modèles de diffusion et des transformateurs. Cette approche hybride permet au modèle de traiter efficacement les entrées visuelles et textuelles. Le processus de diffusion affine itérativement les entrées bruyantes en images cohérentes, tandis que le composant transformateur gère les relations complexes entre le texte et les éléments visuels.
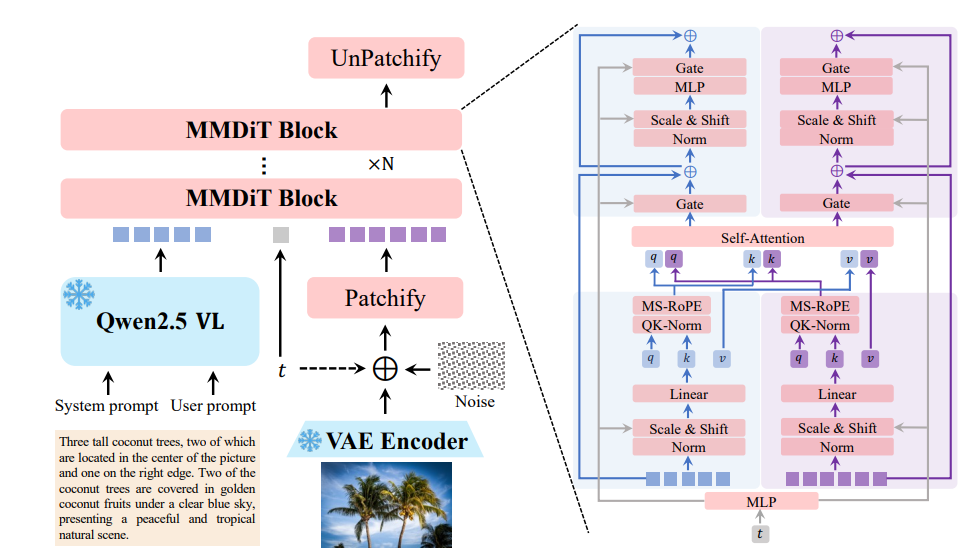
Les 20 milliards de paramètres du modèle sont optimisés pour l'efficacité, ce qui lui permet de fonctionner sur du matériel grand public avec aussi peu que 4 Go de VRAM en utilisant des techniques comme la quantification FP8 et le déchargement couche par couche. Cette accessibilité rend Qwen-Image adapté aux développeurs d'entreprise et individuels.
Pré-entraînement et affinage
L'ensemble de données de pré-entraînement de Qwen-Image est une pierre angulaire de ses performances. S'étendant sur plus de 30 billions de jetons, l'ensemble de données comprend des données web, des documents de type PDF et des données synthétiques générées par des modèles comme Qwen2.5-VL et Qwen2.5-Coder. Le processus de pré-entraînement se déroule en trois étapes :

- Étape 1 (S1) : Le modèle est pré-entraîné sur 30 billions de jetons avec une longueur de contexte de 4K jetons, établissant des compétences linguistiques et visuelles fondamentales.
- Étape 2 : L'apprentissage par renforcement améliore les capacités de raisonnement et spécifiques aux tâches du modèle.
- Étape 3 : L'affinage avec des ensembles de données sélectionnés améliore l'alignement avec les préférences de l'utilisateur et des tâches spécifiques comme le rendu de texte et l'édition d'images.
Cette approche multi-étapes garantit que Qwen-Image est à la fois robuste et adaptable, capable de gérer diverses tâches avec une grande précision.
Intégration avec les outils de développement
Qwen-Image s'intègre parfaitement aux frameworks de développement populaires comme Diffusers et DiffSynth-Studio. Par exemple, les développeurs peuvent utiliser le code Python suivant pour générer des images avec Qwen-Image :
from diffusers import DiffusionPipeline
import torch
model_name = "Qwen/Qwen-Image"
torch_dtype = torch.bfloat16 if torch.cuda.is_available() else torch.float32
device = "cuda" if torch.cuda.is_available() else "cpu"
pipe = DiffusionPipeline.from_pretrained(model_name, torch_dtype=torch_dtype)
pipe = pipe.to(device)
prompt = "A coffee shop entrance with a chalkboard sign reading 'Qwen Coffee 😊 $2 per cup.'"
image = pipe(prompt).images[0]
image.save("qwen_coffee.png")
Cet extrait de code démontre comment les développeurs peuvent exploiter les capacités de Qwen-Image pour générer des visuels de haute qualité avec une configuration minimale. Des outils comme Apidog simplifient davantage l'intégration d'API, permettant un prototypage et un déploiement rapides.
Applications pratiques de Qwen-Image
Génération de contenu créatif
La capacité de Qwen-Image à générer des scènes photoréalistes, des peintures impressionnistes et des visuels de style anime en fait un outil puissant pour les artistes et les designers. Par exemple, un graphiste peut créer une affiche de film avec des mises en page de texte dynamiques et des images vibrantes, comme le montre un cas de test où Qwen-Image a produit une affiche pour « Imagination déchaînée » avec un ordinateur futuriste émettant des créatures fantaisistes.

Publicité et marketing
Dans la publicité, les capacités de rendu et d'édition de texte de Qwen-Image permettent la création de campagnes visuellement attrayantes. Les spécialistes du marketing peuvent générer des affiches avec un placement de texte précis ou modifier des visuels existants pour mettre à jour les messages promotionnels, garantissant la cohérence de la marque et la cohérence visuelle.

Analyse visuelle et automatisation
Pour des industries comme le commerce électronique et les systèmes autonomes, les tâches de compréhension d'images de Qwen-Image — telles que la détection d'objets et la segmentation sémantique — offrent une valeur significative. Les plateformes de vente au détail peuvent utiliser le modèle pour étiqueter automatiquement les produits dans les images, tandis que les véhicules autonomes peuvent exploiter son estimation de profondeur pour la navigation.
Outils pédagogiques
La capacité de Qwen-Image à générer des visuels éducatifs, tels que des diagrammes avec des annotations de texte précises, prend en charge les plateformes d'apprentissage en ligne. Par exemple, il peut créer une illustration détaillée d'un concept scientifique avec des composants étiquetés, améliorant l'engagement et la compréhension des étudiants.

Comparaison de Qwen-Image avec ses concurrents
Comparé à des modèles comme DALL-E 3 et Stable Diffusion, Qwen-Image se distingue par son rendu de texte multilingue et ses capacités d'édition avancées. Bien que DALL-E 3 excelle dans la génération d'images créatives, il a des difficultés avec les mises en page de texte complexes, en particulier pour les écritures logographiques. Stable Diffusion, bien que polyvalent, manque de la compréhension visuelle profonde offerte par la suite de tâches de compréhension de Qwen-Image.
De plus, la nature open source de Qwen-Image et sa compatibilité avec du matériel à faible mémoire lui confèrent un avantage pour les développeurs disposant de ressources limitées. Ses performances sur des benchmarks comme TextCraft et GEdit consolident davantage sa position en tant que modèle de pointe en IA multimodale.
Défis et limitations
Malgré ses forces, Qwen-Image fait face à des défis. La dépendance du modèle à l'égard d'ensembles de données à grande échelle soulève des préoccupations concernant la confidentialité des données et l'approvisionnement éthique, bien qu'Alibaba Cloud adhère à des directives strictes. De plus, bien que le modèle prenne en charge plus de 100 langues, ses performances peuvent varier pour les dialectes moins représentés, nécessitant un affinage supplémentaire.
De plus, les exigences computationnelles du modèle à 20 milliards de paramètres peuvent être importantes sans techniques d'optimisation comme la quantification FP8. Les développeurs doivent équilibrer les performances et les contraintes de ressources lors du déploiement de Qwen-Image dans des environnements de production.
Perspectives d'avenir pour Qwen-Image
À l'avenir, Qwen-Image est appelé à évoluer davantage. L'équipe Qwen prévoit de publier une version du modèle spécifique à l'édition, améliorant ses capacités pour les applications de qualité professionnelle. L'intégration avec des frameworks émergents comme vLLM et le support continu des workflows LoRA et d'affinage élargiront son accessibilité.
De plus, les avancées en apprentissage par renforcement, comme on le voit dans des modèles comme Qwen3, suggèrent que Qwen-Image pourrait intégrer des capacités de raisonnement plus profondes, permettant des tâches de raisonnement visuel plus complexes. Alors que la communauté de l'IA continue de contribuer à son développement, Qwen-Image a le potentiel de redéfinir la création et la compréhension visuelles.
Démarrer avec Qwen-Image
Pour commencer à utiliser Qwen-Image, les développeurs peuvent accéder aux poids du modèle sur GitHub ou Hugging Face. Le blog officiel à l'adresse qwenlm.github.io fournit des instructions de configuration détaillées et des cas d'utilisation. Pour une expérience pratique, visitez Qwen Chat et sélectionnez « Génération d'images » pour tester les capacités du modèle.
Pour l'intégration d'API, des outils comme Apidog simplifient le processus en offrant une interface conviviale pour tester et déployer les fonctionnalités de Qwen-Image. Téléchargez Apidog gratuitement pour rationaliser votre flux de travail de développement.
Conclusion : Pourquoi Qwen-Image est important
Qwen-Image représente un bond significatif dans l'IA multimodale, combinant un rendu de texte avancé, une édition d'images précise et une compréhension visuelle robuste. Sa disponibilité open source, son pré-entraînement étendu et sa compatibilité avec les outils de développement en font un choix polyvalent pour les créateurs, les développeurs et les chercheurs. En relevant des défis tels que le support multilingue et l'efficacité des ressources, Qwen-Image établit une nouvelle norme pour la création visuelle basée sur l'IA.
Alors que l'IA continue d'évoluer, des modèles comme Qwen-Image joueront un rôle essentiel pour combler le fossé entre le langage et l'imagerie, ouvrant de nouvelles possibilités pour les applications créatives et analytiques. Que vous construisiez une campagne marketing, analysiez des données visuelles ou créiez du contenu éducatif, Qwen-Image offre les outils pour donner vie à votre vision.